
近几日,我们在 Reddit 和 Hacker News 上随处可见关于 Atlassian 的 Cloud 版本宕机的讨论,这导致近 400 家公司,5 万至 40 万名用户无法访问 Jira、Confluence 在内的至少 7 款产品,这场宕机事故从 4 月 4 日开始持续至今。Atlassian 估计许多受影响的客户在两周内无法访问他们的服务,目前至少有 53% 的公司已经恢复了访问权限。
发生了什么?
4 月 4 日,JIRA、Confluence、OpsGenie 和其他 Atlassian 服务在某些公司停止工作。
4 月 5 日,Atlassian 注意到该事件并开始在其状态页面上对其进行跟踪。他们今天发布了几个更新,确认他们正在修复。他们在当天结束时说“我们将在解决问题的过程中提供更多细节”。

部分客户开始抱怨本次宕机,比如:
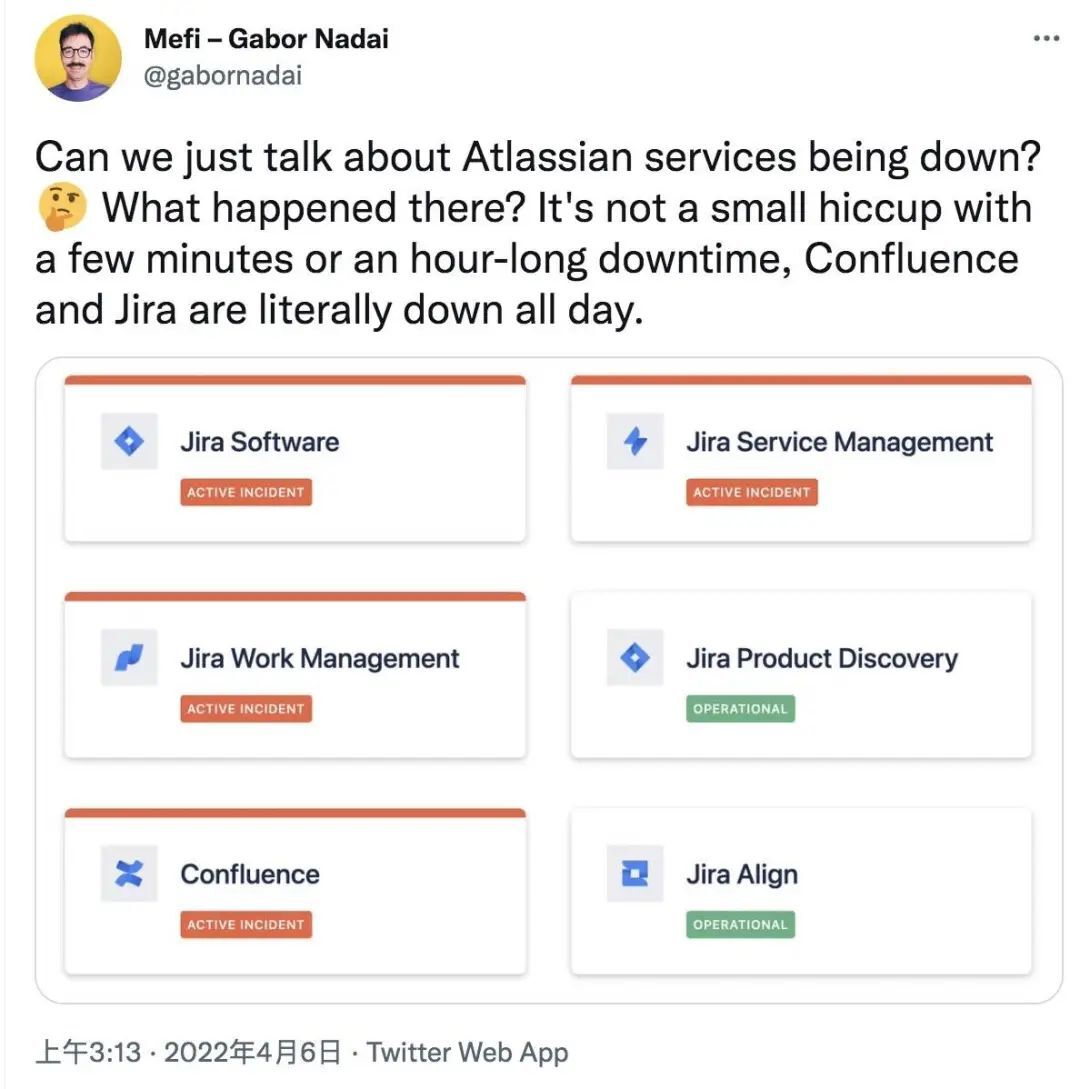
4 月 6 日,Atlassian 每隔几个小时发布一次相同的更新,但不分享任何相关信息。更新内容如下:
“我们正在对部分实例进行验证阶段的工作。重新启用后,支持人员将通过打开的事件单更新账户。恢复客户站点仍然是我们的首要任务,我们正在与全球团队进行协调,以确保工作 24/7 持续进行,直到所有实例都恢复。”

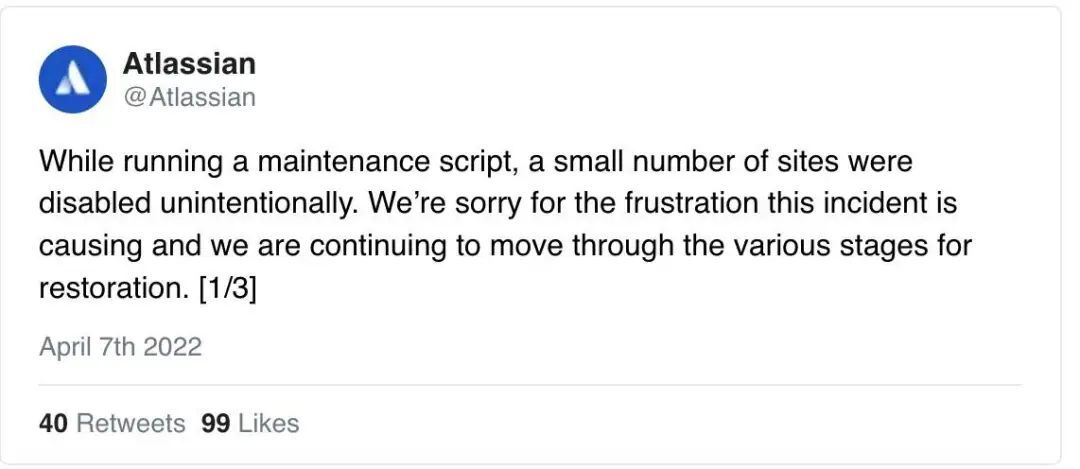
4 月 7 日,Atlassian 通过 Twitter 账户承认了这个问题并提供了一些简单的细节。
