
上周,月之暗面放了个“大招”,发布并开源了 Kimi K2“增强版”:Kimi K2 Thinking,主打“模型即 Agent”,一上线便激起千层浪。
Hugging Face 联合创始人 Thomas Wolf 惊叹道:
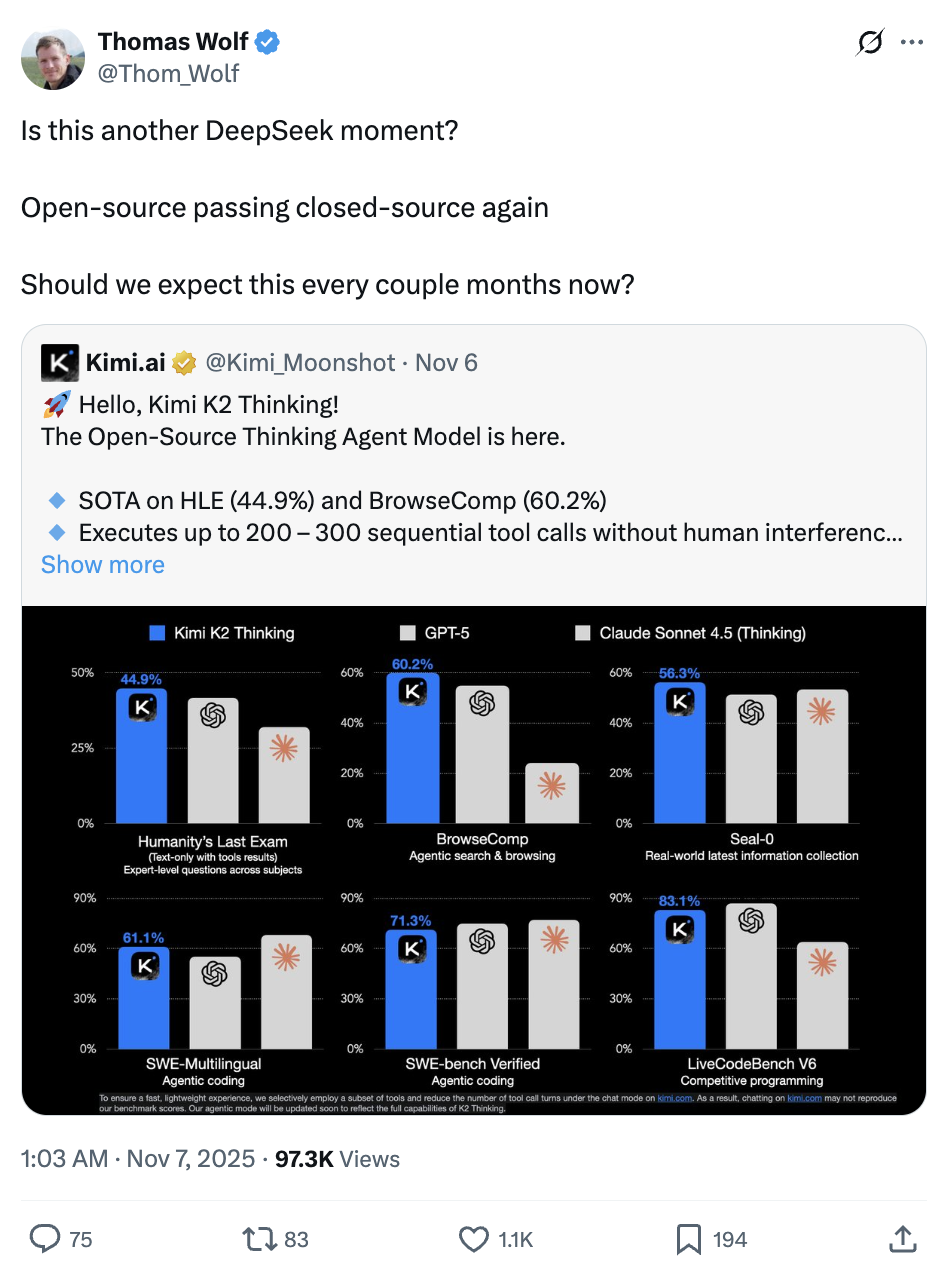
“这是另一个 DeepSeek 时刻吗?”
