
在构建企业级 AI Agent 的路上,几乎每个团队都会经历一个从兴奋到痛苦的转折点——当接入的工具数量从几十个激增至上千个,“调用灾难”便不期而至。我们的团队正深陷其中。
这不仅是技术挑战,更是一场关乎架构、流程和团队协作的“系统性危机”。这篇文章,并非一份高高在上的“终极指南”,而是一次彻底的、毫无保留的思考与设计复盘。我们希望与你分享我们如何从当前的“泥潭”出发,一步步设计出未来出路的完整历程:
我们正在走的弯路: 深入剖析我们当前在用的“路由模型”,以及它如何将我们拖入“治理噩梦”。
我们的顿悟时刻: 在研究 MCP Registry 时,我们如何意识到“代码即治理”的契合,并决定进行一次架构范式的转移设计。
我们的新蓝图: 我们将提供一套从零设计的、端到端的自动化工作流的完整架构和可行性验证(PoC)代码,并解释其中的每一个技术决策。
在 AI Agent 的工程化领域,我们都还是学习者。希望这次深度的分享,能为你提供一个有价值的参考案例,更期待能与正在这条路上探索的各位朋友,进行一场坦诚的技术交流。
共同的起点——当“千具之灾”成为日常
项目的初期总是美好的。每当业务部门接入一个新的 API,我们将其封装成工具,Agent 的能力就增强一分。但当工具数量突破三位数时,警报开始拉响。我们目前面临的具体问题是:
1. 上下文的“爆仓”: 将上千个工具的 Schema 全部注入上下文,即使是像 GPT-5、Gemini 2.5 Pro、Claude 4 Opus 这样拥有超长上下文窗口的模型,也显得捉襟见肘。更重要的是,这会产生巨量的 Token 消耗,成本难以控制。
2. LLM 的“决策瘫痪”: 我们发现,当选项过多时,LLM 的推理能力会显著下降。它就像一个站在巨大菜单前不知所措的顾客,要么选择困难,要么干脆选错,幻觉(Hallucination)和调用失败的概率直线上升。
这就是我们内部戏称的“千具之灾”(The Thousand-Tool Disaster)。很明显,必须找到一种方法,在请求到达主 LLM 之前,就将工具的选择范围从 N(>1000)缩小到一个极小的可行域 K(我们期望 K≤5)。
我们正在走的路:路由模型的尝试与“治理噩梦”
社区的主流思路给了我们第一个灵感:路由模型(Router Model)。这也是我们目前线上在用的 V1 版本解决方案。
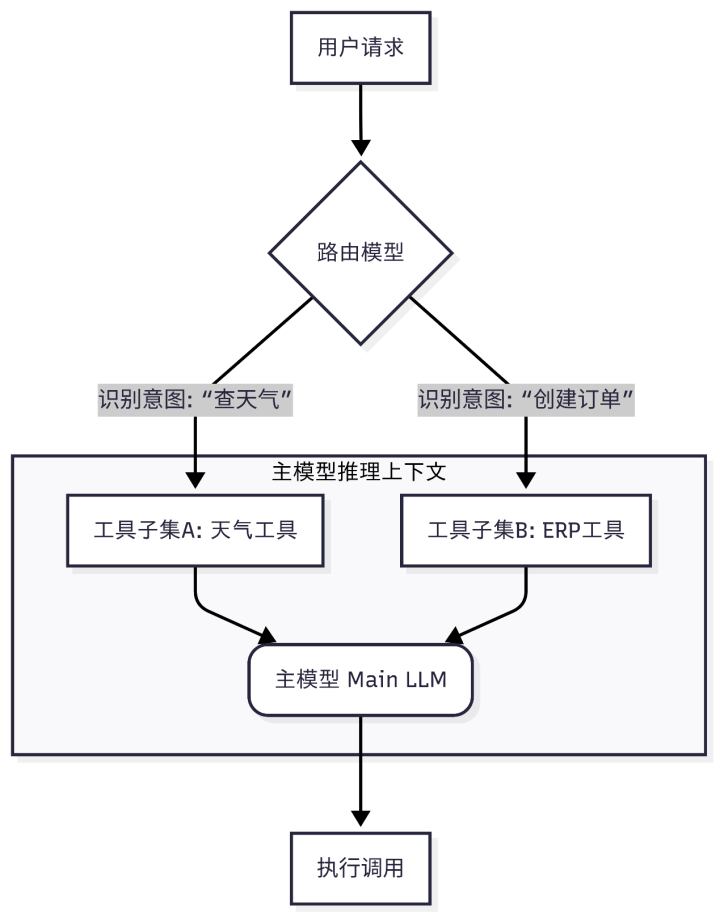
图:架构图示 1 -路由模型的“战术性胜利”与“战略性失败”
这个方案的核心,是在主 LLM 前增加一个更小、更快的模型。它的任务很简单:根据用户意图,从一个预先定义好的、巨大的工具清单中,挑出几个最可能用到的工具。
初期的效果是喜人的:主 LLM 的上下文干净了,调用成功率也上去了。但随着时间的推移,这个方案的“维护成本”开始以指数级增长,一个新的“治理噩梦”开始了,并且至今仍在困扰我们:
配置文件的“中央集权”: 我们用一个巨大的 JSON 文件来管理人机路由规则和工具子集。这个文件成了整个系统的“阿喀琉斯之踵”。每次业务方上线一个新工具、修改一个工具签名、或者下线一个旧工具,都必须通知我们 AI 平台团队,由我们手动去更新这个 JSON。这完全违背了我们追求的“敏捷”和“去中心化”原则。
沟通成本的剧增: 为了更新那个“神圣”的 JSON 文件,跨团队的沟通会议、审批流程变得越来越频繁。我们甚至遇到过,因为一个工具参数描述的微小改动没有及时同步,导致线上 Agent 连续报错几个小时的事故。
知识的“孤岛化”: 工具的唯一“户籍”,竟然是那个由少数人维护的 JSON 文件。新来的工程师想了解公司有哪些可用的 AI 能力,居然要去“考古”这个文件,而不是一个统一、公开的平台。
我们深刻地意识到,一个需要在运行时依赖大量人工配置和跨团队沟通的系统,是脆弱且不可扩展的。我们治愈了运行时的“头痛”,却引发了架构和流程上的“系统性红斑狼狼疮”。 这促使我们必须寻找一条全新的道路。
一次顿悟:MCP Registry,从“配置”到“契约”的架构新思路
在一次技术调研中,我们了解到了新开源的 MCP Registry。起初我们以为这只是又一个“工具商店”,但深入研究其 server.json 的 Schema 后,我们有了一种“顿悟”的感觉。
我们意识到,server.json 的价值,远不止于描述一个工具。它是一份“代码即治理”(Governance as Code)的契约。这份契约由工具的“所有者”(业务团队)在发布时亲手签署,并由 Registry 这个“公证处”进行验证和存档。
所有权契约(“name”): com.mycompany.crm/这个命名空间,通过 DNS 验证,确保了只有 CRM 团队的 CI/CD 流水线能在此发布。权责一下子就清晰了。
生命周期契约(“status): “status:”“deprecated”这个简单的字段,意味着业务团队在发布新版本时,就已通过代码明确宣告了旧版本的“死亡”。下游的任何系统都可以自动地、无争议地执行“葬礼”。
