
核心要点
在企业内部环境中部署的 Apache Kafka Stretch 集群存在较高的服务不可用风险,尤其在广域网(WAN)中断时,常导致脑裂(split-brain)或脑死亡(brain-dead)的场景,并可能因恢复时间目标(RTO)和恢复点目标(RPO)恶化而违反服务级别协议(SLA)。
对 Kafka 环境进行主动监控以了解跨 broker 的数据偏斜至关重要,单个节点上的不均衡数据负载可能导致 stretch 集群的故障。
升级过程或糟糕的安全措施会导致 broker 非正常关闭,这可能会使 Kafka 服务不可用,导致数据丢失。
有三种流行且广泛使用的 Kafka 灾难恢复策略,每种策略都存在其挑战、复杂性和陷阱。
Kafka Mirror Maker 2 灾难恢复配置中的复制延迟(Δ)可能会导致消息丢失和数据不一致。
Apache Kafka 是一个人们熟知的发布-订阅分布式系统,它在各个行业中得到了广泛使用,主要用于日志分析、可观测性、事件驱动架构和实时流处理等使用场景。其分布式特性使其成为现代流处理架构的关键组成部分或基石,它提供了许多集成选项,并支持近实时或实时的延迟要求。
如今,Kafka 已被很多主要的公司作为服务来进行提供,包括 Confluent Kafka 以及云服务,如Confluent Cloud、AWS Managed Streaming Kafka、Google Cloud Managed Service for Apache Kafka、Azure Event Hub for Apache Kafka等。此外,超过十万家公司部署了 Kafka,包括财富 100 强在内的各个行业领域,如企业、金融、医疗保健、汽车、初创企业、独立软件供应商和零售部门。
数据的价值会随着时间的推移而降低。许多企业现在都在时间上进行竞争,需要实时数据处理,以毫秒级响应来支持关键任务型的应用程序。金融服务、电子商务、物联网和其他对延迟敏感的行业需要高可用性和弹性架构,这些架构能够在不影响业务连续性的情况下承受基础设施故障。
在多个地理位置运营的公司需要提供无缝故障转移、数据一致性和灾难恢复(disaster recovery,DR)能力的解决方案,同时最小化运维的复杂性和成本。公司经常考虑使用的一种通用架构模式是广域网(WAN)上的跨多个数据中心位置的单 Kafka 集群,这被称为Stretch集群。公司通常考虑采用这种模式实现灾难恢复(DR)和高可用性(high availability,HA)。
理论上,Stretch 集群可以提供跨区域的数据冗余,并在区域性故障事件中实现数据丢失的最小化。然而,这种方法由于 Kafka 的固有特性以及在多区域架构中对网络延迟、一致性和分区容错的依赖,带来了多项挑战和权衡。在本文中,我们将重点关注 Stretch 集群架构模式对 DR 或 HA 相关的影响和考虑。
我们已经执行了如下的测试,并且记录了集群的行为。
环境详情
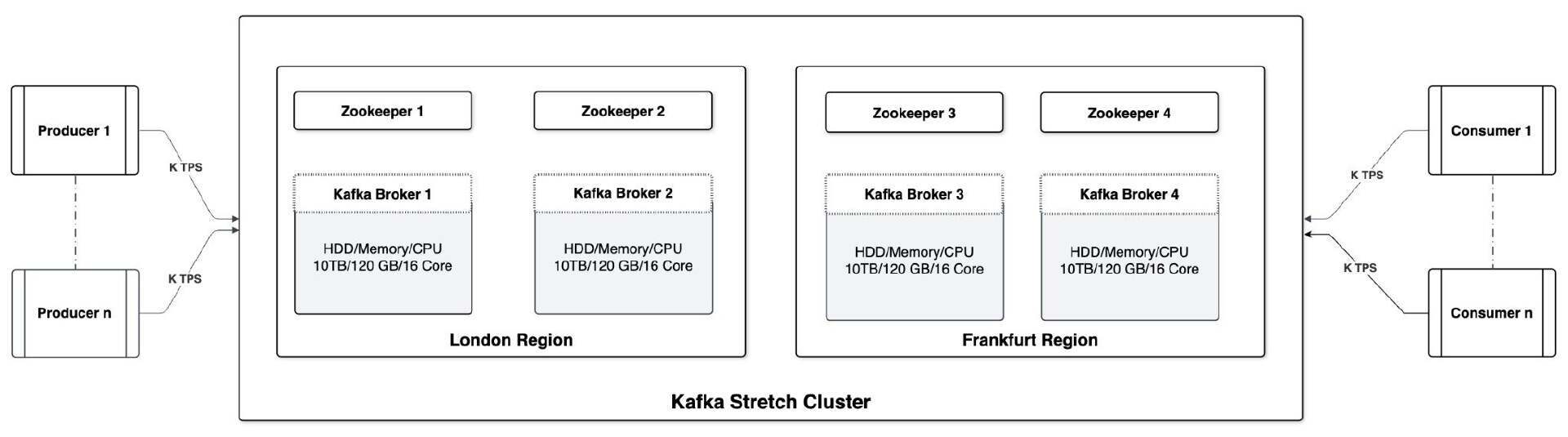
高层的环境架构视图
以下是跨伦敦和法兰克福区域的单个 Stretch 集群架构的高层视图,其中包含:
四个 Kafka broker,实际数据存储在这里。
四个 Zookeeper 节点(采用三节点而不是四节点的设置也可以正常工作,但为了在两个区域中模仿真实的环境,我们设置了四个 Zookeeper 节点)
Zookeeper 遵循 [N/2] + 1 规则以确定 quorum。在本例,Zookeeper quorum 将是[4/2] + 1 = 2 + 1 = 3。
这些区域之间的网络延迟约为 15 毫秒。
多个生产者(1 到 n)和消费者(1 到 n)从世界各地的不同区域生产和消费此集群中的数据。
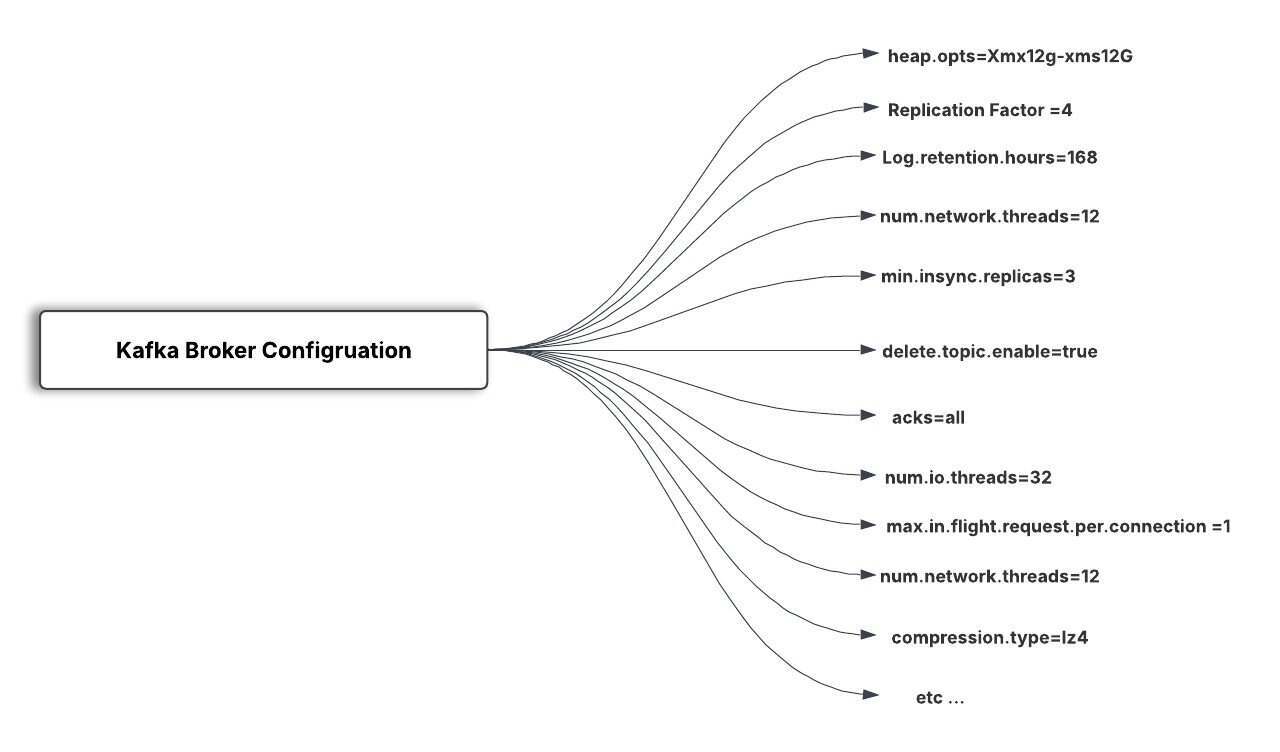
Kafka Broker 的硬件配置
Kafka Broker 的配置
复制系数(replication factor)设置为 4
数据保留(即日志保留)期限为 7 天
