
Dropbox 工程师详细介绍了他们如何搭建 Dropbox Dash 背后的上下文引擎,展示了从传统方案向基于索引的检索、知识图谱派生上下文以及持续评估机制的演进,以支撑企业级 AI 知识检索的规模化落地。这一设计也反映出企业助手领域正在形成的一种更普遍的模式:研发团队正有意识地减少对实时工具的依赖,转而更多采用预处理、权限感知的上下文方案,从而降低延迟、提升效果,并缓解 Token 消耗压力。
在最近的一次工程演讲中,Dropbox 工程副总裁 Josh Clemm 将他们的这款应用定位为对企业工作分散在数十个 SaaS 应用中的现状所做出的回应,这些应用各自拥有独立的 API、权限体系与调用速率限制。Clemm 表示,尽管最新的大语言模型已具备推理能力,但它们无法直接访问企业数据来获取上下文,因此需要额外的基础设施,来安全地检索这类可能敏感的信息。
Dash 的核心架构依赖于预处理内容,而非运行时的推理检索。在用户发起查询前,已接入的各类知识应用数据会经过归一化、增强与索引处理,并结合词法搜索与稠密向量检索技术。这使得应用无需在查询阶段构建复杂的 API 调用网络,就能快速返回结果。
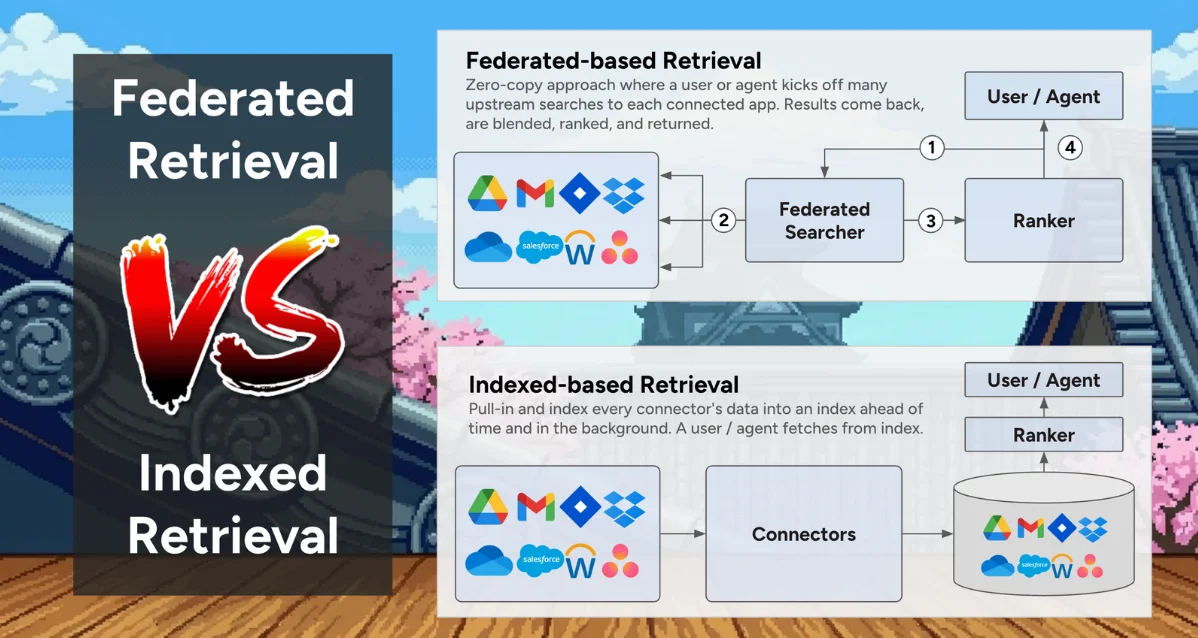
这种方法确实会带来更高的复杂度与存储成本,但 Dropbox 认为,考虑到离线排序实验、相关性信号优化以及查询时性能更稳定等优势,这项投入是值得的。
Dash 应用的核心组件之一是利用知识图谱对人员、文档、会议等常见业务核心对象建立关系模型。不过,团队并不会在运行时直接查询图数据库,而是先派生出“知识包”,再将其导入前面提到的索引流程中。Clemm 表示,早期对图数据库的试验出现了延迟过高、查询模式不稳定等问题,因此团队将图谱信息作为上下文增强的一环,而非新增一层查询。