而今天凌晨,杨植麟本人和其他两位联合创始人对 K2 Thinking 的一系列问题作出了首次回应,他们在 Reddit 上开展了场干货满满的 AMA(有问必答)活动,直面网友的一大堆犀利问题。

如图,参与者依次为:杨植麟、周昕宇、吴育昕
主要回复可概括为:
K2 的 KDA 注意力机制 的核心思想,将在 Kimi K3 中延用
网传的 “460 万美元的成本” 不是官方数据,具体训练成本很难量化
计划推出 视觉语言模型(Vision-Language Model),而且已经在做了
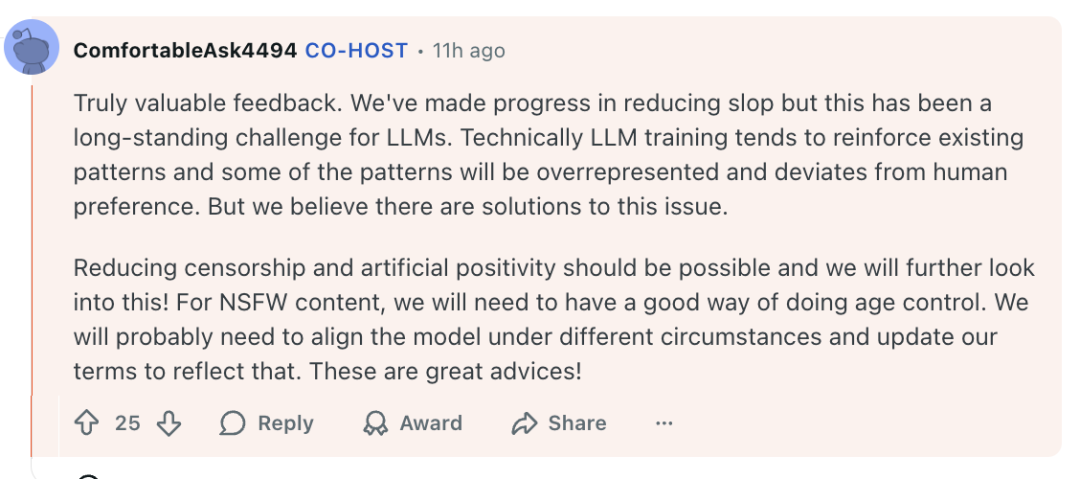
在 减少 slop 方面取得了一定进展,但这是 LLM 长期存在的挑战
……
这里再简单回顾一下 K2 Thinking 有多牛:
K2 Thinking 在 HLE(Humanity’s Last Exam,一项超高难度的 AI 基准测试),BrowseComp( AI“上网推理”与信息检索、理解类基准测试)等重要全球测试中成绩亮眼,超越了 GPT-5、Claude 4.5 等全球最强开源乃至闭源模型。
在 AIME25(公认的数学推理基准之一)也表现优异,和 GPT-5、Claude 4.5 几乎打了个平手,远超 DeepSeek V3.2。
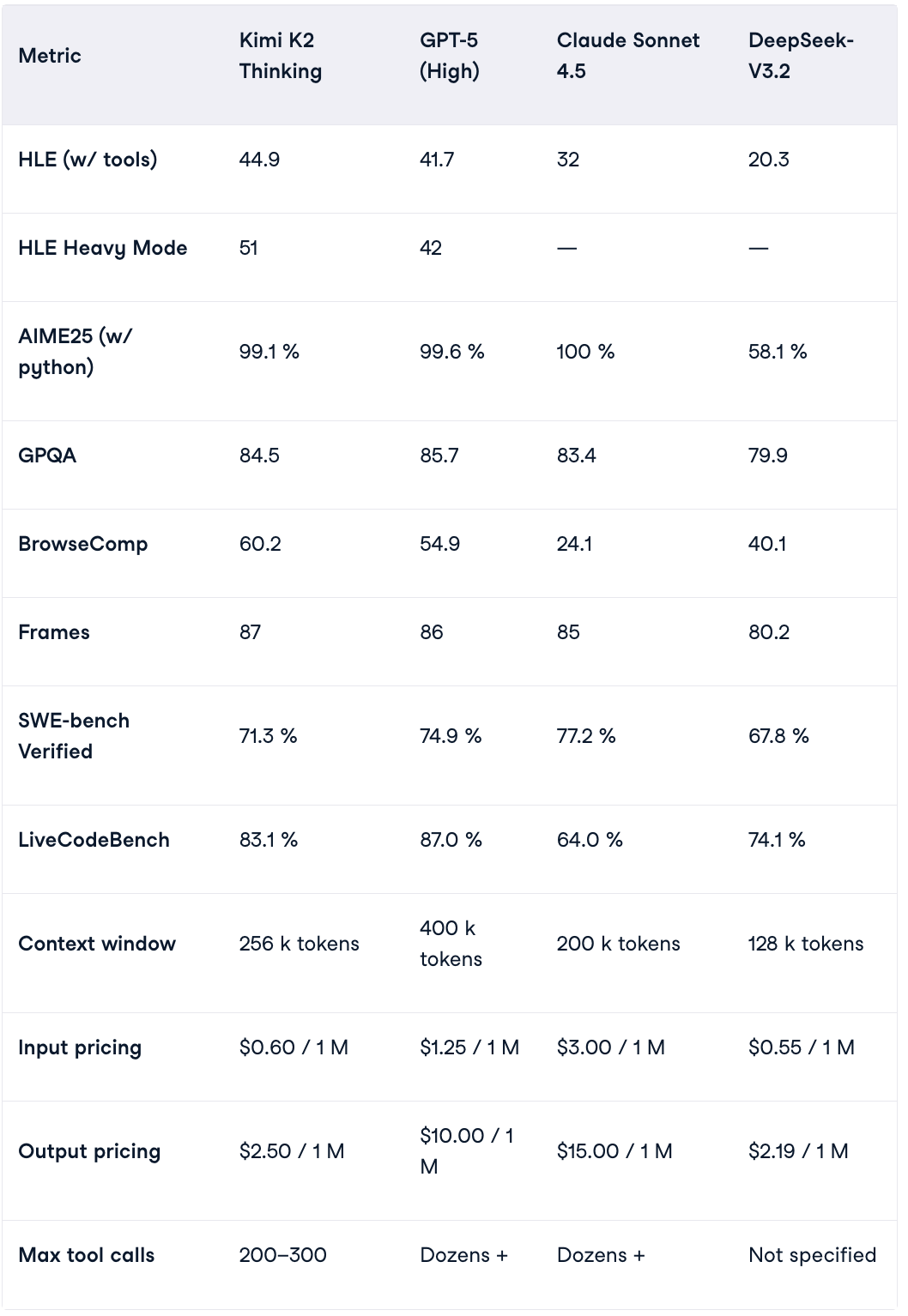
图源:datacamp
下面来具体看看月之暗面团队对 K2 Thinking 的回应。
回应了哪些要点
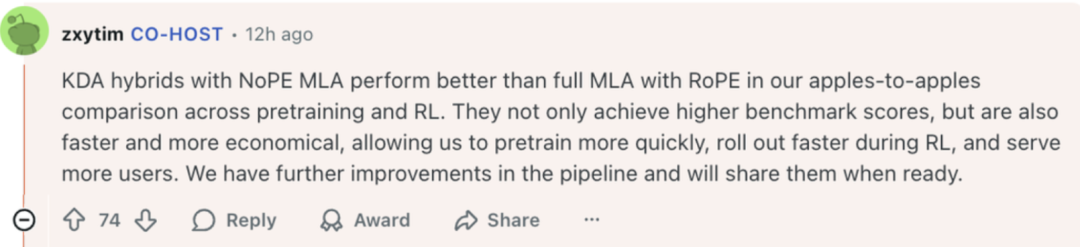
Kimi K2 系列里有一个很关键的创新机制:KDA(Kimi Delta Attention), 它使用"增量更新(delta)+门控(gating)"的方式替代传统的 full attention。
KDA 最关键的作用,是弥补了 MoE 模型常见的“长上下文一致性差”、“KV 缓存大”等问题。简单来说,它相当于 Transformer 架构中的一个“高性能 Attention 引擎”。
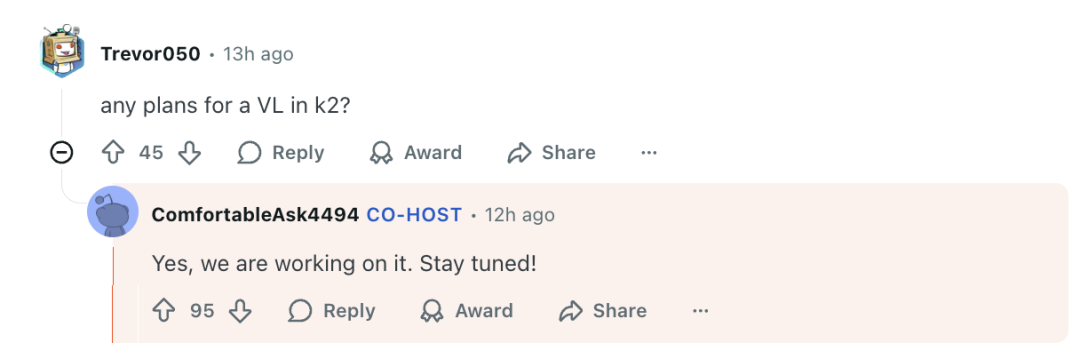
有网友问,Kimi 的下一代旗舰模型还会使用 KDA 吗?杨植麟表示,那是相当有希望的:
“KDA 是我们最新的实验性架构... 相关思想很可能会在 K3 中得到应用。”
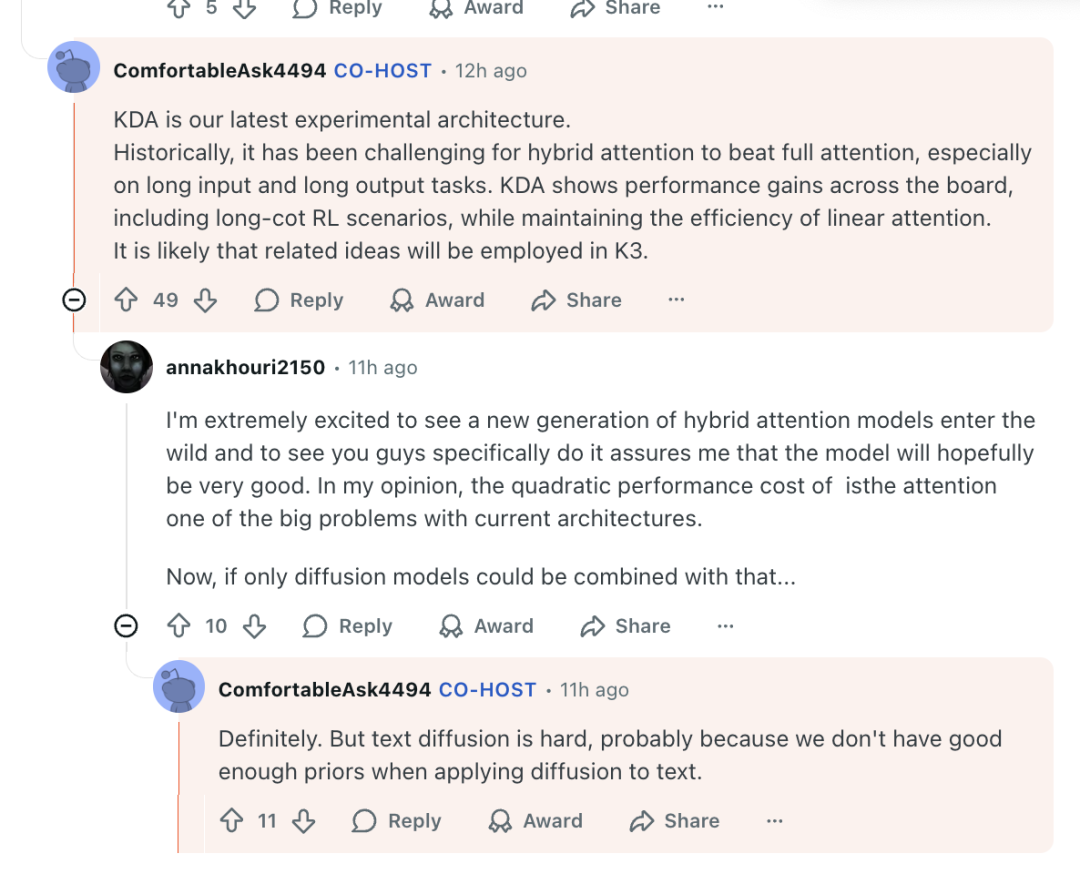
月之暗面联创周昕宇补充称,团队正在开发更多关于 KDA 改进方案,完成后会与大家分享。
说到 Kimi K3,还真有人问了一嘴这玩意打算什么时候出,杨植麟调侃道:
“在(OpenAI 的)Sam Altman 的万亿美元数据中心建成之前。”
(众所周知,OpenAI 的万亿美元数据中心起码要花 8 年才能建成,而且能不能建成也是个问题)
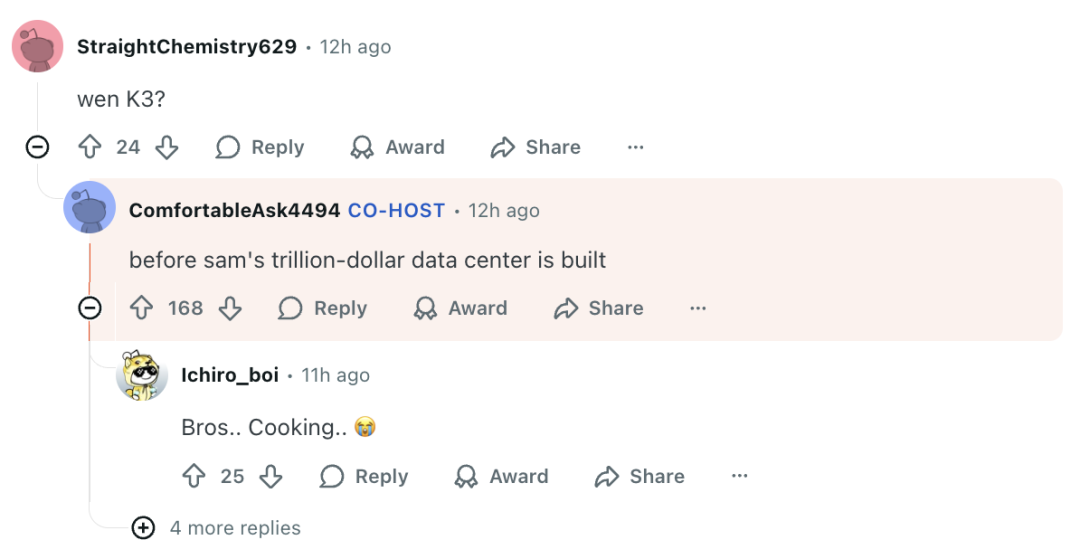
此外,还有网友提出 K2 未来是否会推出 视觉语言模型(VL),杨植麟给出肯定答复:
“是的,我们正在努力。敬请期待!”
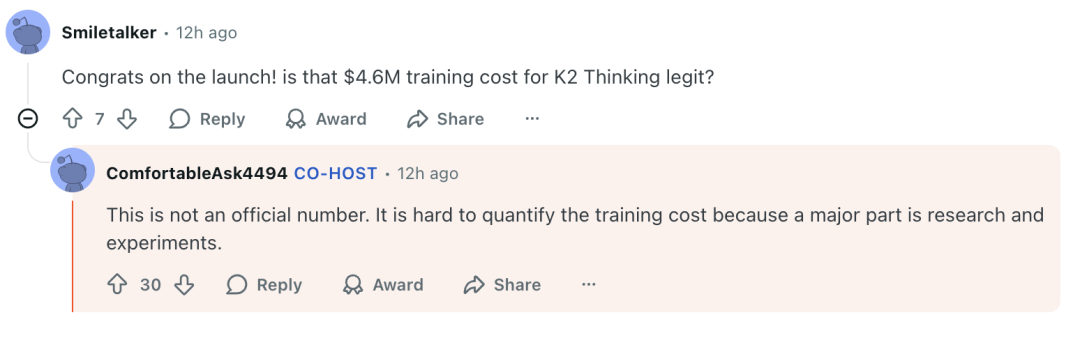
对于网传的网上广泛传播的“训练成本仅 460 万美元”,杨植麟否认其为官方数字,并表示:
“培训成本很难量化,因为其中很大一部分用于研究和实验。
在七嘴八舌的网友中,不乏真上手细品 K2 Thinking 的人,他们提出了一些更深入的问题。