允许自动创建主题
最小同步复制(in-sync replication,ISR)设置为 3
每个主题的分区数为 10
其他配置细节
Acks = all
max.in.flight.request.per.connection=1
compression.type=lz4
batch.size=16384
buffer.memory=67108864
auto.offset.reset=earliest
send.buffer.bytes=524288
receive.buffer.bytes=131072
num.replica.fetchers=4
num.network.threads=12
num.io.threads=32
生产者和消费者
生产者
在本用例中,我们使用了一个 Java 编写的生产者,它持续性地生成预定义的每秒事务数(Transactions Per Second,TPS),可以通过属性文件对其进行控制。使用 Kafka 性能测试 API 的示例代码片段如下所示:
******** Start of Producer code snippet ******* void performAction(int topicN){ try { ProcessBuilder processBuilder = new ProcessBuilder(); Properties prop = new Properties(); InputStream input = null; input = new FileInputStream("config.properties"); prop.load(input); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS"); sdf.setTimeZone(TimeZone.getTimeZone("America/New_York")); String startTime = sdf.format(new Date()); System.out.println("Start time ---> "+startTime+" topic " +topicN);String command = "/home/opc/kafka/bin/kafka-producer-perf-test --producer-props bootstrap.servers=x.x.x.x:9092"+ " --topic "+topicN+ " --num-records "+ prop.getProperty("numOfRecords") + " --record-size "+ prop.getProperty("recordSize") + " --throughput "+ prop.getProperty("throughputRate") + " --producer.config "+ "/home/opc/kafka/bin/prod.config"; //processBuilder.command("cmd.exe", "/c", "dir C:\\Users\\admin"); processBuilder.command("bash", "-c", command); Process process = processBuilder.start(); //StringBuilder output = new StringBuilder(); BufferedReader reader = new BufferedReader( new InputStreamReader(process.getInputStream())); String line; while ((line = reader.readLine()) != null) { //output.append(line + "\n"); if(line!=null && line.contains("99.9th.")) { break; } } int exitVal = process.waitFor(); if (exitVal == 0) { System.out.println("Success!"); String endTime = sdf.format(new Date()); //send to opensearch for tracking purpose - optional step pushToIndex(line,startTime, endTime, prop.getProperty("indexname")); //System.out.println(output); //System.exit(0); } else { System.out.println("Something unexpected happend!!!"); } } catch (IOException e) { e.printStackTrace(); } catch(Exception e){ e.printStackTrace(); } }********** End of producer code snippet ******************** Stat of Producer properties file ***** numOfRecords=70000recordSize=4000throughputRate=20topicstart=1topicend=100****** End of Producer properties file ***** 消费者
在本用例中,我们使用了 Java 编写了消费者,它们可以持续消费每秒事务数(TPS),这可以通过属性文件进行控制。
***** Start of consumer code snippet ******* void performAction(int topicN){ try { ProcessBuilder processBuilder = new ProcessBuilder(); Properties prop = new Properties(); InputStream input = null; input = new FileInputStream("consumer.properties"); prop.load(input); SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS"); sdf.setTimeZone(TimeZone.getTimeZone("America/New_York")); String startTime = sdf.format(new Date()); System.out.println("Start time ---> "+startTime+" topic " +topicN);String command =null; if( prop.getProperty("latest").equalsIgnoreCase("no")) { command = "/home/opc/kafka/bin/kafka-consumer-perf-test --broker-list=x.x.x.x:9092"+ " --topic "+topicN+ " --messages "+ prop.getProperty("numOfRecords") + // " --group "+ prop.getProperty("groupid") + " --timeout "+ prop.getProperty("timeout")+ " --consumer.config "+"/home/opc/kafka/bin/cons.config";}else{command = "/home/opc/kafka/bin/kafka-consumer-perf-test --broker-list=x.x.x.x:9092"+" --topic "+topicN+ " --messages "+ prop.getProperty("numOfRecords") + // " --group "+ prop.getProperty("groupid") + " --timeout "+ prop.getProperty("timeout")+ " --consumer.config "+"/home/opc/kafka/bin/cons.config"+ " --from-latest"; }System.out.println("command is ---> " +command); //processBuilder.command("cmd.exe", "/c", "dir C:\\Users\\admin"); processBuilder.command("bash", "-c", command); Process process = processBuilder.start(); StringBuilder output = new StringBuilder(); BufferedReader reader = new BufferedReader( new InputStreamReader(process.getInputStream())); String line; while ((line = reader.readLine()) != null) { // output.append(line + "\n"+"test"); //if(line.contains(":") && line.contains("-")) { if (line.contains(":") && line.contains("-") && !line.contains("WARNING:")) { break; } } int exitVal = process.waitFor(); if (exitVal == 0) { System.out.println("Success!"); //optional step - send data to opensearch pushToIndex(line, prop.getProperty("indexname"),topicN); System.out.println(output); //System.exit(0); } else { System.out.println("Something unexpected happend!!!"); } } catch (IOException e) { e.printStackTrace(); } catch(Exception e){ e.printStackTrace(); } }***** End of consumer code snippet ************Start of Consumer properties snippet **** numOfRecords=70000topicstart=1topicend=100groupid=cgg1reportingIntervalms=10000fetchThreads=1latest=noprocessingthreads=1timeout=60000***** End of consumer properties snippet ****CAP 理论
在深入讨论和场景执行之前,了解分布式系统的基本算法至关重要。这些基础知识将帮助你更好地将 WAN 中断与系统行为的影响联系起来。
CAP理论,即一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),适用于所有的分布式系统,如 Kafka、Hadoop、Elasticsearch 等,其中数据分布在多个节点中:
启用并行数据处理
维护数据和服务的高可用性
支持水平或垂直扩展的需求
Kafka 是一个 AP 系统,它优先考虑可用性和分区容错性,而一致性是最终性的,可以通过设置进行调整。
现在,让我们进入到具体的场景中。
Stretch 集群的失败场景
在深入介绍具体的场景之前,我们先了解 Kafka 内部的关键组件和术语。
Broker 代表数据节点,所有数据都分布在这里,采用副本以实现数据的高可用性。
控制器(Controller)是 Kafka 中一个关键组件,负责维护集群的元数据,包括主题、分区、副本和 broker 的相关信息。同时执行管理任务。可以将其视为 Kafka 集群的“大脑”。
Zookeeper quorum 是一组节点(通常部署在专用节点上),作为协调服务帮助管理控制器选举、broker 注册、broker 发现、集群成员资格验证、分区领导者选举、主题配置、访问控制列表(ACL)、消费者组管理和偏移量管理。
主题(Topic)是数据的逻辑结构,所有相关数据都会发布到这些主题上。例如,所有网络日志都发布到“
Network_logs”主题,应用程序日志发布到“Application_logs”主题。分区(Partition)是支持主题内可扩展性和并行性的基本单位或构建块。当创建一个主题时,它可以有一个或多个分区,所有数据都按顺序发布在这些分区中。
偏移量(Offset)是分配给主题分区中每条消息的唯一标识符,它本质上是一个序列号,指示消息在分区中的位置。
生产者(Producer)是发布记录(消息)到 Kafka 主题的客户端应用程序。
消费者(Consumer)是消费 Kafka 主题中记录(消息)的客户端应用程序。
场景 1:WAN 中断,活跃控制器为“0”,也称为脑死亡的场景
WAN 中断
WAN disruption can be done by deleting or modifying route tables.警告:删除路由表可能会中断相关子网的所有流量。相反,应该考虑修改或分离路由表。
停止防火墙
你可能需要关闭防火墙:
查看防火墙状态:
systemctl status firewalld关闭防火墙:
service firewalld stopZK 命令列表
ZK 服务器启动:
bin/zookeeper-server-start etc/kafka/zookeeper.propertiesZK 服务器关闭:
zookeeper-server-stopZK Shell 命令:
bin/zookeeper-shell.sh <zookeeper host>:2181活跃控制器检查:
get /controller or ls /controllerBroker 列表:
/home/opc/kafka/bin/zookeeper-shell kafkabrokeraddress:2181 <<<"ls /brokers/ids"
检查集群中的控制器和 broker 的替代方法。从 kafka 3.7.x 开始可以使用
bin/kafka-metadata-shell.sh --bootstrap-server <KAFKA_BROKER>:9092 --describe-cluster场景 2:WAN 中断,活跃控制器为“2”,也称为脑裂场景
场景 3:Broker 磁盘已满,导致相应的 Broker 进程崩溃,没有活跃控制器
场景 4:Kafka 进程杀死后索引损坏
关于 WAN 中断故障场景的结论
如果要在公司内部署 stretch 集群,那么需要深入了解故障的场景,特别是在网络中断期间。与云环境不同,公司内部署可能缺乏高可用的网络基础设施、容错机制或专用光纤线路,使它们更容易出现故障。在这种情况下,如果网络连接被中断,Kafka 集群可能会经历停机。
而云服务提供商在区域和数据中心之间提供了高带宽、低延迟的网络,通过完全冗余的专用光纤连接。他们的托管 Kafka 服务旨在实现高可用性,通常建议跨多个区域部署以承受区域性故障。此外,这些服务还包含区域感知功能,确保 Kafka 数据复制发生在多个区域之间,而不是被限制在单个区域。
同样重要的是,要理解并强调在两个不同的地理位置部署的 stretch 集群上,通过 WAN 连接所造成的延迟影响。我们不能逃避物理定律,在我们的情况下,根据WonderNetwork的数据,伦敦和法兰克福之间的平均延迟是 14.88 毫秒,距离为 636 公里。因此,对于关键任务型的应用程序,需要通过测试来设置一个由延迟驱动的 stretch 集群,以确定数据是如何被复制和消费的。
通过了解这些差异,组织可以做出明智的决策,判断公司内 stretch 集群是否符合它们的可用性和弹性要求,或者云原生 Kafka 部署是否为更合适的替代方案。
灾难恢复策略
业务连续性计划(Business Continuity Plan,BCP)对于任何企业来说都是至关重要的,这可以维持其品牌和声誉。几乎所有公司都考虑高可用性(HA)和灾难恢复(DR)策略以满足他们的 BCP。以下是 Kafka 流行的 DR 策略:
主备架构(Active – Standby,又称主动-被动,Active-passive)
双活架构(Active – Active)
备份和恢复 Backup and restore
在进一步深入研究 DR 策略之前,我们先了解一下以下架构模式中使用的 Kafka Mirror Maker 2.0。除此之外,还有 Confluent 和其他云服务提供的其他组件,如 Kafka Connect、Replicator 等,但它们不在本文讨论范围内。
Apache Kafka 中的DNS重定向(DNS Redirection)是一个跨集群复制的工具,它使用 Kafka Connect 框架在集群之间复制主题,支持双活和主备架构。它提供了自动消费者群组同步、偏移量转换和故障转移的支持,可用于灾难恢复和多区域架构。
主备架构
这是一种流行的 DR 策略模式,将两个大小和配置完全相同的 Kafka 集群,部署在两个不同的地理区域或数据中心。在本例中,是伦敦和法兰克福地区。通常,地理位置的选择取决于地球不同的构造板块、公司或国家的合规性和法规要求以及其他因素。在给定时间点,其中只有一个集群是活跃的,接收并服务于客户。
如下图所示,Kafka 集群一(KC1)位于伦敦地区,Kafka 集群二(KC2)位于法兰克福地区,大小和配置相同。
所有生产者都在向 KC1(伦敦地区集群)生产数据,所有消费者都从同一集群消费数据。KC2(法兰克福地区集群)通过 Mirror Maker 从 KC1 集群接收数据,如图 1 所示。
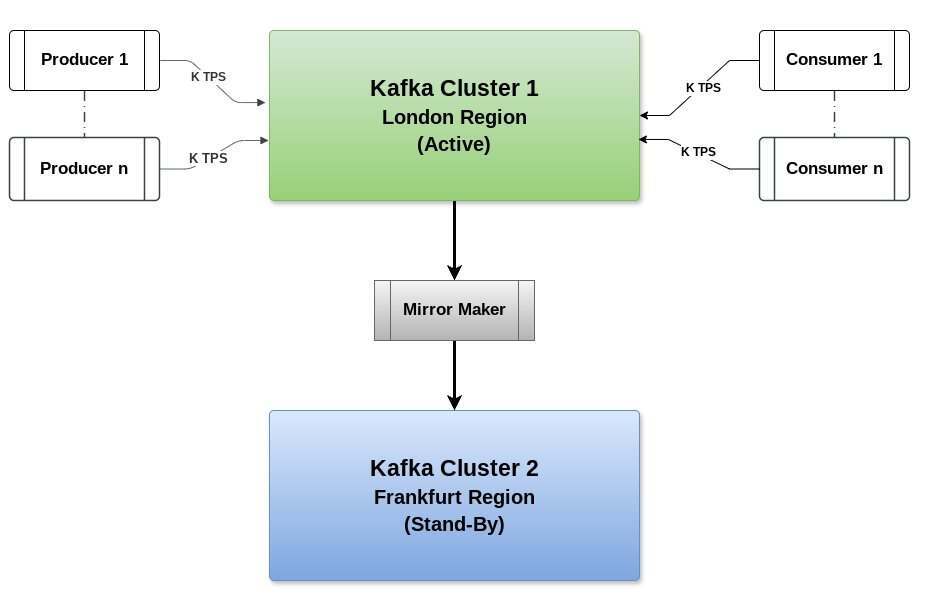
图 1:Kafka 主备架构(也称为活动-被动)集群设置,需要 Mirror 角色
简单来说,我们可以将 Mirror Maker 视为生产者和消费者的组合,它从源集群 KC1(伦敦地区)消费主题,并产生数据到目标集群 KC2(法兰克福地区)。
在主/活跃集群 KC1(伦敦地区)发生灾难时,备用集群(法兰克福地区)将变得活跃,所有生产者和消费者的流量将重定向到备用集群。这可以通过在 Kafka 集群前的负载均衡器进行 DNS 重定向来实现。图 2 显示了这种情况。
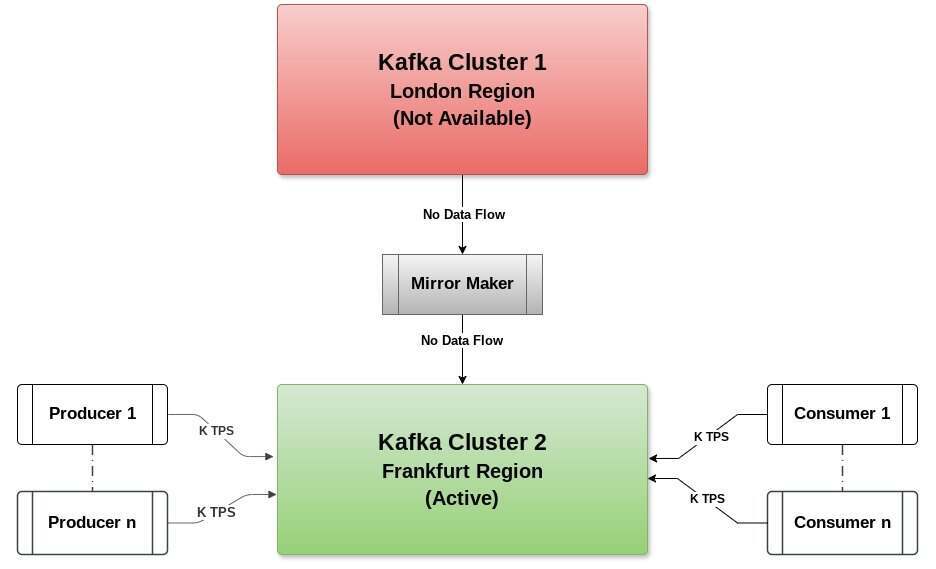
图 2:Kafka 主备架构 - 备用集群变得活跃
当伦敦地区 KC1 集群变得活跃时,我们需要设置一个 Mirror Maker 实例,从法兰克福地区集群消费数据,并将其生成切回到伦敦地区 KC1 集群。这种情况在图 3 中进行了显示。
业务需要决定继续保持法兰克福地区(KC2)处于活跃状态,还是一旦数据完全同步/恢复到当前状态,就将伦敦地区集群(KC1)提升回主集群。在某些情况下,备用集群,即法兰克福地区集群(KC2),会继续像活跃集群一样运行,而伦敦地区集群(KC1)则成为备用集群。
需要注意的是,与双活架构相比,该架构的 RTO(Recovery Time Objective,恢复时间目标)和 RPO(Recovery Point Objective,恢复点目标)值较高。主备架构的成本是中等到高,因为我们需要在两个区域维护相同的 Kafka 集群。
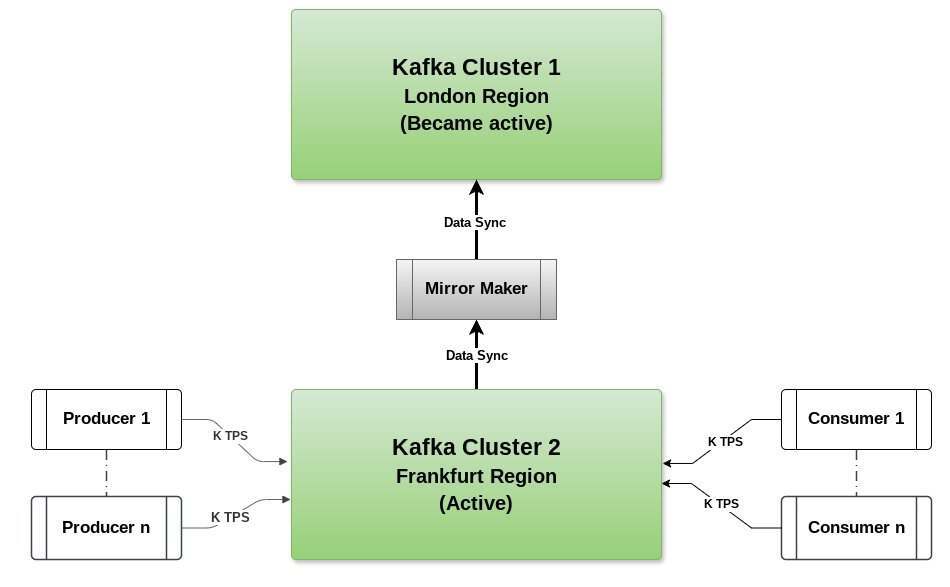
图 3:Kafka 主备架构 - 备用集群数据同步到 KC1
主备架构的注意事项
Kafka Mirror Maker 复制延迟(Δ):
我们考虑这样一个场景,该情况可能非常罕见,我们完全丢失了所有集群,包括节点和磁盘等。其中,活跃 Kafka 集群(伦敦地区 - KC1)有“m”条消息,Mirror Maker 正在消费并产生消息到备用集群。由于网络延迟或消费者和生产者之间的处理确认,备用集群(即法兰克福地区 - KC2)落后并仅持有“n”条消息。这意味着偏差(Δ)是 m 减去 n。
Δ=m−n
其中:
m = 活跃 Kafka 集群的消息(伦敦)
n = 备用 Kafka 集群的消息(法兰克福)
由于这种复制延迟(Δ),将对关键任务型应用程序产生以下影响:
可能出现的消息丢失::
如果在备用集群赶上活跃集群之前发生故障转移,一些消息(Δ)可能会丢失。
数据不一致:
依赖备用集群的消费者可能会处理不完整或过时的数据。
处理延迟::
依赖实时复制的应用程序可能会在数据可用性上经历延迟。
双活架构
我们可以通过双活架构克服复制延迟的问题。就像主备一样,我们将在伦敦和法兰克福地区部署相同的 Kafka 集群。
摄取流水线(ingestion pipeline)的生产者将给定时间内的所有数据写入两个集群。这也被称为双重写入。因此,两个集群的数据是同步的,如图 4 所示。
请注意,摄取流水线或生产者应该有能力支持双重写入。同样重要的是要注意,这些写入流水线应该是隔离的,以便一个集群的任何问题都不会影响其他流水线或造成回压和生产者延迟。例如,如果你的使用场景是日志分析或可观测性,那么可以考虑在摄取中使用 Logstash,并在单个或更多的 Logstash 实例中创建两个单独的流水线,它们将作为隔离的流水线。但是,在任何给定时间内,只有一个集群对消费者是活跃的。
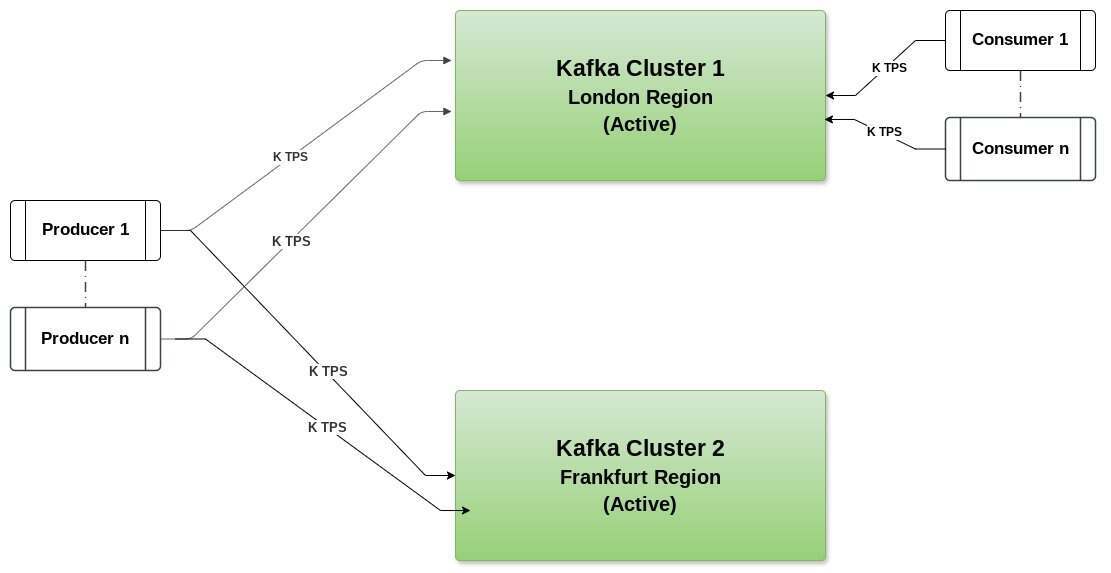
图 4:双活架构或双重写入
在图 5 所示的情况下,如果一个集群出现问题,消费者需要通过 DNS Redirect 向进行重定向,RTO 和 RPO 或 SLA 接近零。
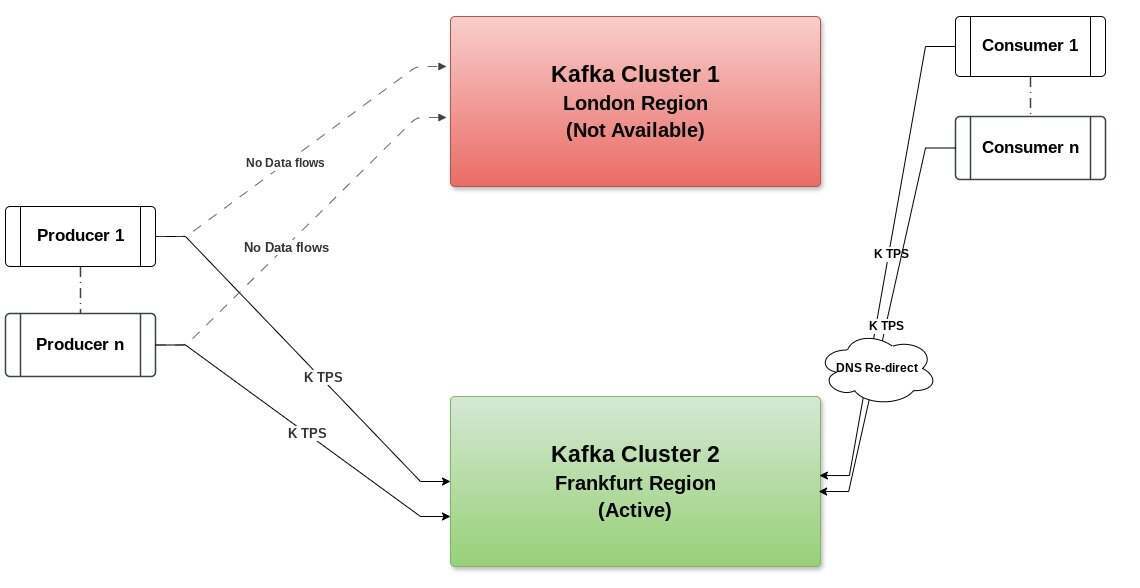
图 5:双活架构中某个集群不可用的场景
一旦伦敦集群可用并变得活跃,数据可以从法兰克福集群使用 Mirror Maker 同步回伦敦集群。如图 6 所示,消费者可以使用 DNS 重定向切换回伦敦集群。同样,配置消费者群组从他们离开的地方开始进行处理也很重要。
在这种架构中,在故障转移期间,配置消费者偏移量以从特定时间点读取消息非常重要,比如,从最后当前时间减去 15 分钟内的回复消息,或者在活跃集群之间设置一个 Mirror Maker,从伦敦地区集群“仅”读取消费者偏移的主题,并复制到法兰克福地区集群。在失败期间,可以使用source.auto.offset.reset=latest从法兰克福地区集群的最新偏移量读取数据。
如果消费者群组没有正确配置,可能会在下游系统中看到重复的消息。因此,设计下游处理重复记录非常重要。例如,如果可观测性的使用场景,并且下游是 OpenSearch,设计一个基于消息时间戳和其他参数(如会话 ID 等)的唯一 ID 是一个好习惯。这样,重复的消息将会覆盖现有的记录,从而保持只有一条记录。
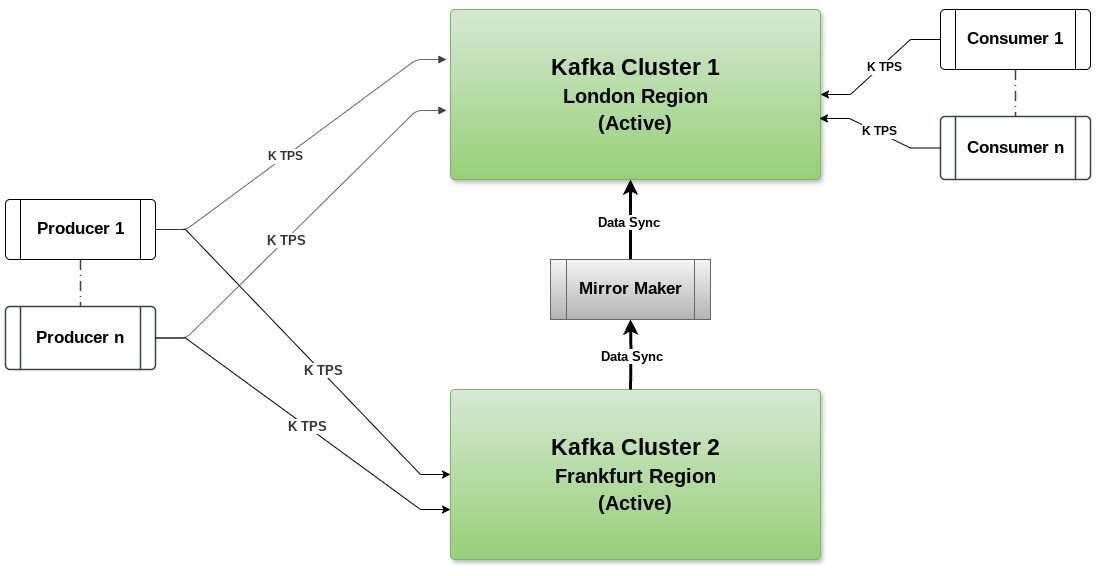
图 6:双活架构集群通过 MirrorMaker 同步数据
双活架构 Kafka 中的挑战和复杂性
当同时向两个集群写入时,会出现消息排序方面的挑战,由于区域间的网络延迟,消息可能会以不同的顺序到达。这对于需要严格消息排序的应用程序来说可能会产生特殊的问题。因此,需要在数据处理时间或下游系统中进行处理。例如,在消息体中定义一个主键时间戳字段,并根据时间戳对消息进行排序。
在对两个不同集群进行双重写入时,可能会出现数据一致性问题。这需要强大的监控和对账流程,以确保跨集群的数据完整性。因为可能会出现数据成功写入一个集群但在另一个集群中失败的情况,这将导致数据不一致。
生产者复杂性是这种双活架构中的一个问题。生产者需要处理向两个集群的写入,并独立管理每个集群的故障,因此隔离每个流水线是非常重要的。这种架构可能会增加生产者应用程序的复杂性,并需要更多的资源来有效地管理双重写入。市场上也有一些代理或工具,如 Elastic Logstash,它们提供了开源的方案,以支持双流水线选项。
消费者群组管理是很复杂的。跨多个集群管理消费者偏移量可能是很具有挑战性的,特别是在故障转移的场景中,这可能导致消息重复。消费者应用程序或下游系统需要设计为能够处理重复消息或实现去重逻辑。
运维开销,运行双活集群需要复杂的监控工具,并显著增加运维成本。团队需要维护详细的运行手册,并定期进行灾难恢复演练,以确保平滑的故障转移过程。
网络延迟的考虑,跨区域网络延迟和带宽成本成为双活架构中的关键因素。区域间可靠的网络连接对于维护数据一致性和有效管理复制至关重要。
备份和恢复
与主备(AP)或双活(AA) DR 架构模式相比,备份和恢复是一种成本效益很高的架构模式。它适用于与 AA 或 AP 模式相比,具有更高 RTO 和 RPO 值的非关键型应用程序。
备份和恢复是一个成本效益较高的可选方案,因为我们只需要一个 Kafka 集群。如果 Kafka 集群临时不可用,那么在其可用时,可以从集中式存储库中重放/恢复数据到 Kafka 集群。在这个架构模式中,如图 7 所示,所有数据将被保存到像 Amazon S3 这样的持久化位置或其他数据湖中,当 Kafka 集群可用时,数据可以从这些位置恢复/重放到 Kafka 集群。通常来讲,我们也会看到使用 Terraform 模板一起构建的新 Kafka 集群环境,它们会构建新的 Kafka 集群并重放数据。

图 7:备份和恢复架构模式
Kafka 备份和恢复架构中的挑战和复杂性
恢复时间影响是一个主要的考虑因素,将大量数据恢复(即重放)到 Kafka 可能需要相当长的时间,这会导致更高的 RTO。这使得该方案只适用于能够容忍更长停机时间的应用程序。
数据一致性方面的挑战也是一个问题。当从备份存储(如 Amazon S3)恢复数据时,保持与原始集群完全相同的消息排序和分区可能是很具有挑战性的。需要特别注意确保在恢复期间的数据一致性。
备份性能开销是另外的考虑因素。定期备份到外部存储可能会影响生产集群的性能。备份过程需要进行仔细安排和资源管理,以最小化对生产工作负载的影响。
存储是关键。管理大量备份数据需要有效的存储生命周期策略和控制成本。定期清理旧备份和高效的存储利用策略是必不可少的。
恢复期间的协调是强制性要求的。恢复过程需要在备份偏移信息和实际消息之间进行仔细协调。缺少任何一个都可能导致在恢复期间丢失或重复消息。
关于 Kafka DR 策略的结论
正如我们之前探讨的,选择 DR 策略并不是一劳永逸的,它涉及到权衡。通常来讲,就是在业务需求和它能负担得起的东西之间找到正确的平衡。决策通常取决于如下几个因素。
SLA(例如,99.99%+的正常运行时间)是预先定义的正常运行时间和可用性的承诺。要求 99.99%正常运行时间的 SLA 每年只允许 52.56 分钟的停机时间。
RTO 指标用于定义系统或应用程序在故障后的最大可接受停机时间,以免造成不可接受的业务损害。例如,知识/内容/培训系统可以预期一个小时或更长时间的停机时间,因为它们不是关键任务。而对于银行应用程序,停机时间的接受度可能是零或几分钟。
RPO 指标用于定义在破坏性事件期间可接受的最大数据丢失量,以从最近一次备份以来的时间来度量。例如,一个可观测性/监控应用程序可以容忍丢失过去一小时的数据,而金融应用程序则不能容忍丢失任何一条交易记录。
相关成本各不相同。更高的可用性和更快的恢复通常意味着更高的价格。组织必须权衡他们对正常运行时间和数据保护的需求与它们所需的财务投资。
参考资料:
原文链接:
Analyzing Apache Kafka Stretch Clusters: WAN Disruptions, Failure Scenarios, and DR Strategies