接下来几天,Atlassian 方面关于本次宕机事件没有做太多细节说明。与此同时,这一消息已经在 Hacker News 上引起了广泛的讨论,有自称是该公司前员工的网友评论说该公司内部的工程实践低于标准。
“This does not suprise me at all. (…) at Atlassian, their incident process and monitoring is a joke. More than half of the incidents are customer detected.
“这一点都不让我吃惊。(…) 在 Atlassian,他们的事件流程和监控是个笑话。超过一半的事件是客户检测到的。
虽然 Atlassian 方面表示在和客户做沟通,但客户们似乎并不满意。Atlassian 首席技术官 Sri Viswanath 发布了一篇关于此事件的博客:
4 月 4 日,约 400 位 Atlassian Cloud 客户经历了服务产品全面宕机。我们正在努力恢复网站,目前已经为约 53% 的客户恢复了正常服务(这一比例截至 4 月 14 日,可以在 Statuspage 页面中查看最新进度)。预计在未来两周内,其余客户的服务也将逐步回归正常。
这里首先澄清一点:此次事件并非网络攻击,也不属于任何系统扩展故障。此外,大部分已经恢复的客户没有出现数据丢失,仅有少部分客户报告称事件发生前 5 分钟内的数据无法找回。
必须承认,此次事件与我们的响应时间及运营标准相违背,我谨代表 Atlassian 向您诚挚道歉。我们知道,Atlassian 产品对您的团队至关重要;而一旦服务可用性受限,您的业务也将受到影响。我们正在夜以继日工作,着力帮助客户业务尽早恢复正常运行。
什么情况?
