
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
观察你的 Cortex Agent 集群
使用 Snowflake Intelligence 的团队往往行动很快。Cortex Agents 可以快速且无缝地构建,不知不觉间,你就已经有一个集群在不同领域和业务职能中投入生产运行。
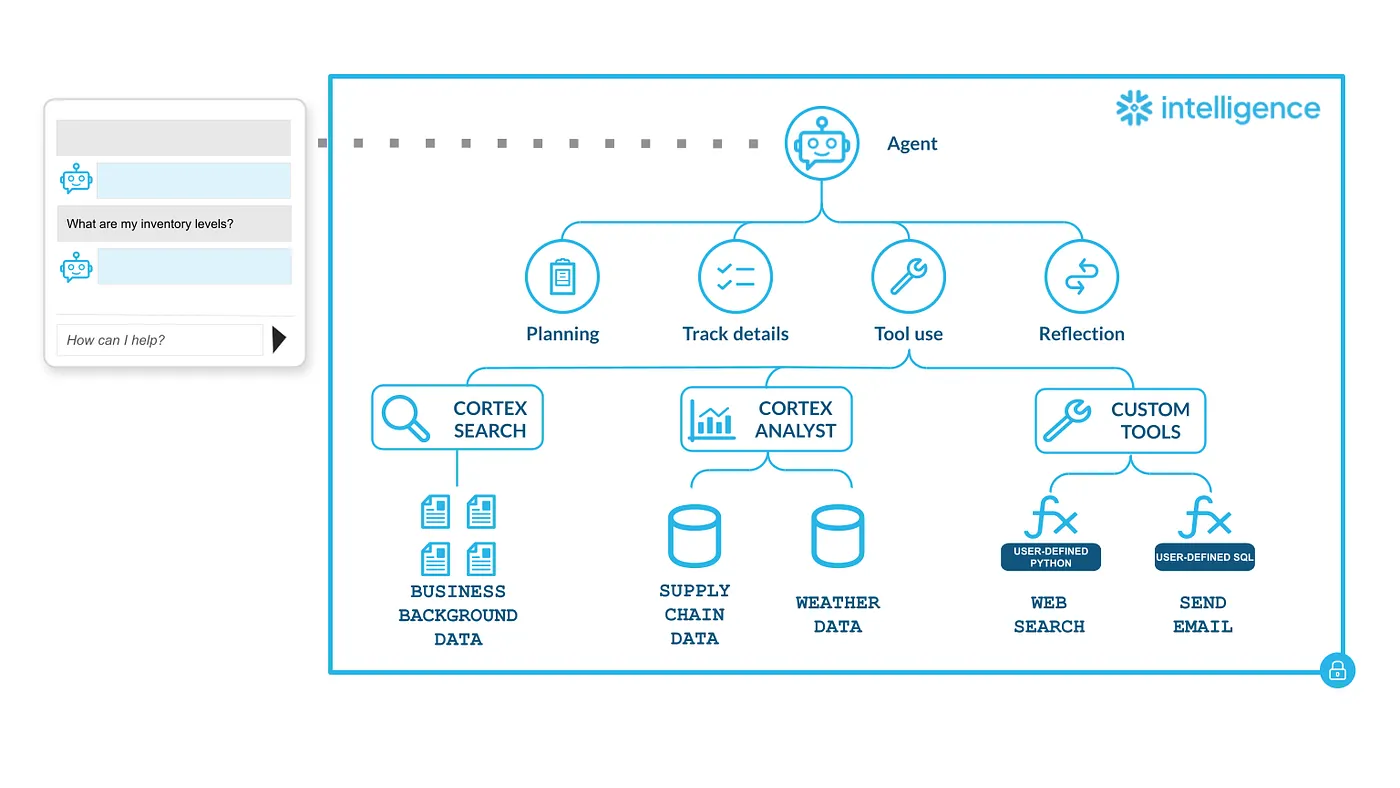
Snowflake Intelligence 架构
部署 agents 是一种赋能体验。然而,理解和评估它们的性能可能是另一回事。监控错误率、延迟、token 消耗等健康功能指标,以及新鲜度和数量等质量指标,是任何生产系统的基本要求;agents 也不例外。
Snowflake Intelligence 为团队回答这些重要问题提供了所需的基础。它会原生记录丰富的 trace 数据——对话历史、工具执行、LLM 规划、响应生成。
挑战在于如何以具有运营实用性的方式呈现这些数据,而不是每次都要针对可观测性表编写 SQL。
可以把它看作一条成熟曲线。
一开始,你可能只是通过查询 agent 错误率或其他性能指标来获取某个时点的快照。随着不断推进,你会开始构建和维护仪表板,然后使用异常检测模型监控这些仪表板趋势,以识别离群值和 SLA 违约。最终,你可以主动识别导致“边缘案例”的系统性问题,并实施事件管理流程,以维持生产级 SLA。
要沿着这条成熟曲线不断升级,需要深入理解 agent telemetry,以及它如何被观察、分析,并最终用于排查 Agentic 故障。
我们将在本文中探讨这些主题,逐步介绍 Snowflake 如何记录 Cortex Agent telemetry,以及 agent 可观测性解决方案如何帮助监控并修复常见的性能故障模式。agent 可靠性的其他关键方面,包括上下文(数据质量)、轨迹(工具调用)和输出,将留待以后讨论。
Snowflake 为 Cortex Agents 记录了什么:深入底层一探究竟
在设置任何监控之前,值得先理解 Snowflake Intelligence 生成的 trace 结构。
