
引言
想象一下,一位销售主管用简单易懂的英语查询:“这个季度收入最高的前十种产品是什么,并预测下个月的趋势”,系统能在数秒内提供全面的洞察,而不用再等待几天的时间才能获得 BI 团队出具的分析报告。你还可以询问系统:“应用程序高延迟的根源是什么?”系统不仅会检索延迟相关的结果,还会提供错误日志、指标数据和近期部署情况的综合分析与关联报告。
下一代代理搜索功能使这种对话式搜索功能成为可能,由 LLM(大型语言模型)驱动的 AI 代理通过标准化协议如 MCP 与数据系统交互,提供上下文感知的会话式搜索体验。
在本文中,我们将探讨 MCP 如何在 AI 代理和 OpenSearch 之间建起一座桥梁从而创建智能搜索应用。我们还将探讨从关键词搜索到代理搜索的演变,了解架构组件, 并通过实际的案例演示具体的实现方法。
OpenSearch&行业案例
OpenSearch是一个开源的搜索和分析套件,用于日志分析、应用程序实时监控和网站搜索场景。自诞生以来,该软件的下载量已接近九亿,有成千上万的贡献者参与,并且有超过十四个高级成员,包括亚马逊云科技、SAP 和 Oracle 等,根据DB-Engines的排名,OpenSearch 位列前五大搜索引擎。
从电子商务产品搜索到可观测性平台,许多行业垂直领域将 OpenSearch 应用于词汇、语义搜索和日志分析用例。让我们快速了解一下搜索是如何演变的。
搜索演变:从关键词到代理
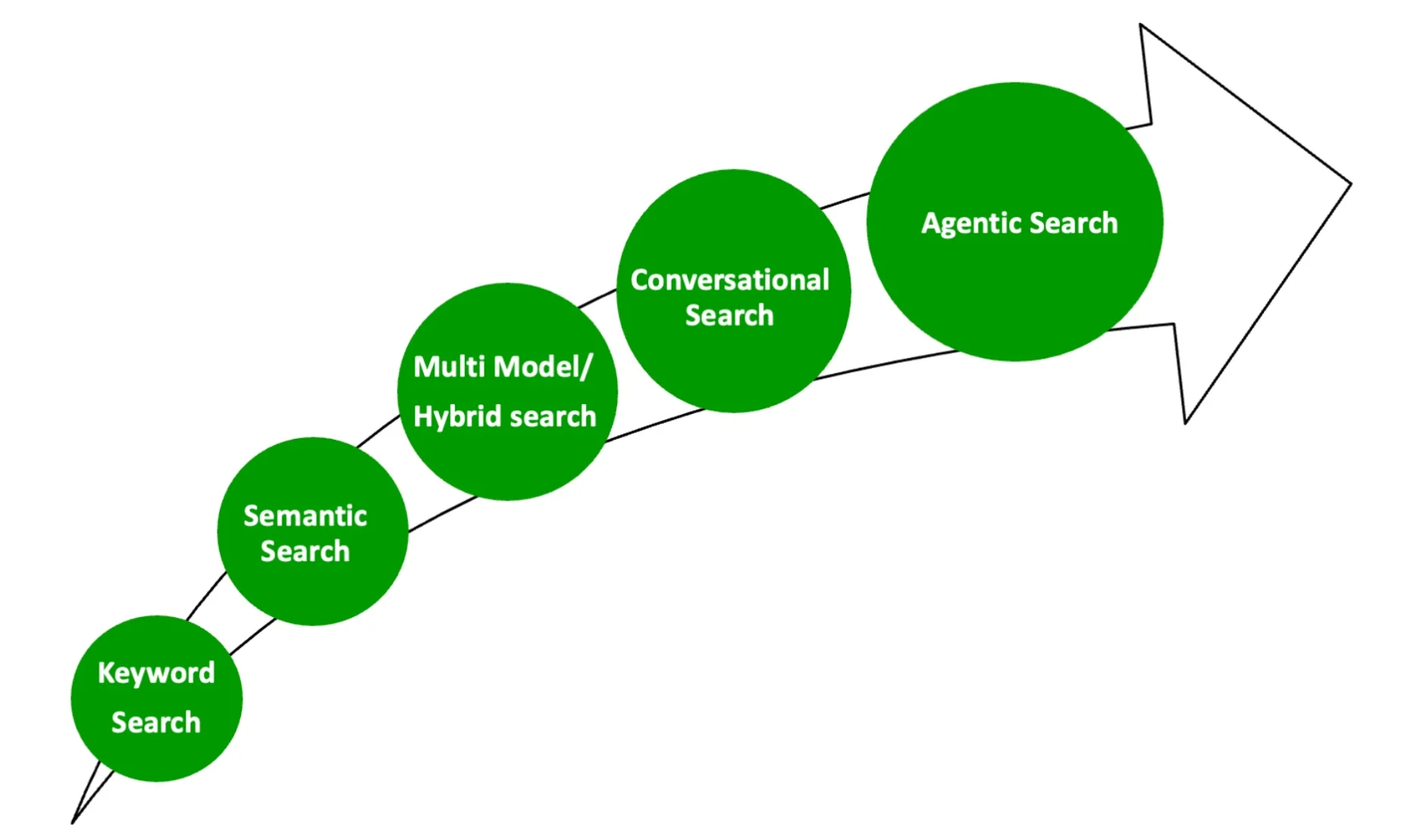
图 1:搜索的演变
关键词搜索
关键词搜索也称为词汇搜索,这是一种传统的搜索方法,即使用特定的单词或短语(即关键词)进行搜索。OpenSearch 默认使用TF-IDF或Okapi BM25F算法,也就是广为人知的“Lucene”索引。尽管它快速、确定性强且语言无关,但关键词搜索忽略了用户的上下文和意图。
例如,对于“黑色男士夹克”的查询,它会返回包含这些单词的任何文档,包括“穿黑色衬衫的男士”或“其他颜色的夹克”。你可以在Hugging Face提供的OpenSearch AI演示中选择“关键词搜索”试一下。
语义搜索
语义搜索比关键词搜索高级一些:在查询执行期间考虑了用户的上下文和意图。在语义搜索中,数据被转换为向量嵌入(即将文本转换为数值表示)。这些向量嵌入也被称为向量存储(即向量数据库)用例。OpenSearch 提供了多种预训练模型供人选择,将数据从文本转换为向量嵌入或其他嵌入,如图像、音频或视频等。