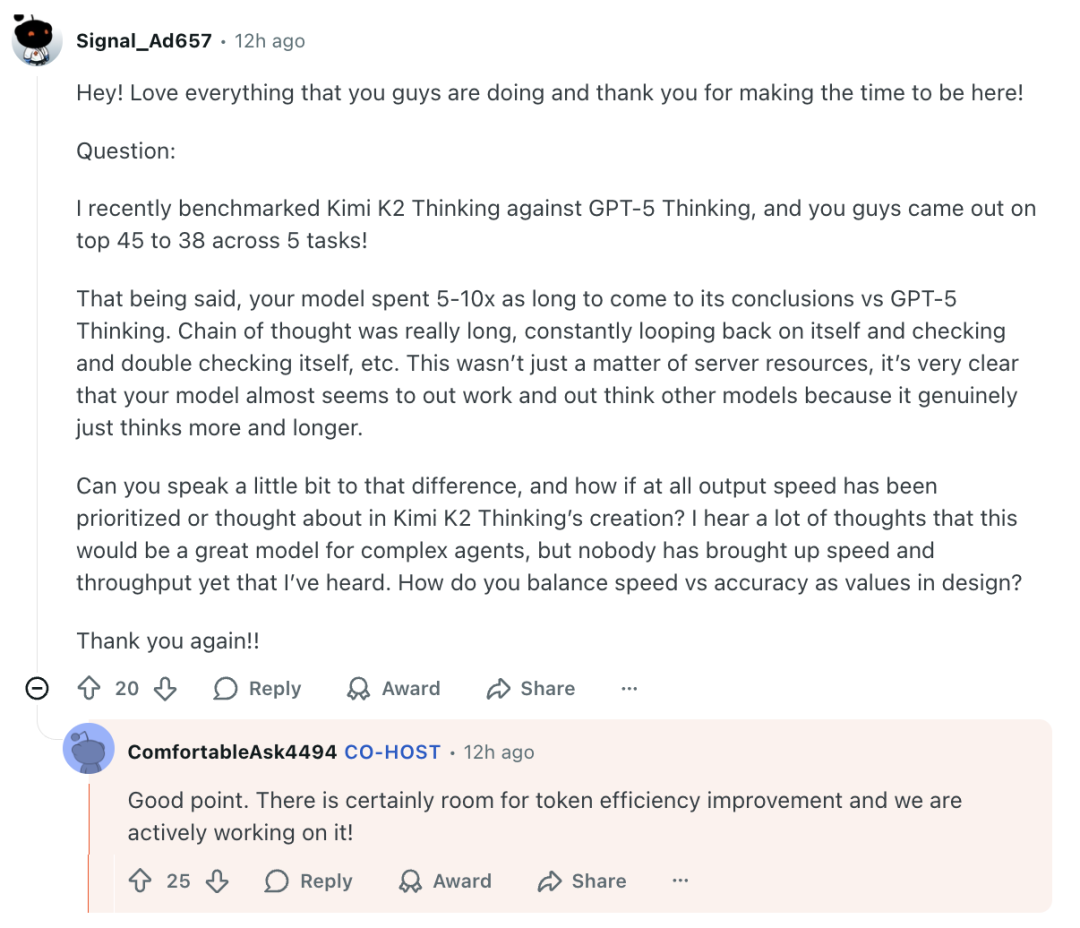
比如,有网友发现,K2 Thinking 比 GPT-5 更“聪明”、在复杂任务上推理结果更好;但问题是:速度慢很多(5–10 倍)。他进一步研究发现:这不是算力问题,而是 K2 Thinking 真的“想太多”了。
于是抛出问题:
“你们在设计 K2 Thinking 时,是如何平衡速度和准确性的?”
杨植麟表示,这与模型内部的“长链式推理机制”有关:
“(速度)确实还有改进空间,我们正在积极提升 token 效率。”
也就是说,对于智能体(Agent)和复杂推理任务,团队在速度与思维深度之间更侧重于后者,但也在努力提速。
还有位网友直言:
“Kimi K2 Thinking 是目前最好的创意写作(creative writing)模型之一,但还有提升空间。”
他指出:模型输出存在 “slop 问题”,即语言啰嗦、重复,文风缺乏节奏和情绪变化,有时词句堆叠、逻辑松散等。
尽管 Kimi K2 比 OpenAI / Anthropic 等模型限制更少、语气更自然,但其在描写真实人性矛盾、情绪激烈的对话时,仍会自动“净化”内容,使作品显得“过于温和”,缺乏人性真实的张力。
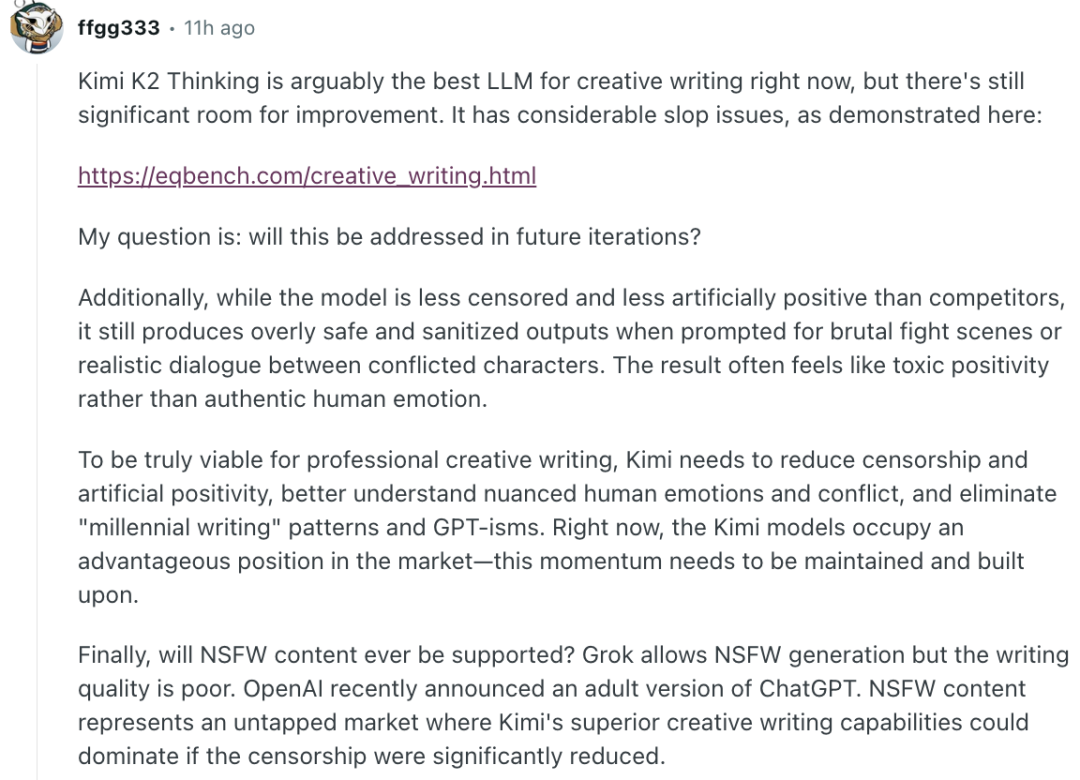
杨植麟称此为非常好的反馈,还给出了一段较详尽的回复:
“我们已经在减少 slop 方面取得了一定进展,但这是 LLM 长期存在的挑战。”
还表示团队也意识到模型的“人性张力”不足,未来版本可能在情绪表达上更开放、更真实
“减少 censorship 和 artificial positivity 是可能做到的,我们会进一步研究。”