每一次 Cortex Agent 交互都由一个 spans 层级结构组成,每个 span 代表 agent 操作的不同阶段。Snowflake 将这些 trace 数据存储在原生可观测性表中,可以通过一个名为 SNOWFLAKE.LOCAL.GET_AI_OBSERVABILITY_EVENTS 的表函数访问,该函数可以直接在 Snowflake SQL worksheet 中调用。
例如,Monte Carlo 在底层运行、用于支持我们 agent 性能监控的查询如下。这个查询值得仔细看一看,因为它准确揭示了 Snowflake 在 span 级别记录了什么:
SELECT * FROM TABLE( SNOWFLAKE.LOCAL.GET_AI_OBSERVABILITY_EVENTS( 'YOUR_DATABASE', 'YOUR_SCHEMA', 'YOUR_AGENT_NAME', 'CORTEX AGENT' ))WHERE RECORD_TYPE = 'SPAN' AND RECORD:name::STRING NOT LIKE 'SqlExecution_%'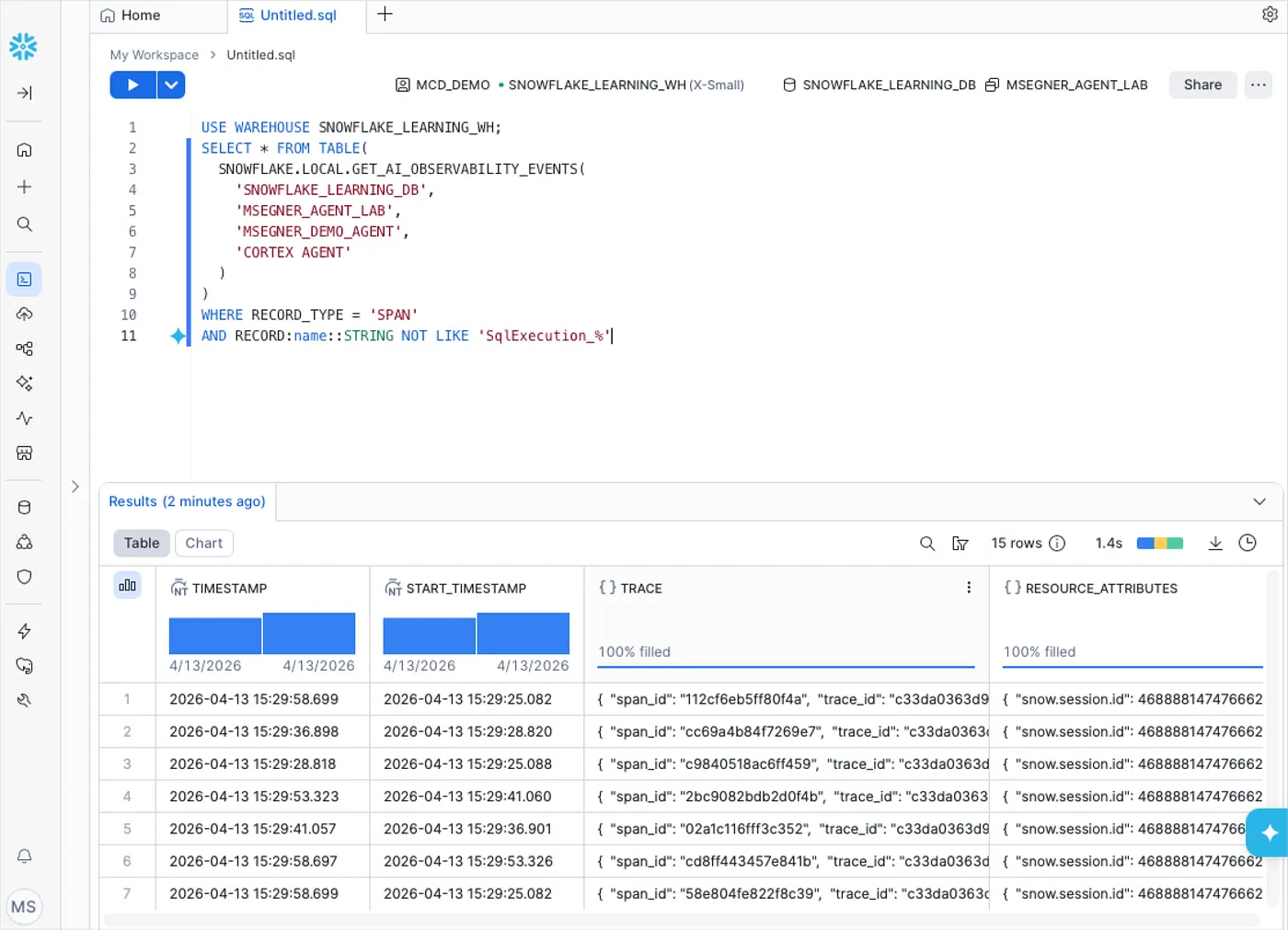
在 Snowflake 中对 “MSegner_Demo_Agent” 运行 Get_AI_Observability_Events 查询
这里有意过滤掉了 SqlExecution_* spans,因为它们代表 Cortex Analyst 触发的实际 SQL 运行,如果包含在 agent 级指标中,往往会产生噪声。将它们移除后,剩下的就是 agent 行为 trace。
将 records 映射到 span 类型
每个 span 都有一个 record_name,用于标识其 span 类型。
这些元数据对于理解每个 record_name 在 agent 行为中实际代表什么至关重要,也正是它让 trace 数据变得可操作。如果没有这种映射,你看到的只是一串晦涩字符串组成的扁平列表,无法清楚判断 agent 操作中的哪个环节出了问题。
它们与 agent 操作的映射关系如下:
CASE WHEN record_name = 'AgentV2RequestResponseInfo' THEN 'chat' WHEN record_name LIKE 'ReasoningAgentStepPlanning-%' THEN 'planning' WHEN record_name LIKE 'ReasoningAgentStepResponseGeneration-%' THEN 