
阿里半夜刚发完旗舰模型,这边 DeepSeek 坐不住了,突然发布更新了。

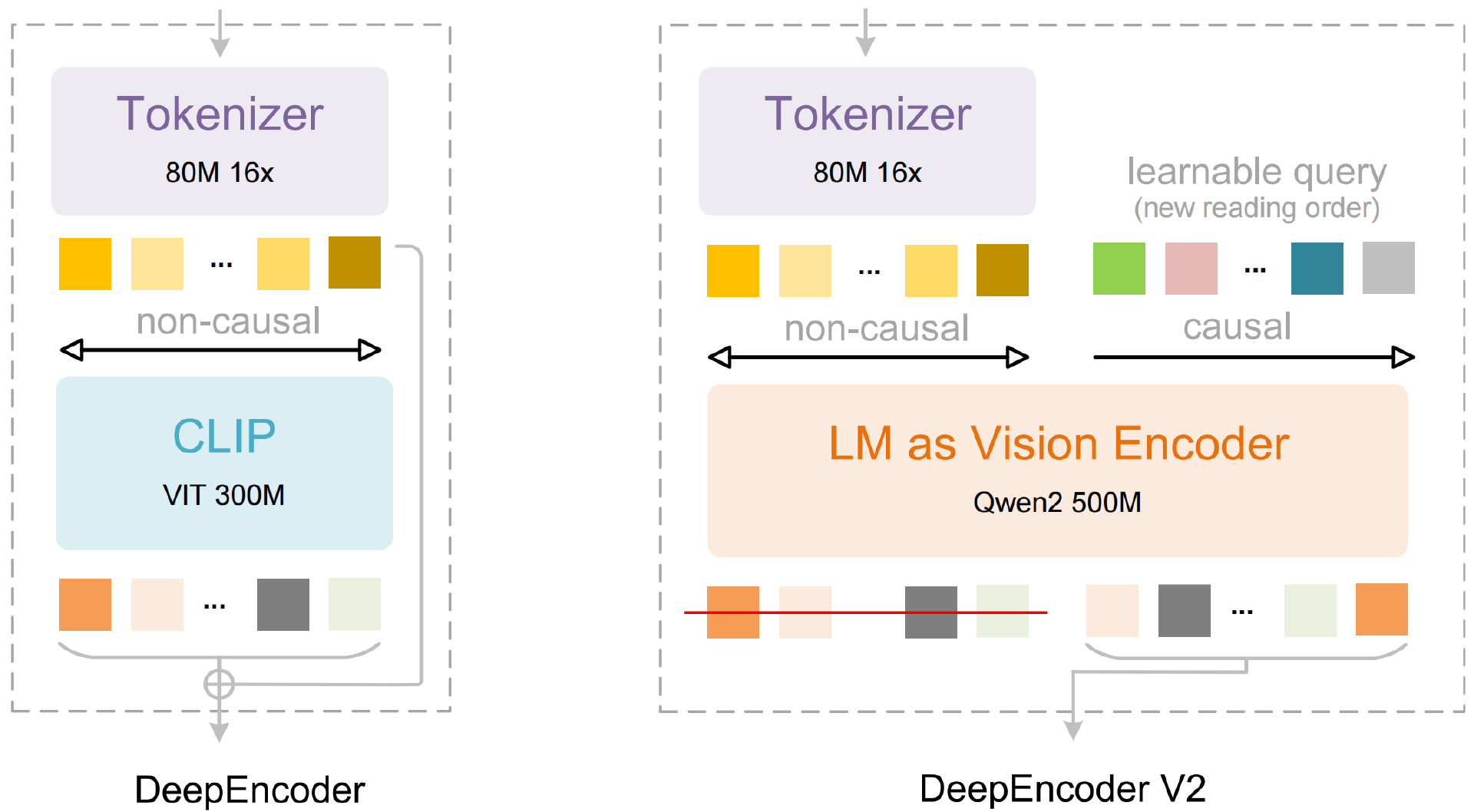
刚刚,DeepSeek 发布了 新模型 DeepSeek-OCR 2,采用创新的 DeepEncoder V2 方法,让 AI 能够根据图像的含义动态重排图像的各个部分,更接近人类的视觉编码逻辑。在具体实现上,DeepSeek 团队在论文中称采用了 Qwen2-0.5B 来实例化这一架构。
如果说去年 10 月 DeepSeek-OCR 的发布,让行业第一次意识到“视觉压缩”可能是一条被严重低估的技术路线,那么现在,DeepSeek 显然决定把这条路走得更激进一些。
DeepSeek-OCR 2 有何不同?
在传统 OCR 体系中,无论是经典的字符检测—识别流水线,还是近年来多模态模型中的视觉编码模块,本质上都遵循同一种思路:对图像进行均匀、规则的扫描和编码,再将结果交给语言模型或后续模块处理。
这种方式的问题在于,它并不关心“哪些视觉区域真正重要”。
DeepSeek-OCR 1 之所以在当时引发讨论,正是因为它将 OCR 看作一种 视觉压缩问题:不是尽可能多地保留像素信息,而是将视觉内容压缩成更有利于语言模型理解的中间表示。
而在 DeepSeek-OCR 2 中,这一思路被进一步推进。
根据技术报告,DeepEncoder V2 不再将视觉编码视为一次静态的、固定策略的扫描过程,而是引入了语义驱动的动态编码机制。模型会在编码阶段就开始判断哪些区域更可能承载关键信息,并据此调整视觉 token 的分配与表达方式。

换句话说,视觉编码不再只是“预处理”,而是已经提前进入了“理解阶段”。
和 DeepSeek 过往几乎所有重要发布一样,这一次依然选择了模型、代码与技术报告同时开源。项目、论文和模型权重已同步上线:
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf




