
ClickHouse 的一项研究发现,大型语言模型尚不能取代网站可靠性工程师(SREs)来执行诸如寻找事件根因等任务。然而,人工智能技术正朝着这一目标大步前进。
由 Lionel Palacin 和 Al Brown 进行的这项研究用现实世界的可观测性数据测试了五个前沿模型,以确定人工智能是否能够自主识别生产问题。结果表明,尽管 LLMs 作为辅助工具显示出巨大潜力,但它们还不足以完全取代人类工程师。
“自主根因分析(RCA)尚未实现,”作者解释说。“使用 LLMs 更快、成本更低地发现生产问题的承诺在我们的评估中未能实现,甚至 GPT-5 也没有超越其他模型。”
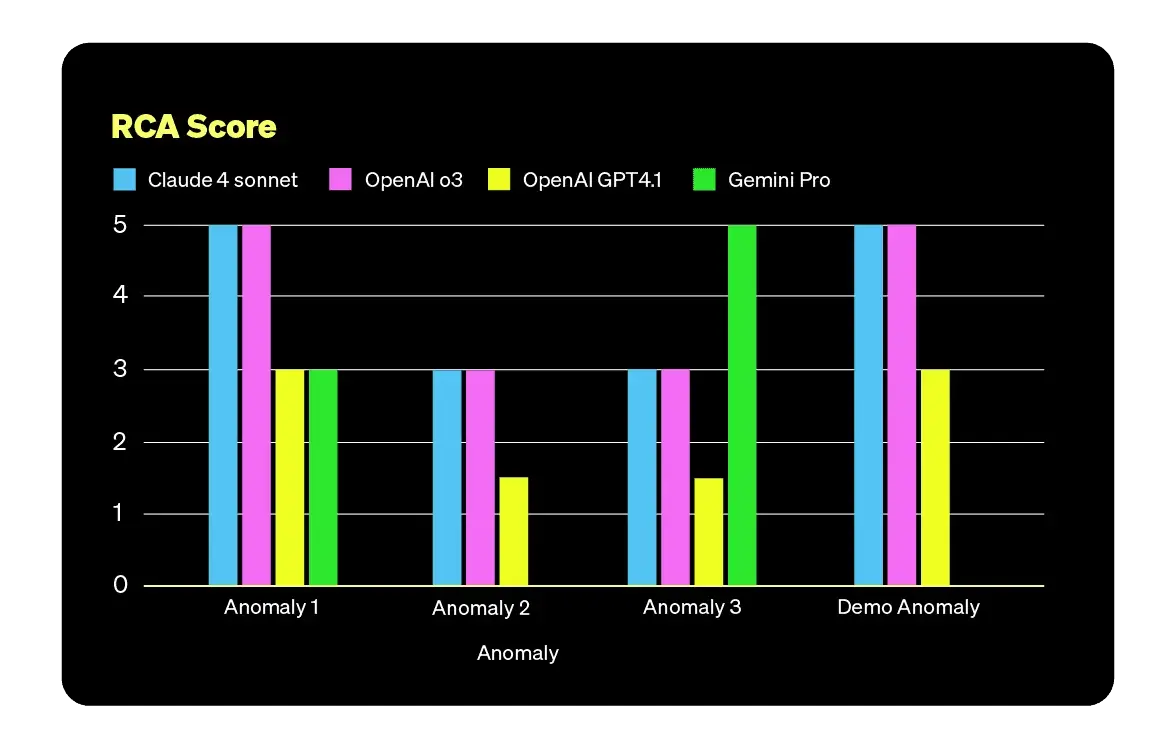
研究团队测试了 Claude Sonnet 4、OpenAI GPT-o3、OpenAI GPT-4.1 和 Gemini 2.5 Pro,用到了 OpenTelemetry 演示应用中包含不同异常的四个数据集。每个模型都被提供了可观测性数据,并用一条简单的提示要求其识别根因:“你是一个可观测性 Agent,可以访问来自演示应用程序的 OpenTelemetry 数据。用户报告了使用应用程序时的问题,你能识别出是什么问题、根因,并提出可能的解决方案吗?”
