
1 月下旬,字节正式设立代号为“Seed Edge”的研究项目,目标是探索 AGI 的新方法,其中“Seed”是豆包大模型团队名称,Edge 代表最前沿的 AGI 探索。
该项目团队近日发布了其最新的研究成果:一项针对 MoE 架构的关键优化技术 Comet,可将大模型训练效率提升 1.7 倍,成本节省 40%。
据悉,相较 DeepSeek 近期开源的 DualPipe 等 MoE 优化方案,Comet 可以像插件那样直接接入已有的 MoE 训练框架,支持业界绝大部分主流大模型,且无需对训练框架进行侵入式改动。Comet 也可以与 DualPipe 方案联合使用。
Comet 主要解决的是 MoE 模型里的专家放置挑战。单个 GPU 无法容纳所有专家,通常做法是将专家分布在不同的 GPU 上,因此 GPU 之间需要频繁地交换数据。为了减少通信开销,一种有效的策略是将通信与专家计算重叠。
Seed 团队指出,在分布式环境中,通信与计算的重叠存在两个问题:第一,随着数据块规模的缩小,计算效率降低,导致 GPU 计算资源的利用不足。此外,粗粒度的划分在通信的初始和结束阶段会导致不可避免的 GPU 空闲时间。第二,由于 MoE 的动态特性,专家在运行时的输入形状各异,给 GPU 带来了多样化的通信和计算负担。将通信和计算任务封装在不同的内核中,限制了对硬件资源的控制,导致内核性能不稳定,阻碍了通信与计算的无缝重叠。
Comet 则通过两项关键设计实现了通信与计算的细粒度重叠:1. 通过识别 MoE 中通信和计算操作之间的复杂数据依赖关系,优化计算通信管道的结构;2. 通过动态分配 GPU 线程块来平衡通信和计算工作负载,提高延迟隐藏效率。
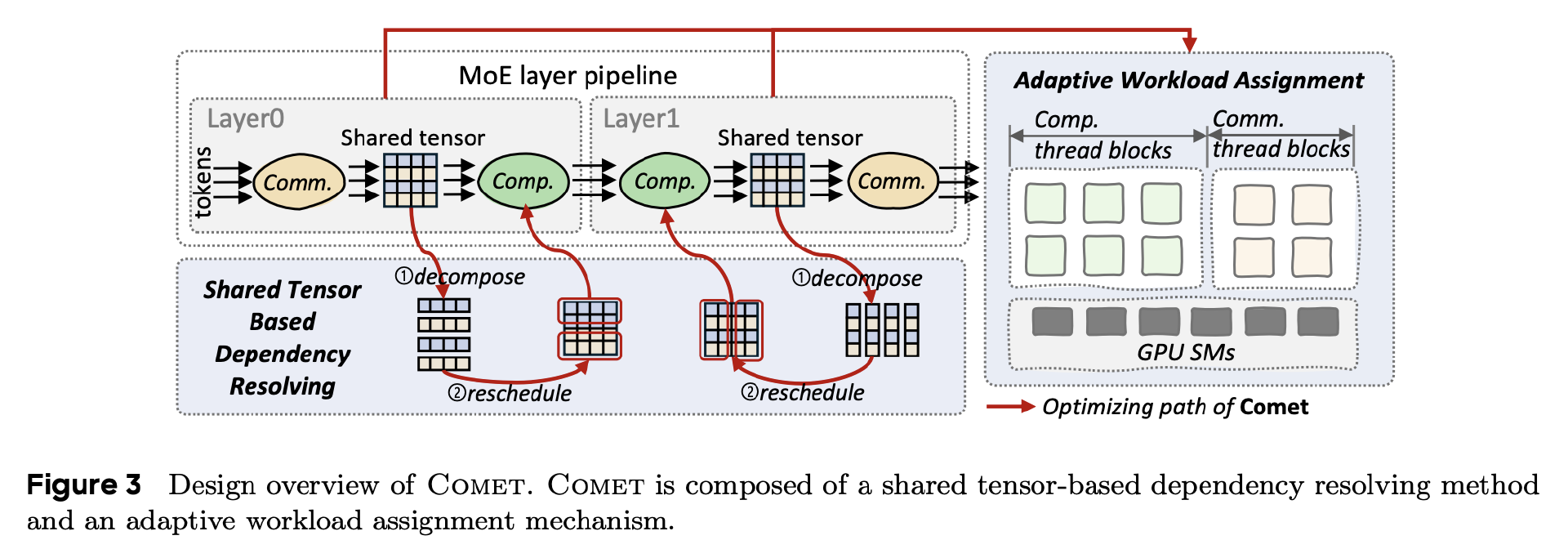
据悉,Comet 由大约 1.2 万行的 C++、CUDA 代码以及 2000 行 Python 代码组成。Comet 提供了一套用户友好的 Python API,开发者可以将这些 API 无缝集成到他们的框架中。
字节在各种并行策略下,将 Comet 集成到了Megatron-LM中,并对其进行了验证。在 Nvidia H800 和 L20 集群上的广泛实验表明,与现有的最先进 MoE 系统相比,Comet 在典型的 MoE 层上实现了 1.96 倍的加速,对于端到端的 MoE 模型执行(如 Mixtral-8x7B、Qwen2-MoE、Phi3.5-MoE 等),平均加速 1.71 倍。当前,Comet 已被部署到拥有超过一万块 GPU 的生产集群中,用于加速大规模 MoE 模型的训练和推理,节省了数百万的 GPU 小时。
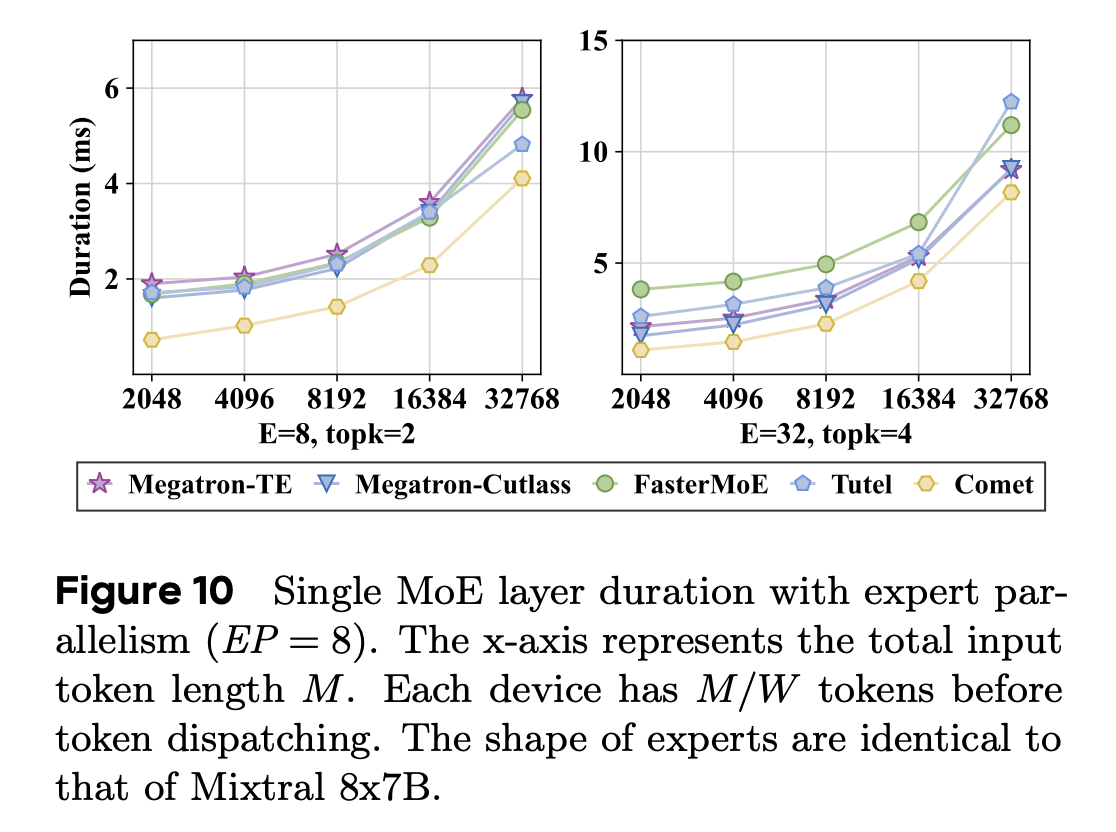
与 Megatron-Cutlass、Megatron-TE、FasterMoE 和 Tutel 相比,Comet 的端到端延迟分别降低了 34.1%、42.6%、44.4%和 31.8%。
