
早前在回答为什么要自研超算 Dojo 时,马斯克曾表示,“解决自动驾驶的唯一方法是解决现实世界中的 AI 问题,无论是硬件还是软件,而这也是特斯拉正在做的事情。除非一家公司具有很强的 AI 能力以及超强算力,否则很难解决自动驾驶难题。”
特斯拉公布自研超算 Dojo 细节
近日,在 Hot Chips 34 大会上,特斯拉公布了大量自研超算 Dojo 的细节,并发布了两个有关 Dojo AI 超级计算机的深入演示。
本质上,Dojo 是一种可组合的规模化超级计算机,与我们熟悉的五百强超算系统不同,Dojo 是一套完全可定制架构,全面涵盖计算、网络、输入/输出(I/O)芯片,乃至指令集架构(ISA)、供电、封装和冷却。所有这些都服务于同一个目标:大规模运行定制化机器学习训练算法。
据了解,Dojo 发布于 2021 年 8 月特斯拉 AI Day,特斯拉硬件工程高级总监、Dojo 项目负责人 Ganesh Venkataramanan 当时曾上台就 Dojo 的主要性能进行了展示。
Ganesh Venkataramanan 表示,马斯克想要一台超快的训练计算机来训练 Autopilot。因此,Project Dojo 诞生了。Dojo 架构拥有一个大规模计算平面,极高宽带和低延迟。作为 Dojo 架构的重要组成部分,D1 芯片采用 7 纳米制造工艺,处理能力为每秒 1024 亿次。
Venkataramanan 认为,将一组这样的芯片放置在单个“训练片”上,以提供每秒九千万亿次的计算能力,并将 120 个芯片放在多个服务器机柜上,达到每秒超过 1 千万亿次的计算能力。这些芯片可以帮助训练模型来识别特拉斯汽车摄像头中收集到的各种物品。训练模型需要大量的计算工作。
在近期举办的 Hot Chips 34 大会上,Venkataramanan 在主题演讲中称,“现实世界中,海量数据的处理只能通过机器学习技术来实现,而由此支撑起的应用场景则包括自然语言处理、基于视觉设计的自动驾驶、与日常环境交互的机器人技术等。”
他同时承认,传统的分布式工作负载扩展方法并不能跟上机器学习对于处理速度的需求。时至今日,摩尔定律已经帮不上多大的忙,CPU 加 GPU 的组合、或者是极少数配备专用 AI 加速器的方案,也远未达到人们对于大规模 AI/ML 训练系统的性能预期。
Dojo 的三明治式数据中心
Venkataramanan 表示,“在过去,我们会先制造芯片,再把它纳入封装、部署进印刷电路板、接入系统,最后把系统安装在机架内。”问题在于,每当数据从芯片移向封装、或者由封装移出时,都会产生相应的延迟和带宽损失。
为了克服这些限制,Venkataramanan 和他的团队决定从零起步、重新设计。“在当初接受马斯克的面试时,他就问我能不能在 CPU 和 GPU 之外,给 AI 场景一个新的答案。我们整个团队一直在为此而努力。”

于是,Dojo 训练单元应运而生。这是一个独立的计算集群,体积约为 1.5 立方英尺,能够在 15 kW 液冷封装中实现每秒 556 万亿次 FP32 浮点运算。每个单元都配备有 11 GB 的 SRAM,并在整个堆栈中以自定义传输协议通过 9 TB/s 结构实现互连。
Venkataramanan 介绍称,“这个训练单元以前所未有的集成度,把计算机中的内存、电源、通信等机制整合了起来,无需任何额外交换设备。”
这个训练单元的核心就是 Dojo D1,一款包含 500 亿个晶体管的芯片,采用台积电 7 纳米制程工艺。特斯拉表示,每块 D1 芯片能够在 400 瓦最大散热功率下实现每秒 22 万亿次的 FP32 浮点运算。此外,该芯片还能支持包括自定义计算在内的其他多种浮点运算。