'response_generation' WHEN record_name LIKE 'CortexSearchService_%' THEN 'tool_call' WHEN record_name LIKE 'CortexAnalystTool_%' THEN 'tool_call' ELSE 'unknown'END AS request_type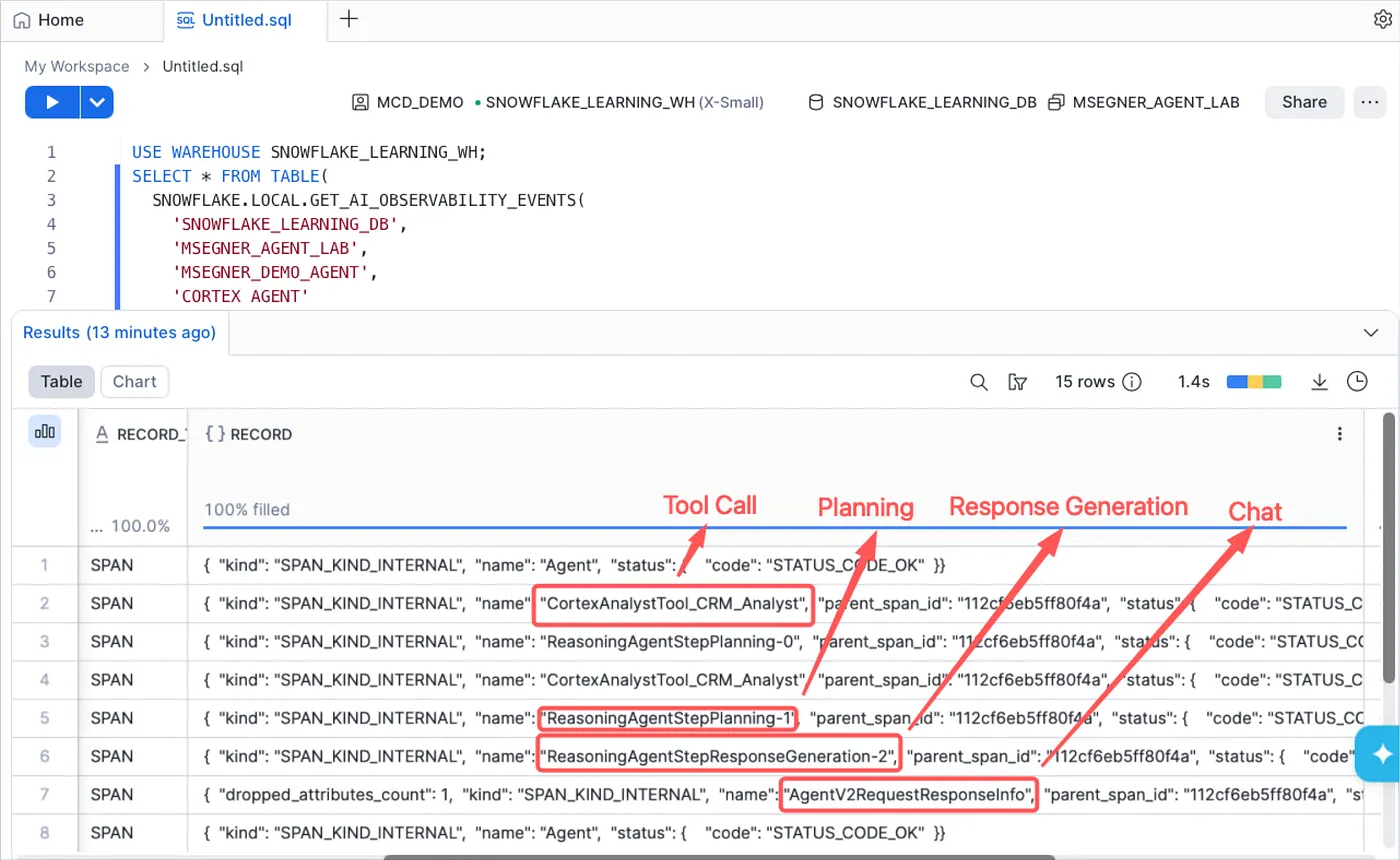
Snowflake 中的 Agent telemetry,record_name
每种 span 类型代表什么:
- chat:完整对话轮次的顶层 span。AgentV2RequestResponseInfo 是最外层封装:它捕获单次用户交互的完整输入和输出,以及将多轮对话关联在一起的 thread_id;
- planning:ReasoningAgentStepPlanning spans 捕获 agent 的决策过程:下一步调用哪个工具、制定什么查询、传递什么上下文。每个 planning step 都会在 RECORD_ATTRIBUTES 中记录自己的 token 数量、模型名称和工具选择;
- response_generation:ReasoningAgentStepResponseGeneration spans 捕获最终答案合成过程。此时 agent 已经完成工具调用,正在生成响应。这里的 token 数量反映最终 LLM 调用的成本;
- tool_call:两类工具会使用不同的属性 schema 记录,包括:
CortexSearchService_*spans 记录搜索查询、请求的列、应用的筛选器、结果限制、返回结果和状态;CortexAnalystTool_*spans 记录传入的 messages、使用的 semantic model、生成的 SQL 查询、文本响应,以及——尤其值得注意的是——一个question_category字段,用于分类 Cortex Analyst 收到的问题类型。
关于 question_category 字段,Cortex Analyst 会自动对问题进行分类,并且该分类可在 trace 数据中观察到。类别可能包括简单查找、聚合、时间序列查询和比较分析等。