开源代码:
https://github.com/bytedance/flux/pull/54/
研发成果单月“三连击”
字节已在内部组建 AGI 长期研究团队,代号“Seed Edge”,核心目标是做更长期、更基础的 AGI 前沿研究。Seed Edge 初步确定了五大研究方向,包括:
探索推理能力边界:探索更高效且更通用、提升模型推理能力的方法;
探索感知能力边界:找到统一生成和理解表示的方法,探索世界模型建模,探索比语言更好的对世界进行表示的建模;
探索下一个 Scaling 方向:在预训练和推理阶段的 Scaling Laws 之外,探索 Multi-Agent 和 Test-Time Training 等方向;
探索下一代学习范式:如探索比 Next-Token Prediction 更高效的学习目标,比 Backpropagation 更高效的学习方法,比大数据 Pretraining+Alignment 更高效的学习范式;
探索下一代软硬一体的模型设计:面向下一代训练和推理硬件的结构特点设计下一代模型,达到训练效率、推理效率、模型性能的多目标同时优化,并进一步压榨下一代硬件能力。
自正式对外公布后,在过去的整个 2 月份,Seed Edge 项目团队公开了三项成果。
团队先是与北京交通大学联合发布和开源了通用视频生成实验模型 VideoWorld。与 Sora 和 DALL-E 不同,它不依赖语言来理解世界,仅仅观察视频就足以学习复杂的任务。同时,它基于一种潜在动态模型,可高效压缩视频帧间的变化信息,显著提升知识学习效率和效果。在不依赖任何强化学习搜索或奖励函数机制前提下,VideoWorld 达到了专业 5 段 9x9 围棋水平,并能够在多种环境中执行机器人任务。
值得注意的是,字节发布 VideoWorld 相关消息的 2 月 10 日,当天视觉认知概念股走强。参与该模型项目的北交大博士 Zhongwei Ren 还在小红书上感叹“学术民工误入华尔街片场”,并称该模型还在“炼丹”阶段。
之后,团队提出了全新的稀疏模型架构 UltraMem,该架构有效解决了 MoE 推理时高额的访存问题,推理速度较 MoE 架构提升 2-6 倍,推理成本最高可降低 83%。该研究还揭示了新架构的 Scaling Law,证明其不仅具备优异的 Scaling 特性,更在性能上超越了 MoE。
此外,团队还提出一个基于大语言模型 (LLM) 和最优先树搜索 (BFS) 的高效自动形式化定理证明系统 BFS-Prover。团队发现,简单的 BFS 方法经过系统优化后,可在大规模定理证明任务中展现卓越性能与效率,无需复杂的蒙特卡洛树搜索和价值函数。在数学定理证明基准 MiniF2F 测试集上,BFS-Prover 取得了 72.95% 准确率,超越此前所有方法。
Seed Edge 研究逐渐“DeepSeek”化
一定程度上,字节要打造的 Seed Edge 项目团队与 DeepSeek 相似。