我们在 Jira Service Management 以及 Jira Software 等产品中广泛使用到一款独立应用,名为“Insight-Asset Management”。这款应用以原生功能的形式全面集成到 Atlassian 产品之内。因此,我们需要在已经安装过这款旧版应用的客户站点上将其停用。我们的工程团队原计划使用现有脚本停用该独立应用实例,但却意外引发两个重大问题:
沟通不畅。首先,请求停用的团队与执行停用的团队间未能顺畅沟通,导致前者没能提供正确的预期停用应用 ID,反而把整个云站点上所有应用程序的 ID 交给了执行团队。
脚本错误。第二,我们使用的脚本既提供用于日常操作(需要保障可恢复性)的“删除标记”功能,也提供出于合规性要求而永久删除数据的“永久删除”功能。此次事件,就源自该脚本以错误的执行模式对错误的 ID 列表进行操作,最终导致约 400 名客户的站点被意外删除。
为了实现事件恢复,我们的全球工程团队专门建立起系统性流程,帮助受影响客户重回正轨。
恢复方案
Atlassian Data Management(https://www.atlassian.com/trust/security/data-management)详细描述了我们的数据管理流程。
为了保障高可用性,我们在多个 AWS 可用区(AZ)中预置并维护有一套同步备用副本。可用区具备自动故障转移功能,一般每隔 60 到 120 秒保存一次;我们会定期处置数据中心宕机及其他常见的服务中断情况,并保证不对客户造成可感知的影响。
我们还维护着多个不可变备份,用以抵御数据损坏事件、借此随时恢复至之前的特定时间点。备份数据会保留 30 天,Atlassian 还会持续测试并审计这些用于支持恢复需求的存储备份。
利用这些备份,特准会定期回滚个别客户、或者少部分意外删除了自己数据的客户。如果有必要,我们还可以立即将所有客户恢复至另一个全新环境当中。
但我们的自动化体系仍有缺失,就是无法在不影响其他客户的前提下、将大量客户自动恢复至现有(且当前正在使用的)环境当中。
在我们的云环境当中,每份数据存储都包含来自多家客户的数据。由于此次事件中被删除的数据并非独立存在,其所在数据存储中还承载着其他客户仍在使用的信息,所以我们只能从备份当中手动提取并恢复各部分。因此,各个客户站点的恢复成了漫长而复杂的过程,还要求我们在恢复期间不断进行内部验证与客户验证。具体步骤我们的初步客户站点恢复方案只能做到半自动化,其中仍涉及一系列耗时费力的复杂步骤,原因就是之前提到的需要手动验证已恢复站点中的客户数据。
现在,我们希望转向自动化程度更高的新流程,具体如下:
在集中编排系统内重新启用已删除站点的元数据。
恢复从备份中提取到的客户数据,包括用户、权限等。
重新启用生态系统应用、计费数据以及其他与客户所生成数据没有直接关联的数据。
因为每个站点都需要进行对应的数据存储提取与恢复,所以我们不断测试站点并与各家客户密切合作,共同确保恢复结果的准确性。
目前我们正在分批恢复客户,一轮最多可涵盖 60 个租户。自始至终,整个网站恢复过程大概需要 4 到 5 天。我们的团队已经开发并开始使用新的多批次恢复功能,相信这有助于缩短我们的整体恢复周期。
第一要务:恢复客户业务
我们知道,此类事件会削弱我们在客户心中的可信度。我们未能达成自我设定的运营高标准,也没能做好全面的客户沟通工作——截至目前,我们的沟通对象仍然仅限于受到事件直接影响的客户群体。
此次事件已经得到工程团队乃至整个 Atlassian 公司的高度关注。我们将继续夜以继日工作,直至成功恢复每一位客户的网站。
下面,我们向大家汇报接下来的工作安排:
恢复客户站点。我们将继续与受影响客户直接合作,帮助各位恢复站点、通过支持工单与客户支持团队一对一沟通。请您相信,我们正在尽快解决此次事件。
每日更新。我们将随时通过受影响客户的工单及每日状态页面更新,向受到影响的客户发布最新恢复动态。
事后审查。我们也会组织事后审查,并及时公布调查结果与后续计划。相关报告整理完成后将全面公开。
最后,感谢各位客户:谢谢您的合作,也感激您与我们共同走过的每一步。我们知道您需要为组织内的利益相关方陈述事件,也知道此次故障已经给正常业务带来重大干扰。我和我的团队将尽一切努力为每位客户尽快恢复业务,也将尽我们所能消除事件影响。
从这次中断中吸取的教训
任何工程团队都可以从这次中断学到很多东西。
事件处理:
拥有灾难恢复和黑天鹅事件的运行手册。对于可能的意外事件提前计划如何回应、评估和沟通。遵循灾难恢复手册。Atlassian 有自己的 Confluence 灾难恢复手册,但可能没有完全遵循该手册。他们的操作手册指出,任何操作手册都有沟通和升级指南。
直接和透明地沟通。一旦发生类似事件,一定要及时与客户沟通,缺乏沟通会导致信任缺乏,不仅在受影响的客户之间,而且在任何意识到中断的人之间。虽然 Atlassian 可能认为什么都不说是安全的,但这可能不是最好的选择。这一点可以参考 GitLab 或 Cloudflare 发生中断后的做法。
说客户的语言。Atlassian 状态更新含糊不清,缺乏技术细节,这对于购买了 Atlassian 产品的 IT 主管和 CTO 可能是不够的。
避免什么都不说的状态更新。事件页面上的大多数状态更新都是复制粘贴相同的内容,这样做显然是为了每隔几个小时提供一次更新……但这些不是更新,他们增加了无法控制住宕机的感觉。
避免沉默。直到第 9 天,Atlassian 一直处于静默状态。不惜一切代价避免这种方法。
避免事件:
为所有迁移和弃用制定回滚计划。
进行迁移和弃用的试运行。
不要从生产中删除数据。
相反,标记要删除的数据或使用租约来避免数据丢失。