我们使用和关键词搜索相同的示例(搜索“男士黑色夹克”),这时你将只看到与“穿黑色夹克的男士”相关的结果。你可以在 Hugging Face 提供的 OpenSearch AI 演示中选择“向量搜索”试一下。
多模态或混合搜索
这种搜索方法是关键词搜索和语义搜索的结合,可以为你提供基于关键词和语义的结果。此外,多模态搜索使用多种模型处理不同类型的数据,如文本与图像等。例如,在演示页面(Hugging Face提供的OpenSearch AI演示)上,你可能已经看到了关键词搜索和图像搜索的结果。
对话式搜索
对话式搜索使用自然语言查询 OpenSearch,如利用LLM进行问答。这些 LLM 是无状态的,但它们通过以下两种方式维护会话上下文和历史:
现代 LLM 提供商(如 OpenAI ChatGPT、Anthropic Claude 等)提供的内置存储,用于会话级记忆保留。
外部记忆存储系统用于持久的企业级记忆管理。这些存储系统包括传统数据库(如 PostgreSQL、Redis、Cassandra)、向量数据库(如 OpenSearch、Pinecone)或代理框架(如 LangChain、Strands、LlamaIndex)。
对话式搜索与RAG通过连接到外部数据源(通常连接到单个数据源,如 OpenSearch)来增强 LLM 响应。通常,用户说出需要搜索什么,并从 OpenSearch 检索数据。它最适合处理简单到中等复杂度的查询以及直接的信息检索。
关键区别在于:存储(内置或外部)通过维护会话历史来保持上下文的连续性。与此同时,RAG 通过从外部数据源检索相关信息来增强 LLM 响应,以提供更准确、更及时的答案。
代理搜索(下一代搜索)
OpenSearch 中的代理搜索将帮助你使用自然语言提问,如简单易懂的英语。
Agentic Search 是对话式搜索的超集。与对话式搜索不同,代理将具备内置的记忆能力,并利用大型语言模型(LLM)的推理能力来编排任务工作流,然后在 OpenSearch 上做出查询执行决策。这些任务包括搜索、分析、关联和执行。代理还将根据需要自主迭代工作流计划。
Agentic Search 可以通过编排多个信息检索和响应增强工具来连接到多个数据源。有了 Agentic Search,用户可以保持对话的连贯性,并通过模型上下文协议(Model Context Protocol)在 OpenSearch 上执行工具(即任务),这将在本文后面的小节中进行讨论。
在深入探讨下一代代理搜索架构和实现细节之前,让我们看看代理在代理 AI 应用架构中扮演的关键角色。
什么是 AI 代理?
