
在 4 月 25 日的百度 Create 开发者大会现场,百度创始人李彦宏发布了两大模型、多款热门 AI 应用,并宣布将帮助开发者全面拥抱 MCP。同时,百度正式点亮了国内首个全自研的三万卡集群,可同时承载多个千亿参数大模型的全量训练,支持 1000 个用户同时做百亿参数的大模型精调。
“所有这些发布,都是为了让开发者们可以不用担心模型能力、不用担心模型成本、更不用担心开发工具和平台,可以踏踏实实地做应用,做出最好的应用!”李彦宏说道。
李彦宏表示,大模型厂商卷生卷死,几乎每周都在发布新模型,但开发者不敢大胆用,因为担心自己的应用被模型迭代快速覆盖掉。李彦宏认为这是把双刃剑:一方面,开发者确实需要理解技术发展趋势;另一方面,这么多日益强大的模型提供了更多的选择,打开了更多的可能性。
“只要找对场景,选对基础模型,有时候还要学一点调模型的方法,在此基础上做出来的应用是不会过时的”。他强调,“没有应用,芯片、模型都没有价值。模型会有很多,但未来真正统治这个世界的是应用,应用才是王者。”
发布两大新模型,价格最高降 80%
文心大模型 4.5 Turbo 和文心大模型 X1 Turbo,具备多模态、强推理、低成本三大特性。
“多模态将成为未来基础模型的标配,纯文本模型的市场会越变越小,多模态模型的市场会越来越大”。李彦宏表示。基于这样的判断,新模型都进一步增强了多模态能力。在多个基准测试集中,文心 4.5 Turbo 多模态能力与 GPT 4.1 持平、优于 GPT 4o。
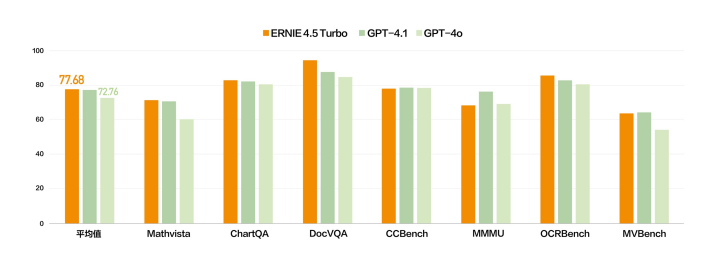
文心 4.5 Turbo- 多模态
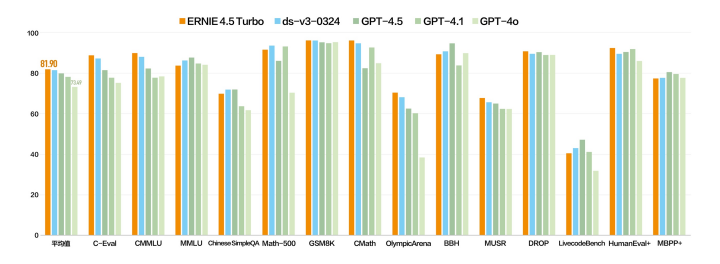
文心 4.5 Turbo- 文本
文心大模型 X1 Turbo 则是基于 4.5 Turbo 的深度思考模型,性能提升的同时,进一步增强思维链,问答、创作、逻辑推理、工具调用和多模态能力,整体效果领先 DeepSeek R1、V3 最新版。
“有了这样超级能干的基础模型,我们就可以打造出超级有用、超级有趣的 AI 应用来。”李彦宏还指出,随着模型能力的增强,大模型和应用场景结合的机会将越来越多,能够渗透场景、带来实在价值的 AI 应用,是属于开发者的真机会。
李彦宏认为,当前开发者做 AI 应用的一大阻碍,就是大模型成本高、用不起。成本降低后,开发者和创业者们才可以放心大胆地做开发,企业才能够低成本地部署大模型,最终推动各行各业应用的爆发。
“中国市场上绝大多数大模型 API 的调用价格都比 DeepSeek 要低,而且反应速度也更快。”李彦宏还表示,“DeepSeek 不是万能的。”他指出,DeepSeek 不支持多模态理解,有幻觉,更重要的是,慢和贵。”
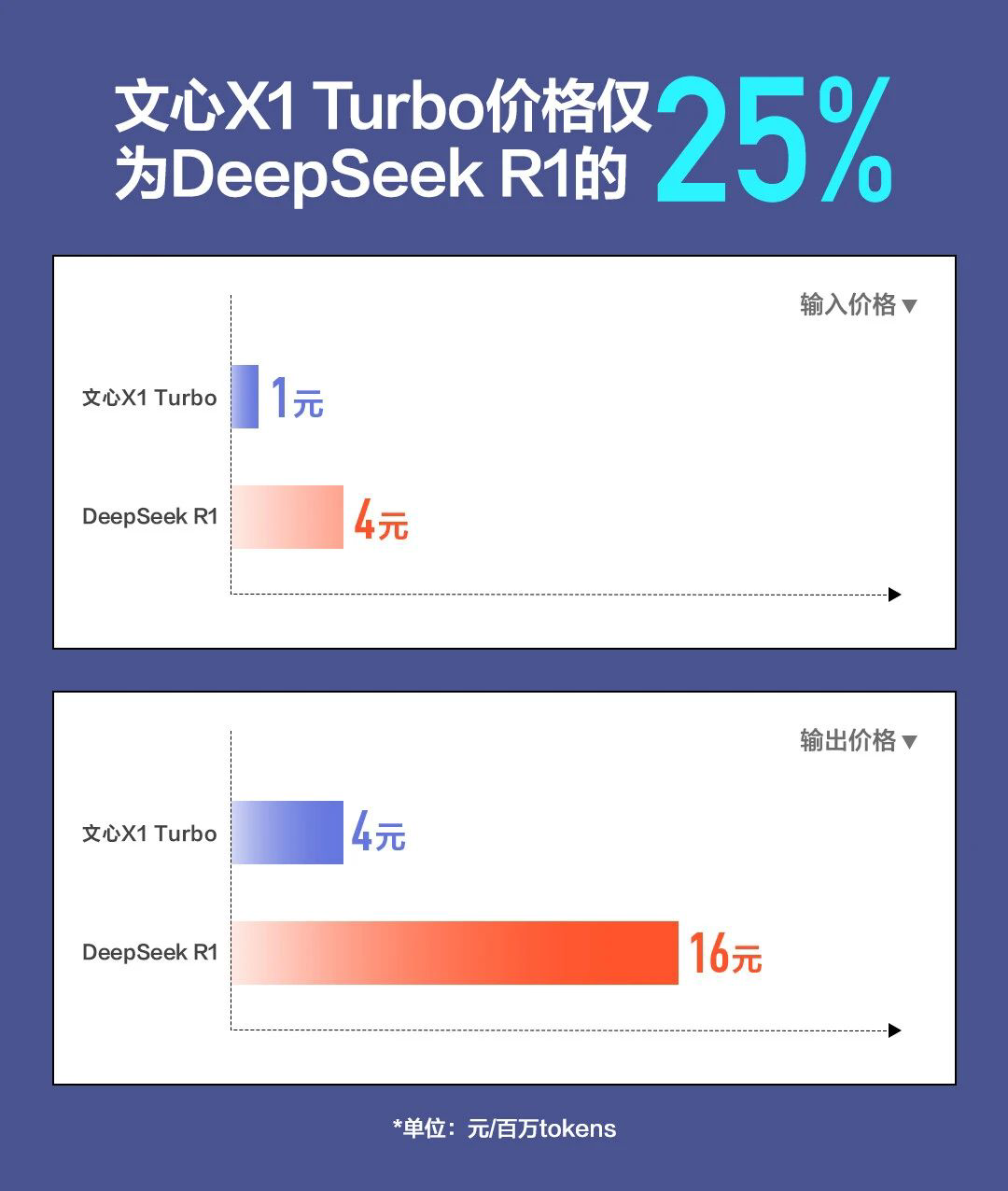
百度两款模型的使用价格也重点与 DeepSeek 进行了对比。文心大模型 4.5 Turbo 输入价格仅为 0.8 元 / 每百万 token,输出价格 3.2 元 / 每百万 token,仅为 DeepSeek-V3 的 40%,比文心 4.5 价格下降 80%。