K2 Thinking 让月之暗面打了个翻身仗
可以说,Kimi K2 Thinking,让月之暗面打了个漂亮的“翻身仗”。
在融资传闻与全行业苦等 DeepSeek R2 的空窗期,月之暗面推出了这个迄今最强的开源思考模型,引起广泛关注。
它基于 Kimi K2 打造,延续并超越 DeepSeek R1 的架构——万亿级 MoE、原生 INT4、256k 上下文,一次可稳定完成 200 多次工具调用,让开源阵营的“思考引擎”首次具备正面对抗闭源巨头的底气。
与以往大模型最大的不同在于,Kimi K2 Thinking 是从一开始就按“Agent”来设计的。
Kimi K2 Thinking 同时在推理、搜索、编码、写作等多个维度完成了系统性升级,以原生 INT4、超稀疏 MoE 和 Test-Time Scaling 的组合。
它不是一个被动回答问题的聊天模型,而是一个会自己规划、自己行动的思考系统。
无需任何人工干预,它就可以自主完成 200–300 次连续工具调用,在跨度极长的多步任务中维持逻辑一致的推理链,把 “边思考,边用工具” 变成日常能力,而不是 demo 级的炫技展示。
这背后,是对模型在测试时进行扩展(Test-Time Scaling)的系统性投入:一方面扩展思考 Token,允许模型“想得更久”;另一方面增加可用的工具调用轮次,让模型在真实环境中“做得更多”。
这种“原生智能体”设计,首先带来了推理能力的质变。
在 HLE、BrowseComp、SWE-Bench 等多项高强度评测中,K2 Thinking 展现出连贯、稳定且具深度的推理表现,能够在复杂任务中保持逻辑一致与目标导向。
