
Uber Eats 推出 INCA(INventory and CAtalog),一个用于 Uber 全球平台的可扩展的目录系统,用来管理来自超市、药店和其他零售合作伙伴庞大且多样化的商品库存。INCA 打破了 Uber Eats 最初以餐厅为中心的架构的局限性。最初的架构针对的是低 SKU 数量和直接传递式目录管理,无法满足零售环境中对规模、元数据复杂性和合规性的要求。
INCA 每天处理数十亿次目录变更,旨在近乎实时地更新产品数据,确保价格或可用性等关键信息的延迟时间低于一分钟。它将数据的摄取、填充、发布和索引管道统一起来,确保用户能够在 Uber Eats 的应用程序中看到准确且最新的产品。
Uber Eats 的工程师将零售目录管理描述为一个“模糊且复杂的问题空间”。产品数据可能会被摄取,但其可用性可能会因下游因素而发生改变,这些因素会影响商品是否以及如何呈现给客户。QCon 的一场演讲和一篇关于优化搜索系统的文章讨论了管理商品杂货和零售库存所面临的一些挑战,包括搜索优化和相关性问题。
数据模型采用了通用的“实体 + 扩展”结构,能够灵活地表示各种属性,例如营养成分信息、合规标签或商店营业时间等。它还支持零售商提供的 ID 和内部 UUID,从而减少了在标识符更改时可能出现的重复或产品不匹配问题。
模型的核心是项,也称为“销售产品”,代表正在销售的产品,包括价格、可用性和数量。项与零售商、目录部分和履行选项进行了链接,并与一个详细描述其属性(例如营养信息、尺寸和费用等)的产品相关连。
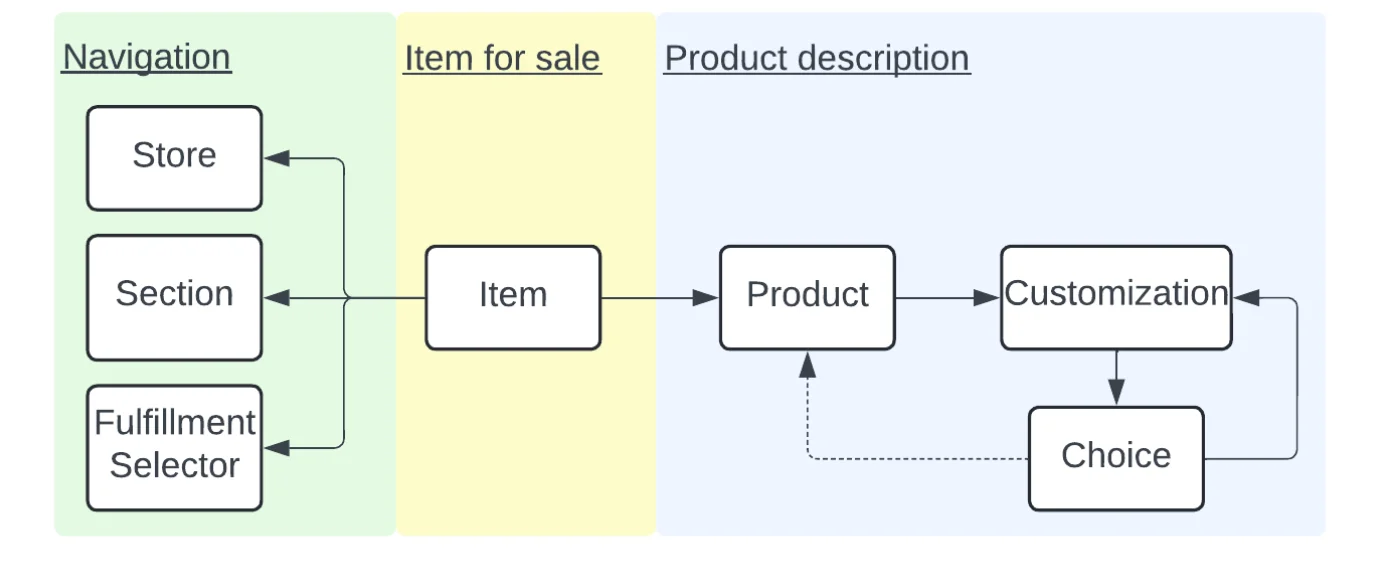
INCA 目录模型(来源:Uber 工程博客)
INCA 的架构遵循六个核心原则:无限可扩展性;无需重新设计架构即可添加新属性;针对商家、地区或产品类型配置智能规则;在发布前填充产品数据;以分类驱动的目录结构;以及支持推送和拉取 API、节流和容错的弹性摄取。
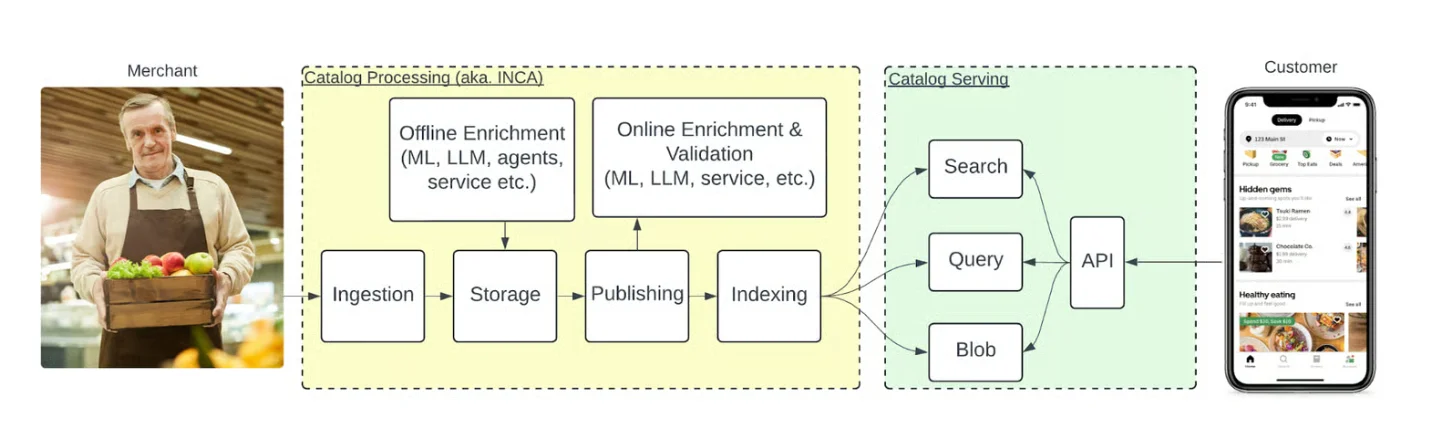
端到端目录流程(来源:Uber 工程博客)
目录摄取支持多种集成模式,可以通过 SFTP 上传 CSV 文件,也可以通过 Starlark 脚本进行灵活的属性转换。通过 Cadence 工作流实现了容错摄取协调,支持增量和全目录同步。在发布时系统会依据优先级排序的合并规范,从多个来源中挑选出最佳属性。在发布过程中会运行在线填充器和验证器,以丰富数据度并验证其准确性。
