
10 月 13 日,蚂蚁集团正式开源业界首个高性能扩散语言模型推理框架 dInfer。
在基准测试中,dInfer 将扩散语言模型的推理速度相比于英伟达扩散模型框架 Fast-dLLM 提升了 10.7 倍;在代码生成任务 HumanEval 上,dInfer 在单批次推理中创造了 1011Tokens/秒的速度,首次在开源社区中实现扩散语言模型的单批次推理速度显著超越自回归模型。dInfer 的工作表明,扩散语言模型具备显著的效率潜力,可以通过系统性的创新工程兑现,为通往 AGI 的架构路径提供极具竞争力的选项。
扩散语言模型,作为一种全新的范式将文本生成视为一个“从随机噪声中逐步恢复完整序列”的去噪过程,具有高度并行、全局视野、结构灵活三大优势。
凭借这些优势,以蚂蚁集团和人大发布的 LLaDA-MoE 为代表的模型已在多个基准测试中,展现出与顶尖 AR 模型相媲美的准确性 。然而在推理效率方面,dLLM 理论上的强大潜能,却长期被残酷的现实“枷锁”所束缚。dLLM 的高效推理面临计算成本高、KV 缓存失效、并行解码三大挑战。这些瓶颈使得扩散语言模型的推理速度一直不尽人意,如何打破枷锁释放扩散语言模型在推理效率上的潜能,成为整个领域亟待解决的难题。
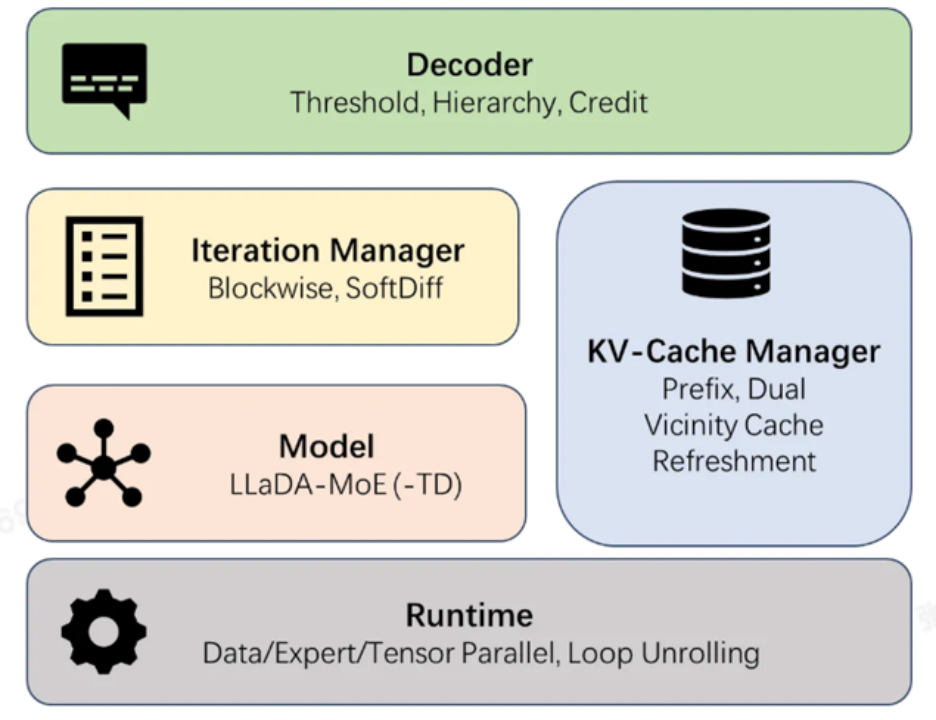
dInfer 是一款专为扩散语言模型设计的、算法与系统深度协同的高性能推理框架 ,可支持多种扩散语言模型,包括 LLaDA、 LLaDA-MoE、LLaDA-MoE-TD 等。
dInfer 包含四大核心模块:模型接入(Model)、KV 缓存管理器(KV-Cache Manager),扩散迭代管理器(Iteration Manager),和解码策略(Decoder)。这种可插拔的架构,允许开发者像搭乐高一样,进一步组合和探索不同模块的优化策略,并在统一的平台上进行标准化评测 。更重要的是,dInfer 针对上述三大挑战,在每个模块中都集成了针对性的解决方案。
在配备 8 块 NVIDIA H800 GPU 的节点上,dInfer 的性能表现令人瞩目:
在与先前的 dLLM 推理方案 Fast-dLLM 的对比中,dInfer 在模型效果持平的情况下,平均推理速度(avg TPS)实现了 10.7 倍的巨大提升(681 vs 63.6) ;在代码生成任务 HumanEval 上,dInfer 在单批次推理中创造了 1011 tokens/秒的速度 ;与在业界顶尖的推理服务框架 vLLM 上运行的、参数量和性能相当的 AR 模型 Qwen2.5-3B 相比,dInfer 的平均推理速度是其 2.5 倍(681 vs 277) 。
蚂蚁集团介绍,dInfer 连接了前沿研究与产业落地,标志着扩散语言模型从“理论可行”迈向“实践高效”的关键一步。此次开预案,也是诚邀全球的开发者与研究者共同探索扩散语言模型的巨大潜能,构建更加高效、开放的 AI 新生态。