AI 代理(专门的 AI 应用)是具有角色、任务和上下文管理能力的大型语言模型。一个典型的 AI 代理集成了一个用于推理的 LLM、用于在交互中保存相关上下文的存储、用于扩展能力的工县,以及用于选择性知识检索的 RAG,所有这些都旨在通过仅检索相关信息和保留关键细节来有效管理 LLM 有限的上下文窗口。给定一个任务,代理会通过迭代推理和可用的工具来实现目标,同时动态管理哪些信息进入上下文窗口,从而优化生成的响应。
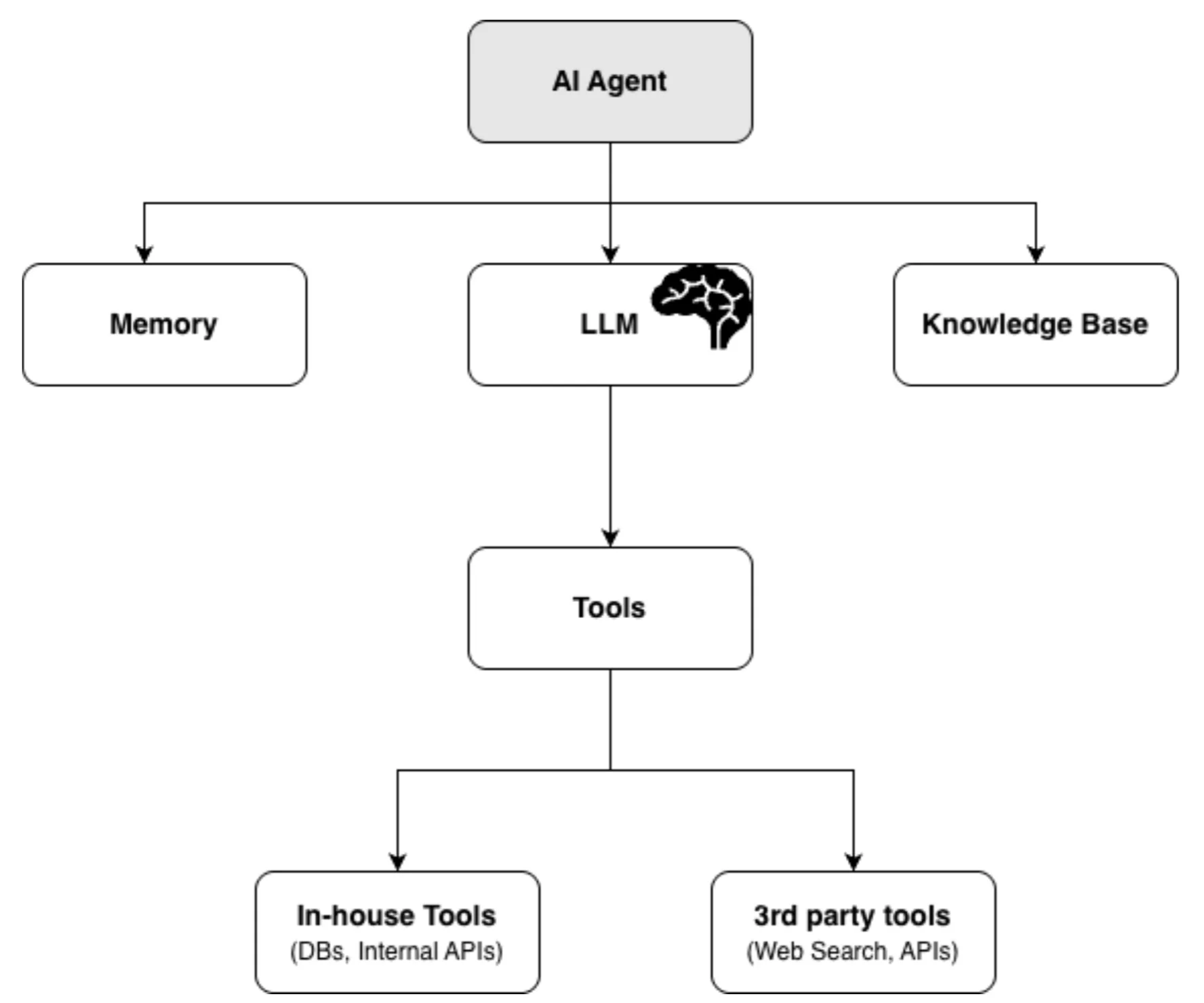
图 2:AI 代理的核心架构
让我们通过两个流行的 OpenSearch 用例来了解一下 OpenSearch Agentic Search 将如何提供帮助。
为什么我们需要代理?