Venkataramanan 表示,“从每平方毫米的晶体管密度来看,Dojo D1 可能是当前最先进的技术成果。”
特斯拉将 25 块 D1 裸片用台积电的代工技术封装起来,由此“以极低延迟与极高带宽实现了对大量计算元件的集成”。然而,片上系统设计和垂直堆叠架构,也在供电层面带来了新的挑战。
根据 Venkataramanan 的介绍,目前大多数加速器都会将电源直接放置在芯片附近。他解释称,虽然也能通过验证,但这种方法使得加速器的大部分区域只能专门放置这些组件。而 Dojo 则反其道而行,选择直接通过芯片底部传输电力。
组装成形
“我们可以用这个训练单元构建起整个数据中心甚至是整栋服务器大楼,但训练单元只是计算的部分,我们还得考虑资源的实际交付。”

为此,特斯拉开发出 Dojo 接口处理器(DIP),负责充当主机 CPU 和训练处理器间的桥梁。DIP 还可以提供共享高带宽内存(HBM)与高速 400 Gb/s 网卡。每个 DIP 包含 32 GB HBM,最多能够将五块 DIP 卡以 900 GB/s 的速度接入同一训练单元,因此主机总传输速率达 4.5 TB/s、单个单元 HBM 容量可达 160 GB。
特斯拉的 V1 双单元配置方案就一口气用上了 150 块 D1 芯片,能够支持四块主机 CPU、每台主机配备五块 DIP 卡,号称能实现百亿亿次 BF16 或 CFP8 性能。
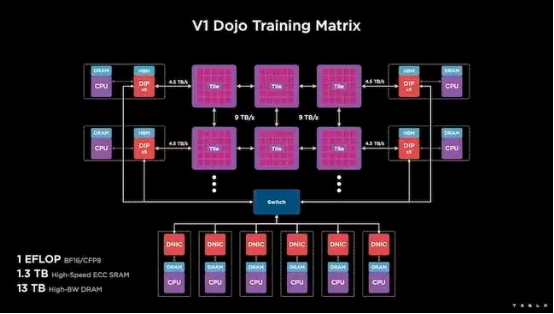
Venkataramanan 称该架构帮助特斯拉成功克服了英伟达与 AMD 等传统加速器中的固有限制。“传统加速器的工作原理,是将整个模型部署到各个加速器内、多次复制,让数据流经每个加速器。但随着模型体量越来越大,结果会怎么样?这些加速器的内存可能不足以存放完整模型,到时候就没有训练效果可言了。”
这其实并不是新问题。英伟达的 NV-switch 就能够跨多个 GPU 实现内存池化。然而,Venkataramanan 认为这不仅增加了复杂性,而且引入了额外的延迟与带宽损失。“我们从设计之初就考虑到了这一点,所以我们的计算模块和每块裸片都是专为大型机器学习模型的训练而生。”
可编程性将直接决定 Dojo 的成败
很明显,这样一套专门的计算架构需要与之配套的特殊软件堆栈。Venkataramanan 和他的团队也意识到,可编程性将直接决定 Dojo 的成败。
“在我们设计这些系统时,最关注的问题就是软件的编程便捷性。研究人员可不会坐等我们手动编写出新内核之后,再尝试运行新算法,人家直接就换架构了。”
为此,特斯拉放弃了使用内核的思路,开始围绕编译器设计 Dojo 架构。“我们决定使用 PyTorch,创建出中间层以通过并行化扩展底层硬件。底层的一切都是编译代码,这也是保证软件堆栈适应未来所有工作负载的唯一方法。”
尽管一直在强调软件灵活性,但 Venkataramanan 也承认他们的平台目前只能在实验室内支持特斯拉自己的工作负载。
他总结道,“我们首先得关注内部客户的需求。马斯克已经公开表示,这些成果将随时间推移逐步向其他研究人员开放,但我们还没有制定具体的开放时间表。”