团队还介绍了通过 MCP(模型上下文协议)将多个工具直接开放给语言模型时遇到的挑战。Dropbox 指出,当大量工具被异步调用时,会出现上下文窗口占用过多、智能体性能下降、查询速度变慢等问题。为解决这些问题,团队将检索能力整合到少数高阶工具中,这些工具可以在提示词之外主动获取上下文,并将更复杂的请求路由给职责更专一的智能体处理。

MCP 的创建者也表达了对于使用多个工具时消耗上下文窗口的担忧。他们认为每增加一个工具都需要进行细致的管理。
除检索外,Dropbox 还阐述了大规模标注评估的重要性。由于查询结果是供语言模型使用,而非人类直接查看,传统的点击相关性信号已不再适用。Dropbox 采用语言模型作为评判者,对检索质量进行衡量与打分,以此优化提示词和排序逻辑,减少与人类用户标注之间的差异。
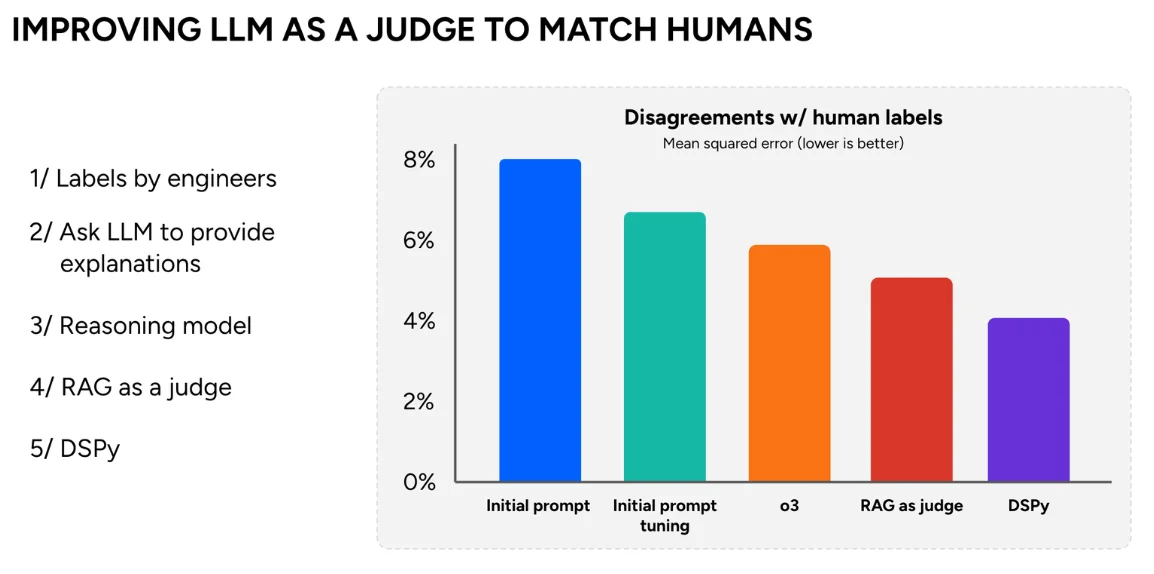
Dash 团队借助 DSPy(一个提示词优化框架)实现了评估流程的工程化落地。Clemm 表示,DSPy 能够管理所有工作流中的 30 多个提示词,让团队能够更快切换模型,而无需手动重写每个模型的提示词。
Dash 团队所采用的方案与其他企业知识助手的实现思路高度相似。Microsoft 365 Copilot 同样依托从 Microsoft Graph 中派生的预计算语义索引来实现高效的上下文检索。
这些设计共同指向了一个愈发清晰的趋势:在企业 AI 中,上下文应当被视作系统的一等公民,而非推理时临时拼凑的内容。随着团队在大型组织中扩展内部搜索与智能体能力,采用预先计算、权限约束与持续评估上下文的架构,正逐渐成为更主流的基础方案。
原文链接:




