
过去的半个世纪,数据库产品形态经历了漫长演变与持续更新。起始于大型机的集成式、封闭的数据库服务,随后过渡到小型机时代的标志性 IOE 数据库架构。随着互联网的蓬勃发展,MySQL 等开源数据库掀起了一股浪潮。而云计算的崛起则标志着云数据库新时代的来临。
深究背后的原因,我们不难发现数据库的发展始终紧密跟随用户需求的转变。在当下,云原生数据库崭露头角,受到了 AWS、阿里云、百度智能云等众多云厂商的热烈推崇。作为数据库发展的未来方向,它更有望重塑数据库市场的全新格局。
云原生数据库为市场焦点
随着数据的爆发式增长和业务多元化发展,传统集中式数据库已无法满足应用场景需求。例如游戏行业中,业务存在明显的流量峰谷,这种特性使得传统的数据库很难应对极致的弹性需求,从而带来资源利用率不足、运维人力成本高等问题。
近两年,云原生数据库成为行业关注的焦点,一方面是因为云原生数据库确实满足用户更为苛刻的业务场景,在弹性、性价比、使用体验等方面具备明显优势;另一方面,随着业务云原生化的比例增长,云原生数据库也成为企业进行数据库替换的重要选型。
据 Gartner 预测,到 2025 年,基于云原生平台的数字化业务比例将达到 95%,这将带来云原生数据库市场的快速增长。
目前,云原生数据库在核心能力方面已经比较成熟,在各类苛刻的业务场景得到应用。用户转向更加强调全新的体验,更好的适用现代应用场景。
从购买资源变为购买服务,加速业务交付
传统数据库大多以资源型为主,用户需要关心数据库的部署位置、资源需求大小以及访问量等问题。这是因为传统数据库的架构多以物理机或虚拟机为基础,资源分配和管理都需要用户自行处理。而云原生数据库则彻底改变了这一模式。它基于容器化技术和微服务架构,实现了数据库的即插即用、弹性伸缩和自动化管理,极大地提升了数据库的易用性和维护效率。
极致的弹性和扩展性,紧随业务发展脚步
云原生数据库的另一大特点是其极致的弹性和可扩展性。借助于云计算的弹性伸缩能力,云原生数据库可以根据业务需求实时调整资源分配,无需进行繁琐的手动扩容或缩容操作。这种弹性伸缩不仅适用于计算资源,还包括存储资源和网络资源,确保数据库在高并发、大数据量等场景下依然能够保持稳定的性能。
AI 加持的运维和管理,降低人力运维成本
云原生数据库还引入了智能化的运维和管理功能,进一步降低了数据库的运维难度和成本。通过内置的监控、诊断和优化工具,用户可以实时了解数据库的运行状态、性能瓶颈和潜在问题,并及时进行优化和调整。此外,云原生数据库还支持自动备份、恢复和容灾等功能,确保数据的安全性和可用性。
云原生数据库通过基于云计算的特性,为用户提供了以上提到的全新使用体验,降低数据库 TCO 的同时提供极致的扩展性,同时又规避了分布式数据库带来的兼容性问题。这使得云原生数据库成为继云托管数据库之后备受市场关注数据库方案。
依然有 42% 用户存在云原生数据库的选型顾虑
据中国信通院统计,在受访的企业中,57.9% 的企业会考虑使用云原生数据库并将其应用到主要业务系统中去,另外 42% 的企业还处于观望状态。在实际的应用行业分析,互联网行业占比 55.4%,其它金融、制造、消费行业平均占比不超过 10%。
云原生数据库已经在互联网场景被早期客户接受和应用,但更多客户还没有开始采用。当前企业在数据库技术选型过程中仍然面临一些顾虑和挑战,例如灵活的部署模式、技术成熟度、兼容性和服务可持续性等。同时,国内云原生数据库产品百花齐放,也对企业选型造成一些选择困难。
这导致仍然有大量的客户,目前还无法方便地享受到云原生数据库带来的业务效果提升。
这些客户的选型顾虑主要集中在以下几点:
灵活的部署问题:不同企业对数据库的部署要求不同,有些企业可以直接使用公有云服务,有些企业出于安全合规要求需要将数据库部署在本地 IDC,或者同时兼顾采用混合云和多云的形式。例如政府、金融等行业,90% 的业务还是要求私有化部署,仅有部分互联网业务采用云服务方式。
技术成熟度:国内云原生数据库还处于快速发展阶段,产品和技术的迭代比较频繁,用户也比较顾虑技术是否成熟,版本是否稳定。特别是在企业比较稳定和核心的业务场景,用户一般不愿意尝试新的技术架构,同时也不能接受频繁的版本更新,这将带来极大的业务稳定性问题。
服务可持续性:对于新的技术,用户通常关心服务的可持续性。数据库作为承载业务核心数据的载体,用户希望服务是稳定的、持续的。毕竟,更换数据库对于业务来说是一个高风险的工作。
回顾 MySQL 的发展和大流行, MySQL 之所以能成为广泛使用的数据库,主要原因在于其灵活的部署能力、稳定的性能、开源生态,以及被 Oracle 收购后,为其提供了丰富的企业级的能力,这使 MySQL 成为用户信赖的数据库。
提升体验降低门槛,让更多用户使用云原生数据库
云原生数据库的普惠,简而言之,就是云原生数据库技术能够被更广泛的企业和开发者轻松获取和使用,并从中获得实际利益。它不仅仅意味着技术的高可用性和弹性伸缩,更重要的是让不同规模、不同需求的企业和开发者都能够以合理的成本享受到云原生数据库带来的便利和效益。
从产品的使用体验的角度看,普惠的云原生数据库应该在「部署 — 使用 — 运维」等环节进一步降低门槛提升体验:
部署环节
数据库的易于部署是实现普惠目标的关键环节。对于大多数企业和开发者而言,简单、快捷的部署流程能够极大地降低技术采纳的门槛。随着公有云的广泛使用,用户可以直接在云平台一键购买并部署云原生数据库集群,无需担心部署资源、故障处理等问题,极大方便技术的普及使用。
仅有公有云是不够的,很多用户出于安全合规要求或多云容灾要求,需要将数据库部署在自建 IDC 或跨云部署,这需要数据库产品提供更加灵活的跨平台部署能力,这种跨平台能力包括:
基于通用硬件服务器构建高性能的数据库服务,这意味着无论用户使用的是什么样的硬件环境,数据库都能够高效地运行,不受硬件限制;
可以基于容器化技术,例如 K8s,实现更加标准化的部署方式;
数据库自身支持单机和分布式灵活的部署架构,对于小规模资源环境通用可以部署,甚至部署在开发者的笔记本中。
使用环节
易于使用的数据库要求具备低门槛的学习成本和简单的技术栈体系,用户不需要具备专业的数据库知识,就能够轻松地管理和使用数据库。
良好的兼容性是当前比较好的方式。例如兼容 MySQL、PostgreSQL 等。这使得用户可以保留已有的使用习惯和相关技术栈,让大量的开发者和业务可以快速迁移到云原生数据库,降低技术门槛、迁移门槛和学习门槛。
简化技术栈体系可以让用户更低门槛的使用。例如通过 HTAP 能力实现在线交易能力和分析能力融合,用户通过一个数据库集群满足混合负载需求。