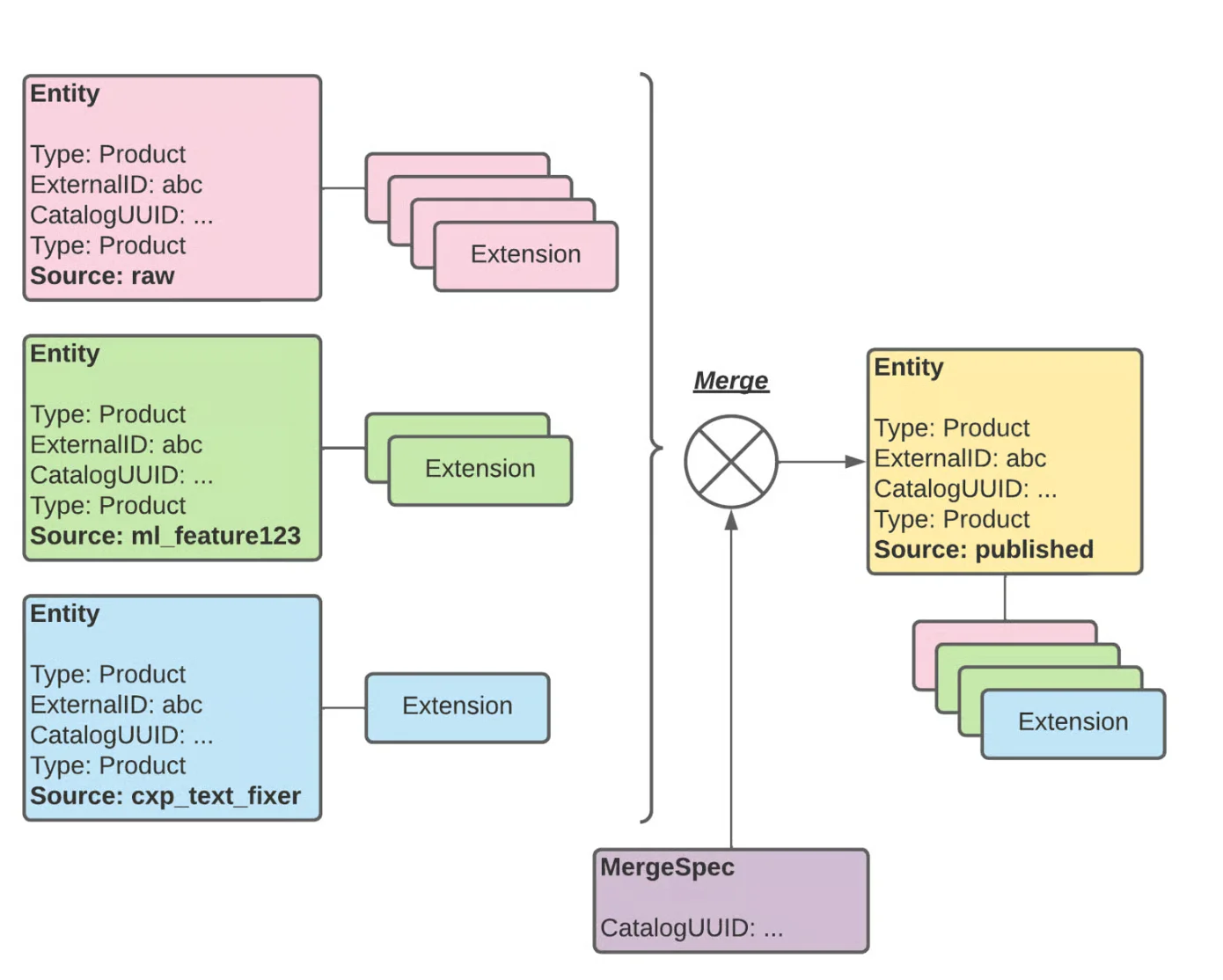
INCA 中使用的基于实体和扩展的数据模型(来源:Uber 工程博客)
数据填充服务使用 LLM 生成的描述、分类、规范链接和合规性检查来丰富原始产品数据。回归检测会监控异常情况,例如大量 SKU 下架、定价归零或通道移除,帮助团队在问题影响到客户之前迅速发现并解决问题。
INCA 管理着数亿个非餐厅类别的 SKU,为 Uber Eats 的零售目录提供结构化、丰富且易于发现的产品数据。目录版本控制功能支持在全球和单店级别近乎即时地回滚更新,使团队能够在不影响客户体验的前提下,迅速从错误或异常中恢复。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
原文链接:
https://www.infoq.com/news/2025/08/ubereats-inca-inventory-catalog/