而文心大模型 X1 Turbo 的输入价格为 1 元 / 每百万 token,输出价格 4 元 // 每百万 token,仅为 DeepSeek-R1 的 25%。
那么,最新模型有哪些技术上的创新呢?对此,百度 CTO 王海峰从基础模型、后训练、深度思考和数据等方面介绍了一些文心 4.5 Turbo 和 XE Turbo 的关键技术细节。
首先,文心 4.5 和 4.5 Turbo 实现了文本、图像和视频的混合训练。针对模态间结构规模与知识密度的差异,百度通过多模态异构专家建模、自适应分辨率视觉编码、时空重排序的三维旋转位置编码、自适应模态感知损失计算等技术,将跨模态学习效率提升近两倍,多模态理解效果提升超过 30%。
后训练方面,百度研发了自反馈增强技术框架,基于大模型自身的生成和评估反馈能力,实现了“训练——生成——反馈——增强”的模型迭代闭环,解决大模型对齐过程中数据生产难度大、成本高、速度慢等问题,还降低了模型幻觉,提升模型理解和处理复杂任务的能力。
在训练阶段,他们研发了融合偏好学习的强化学习技术,通过多元统一奖励机制,提升了对结果质量判别的准确率,通过离线偏好学习和在线强化学习统一优化,进一步提升了数据利用效率和训练稳定性,并增强了模型对高质量结果的感知。得益于偏好信号与奖励信号的融合运用,模型的理解、生成、逻辑和记忆等能力全面提升。
深度思考方面,突破了仅基于思维链优化的范式,在思考路径中结合工具调用,构建了融合思考和行动的复合思维链,模型解决问题能力得到显著提升。同时,结合多元统一的奖励机制,实现了思考和行动链的端到端优化,大幅提升了跨领域的问题解决能力。
数据方面,打造了“数据挖掘与合成 – 数据分析与评估 – 模型能力反馈”的数据建设闭环,为模型训练源源不断地生产知识密度高、类型多样、领域覆盖广的大规模数据。同时,数据建设流程具备良好的可扩展性,能够轻松迁移到全新的数据类型,实现快速、高效的数据生产。
百度自己的 AI 应用
在看好应用市场的背景下,百度也发布了自己的 AI 应用,主要在多智能体和多模态方面。
多智能体应用
“未来每个公司都需要依赖代码智能体来完成任务,如果还像原来那样吭哧吭哧地写代码,没有赢的可能性。”李彦宏表示。
今年 3 月,百度向全社会开放无代码编程工具“秒哒”,任何人都可以通过秒搭,用一句话就能够生成应用。继“秒哒”之后,百度又最新推出一款多智能协作 App:心响,能够通过自主规划与多智能体协作一站式解决用户复杂问题,在深度研究、数据分析、健康咨询等场景都有着不错的表现。目前产品已上线安卓版,iOS 正在上架中。
据悉,心响 App 是一款以“AI 任务完成引擎”为核心的通用超级智能体产品,通过自然语言交互帮助用户实现复杂任务拆解、动态执行与可视化结果交付。除了常见的外部 MCP 工具调用(Tool Use),在健康、法律等专业场景中,它还实现了“多智能体协作”(Agent Use)机制。比如,面对健康咨询时,系统可自动调度多位“医生 AI 分身联合会诊”;在法律服务中,则支持由多个律师 AI 分身组成的“律师智囊团”协同答复与服务。
百度认为,多智能体协作是下一个高价值的 AI 应用方向。未来的 AI 应用将从回答问题走向任务交付,而任何一个复杂任务的交付,都需要多智能体的协作来解析需求、分拆任务、调度资源、规划执行,最终交付结果。
多模态应用
高说服力数字人,是多模态大模型的一个典型应用。“2025 年最令人激动的突破性应用之一,就是 AI 数字人。” 李彦宏介绍,百度发布的高说服力数字人,具有声形超拟真、内容更专业、互动更灵活的特点,在电商直播、游戏、消费等领域,有着巨大的应用空间。
高说服力数字人还具备“AI 大脑”,能根据直播间实时热度和转化情况,灵活调度助播、场控、运营等角色共同促进转化,譬如适时切换镜头画面、调度图片、视频素材,真正实现了一个人就是一个营销团队。
李彦宏指出,高说服力数字人超越真人主要归功于百度慧播星背后的“剧本生成”能力,实现口播脚本与数字人表情、语气、动作的高度融合,以及顺畅的情绪转折和动作切换,表现“超拟真”。目前,百度慧播星已上线“一键克隆”功能。用户只需录制一条最短 2 分钟的直播视频上传训练,即可拥有自己的专属数字人,人人都能做主播。
据王海峰介绍,高说服力数字人背后有多项关键技术。百度研发了剧本驱动、多模协同的超拟真数字人技术,实现了语言、声音、形象的协调一致。
首先是基于大语言模型的剧本生成,包括台词生成、视觉标签生成以及语音标签生成。模型在生成台词时,同步生成数字人的动作、表情和语调等信息,以及每个模态的对齐位置,整体构成了剧本,进而以剧本驱动视频和语音在生成时进行多模态的内容匹配和位置对齐,最终生成有高表现力、形神兼备的数字人。同时,百度设计了丰富的动态交互模式,打造媲美真人的互动能力,并通过视频断点设计,让动态视频片段能够在视频流中顺畅衔接。
其次是面向数字人场景的语音合成。在生成剧本的基础上,基于文心大模型自动预测当前文本的风格、情绪及韵律起伏等,通过文本自控的语音合成大模型实现自级别指令遵循的合成能力,通过文本控制声音效果的平滑流畅,再结合直播文本及发音人信息,合成风格恰当、自然、流畅的声音。
针对视觉形象生成以及驱动方面媲美真人的数字人面临的关键难题,百度研制了数字人视频生成大模型视频、剧本、语音等多模态信号,一同用于数字人的高可控生成。通过进一步分析原始视频素材,一方面抽取视频中的高表现力片段,另一方面生成与剧本语音匹配的高表现力片段。此外,通过解析视频中的人物场信息,视频生成模型可以生成复杂的人物场交互片段,并保持主体的一致性,最终结合这些片段通过影空间对齐生成足够时长的视频内容。
百度还发布了全球首个内容领域操作系统——沧舟 OS。沧舟 OS 包括两大核心:一是 Chatfile plus,对不同模态、不同形态、不同格式的内容,做解析和向量化处理,然后再进行混合生成;二是建立了“三库”和“三器”:“三库”即公域知识库、私域知识库、记忆库,“三器”是编辑器、阅读器、播放器,它们可以根据用户的需求被大模型组合调用。