如果你发现某个特定 agent 出现 token 峰值或延迟增加,按 question_category 筛选 traces 可以快速显示该模式是否集中在某类特定问题上。
更复杂的分析类问题往往会生成明显更复杂的 SQL 和更长的响应,因此,即便 agent 配置没有变化,命中某个 agent 的问题类型组合发生变化,也可能推动汇总指标变化。
需要监控的关键性能指标
现在我们已经很好地理解了 span 类型,接下来深入讨论团队应该监控的关键性能指标:token 数量、状态码和持续时间。异常行为几乎总是会先在这些指标中显现出来,然后才会出现在其他地方。
Total tokens
Token 消耗(成本)反映了 agent 在其 spans 中处理和生成了多少上下文;你做的工作越多,消耗的 token 就越多。进一步分析,通常平均 token 的持续增加意味着以下几种情况之一:
输入长度变化:用户发送的查询更长,或者调用应用在每个请求中传递了更多上下文;
上下文窗口累积:在多轮对话中,Cortex Agents 通过 thread_id 维护 thread 历史。每一轮后续对话都会携带完整的先前上下文,因此一个从 5k tokens 开始的会话,到第 10 轮时可能超过 40k。如果平均 token 逐渐上升,多轮上下文增长通常就是原因;
检索行为变化:如果 agent 使用 Cortex Search,检索配置发生变化(返回更多结果、更大的 chunks、不同的 reranking)会表现为 token 增加,而用户行为并没有任何变化;
工具调用深度增加:每次对话中的工具调用越多,就意味着更多 planning spans,而每个 planning span 都有自己的 token 成本。工具路由逻辑的变化会在这里变得很明显;
输出冗长度漂移:这种情况较少见,但底层 Cortex model 的变化可能会影响响应的详细程度。planning spans 上的 model_name 字段使我们能够将 token 变化与模型版本关联起来。
在 Snowflake 中,token 计量发生在 span 级别,而不是对话级别。Snowflake 会在每个 span 的 RECORD_ATTRIBUTES 中分别记录 prompt tokens 和 completion tokens,这意味着单次对话会在其 planning、tool call 和 response generation spans 中合计生成多个 token 计数。