更关键的是,它具备 “稳定的思维深度”:不依赖单步推断,而是能在数百步推理链中循环验证与修正,形成类似人类专家的思考节奏。
在官方演示中,它通过 23 次“思考—工具调用”循环,解决了一道博士级数学题,几乎重现了一名博士生攻克难题的思维节奏。
第三方评测机构 Artificial Analysis 的数据进一步印证了这一点——在𝜏²-Bench Telecom 智能体测试中,K2 Thinking 的得分高达 93%,较上一代模型提升 20 个百分点。这不仅是一场技术升级,更是开源模型在推理智能上的一次跃迁。
Kimi K2 Thinking 在编码能力 上的表现,标志着开源模型第一次真正具备了“智能体级”开发能力。
它在 SWE-Multilingual、SWE-Bench Verified、Terminal-Bench 等业界权威基准中分别取得 61.1%、71.3% 和 47.1% 的成绩,展现出对多语言、多环境开发任务的系统性掌握。
若说推理是 “脑子好用”,那么编码则是 “手也要巧”,K2 Thinking 证明了自己在这两方面都能兼顾。
与 GPT-5、Claude Sonnet 4.5 等闭源旗舰相比,它已能在真实工程场景中分庭抗礼。更重要的是,它不再局限于代码片段补全,而是具备完整的 Agentic 编程思维。
在实际开发流程中,K2 Thinking 不再只生成代码,而能完成从需求理解到调试验证的完整闭环。它能够自主调用多种工具,配置环境、生成与修正代码,让开发过程更像一次与智能协作者的配合。
在 HTML、React 等前端任务中,它能将创意快速转化为可交互产品,体现出从“写代码”到“懂工程”的进化。K2 Thinking 不再只是工具,而更像一位能理解语境、具备执行力的虚拟工程师。
