
作者 | 玉盘 AI 团队
审核 | 华卫
“大模型每生成 1 美元价值,需支付 3 美元算力成本”,算力成本挑战已无争议。从软件层面的各类优化方案层出不穷,真正从硬件源头着手的方案却屈指可数,市面上能看到的包括 Groq 在内的新计算硬件也多数在大模型爆发前定型,难以充分匹配大模型本身的需求。
近日,国内团队玉盘 AI 发布《SRDA AI 大模型专用计算架构》白皮书,提出了一种全新的计算架构:系统级精简可重构数据流架构 SRDA (System-level Simplified Reconfigurable Dataflow Architecture),从硬件源头解决当前 AI 算力的核心瓶颈。

与此同时,DeepSeek 于半个月前发表论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》,从用户视角梳理了当前大模型训练与推理中所面临的 AI 硬件瓶颈,以及对未来 AI 硬件的构想建议。

DeepSeek 从用户角度的不少构想与玉盘 SRDA 在做的事不谋而合,包括 IO 融合、3D 堆叠 DRAM 等,而玉盘进一步提出了更完整的架构设计,或正式拉开下一代大模型专用计算架构的序幕。
软硬两头的交汇或暗示业界已逐渐形成共识,即当前算力已不再是瓶颈,瓶颈在于绝大多数算力浪费在了数据搬运及读写上(互联和内存等 I/O 问题)。SRDA 相关思路是否将在不久的未来颠覆 GPGPU 目前在 AI 场景的垄断地位?
当前类 GPGPU 计算架构的困境
硬件架构层面的创新比较少见,人们通常认为国产算力的问题在于制程或封装技术,这种理解源于默认 GPGPU 架构是 AI 大模型的最优架构(GPGPU 架构强依赖先进制程及先进封装)。白皮书认为,GPGPU 是非常优秀的计算架构,但为保证通用性,不会完全针对大模型训练及推理的诸多需求,就像用瑞士军刀切牛排——不是刀不快,而是工具缺乏针对性。
在深入 SRDA 架构细节前,白皮书回顾了目前开发者们普遍面临的难题:
内存与互联带宽不足:H100 每秒可计算 1000 万亿次,但其共享内存架构 + 低内存带宽仅够“喂饱”不足一半的硬件算力,如同几台车抢一个车位。
算力利用率不足:受限于类 GPGPU 架构本身的通信开销及内存瓶颈,芯片的理论算力在实际 AI 负载中往往大打折扣。
网络复杂,大规模集群扩展瓶颈:传统多层网络(节点内高速互联如 NVLink,节点间网络如 InfiniBand/ 以太网)设计复杂,带来带宽层级差异、协议转换开销和管理难题,阻碍了超大规模集群的效能发挥。
功耗过大:以 H100 为例,单卡 700 瓦的 GPU 集群,超三分之一的电量用于数据“搬家”而非计算。