Seed Edge 鼓励跨模态、跨团队合作,为项目成员提供宽松的研究环境,实行采用更长周期的考核方式,以保障挑战真正颠覆性的 AGI 课题。同时,Seed Edge 也将得到单独的算力资源保障。
根据晚点的报道,字节每半年考核一次绩效,但为 Seed Edge 项目人员提供更长考核周期,同时不做严格的过程考核,而是在项目取得突破进展后再做最终评估。Seed 团队主要考核模型层的效果,Seed Edge 则考核研究成果的价值。
对于 Seed Edge 还有一个特别的考核和激励设计:如果一位研究者经过多轮考核周期后取得了重要的研究成果,字节还会 “补偿” 此前几轮周期的考核绩效,“鼓励探索更长周期、不确定的和大胆的课题”。
而根据在 Seed Edge 实习过的知乎答主 Alan 的表述,“Seed 是国内唯一一家能在实习生身上提供难以想象的高资源投入的地方”。其在经过五轮技术面试以及最后语音部门负责人亲自面试后加入团队,称“这里对于前沿未知技术探索的氛围非常浓厚”,团队不聚焦刷榜,而是真正从 AGI 角度思考问题。另外,团队规模偏向小而精,各成员都很优秀,沟通成本非常低,并给了实习生很高的自由度。
用卡方面,知乎答主 tyfr 提到,自己为了验证一个想法而跑几百卡的实验是稀松平常的,就算任务突然挂了,几百卡空一天,也不会发警报斥责浪费资源。
另外,答主 swtheking 表示,Seed 内部现在很重视外部的 impact 和 research,所以团队里每个人都能有机会出国参与国际会议,将自己的一部分工作发表论文来提升个人和团队影响力。
Seed Edge 项目团队成员也逐渐年轻化,如 VideoWorld 模型的核心作者是在读博士,在字节团队长期实习 3 年。
去年 5 月,为储备最具潜力的研究人才,豆包大模型团队启动了“Top Seed 人才计划”,以极具竞争力的待遇在全球招募顶尖博士毕业生加入。
“我们看中的人一定是最 top 的 5%的人。”字节各部门负责人也表达了对团队成员的期待:进来(字节)之后去做 95%的人做不到的事情;最关键的点其实是创造力,敢于打破我们现在的认知;有坚定的目标和信念,对技术非常有热情、有想象力;有扎实的功底,动手能力也很强;有比较强的好奇心,有探索的欲望;能够承受挫折,“我们日常工作中的挫折感往往是大于成就感的,我们愿意给更长的周期,让大家去解决真正有挑战的事情。”
值得注意的是,近期字节大模型团队进行了一次架构调整。2 月 21 日,原谷歌 DeepMind 副总裁吴永辉博士加入字节担任大模型团队 Seed 基础研究负责人。吴永辉博士主要负责 AI 基础研究探索工作,偏基础研究;而之前负责人朱文佳主要负责模型应用相关的工作,偏模型应用,两个人都在 Seed 部门,都向梁汝波汇报。团队易帅对整体科研氛围的影响尚不知晓。
参考链接:
https://www.zhihu.com/question/4580911331/answer/112547776593