依托沧舟 OS,百度网盘上线了“AI 笔记”,这是业内唯一的多模态 AI 笔记,支持用户在网盘内观看学习视频时,一键生成全面、清晰、结构化的 AI 笔记,还能生成 AI 思维导图、基于视频内容 AI 出题等。
迎接 AI 应用井喷:帮开发者全面拥抱 MCP
AI 应用大爆发时代,开发者们普遍遇到一系列的难题,如使用工具缺少统一规范、开发效率不够高、需要反复适配各种不同类型平台、开源工具和组件良莠不齐、整合和维护难度大等。MCP(模型上下文协议)的出现带来全新的解决思路,就像是给 AI 装上了一个“万能插座”,开发者不再需要为每个工具编写定制化的代码,只要按照 MCP 的标准编写一次接口就可以了。
在李彦宏看来,MCP 是是 AI 发展的一大步。为此,百度内部全面支持 MCP:
百度优化了文心基础大模型,提升模型在使用 MCP server 时的任务规划和调度能力。
百度智能云千帆大模型平台已率先全面兼容 MCP,不仅提供大量第三方 server,也支持开发者创建和发布 MCP server;
百度搜索构建了 MCP server 发现平台,可索引全网优质的 server;
文心快码,成为国内首个支持 MCP server 的智能编码助手;
百度的商品检索、商品交易、商品详情、商品参数对比、商品排行榜能力等也已经通过百度电商的 MCP server 对外提供,这是国内首家支持电商交易的 MCP 服务;
百度文库、百度网盘、百度地图等应用全面对外提供 MCP Server 服务。
最重要的是,文心大模型使用的联网搜索工具也变身为百度搜索 MCP server 供开发者调用,“这是目前市场上最好的搜索 MCP,”李彦宏表示,现在基于 MCP 开发智能体,就像是在 2010 年前后开发移动 APP。百度将持续加大对 MCP 的支持,推动更多的应用和服务兼容 MCP。
李彦宏表示,作为一家技术公司,百度始终坚持创新,坚持 AI 人才的培养,且一直为开发者提供模型、开发工具,以及资金和资源等多方面的支持。5 年前,百度提出的 500 万 AI 人才计划已在 2024 年提前完成,到现在为止已经为社会培养了 630 万 AI 人才。会上,李彦宏宣布,未来 5 年,百度将加大力度,再为社会培养 1000 万 AI 人才。
One more thing
最后在发布现场,百度向外界透露了一项重大技术突破:中国首个全自研的 3 万卡超级计算集群已成功点亮。据介绍,这台由昆仑芯三代组成的集群,完全为大模型时代的计算需求应运而生的,能够同时承载多个像满血版 Deepseek 这样的千亿级参数大模型进行全量训练,并且可以支持 1000 个客户同时做百亿参数的大模型的精调。
“现在可以说,在中国开发 AI 应用我们有底气。”李彦宏称,百度建设了超大规模的高性能网络,来保证大规模集群执行训练任务时候的稳定性,大幅提升了芯片的有效利用率,而且创新设计了显著降低能耗的散热方案。
声明:本文为 AI 前线整理,不代表平台观点,未经许可禁止对全文或部分内容进行转载。