Snowflake 中显示的 ReasonAgentStepPlanning-O span 的 Token_count
无论你使用的是 agent 可观测性工具,还是更手动的流程,一项最佳实践都是将这些数据解析为每个 span 的统一 total_tokens 指标,并查看当天所有 spans 的平均值,而不是按对话查看。这在解释 token 峰值时非常重要。
Duration
Duration 往往与 token 消耗相关;token 越多,通常处理时间越长。
然而,当 agent 进行了比预期更多的工具调用、命中了较慢的底层数据,或者正在重试失败操作时,duration 也可能独立飙升。同时观察两者,比单独观察任一指标都能提供更多诊断信号。
P50 和 P90 这类延迟分布也比单纯的平均值更能真实反映情况:稳定的平均值可能掩盖越来越长的慢响应尾部,而这种尾部正在悄悄侵蚀用户信任。
虽然 token 消耗和 duration 都无法告诉你具体哪里出了问题(这需要人工或 Agentic 排查),但两者都能告诉你发生了某种变化。这非常有价值,因为对于那些优雅失败而不是直接崩溃的 Agentic 系统来说,检测问题通常非常困难。
Status Codes
Status codes 也会在 Snowflake 的 trace 数据中直接按 span 跟踪,每个 span 都会解析为 STATUS_CODE_OK 或 STATUS_CODE_ERROR。
因此,错误可以在 span 级别被观察到,这意味着你可以区分 planning step 失败、tool call 失败和 response generation 失败。这三者是完全不同的根因,对应不同的修复路径,因此具备这种清晰区分对于排查 Agentic 故障至关重要。
完成率这类派生指标,即解析为 STATUS_CODE_OK 与 STATUS_CODE_ERROR 的 spans 比例,可以捕捉到 duration 和 token 数量完全遗漏的静默失败。
组合信号
一旦你建立了基线指标,并对正常 agent 性能有了感觉,监控范围就会显著扩展,而这正是 agent 可观测性开始与传统数据管道监控产生实质差异的地方。
例如,evaluation monitors 会监控最终 agent 输出适配性的显著退化。它有帮助吗?完成任务了吗?使用了正确的语言或语气吗?