依赖安全契约(“environment_variables”): 工具不再需要在文档里告诉我们它需要什么 API Key。它通过这份契约直接“声明”其依赖。我们的执行器(Executor)可以像管家一样,按这份“清单”去密钥管理系统(如 Vault)里取东西,安全且自动化。
这次思维的转变是根本性的:我们不再需要一个中心化的团队去“配置”和“管理”所有的工具,而是让每个工具的发布者,通过一份标准化的契约,对自己工具的整个生命周期负责。Registry 则成为了这个去中心化协作体系的“单一事实来源”。
我们的新蓝图:一个全自动化的协同架构设计
基于“契约”思想,我们重新设计了我们的 AI Agent 工具调用架构。这是我们为走出当前困境所规划的演进方向。

图:架构图示 2 - Registry 驱动的自动化路由协同架构
这个新蓝图的核心思想是“关注点分离”与“自动化连接”:
1. 治理平面: 开发者唯一需要关心的就是写好自己的工具,并提供一份准确的 server.json 契约。然后 mcp-publisher publish,任务完成。
2. 自动化平面: 我们构建一个独立的、无人值守的同步服务。它像一个勤奋的图书管理员,不知疲倦地从 Registry 这个“总书库”同步最新的“图书目录”,并为之建立智能索引(向量化)。
3. 运行平面: Agent 在运行时,不再依赖任何静态配置。它的路由层变成了一个聪明的“图书检索员”,根据用户的需求,实时地去索引库里,用语义搜索的方式,找出最匹配的那几本书(工具)。
这个架构设计的精妙之处在于它将具备“自愈合”和“自演进”能力。一个工具的发布、更新、下线,都能自动地、无缝地传递到运行时的每一个 Agent,真正实现了“一次发布,处处生效”。
将蓝图变为现实:一份可行的 PoC 与逻辑示意
为了验证这套蓝图的可行性,我们构建了一个核心的概念验证(PoC)原型。以下代码展示了其关键逻辑,证明了这套自动化管道是完全可以实现的。
工具同步与索引服务(PoC)
Python# tool_synchronizer.pyimport requestsimport scheduleimport timeimport jsonimport loggingfrom sentence_transformers import SentenceTransformerimport chromadb# --- Configuration ---REGISTRY_API_ENDPOINT = "http://localhost:8080/v0/servers"CHROMA_DB_PATH = "./tooldb_prod"EMBEDDING_MODEL = 'bge-large-zh-v1.5' # 强大的中英双语Embedding模型SYNC_INTERVAL_MINUTES = 5# --- Setup ---logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')client = chromadb.PersistentClient(path=CHROMA_DB_PATH)model = SentenceTransformer(EMBEDDING_MODEL)collection = client.get_or_create_collection(name="mcp_tools_prod")def fetch_tools_from_registry(): """从MCP Registry获取所有服务定义。""" try: response = requests.get(REGISTRY_API_ENDPOINT, timeout=10) response.raise_for_status() return response.json() except requests.RequestException as e: logging.error(f"从Registry获取失败: {e}") return Nonedef process_and_index_tools(servers): """处理工具元数据,并将其向量化索引,实现幂等同步。""" if not servers: logging.warning("无服务可处理。") return active_tools = {s['meta']['uuid']: s for s in servers if s.get('status') == 'active'} logging.info(f"发现 {len(active_tools)} 个活跃工具待处理。") # --- 1. 准备Upsert数据 --- ids_to_upsert = list(active_tools.keys()) if not ids_to_upsert: logging.info("没有活跃的工具需要更新或插入。") else: documents_to_upsert = [] metadatas_to_upsert = [] for uuid, tool in active_tools.items(): # Pro-Tip: Embedding的文本质量直接决定检索效果。 # 融合工具名、描述和关键参数,能极大提升语义表达的丰富度。 param_names = "" # Safely access parameters which might not exist if 'packages' in tool and tool['packages']: params = tool['packages'][0].get('parameters', []) if params: param_names = ", ".join([p.get('name', '') for p in params]) searchable_text = f"工具名: {tool.get('name', '')}; 功能描述: {tool.get('description', '')}; 参数: {param_names}" documents_to_upsert.append(searchable_text) metadatas_to_upsert.append({ "name": tool.get('name', ''), "version": tool.get('version', ''), "schema_json": json.dumps(tool) # 存储完整定义,供后续LLM使用 }) # --- 2. 执行幂等的Upsert操作 --- collection.upsert( ids=ids_to_upsert, documents=documents_to_upsert, metadatas=metadatas_to_upsert ) logging.info(f"成功Upsert {len(ids_to_upsert)} 个工具到向量库。") # --- 3. 处理删除项,保持数据一致性 --- existing_ids_in_db = set(collection.get(include=[])['ids']) active_ids_from_registry = set(active_tools.keys()) ids_to_delete = list(existing_ids_in_db - active_ids_from_registry) if ids_to_delete: collection.delete(ids=ids_to_delete) logging.info(f"从向量库中删除 {len(ids_to_delete)} 个过时工具。")def sync_job(): """同步任务的主函数。""" logging.info("开始同步任务...") servers_data = fetch_tools_from_registry() if servers_data and 'servers' in servers_data: process_and_index_tools(servers_data['servers']) logging.info("同步任务完成。")if __name__ == "__main__": sync_job() # 启动时立即执行一次 schedule.every(SYNC_INTERVAL_MINUTES).minutes.do(sync_job) logging.info(f"调度器已启动,每 {SYNC_INTERVAL_MINUTES} 分钟同步一次。") while True: schedule.run_pending() time.sleep(1)这是 Agent 在接收到用户请求后,进行实时工具筛选的模块。
Agent 实时工具路由器(PoC)
Python# Part of agent_runtime.pyimport chromadbfrom sentence_transformers import SentenceTransformerimport jsonclass ToolRouter: def __init__(self, chroma_client, embedding_model, top_k=3): self.client = chroma_client self.collection = self.client.get_collection(name="mcp_tools_prod") self.model = embedding_model self.top_k = top_k def route(self, user_query: str) -> list[dict]: """根据用户查询,从向量库中检索最相关的K个工具的完整Schema。""" # Ensure embeddings are normalized for cosine similarity searches query_embedding = self.model.encode(user_query, normalize_embeddings=True).tolist() results = self.collection.query( query_embeddings=[query_embedding], n_results=self.top_k, ) if not results['metadatas'] or not results['metadatas'][0]: return [] retrieved_tools_schemas = [json.loads(meta['schema_json']) for meta in results['metadatas'][0]] return retrieved_tools_schemas# --- 在Agent中的集成示例 ---# 假设已有main_llm客户端,如OpenAI()# from openai import OpenAI# main_llm = OpenAI(api_key="...")def execute_agent_task(user_query: str, tool_router: ToolRouter): # 1. 路由(Route):动态筛选工具,上下文窗口永远轻量 print(f"Routing for query: '{user_query}'") relevant_tool_schemas = tool_router.route(user_query) if not relevant_tool_schemas: print("No relevant tools found.") # Handle case with no tools, maybe a direct LLM call without tools return print(f"Found {len(relevant_tool_schemas)} relevant tools: {[tool['name'] for tool in relevant_tool_schemas]}") # 2. 推理(Reason):将筛选后的工具注入主LLM进行决策 # response = main_llm.chat.completions.create( # model="claude-3-opus-20240229", # Or GPT-4o # messages=[{"role": "user", "content": user_query}], # tools=relevant_tool_schemas, # tool_choice={"type": "auto"} # ) # 3. 执行(Execute):通过安全执行器调用LLM选择的工具 # ...后续的tool_calls处理逻辑... print("Agent would now reason with the main LLM using the filtered tools.")进阶思考与我们仍在探索的问题
这套架构设计解决了我们最头疼的治理问题,但也引发了我们更深层次的思考。这部分内容还未完全成熟,更像是我们团队内部的技术探讨,希望能激发大家的兴趣。
混合路由的必要性: 我们发现,当用户说“用‘财务系统’的‘发票创建工具’给我开一张发票”时,纯语义搜索有时反而会因为“发票”这个词,召回一些不相干的报销工具。因此,我们正在设计一套混合路由策略:优先进行基于 name 的精确匹配(规则引擎),如果失败,再启用语义搜索。
版本控制的艺术: 当一个工具同时存在 v1.1 和 v1.2-beta 时,同步服务应该索引哪一个?我们目前的简单策略是只索引不带预发布标签的最高版本。但更理想的方案,或许是允许 Agent 在运行时,根据用户身份或请求头,动态选择灰度版本。
安全性的最后一道防线: Registry 解决了“治理”层面的权限,但运行时的“调用”权限是它的盲区。我们坚信,这部分工作必须交给 API 网关。我们的最终目标是,Agent 的 Executor 在调用工具时,会携带用户的 JWT,由 API 网关根据用户的角色和工具的权限策略,做最终的“Go/No-Go”决策。
结语
从当前的混乱,到对未来有序架构的清晰构想,我们最大的收获是完成了一次思维模式的转变:从疲于应付运行时的各种“补丁”,转向构建一个具备自我治理能力的、基于“契约”的架构体系。
我们分享的这套架构蓝图,是在我们特定业务场景下,一个我们认为能够平衡效率、稳定性和扩展性的解法。它必然不是终点。例如,如何将工具的调用成功率、耗时等运行时数据,反向注入到路由层的排序算法中,形成一个动态的、自优化的闭环?这是我们非常着迷,且正在探索的下一个方向。
AI Agent 的工程化浪潮才刚刚开始,我们每个人都身处其中。希望我们的这段经历能为你带来启发。如果你有任何疑问、建议,或是有更好的思路,我们非常期待能听到你的声音,共同探索这片充满机遇的领域。
作者简介:
仇智慧,搜狐视频高级工程师,长期关注大语言模型、AI Agent 技术在企业中的应用落地。