低成本的数据迁移能力也能让用户更容易使用。例如用户之前使用集中式的 MySQL 数据库,随着业务增长需要选择扩展性更好的数据库产品,当前用户一般有两种技术路线,一种是分布式数据库,例如 TiDB、DRDS 等,这类数据虽然解决了大容量、高吞吐的扩展性问题,但一般在兼容性、延迟等方面有天然的短板;另一种是云原生数据库,例如 GaiaDB、PolarDB 等,这类数据库可以简单理解成「加强版 MySQL」,既能保障 100% 的兼容性,又能兼容扩展能力,这使得业务的迁移更加丝滑,用户原有的技术体系和人才储备可以延续使用。
运维环节
数据库的运维是确保数据库稳定、高效运行的关键环节。普惠的数据库应该具备自动化运维的能力,减少人工干预的需要,降低运维工作的复杂度。
这包括自动化的备份、恢复、监控、故障排查等功能,确保数据库在出现问题时能够及时发现并修复。
同时,数据库还需要提供灵活的扩展能力,根据应用的访问量和数据量的变化,自动调整资源分配,确保数据库始终处于最佳运行状态。这些自动化的运维功能可以降低运维成本,提高运维效率,使得用户能够更加专注于业务的发展。
当前智能运维是数据库发展的重要方向,基于机器学习和生成式 AI 能力,可以对数据库的运行日志、故障数据、预案等进行训练。通过智能运维技术帮助用户更快速的定位故障问题并提供处理建议。
云原生数据库的 Serverless 能力也能降低运维复杂度。过去 DBA 需要根据预期业务流量提前准备资源,并手动完成数据库扩容,这种方式不仅增加了运维复杂度,同时提高资源成本。云原生数据库的存算分离架构天然的具备 Serverless 能力,业务按需自动扩展计算资源和存储资源,避免人工的复杂运维工作。
综合来说,现在用户期望的不止是一个性能高,成本低,企业级能力强的数据库,而是在这个基础上一个易部署,易使用,易运维的综合能力优秀的数据库。
覆盖产品全部使用环节的体验提升,将是衡量一个数据库是否能够被大众应用,具备普惠能力的关键。具备这些能力的云原生数据库,将不会只停留在象牙塔以及大公司技术栈里面,能够走进更多企业,让他们享受云原生数据库的价值。
从 1.0 到 4.0,普惠一直是 GaiaDB 关注点
百度智能云的 GaiaDB 从 1.0 版本开始,就从长期发展的角度,针对普惠能力进行了技术和产品设计考量,可以基于通用服务器构建适合被大规模商用的云原生数据库产品。
易部署,区别行业传统实现方案,可在普通硬件上实现高性能。
一款云原生数据库,不采用高性能硬件,而是采用通用服务器和网络,又要具备存算分离的能力,以及大规模处理的能力,这里面有非常大的技术挑战。最核心的是存算分离带来的网络延迟和并发处理问题,存算分离导致原来集中式的本地 I/O 变成网络 I/O,网络 I/O 在不通过 RDMA 技术加速的情况下,延迟是比较高的。
为了解决这个问题,GaiaDB 1.0 和 2.0 针对性地进行了两点网络优化,从根本上解决普通硬件的性能问题:
引入 Quorum 一致性协议。将日志层一致性协议从 Raft 改成 Quorum 协议。这样优化是因为 Raft 协议需要两次网络请求,第一次是读写节点写日志层的 Leader 节点,第二次是 Leader 节点同步日志到 Follower 节点,两次网络请求增加了写入延迟。Quorum 只有一次网络请求,读写节点将日志并行写入 3 节点,只要半数以上节点接收到日志,即可写入成功。这种协议方式可以降低网络延迟,增加并发能力。
