
3 月 4 日消息,中国大模型创业公司阶跃星辰继开源 Step 3.5 Flash 模型后,又开源了这款 Agent 基座模型的预训练权重(Base)、中训练权重(Midtrain)以及配套的 Steptron 训练框架。
Base 权重:https://huggingface.co/stepfun-ai/Step-3.5-Flash-Base
Midtrain 权重:https://huggingface.co/stepfun-ai/Step-3.5-Flash-Base-Midtrain
Steptron 训练框架:https://github.com/stepfun-ai/SteptronOss
Step 3.5 Flash 是阶跃星辰目前性能最强、效率最高的开源基座模型。其核心优势在于对混合专家架构(Mixture of Experts, MoE)的极致压榨。
11B vs 196B: 该模型总参数量高达 1960 亿,但在处理每个标语(token)时,系统会根据任务属性动态、选择性地仅激活其中 110 亿 参数。
智能密度(Intelligence Density): 这种稀疏架构让 Step 3.5 Flash 拥有了抗衡顶级闭源模型(如 GPT-4.5 或 Claude 4)的推理深度,同时保持了毫秒级实时交互的“轻盈感”。
不同于传统的聊天机器人,Step 3.5 Flash 的设计初衷是成为智能体的“大脑”。为了解决智能体在复杂推理中的性能瓶颈,阶跃星辰引入了多项前沿技术:
首先是 MTP-3。极速深度推理传统的模型更擅长“阅读”,而智能体需要“思考”。Step 3.5 Flash 搭载了三路多标语预测(MTP-3)技术。
性能表现: 在典型使用场景下,生成吞吐量稳定在 100–300 tok/s。
峰值体验: 在单流编程任务中,峰值可达 350 tok/s,让多步推理链的响应几乎无需等待。
其次是混合注意力机制:高效处理 256K 长上下文。针对长代码库和海量文档,模型采用了 3:1 的滑动窗口注意力(SWA)配比。
结构优化: 每三层 SWA 层对应一层全量注意力层,大幅降低了计算开销。
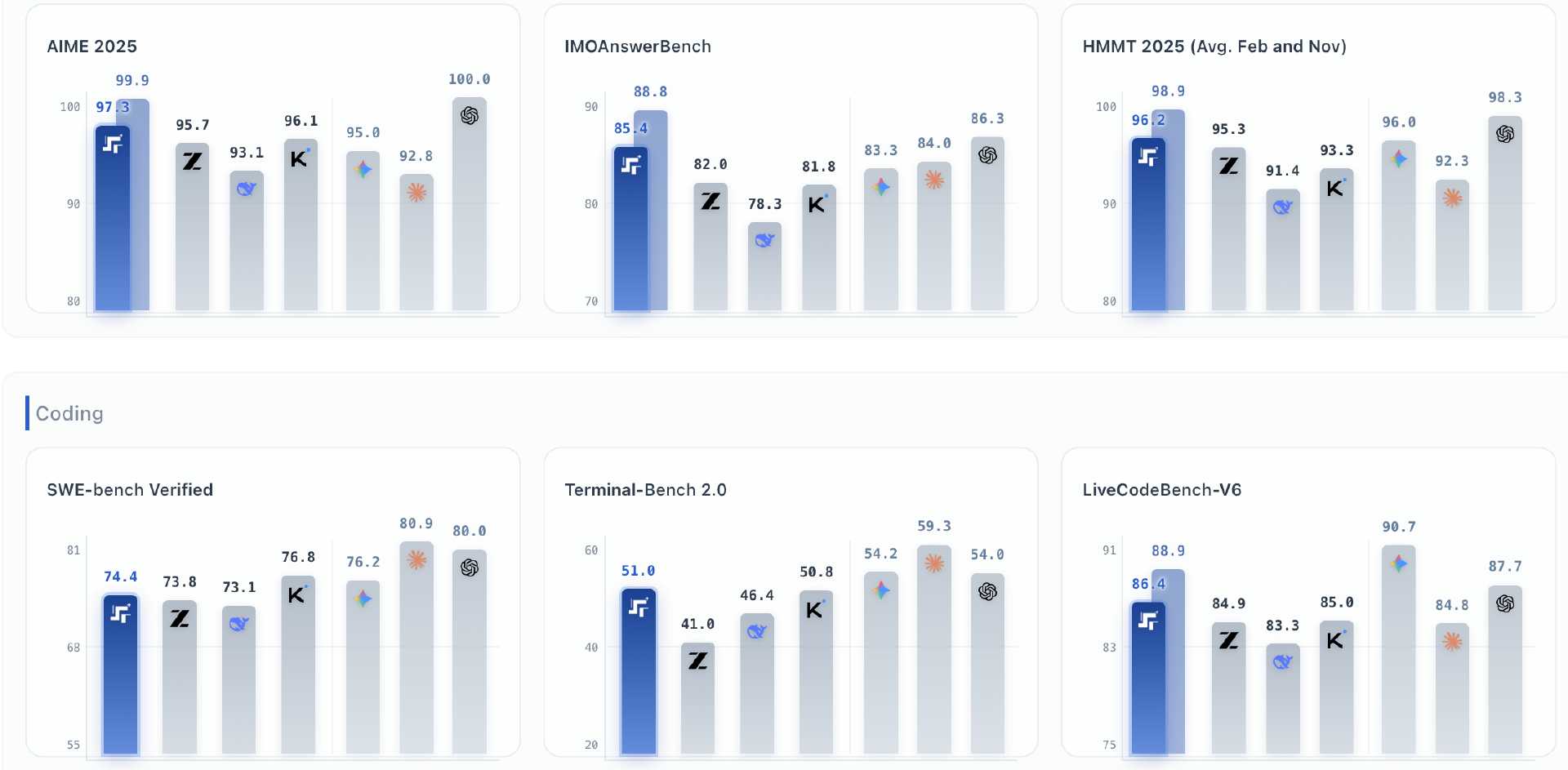