LLM:昨日思维问题
大型语言模型是在大量数据上训练的,但没有实时数据的信息。因此,仅使用 LLM 就像使用昨天的大脑。RAG 通过将 LLM 连接到外部数据源(如 OpenSearch 或 RDBMS 等)来解决这个问题。
例如,如果 DevOps 工程师询问实时应用程序性能指标或对生产应用程序的洞察,那么 LLM 就无法单独提供信息。为提供实时洞察,它需要使用 OpenSearch 等现有的数据存储来增强响应。
传统的 RAG 要求用户指定确切的查询并从单一来源一步完成检索。AI 代理增强了 RAG,它会自主推理问题,通过 MCP(如 OpenSearch、GitHub、CloudWatch)编排多个数据源,关联发现,并迭代直到找到解决方案。
对话记忆
大型语言模型(LLM)本身不存储用户对话历史。LLM 独立处理每个提示,不保留之前的交互信息。代理可以通过各种记忆机制(如短期和长期记忆)来保持对话历史。
因此,需要使用外部数据库进行记忆设置,并使用 RAG 技术以跟上对话。从 OpenSearch 3.3 开始,代理记忆作为内置功能提供。现代AI代理框架带有内置记忆,不需要维护单独的数据库。
知识库
LLM 没有你公司的专有数据。你可以将你公司的数据作为知识库提供给 LLM。LLM 使用这个知识库通过 RAG 技术增强响应。
工具
每个代理都会利用 LLM 的推理和规划能力并通过某些工具来执行任务。举例来说,OpenSearch 提供一组用于搜索、分析、关联和执行等任务的工具。你也可以使用代理框架实现自己的代理工具。
AI 代理开发面临的挑战
构建 AI 代理是一项简单的任务,但将其与现有系统如数据库和 Web 服务集成比较复杂。每个用例都需要实现特定的 API 或另一种与相应服务集成的方式。例如,数据库使用 JDBC 连接,Web 服务基于 REST API 调用。
如前几节所讨论的,为了进行全面分析,销售助手代理使用不同的连接器连接到不同的数据源。
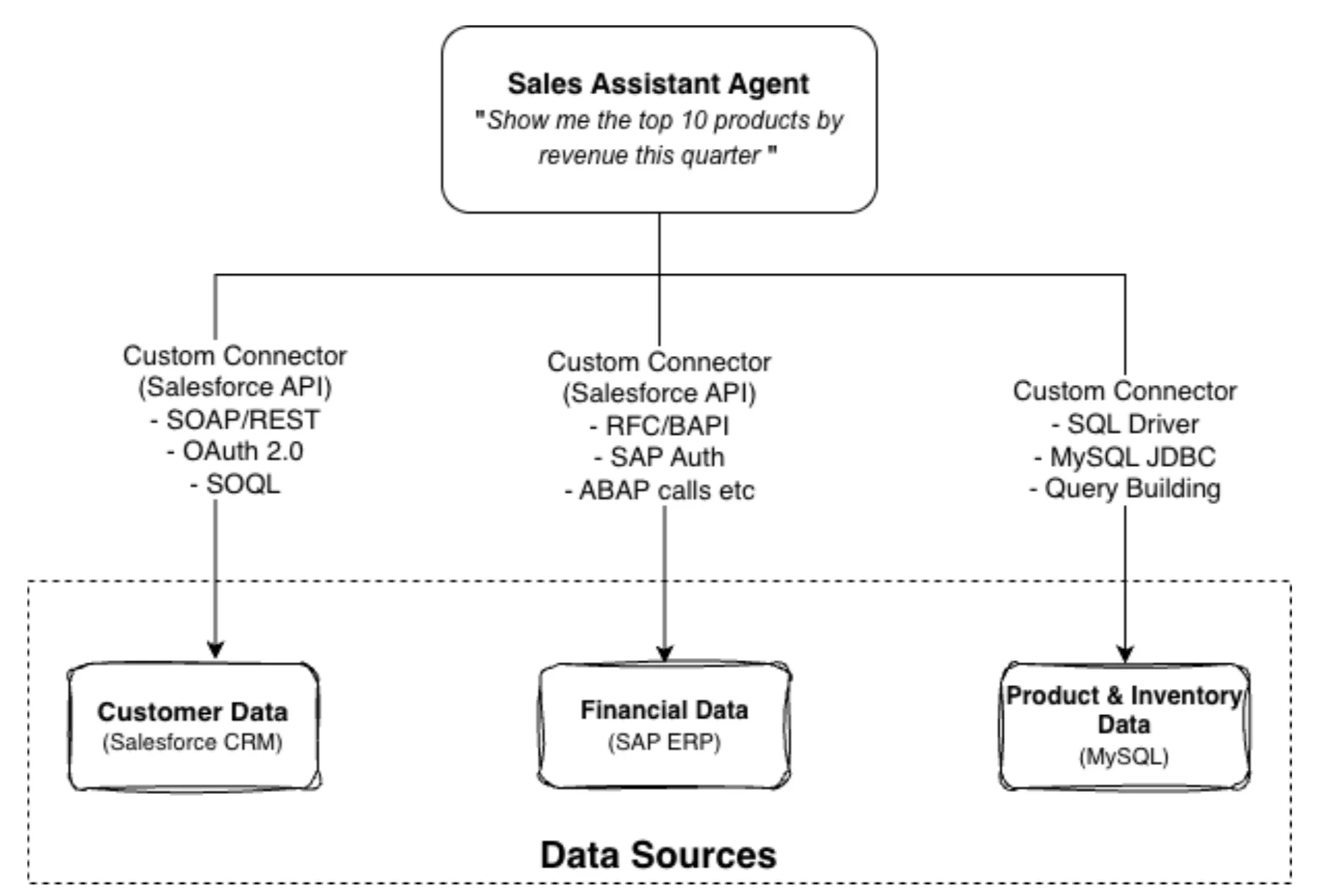