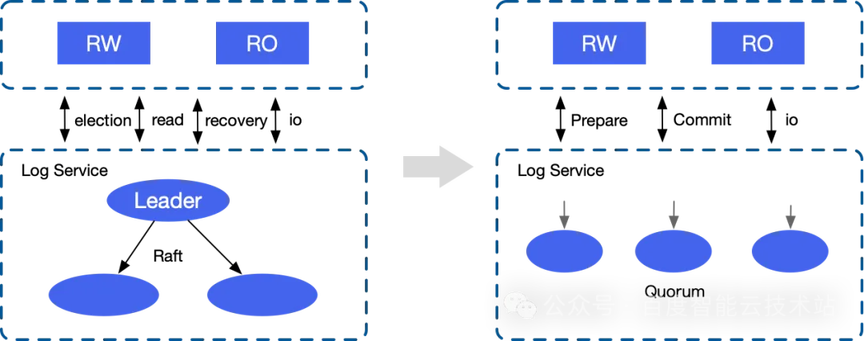
引入智能网络技术。智能网络是一种高性能网络框架,它支持内核态 TCP 和用户态 TCP 等多种协议。智能网络能够根据硬件设备的性能和网络状态,自动选择最优的网络协议和参数,从而最大程度地减少网络传输延迟。智能网络的引入对于降低远程 I/O 的平均时延起到了非常重要的作用。通过智能网络的选择和优化,GaiaDB 能够更好地适应不同的硬件环境,并自动选择最佳的网络协议和参数,进一步提高了数据库的性能和响应速度(E2E 延迟缩短 60%,达到百 us)。
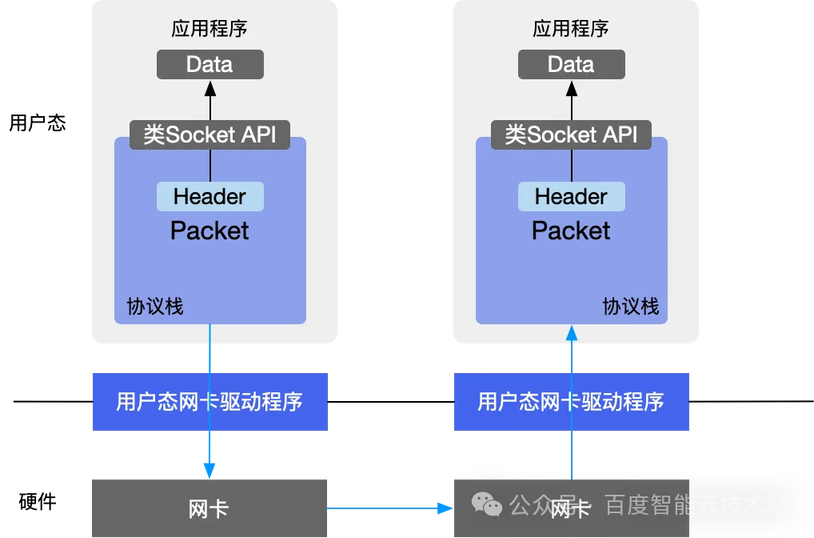
易使用,让业务架构更加简单,可在一个数据库实现 TP 和 AP 混合负载。
近期 GaiaDB 发布了 4.0 版本,引入并行计算技术和列存索引技术,解决了复杂查询场景的性能长尾问题,并进一步提升了在线交易场景和在线实时分析场景(HTAP)的性能表现。通过并行计算技术,GaiaDB 可以充分利用多核 CPU 的计算能力,将查询任务拆分成多个子任务,并同时执行这些子任务,从而加快查询速度。列存索引技术则可以针对分析列增加索引,使得数据检索更加高效,进一步提高查询性能。
现在,GaiaDB 4.0 基于通用服务器,就可以实现企业级苛刻的在线交易场景和实时分析场景的需求,同时保障企业级的高可用能力。这些优化使得 GaiaDB 可以部署在不同平台中,即满足普惠的部署使用需求,同时提供高质量的服务能力。
当前的 GaiaDB 4.0 支持 1 GB ~ 500TB 的存储扩展能力,100% 兼容 MySQL 语法和协议,具备复杂查询场景的混合负载处理能力(HTAP)。在 GaiaDB 2.0 和 3.0 逐步支持了跨 AZ 和地域高可用能力,并对并发性能做了诸多优化,具备高性能低成本的能力。
易运维,结合 AI4DB 能力,实现高效运维、自助运维。
借助于存算分离的技术架构和平台能力,GaiaDB 4.0 在运维方面可以实现完全的自动化或一键操作。例如,基于存储和计算的 Serverless 能力实现了自动扩缩容,减少业务峰谷带来的运维工作量。
目前,GaiaDB 正在与大模型的能力结合,为用户提供智能的运维辅助能力,帮助数据库运维工程师高效获取数据库知识,并做出快速准确的运维决策。
传统的运维知识库系统主要采用固化的规则和策略来记录管理操作和维护的知识,这些系统的知识检索方式主要基于关键字搜索和预定义的标签或分类,用户需要具备一定的专业知识才能有效地利用这些系统。这已不足以满足现在复杂多变的运维环境。因此,GaiaDB 4.0 借助大模型来提供运维知识并协助决策成为趋势。这将在运维能力、成本控制、效率提升和安全性等方面带来深刻的变革。
在数字化转型和智能化升级过程中,各个行业正在不断出现新应用,新场景。不断推动云原生数据库的普惠,让更多企业能够受益于这项新技术的发展,不再受限于在传统 IT 技术探寻解决方案,更好地满足新业务要求。