在智能搜索与网页浏览 任务中,K2 Thinking 的表现更像一位能“刨根问底”的研究员。
在 BrowseComp 等真实网络评测中,它能够在 “思考—搜索—阅读—再思考” 的循环中持续推进,每一轮都在修正假设、更新证据、重构推理路径。
这种 “边搜索边推理” 的机制,使它尤其擅长处理起点模糊、目标不明的问题——先将问题拆解成可执行步骤,再通过检索与验证逐步收敛到最终答案。
得益于 Test-Time Scaling 的设计,K2 Thinking 可以“用时间换取推理深度”:面对复杂任务,它的工作方式更像在完成一个研究项目,而非执行一条指令。
而在很多人最直观感知的写作与通用能力 上,K2 Thinking 也不再只是“能写”。
在创意写作中,K2 Thinking 能将零散灵感组织成结构清晰、节奏自然的长篇文本;在学术与研究场景,它能像研究助理一样拆解复杂任务,保证逻辑与结构一致性。对于日常对话,它的回应更细腻平衡,兼具可执行性与情感理解。
Kimi K2 Thinking 的强大,并非源于单一的算法突破,而是一整套底层工程与架构上的“组合拳”。它既重构了注意力机制,也重新定义了推理效率的极限。
首先,在推理性能上,K2 团队做出了一个几乎“逆主流”的选择——放弃 FP8,转向更极端的 INT4 量化。
在大模型界,这无异于在刀尖上起舞:低比特量化意味着精度被压缩四倍,而长链路思维模型恰恰最依赖数百步的稳定推理。
然而,K2 团队用一种极富工程智慧的方式化解了这一矛盾——在训练阶段就引入 量化感知训练(QAT),让模型从一开始就学习如何在低比特环境下稳定运行;同时,对 MoE 组件 仅做权重量化,以平衡性能与速度。