真正的力量来自利用 agent 可观测性解决方案,将这些信号跨 span 类型组合起来。planning spans 上的高 token 数量与 tool call spans 上的低完成率同时出现,指向的问题,与性能指标稳定但 evaluation scores 下降所指向的问题完全不同。
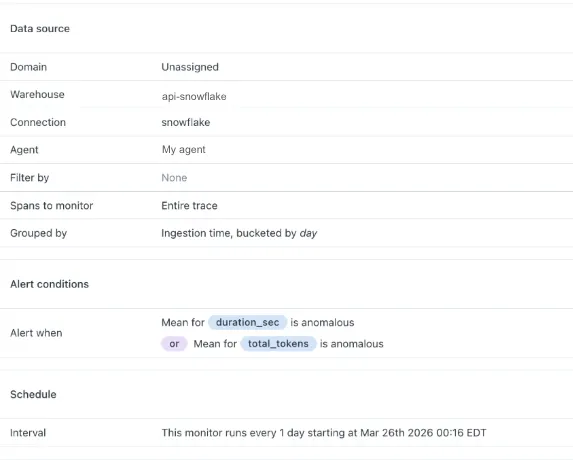
一个按天分组、设置为在 duration 或 token 异常时告警的 agent monitor,显示在 Monte Carlo 中
同时跨多个信号类型获得 span 级可见性,是“知道出了问题”和“知道该去哪里查”之间的关键差别。
常见 agent 性能问题
Token 峰值:它们是什么样子,又是什么导致的
在 Cortex Agent 部署早期几周中,一个常见模式是平均 token 消耗出现阶跃式增长,平均 token 在几天内大约翻倍,然后部分回落。
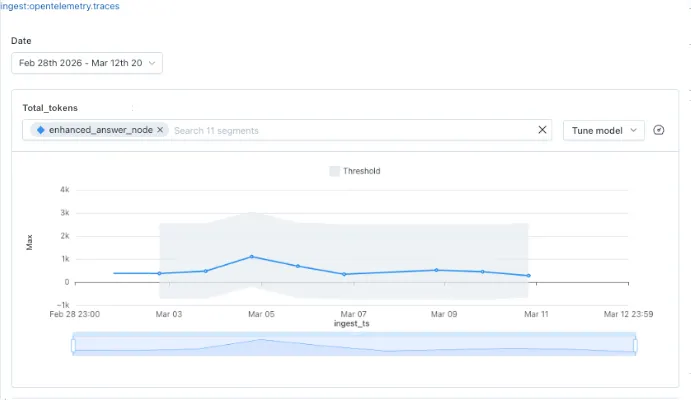
Monte Carlo 中显示的一个 Cortex agent 生命周期早期的初始 token 峰值
这种模式有几种明确的潜在原因,值得系统性排查:突然飙升然后部分回落:这表明发生了一个临时变化,并已部分解决,常见原因包括某个高 token 用户会话抬高了每日平均值,system prompt 或工具配置发生了临时变化后又被回滚,或者一批多轮对话在用户放弃前累积了上下文;
阶跃式上升且没有回落:这表明发生了持续性变化。可能原因包括 system prompt 变化、调用应用的新版本传递了更多上下文,或检索配置变化永久增加了结果集大小;
逐渐上升漂移:这是多轮 agents 最值得担心的模式。如果 thread 历史在没有截断的情况下不断累积,随着用户进行更长对话,平均 token 会持续上升。这是可以管理的,但需要在 agent 配置中明确进行上下文窗口管理。
对于你的 Cortex Agent 中出现的任何这些模式,你可以手动排查,也可以使用 agent 可观测性解决方案进行排查。下一步是查看 traces,筛选受影响的日期范围,并检查单个 spans,对比峰值前后的输入长度、planning step 数量和工具调用行为。一些 agent 可观测性工具提供 Agentic 根因分析,以加速这一步。
来自 Cortex Analyst spans 的 question_category 字段在这里尤其有用:如果峰值与问题类型变化同时出现(例如更多复杂分析查询),这与问题类型保持不变时所代表的问题并不相同。
使用量波动
在早期 Cortex Agent 部署中持续出现的第二种模式,是每日使用量的高方差。
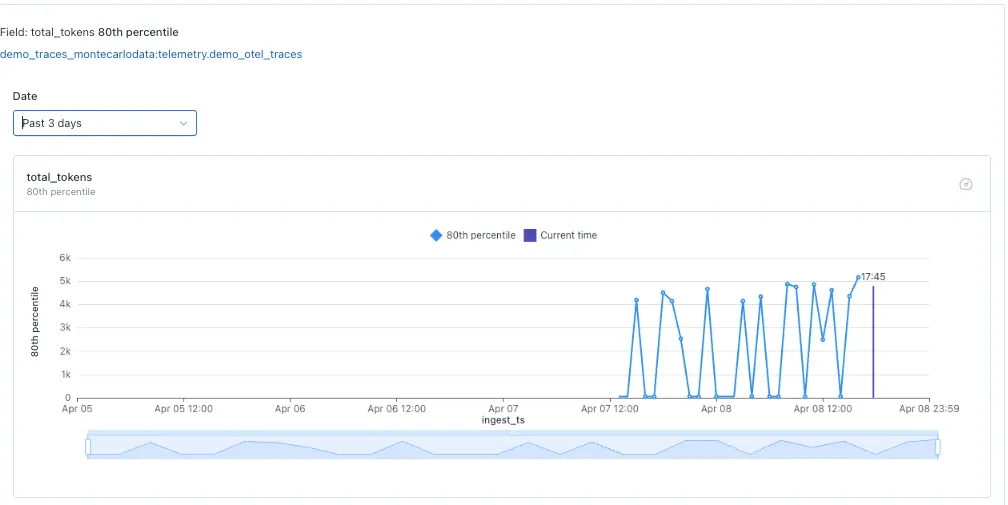
Monte Carlo 中显示的高 token 方差
对于企业内部工具和 B2B 工作流——许多早期 Cortex Agents 通常部署在这些场景中——使用量往往是尖峰式的,而不是均匀的。流量集中在工作时间、特定工作流和特定用户群体周围,因此低流量日可能会在 agent 可观测性表中产生接近零的行数。
这对监控有两个实际影响:
基线质量不均衡。基于高方差数据训练的异常检测模型会产生更宽的置信区间,这意味着需要更大的偏差才会触发告警。接近零流量的日期几乎不会为基线贡献任何信号,而基于小样本量计算出的平均值并不可靠。对于流量模式高度可变的团队,可能需要自行调整 monitor 敏感度,或考虑筛选到工作时间窗口,以获得更干净的基线;
低流量日可能掩盖故障。如果某个 agent 正在经历更高的错误率,但每日量很低,汇总指标可能看起来正常,原因只是没有足够的 spans 来推动平均值变化。这就是为什么要添加错误率监控作为单独信号:将 status_code = 2(STATUS_CODE_ERROR)作为总 spans 的比例进行跟踪,而不是仅依赖性能指标来暴露问题。
底层原则
Snowflake Intelligence 生成的可观测性数据比大多数团队意识到的更多。其中有大量 trace 数据,包括对话历史、span 级 token 数量、工具调用输入和输出、状态码、模型名称以及问题类别。
真正的挑战并不在于有哪些数据可用,而在于能否持续观察这些数据、学习什么是正常状态,并在用户发现问题之前呈现偏差。此外,所有这些都需要以规模化方式完成,因为你和世界上其他人一样,都在竞相部署 agents 集群,而不仅仅是单个 agent 工作流。
原文地址:https://medium.com/snowflake/monitoring-cortex-agent-performance-using-trace-data-8f40dd3e012c
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。