正如 GPGPU 曾广泛用于矿机市场,而后由专用的矿卡芯片替代,站在在今天这个时点,大模型技术需求逐步清晰及收敛,Transformer 等主流架构也已经有明确的市场需求,也给了新的 AI 专用架构机会。
目前多数针对 AI 场景的专用架构(DSA,Domain Specific Architecture)多是在 2023 年大模型爆发前或 2024 年大模型技术收敛前设计的,对大模型的特定需求缺乏充分考虑,很多并没有摆脱 GPGPU SIMT 架构线程间抢占资源、多级共享 Cache、用计算单元处理通讯任务等设计,因此也有和 GPGPU 相似的问题:算力利用率低、依赖先进制程等,依靠后天的软件做算力优化,进而陷入烧钱复刻 CUDA、堆制程等怪圈。
下一代 AI 大模型算力芯片的关键要素
白皮书认为下一代 AI 计算架构应具备以下一系列关键特征:
基于 3D 堆叠创新的内存系统设计与超高带宽
一体化融合网络
原生数据流处理能力
先进的低精度计算支持
计算与通信的深度协同与优化
高度灵活的模型映射与可重构性
SRDA:系统级数据流 +3D 堆叠内存 +I/O 融合 + 极简可重构
与类 GPGPU 架构“控制流”为核心的思想不同,SRDA 架构的设计哲学是将“数据流”置于核心,从数据 I/O 切入,实现从 AI 芯片到 AI 数据中心系统的整体优化。
数据中心系统级数据流:让计算跟着数据跑
AI 计算,尤其是深度神经网络的训练与推理,本质是大规模、并行化的数据在计算节点间依照特定计算图(Computational Graph)进行流动和转换的过程。传统"控制流"架构(Control-Flow Architecture)下,指令的顺序执行和复杂的内存层级访问常常成为性能瓶颈,导致计算单元空转,以及不必要的数据搬运。
SRDA 架构则将“数据流”(Data-Flow)作为第一性原理,通过硬件设计直接映射 AI 计算图中的数据依赖关系。中间数据在经过优化的、可定制的计算路径上,于计算单元之间点到点直接传输,大幅减少了对内存的依赖和访问次数。这种设计理念从根本上减少了数据移动的距离和频率——当前计算系统中主要的性能和能耗瓶颈之一。
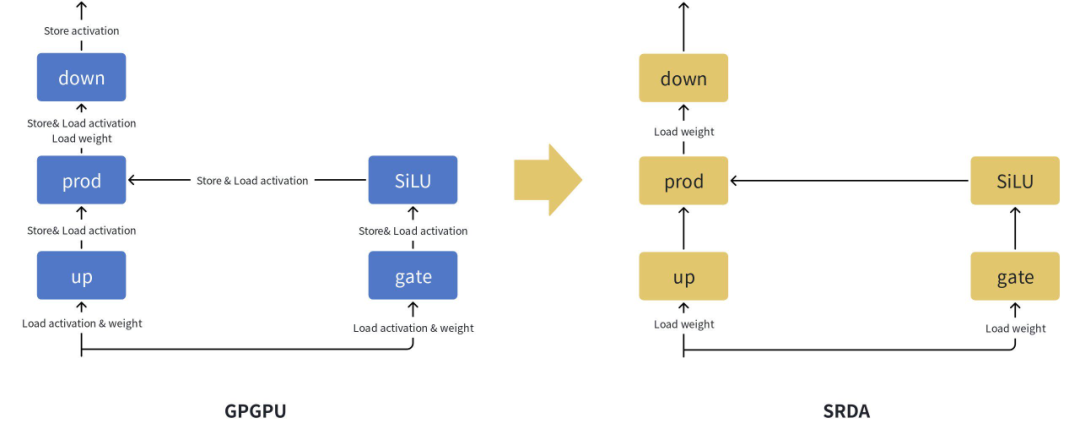
SRDA 还通过 I/O 融合等技术创新,将这种数据流思想不仅应用于芯片,还应用于节点乃至整个集群,实现了系统级的数据流计算范式。
内存架构革命:给每个计算单元配“独享车位”
为彻底攻克内存瓶颈,SRDA 修改整个内存架构,在计算芯片上直接分布式地集成超高带宽、大容量 3D-DRAM 内存,实现内存带宽的极致提升。
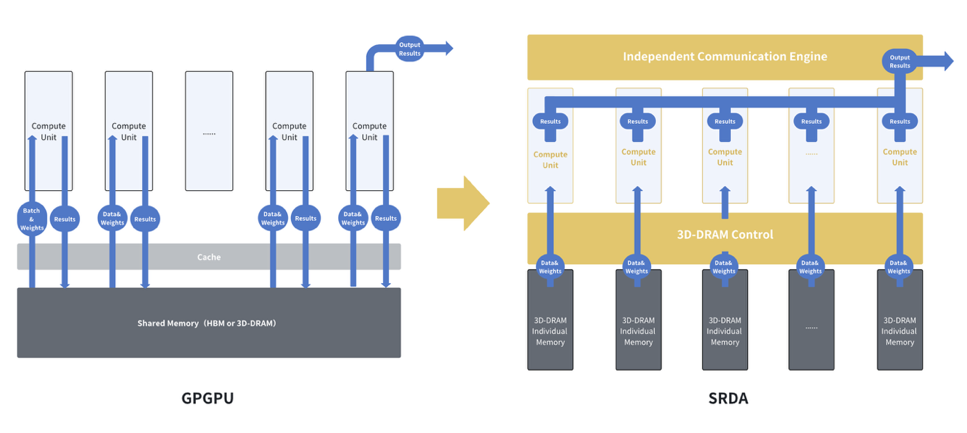
其核心思路的突破在于“计算单元内存私有化”:每个计算核心拥有专属的内存区域,数据访问在本地完成,彻底消除了共享总线和内存竞争导致的拥塞 。这与 GPGPU 架构依赖共享内存、多计算核心并发访问易产生拥塞的模式形成鲜明对比 。
颗粒层面,3D-DRAM 本身可实现远超 HBM 的超高带宽,相关技术上国内也一直领先于海外,是内存方面国产方案弯道超车的好思路,SRDA 架构能充分发挥 3D-DRAM 优势,“SRDA+3D-DRAM”或许有望替代“GPGPU+HBM”成为新的 AI 存算王炸组合。
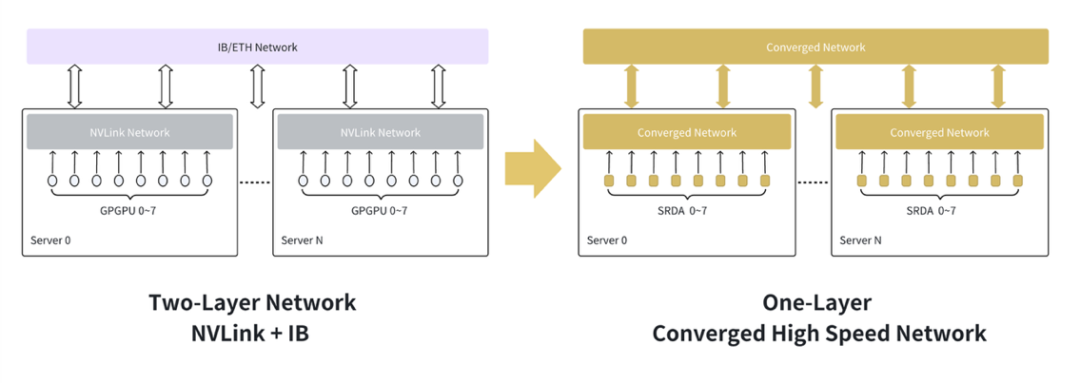
融合互联网络:单层统一,简化集群复杂度
针对传统两层网络的痛点,SRDA 将节点内高速互联(Scale-up)和节点间通信网络(Scale-out)融合成统一的单层网络,显著简化网络拓扑,降低协议转换和管理开销,并能有效减少后端网络端口数量,从而降低部署成本和复杂度。
玉盘将其独有的 I/O 融合互联技术称为 QLink,大有直接超越 NVLink 的意味。
极简可重构:适度灵活,高效开发
可重构性:AI 模型仍在发展(Transformer, MoE, Mamba, DiT, ViT 等),SRDA 允许用户根据模型调整数据流路径、计算单元功能和内存模式,适应未来模型变化。
为 AI 而生 (AI-DSA):SRDA 可重构,但不追求绝对通用(会导致软件栈如 CUDA 般复杂),其剥离通用处理器冗余,聚焦 AI 核心运算,且底层基于开源 RISC-V 指令集,提供简化指令,并降低算子开发难度。
SRDA 为开发者带来的核心价值
SRDA 架构旨在为 AI Infra 和 LLM 开发者带来:
更高有效性能:通过基于 3D-DRAM 的分布式内存解决内存瓶颈,通过融合网络优化通信,通过数据流设计减少搬运,显著提升端到端算力利用率 。
更低成本:提升单卡 / 单节点效率,降低功耗,简化网络和软件栈,从而优化总体拥有成本(TCO)。
更高稳定性:融合网络设计及故障隔离能力也将提升大规模集群的稳定性。
灵活的模型与算法适应性:可重构特性使其能灵活支持不断演进的 AI 模型与算法。
更简单的开发与迁移:由于数据流架构与控制流不同,SRDA 舍弃通用性的同时,也不再需要类 CUDA 那样复杂的软件库。
与 DeepSeek 论文的以点带面不同,玉盘 SRDA 架构白皮书提出了相对完整的架构方案,特别是对 I/O 瓶颈的针对性设计,为 AI 算力芯片的发展路径提供了系统性的思路。
对身处 AI 浪潮之中的开发者而言,SRDA 所倡导的系统级数据流的理念和技术路径值得关注,近期我们确实也开始频繁看见“数据流”思想。或许在不久的将来,我们就会看到包括玉盘在内的更多 AI 芯片公司开始采用类 SRDA 架构。
更多有关《SRDA 计算架构白皮书》的细节可见:https://github.com/moonquest-ai/SRDA/tree/main