结果就是 K2 Thinking 在几乎不损失精度的前提下,推理速度提升了约两倍,显存占用显著下降,并首次在原生 INT4 精度 下完成全部基准测试。
这意味着,它不仅在实验室中高效,在真实部署环境下也能保持同样的稳定表现。
真正让 K2 Thinking 脱颖而出的,是在注意力机制上的系统性重构——KDA。
在传统全连接注意力中,计算量随上下文长度呈平方增长,长序列任务常导致显存与缓存暴涨。
而 K2 Thinking 在“Kimi Linear”架构中引入的 KDA 通过“只更新变化部分”实现增量式计算,显著降低 KV 缓存与显存开销(论文数据显示可减少约 75%)。
同时,门控机制能动态捕捉关键信息,使模型在不同专家(MoE)间切换时仍保持语义连续与思维一致。
如果说 MoE 让模型更“大”,KDA 则让它更“稳”;前者扩展了容量上限,后者保障了思维连贯。两者共同支撑了 K2 Thinking 在长推理和多阶段任务中的稳定表现。——既能像研究者一样深思,又能像工程师一样高效执行。
从更宏观的层面看,K2 Thinking 代表了一种新型工程范式:
通过架构、量化与调度的协同优化,实现了思维深度与推理效率的平衡。它揭示了一个新的方向——大模型的未来,不只是更大,而是更聪明、更轻、更能真正思考。
传送门:
https://www.reddit.com/r/LocalLLaMA/comments/1oth5pw/ama\_with\_moonshot\_ai\_the\_opensource\_frontier\_lab/
参考链接:
https://moonshotai.github.io/Kimi-K2/thinking.html?utm\_source