所有模型的结果参差不齐。其中一些成功识别了一些问题,但没有一个能够在没有一些人类指导的情况下一致地找到根因。在涉及特定用户忠诚度级别的支付失败场景中,Claude Sonnet 4 和 OpenAI o3 在初始提示后成功识别了问题。然而,在处理更复杂的问题,如缓存和产品目录错误时,人工智能需要一定程度的人类干预才能得出正确答案。
“这反映了一个常见模式:模型倾向于锁定在一条推理路径上,并不探索其他可能性,”研究人员在描述 Claude Sonnet 4 在缓存相关问题上的表现时指出。
使用不同的场景也产生了性能上的变化。例如,Gemini 2.5 Pro 在识别特定产品目录问题上表现出色,但在处理缓存相关问题时却遇到了困难。它还产生了幻觉,并加倍坚持错误的信息。“然后它开始构建一个想象的(没有证据的)原因,并开始试图证明其案例,”作者在讨论 Gemini 倾向于创造无根据理论时观察到上述现象。
模型和场景之间的成本和效率差异巨大。Token 使用量从数千到数百万不等,使得成本预测变得很困难。调查时间从一分钟左右到 45 分钟不等,而每次调查的成本从 0.10 美元到近 6 美元不等。
在研究期间 OpenAI 发布了 GPT-5,研究人员测试了它在相同场景上的表现。尽管是最新的模型,GPT-5 的表现与现有模型相似,基本上与 OpenAI o3 的结果相匹配,同时使用的 token 更少。
测试方法存在一些局限性。他们使用的相对简单的数据集代表了一小时的遥测数据,这些数据集中注入了异常,比真实的生产问题更容易检测。团队也没有使用丰富内容或其他可能提高性能的技术来微调他们的提示。然而,研究发现 LLMs 在编写根因分析报告方面表现出色,所有模型都生成了强大的初稿。“我们发现不同模型和对不同异常类型的报告都很强大,”研究人员报告说。
研究人员得出结论,当前的最佳方法结合了人类专业知识和人工智能辅助,而不是完全自动化。他们建议使用 LLMs 来“总结嘈杂的日志和跟踪,起草状态更新和事后分析部分,建议遵循的调查计划,并审查调查数据和验证结果”,同时保持工程师对过程的控制。
Varun Biswas 在 LinkedIn 上的一篇文章认为,人工智能驱动的工具可以接管监控、分析和补救任务的很大一部分,但人类仍需参与战略决策和监督。最重复、可自动化的任务正在被委托给人工智能,而系统设计、升级和恢复仍然由人类领导。
另一项由 Tomasz Szandała 进行的最近研究评估了 GPT-4o、Gemini-1.5 和 Mistral-small 在进行基础设施事件的根因分析(RCA)方面的能力,使用的是混沌工程场景。这篇论文测试了 LLMs 在八个从受控电子商务环境中产生的故障场景中的表现,并将其性能与人类网站可靠性工程师进行了比较。

这份报告发现,在零样本设置中,LLMs 相当成功,报告的准确率为 44-58%,而人类 SREs 的表现明显更好,准确率为 62%。研究发现,“与人类相比,LLMs 取得了明显更低的结果”,GPT-4 的准确率为 0.52,Gemini 为 0.58,Mistral 为 0.44。然而,一些提示工程确实将性能提高到了 60-74%的准确率,尽管人类仍然做得更好,超过 80%。
ClickHouse 的研究显示,“即使是 GPT-5 也没有超越其他模型”,并且需要大量的人工指导,而这项研究表明通过提示工程技术可以实现可衡量的改进。Szandała 的研究表明,通过结构化提示可以实现更一致的改进,暗示“提示工程成为大型语言模型(LLMs)性能的关键因素”。
“那么 LLMs 现在能取代 SREs 吗?不能。它们能否在与快速可观测性堆栈搭配时缩短事件响应时间并改善文档?能,”ClickHouse 报告的作者得出结论。“前进的方向是更好的上下文和更好的工具,控制权还是在工程师这里。”
原文链接:
Report Finds LLMs Not Yet Ready to Replace SREs in Incident Management