实测数据: 在 SWE-bench Verified 评测中取得 74.4% 的佳绩,在 Terminal-Bench 2.0 中获得 51.0%,证明了其在长程任务中的极高稳定性。
此外,强大的编程与智能体引擎也是一大技术亮点。Step 3.5 Flash 专为智能体任务打造,集成了可扩展的强化学习(RL)框架,从而驱动模型持续自我进化。它在 SWE-bench Verified 测试中取得了 74.4% 的成绩,在 Terminal-Bench 2.0 中得分 51.0%,充分证明了其在处理复杂、长程任务时拥有坚如磐石的稳定性。
Step 3.5 Flash 针对可访问性进行了深度优化,将顶尖的智能带入本地环境。它可以在高端消费级硬件(如 Mac Studio M4 Max、NVIDIA DGX Spark 等)上安全运行。这意味着用户无需牺牲性能,即可在本地掌控数据隐私。
此次发布最令开发者兴奋的莫过于 Steptron 训练框架 的开源。
过去,开源模型往往只给结果,不给过程。阶跃星辰此次放出了从 Base 到 Midtrain 的全过程权重和框架,意味着开发者可以基于 Steptron,利用自有的私有数据,按照阶跃星辰的标准路径进行精准微调。这种“可复现性”将极大地降低企业构建垂直领域专用智能体的门槛。
这一举动在当前大模型开源趋于保守的环境下,显得颇为彻底,在开源社区引发热烈反响。
(图:开源社区反响热烈)
在开发者社区和实际应用中,Step 3.5 Flash 已经迅速获得了市场验证。截至目前,这款模型在 Hugging Face 上下载量已超 30 万次,并登上 OpenRouter Trending 第一名,获得了较高的社区认可度。而在知名开源项目 OpenClaw(被中国网友称为“小龙虾”)上,该模型排名已升至前二。这些成绩反映出模型在速度、稳定性和 Agent 适配性上的真实竞争力。
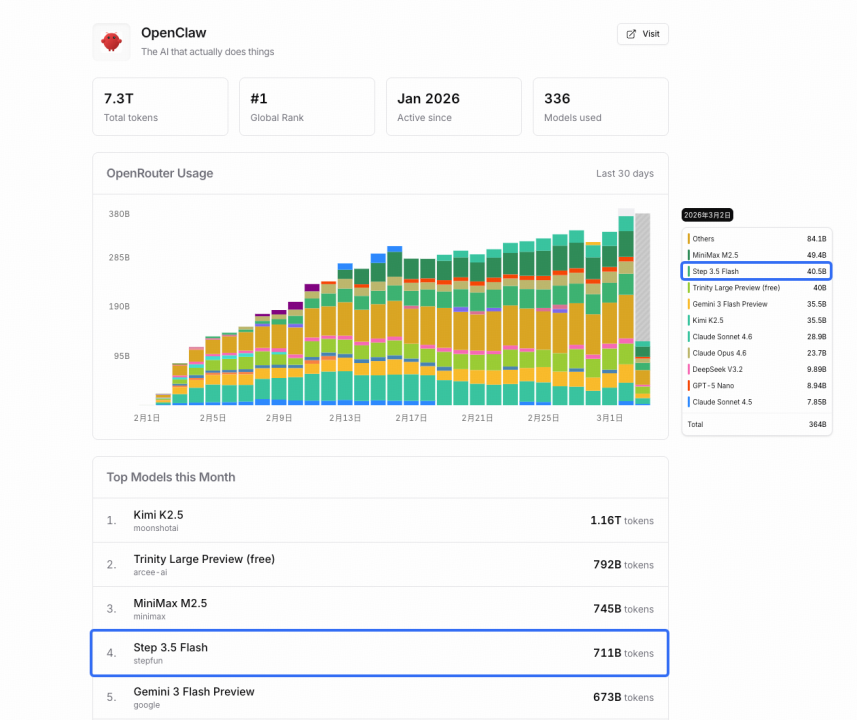
(图:OpenClaw 调用量模型排名)
随着 OpenClaw 等 Agent 平台热度持续升温,Step 3.5 Flash 的开源或将进一步加速中国模型在全球 Agent 生态中的渗透。