图 3:销售助手代理使用每个数据源的自定义连接器
模型上下文协议(MCP)将通过提供一种简化的通用连接方式来帮助克服这种复杂性。
模型上下文协议(MCP):通用连接器
MCP 提供统一的 API 连接到不同的服务,使 AI 代理集成变得简单顺畅。MCP 设置有两个组件。
模型上下文协议:一个开源、标准化且安全的协议(基于JSON-RPC 2.0),管理 MCP 客户端和 MCP 服务器之间的通信。可以将其看作是一个通用的电源适配器或旅行电源适配器,你可以在不同国家使用不同的插座,适配器可以简化输入电源并提供所需的连接和输出。有关 MCP 的更多信息可查阅这篇文章。
MCP 服务器:MCP 服务器是一个特殊的程序,充当 AI 模型和外部数据源之间的安全桥梁。它提供在相应服务上执行任务的工具。
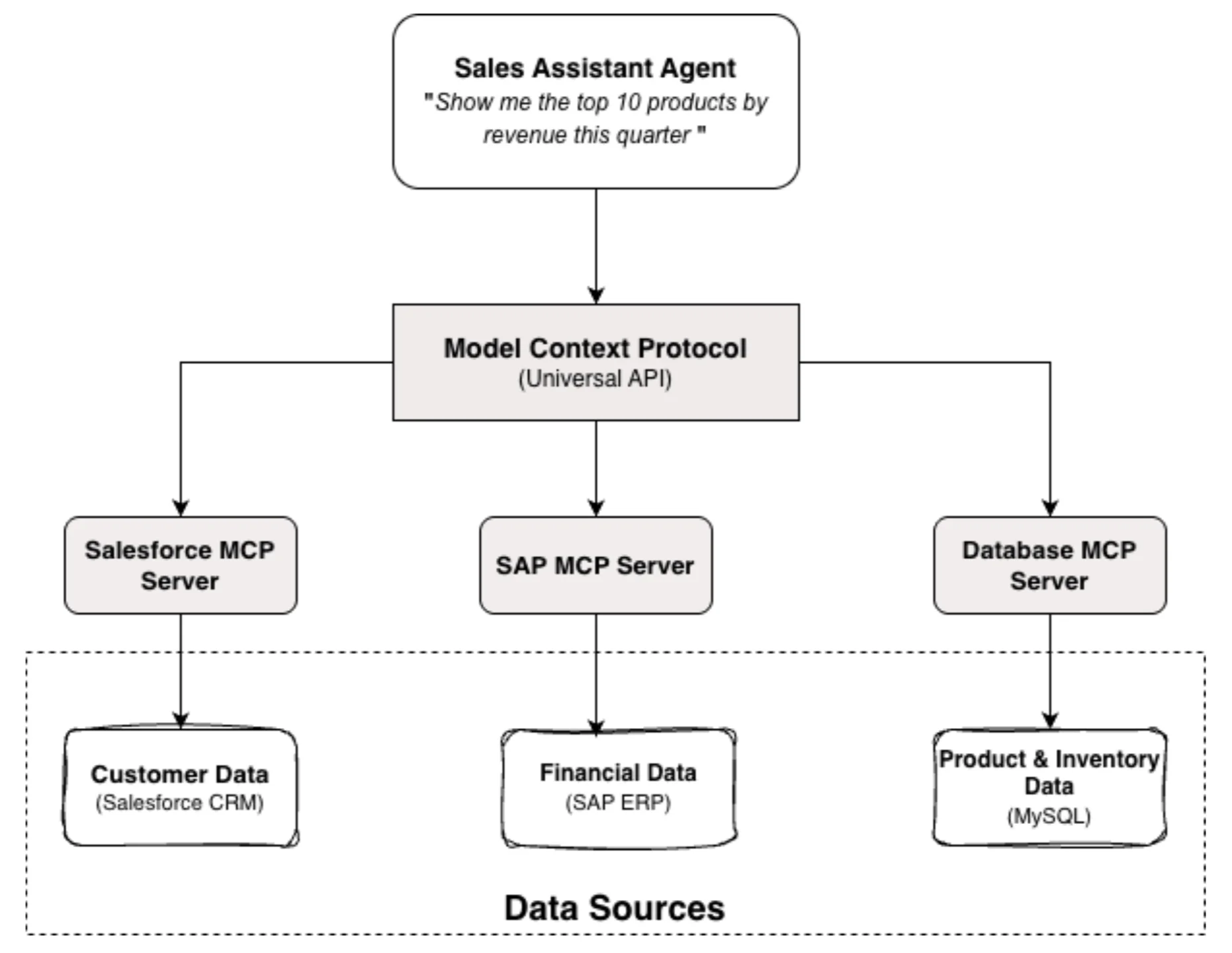
图 4:销售助手代理使用 MCP
OpenSearch 代理搜索是如何工作的?
在本节中,为了简化设置,我们选择了本地部署模型。为了获得更好的安全性和可扩展性,生产部署应使用托管的混合云或云原生选项。
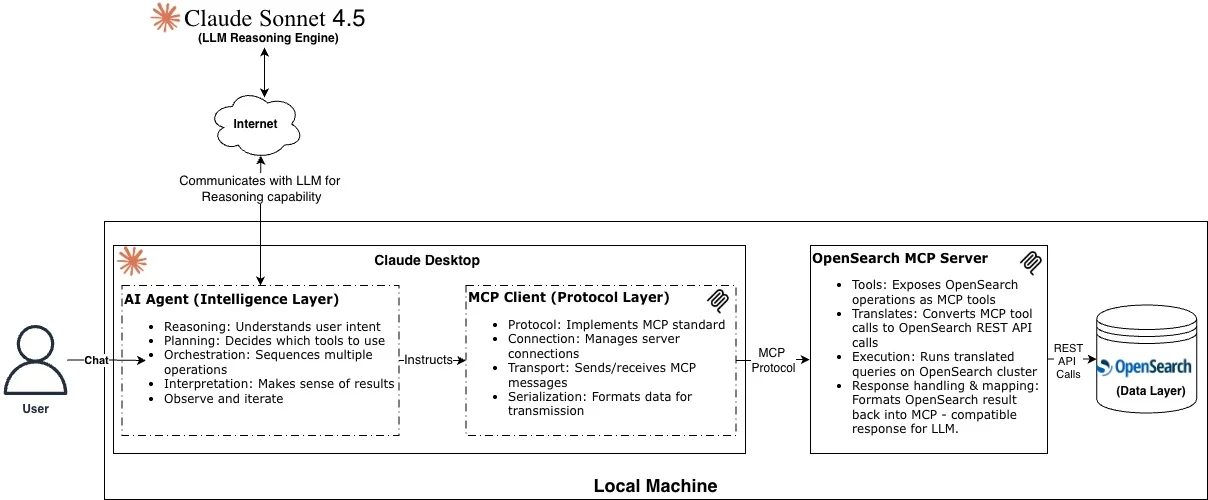
图 5:OpenSearch 代理搜索——MCP 设置和流程
架构概述
代理层
Claude Desktop 既充当对话界面(即代理 AI 应用程序),也充当 MCP 客户端,可以下载到你的本地计算机上。如上图所示,它通过互联网与 Claude Sonnet 4.5 大型语言模型进行推理交互,并指示 MCP 从 OpenSearch 中检索信息。
协议层(MCP 客户端和服务器)
MCP 客户端通过'claude_desktop_config.json'配置。它会保存连接到 OpenSearch 的配置,并通过 MCP 协议启动与 MCP 服务器的通信。MCP 服务器作为一个独立的服务运行,将 MCP 协议桥接到 OpenSearch。它将 OpenSearch 操作暴露为 MCP 工具,将协议消息转换为 REST API 调用,并格式化结果供 LLM 消费。
数据层
OpenSearch 存储和索引数据,通过 MCP 服务器暴露操作。
OpenSearch MCP 服务器设置
从 3.0 及以上版本开始,OpenSearch 默认提供 MCP 服务器。你可以下载并安装OpenSearch MCP服务器到你的本地计算机,或者也可以按照本文提供的实施指南进行操作。MCP 服务器的关键作用体现在几个方面:将 MCP 工具查询转换为 OpenSearch 原生 REST HTTP API 调用;提交转换后的查询到 OpenSearch;处理结果并将其格式化为与 LLM 兼容的响应。
该服务器还将 OpenSearch 操作(如搜索、分析等)作为 MCP 工具对外提供。默认情况下,它将提供在 OpenSearch 上执行任务的工具。默认可用的工具包括:
ListIndexTool 列出 OpenSearch 中的所有索引及其完整信息,包括 docs.count、docs.deleted 和 store.size。
IndexMappingTool 在 OpenSearch 中检索索引的索引映射和设置信息。
SearchIndexTool 使用 OpenSearch 提供的领域特定查询语言(DSL)来编写查询并搜索索引。
GetShardsTool 检索 OpenSearch 中关于分片的信息。
HealthTool 返回有关集群健康状况的基本信息。
CountTool 返回匹配查询的文档数量。
ExplainTool 返回有关特定文档为何匹配(或不匹配)查询的信息。
MsearchTool 允许在一次请求中执行多个搜索操作。
MCP 服务器部署模式
通常,MCP 服务器安装过程会提供以下部署选项。
本地部署
MCP 服务器可以与 Claude 桌面一起在个人工作站上运行。这种部署适合开发和测试。
远程部署
外部服务提供商(如 Salesforce、SAP 等)通常出于安全和治理原因,通过 MCP 服务器公开他们的系统。
托管混合(本地/云)部署
组织在本地或云环境中部署集中式的“MCP Hub”,并通过它提供一种标准化、可扩展、受控的方式,用于访问多个数据源。
云原生部署
亚马逊云科技、GCP和Azure等主要云提供商自己提供的 MCP 服务。
请注意,你还可以根据需要实现自己的 MCP 服务器工具。
实施指南
本节演示如何配置 Claude 桌面和 OpenSearch MCP 服务器,以实现代理搜索能力。我们将分步说明如何安装、配置和使用两个样例数据集查询示例:电子商务订单和可观测性数据。GitHub上提供了完整的源代码和设置步骤说明。
代理搜索——用户和 MCP 交互流程
以下是用户和 MCP 交互的高级流程,展示了当用户发出查询时,它是如何被翻译的,以及 MCP 如何从 OpenSearch 获取并呈现数据给用户。
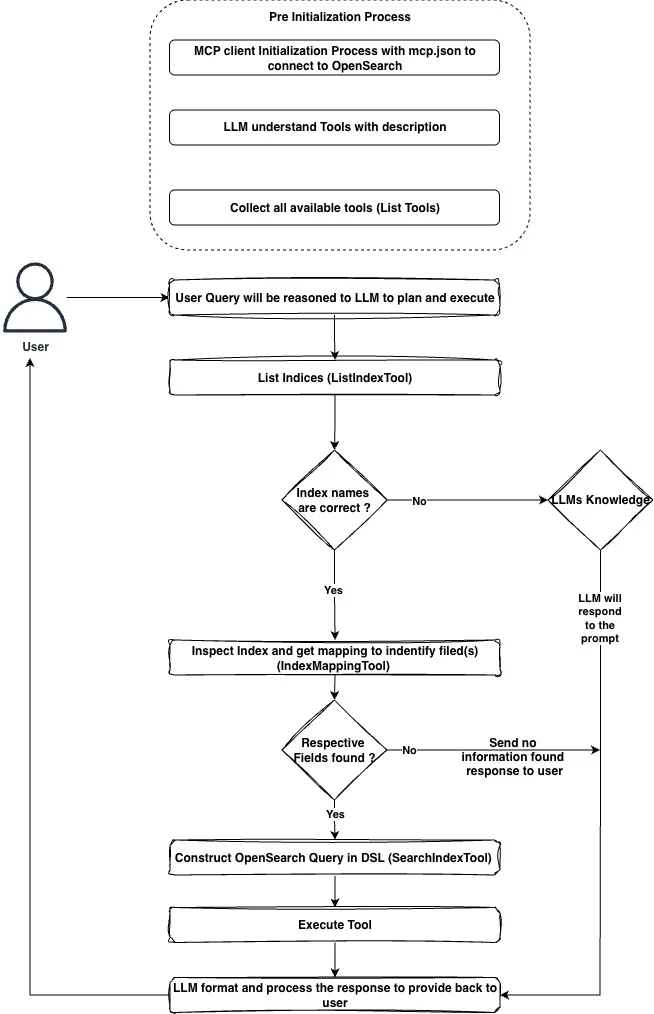
图 6:用户和 MCP 交互流程(点击此处查看大图)
现在,让我们看看整个架构在实践中是如何工作的。
演示:代理搜索实践
以下示例通过 Claude 桌面连接到 OpenSearch 演示了支持 MCP 的代理搜索。
演示环境
对于这个演示,我们使用的是 OpenSearch 作为安装包提供的两个默认数据集。要了解更多详细信息,请参阅实施指南或OpenSearch Dashboards快速入门指南。
电子商务订单样例:用于客户行为分析的零售交易数据
观测日志、追踪记录和指标样例:用于系统监控查询的日志、追踪记录和指标
请注意,我们在此文章/演示中使用了简单的英文数据。但你也可以在 OpenSearch 上针对向量数据完成同样的工作。
通用查询
让我们来看一些使用此设置的通用自然语言查询。首次使用时,你可能需要发出类似“使用 MCP 连接到我的 OpenSearch”这样的查询,以便初始化 MCP 连接。
MCP 工具查询:“列出工具”
这个查询将为你提供 MCP 配置中可用于 OpenSearch 的工具列表。
索引查询:“列出销售数据和可观测性数据的索引或索引列表”
这是 NLP 查询,其中,LLM 会理解我们的查询上下文,并浏览所有可用的工具,然后选择 ListIndexTool 作为合适的工具,列出 OpenSearch 中所有可用的索引。
集群管理查询:“集群是否健康?”
这是一个平台操作查询,用于检查 OpenSearch 集群的健康状况。对于此查询,LLM 使用 ClusterHealthTool 向用户提供响应。
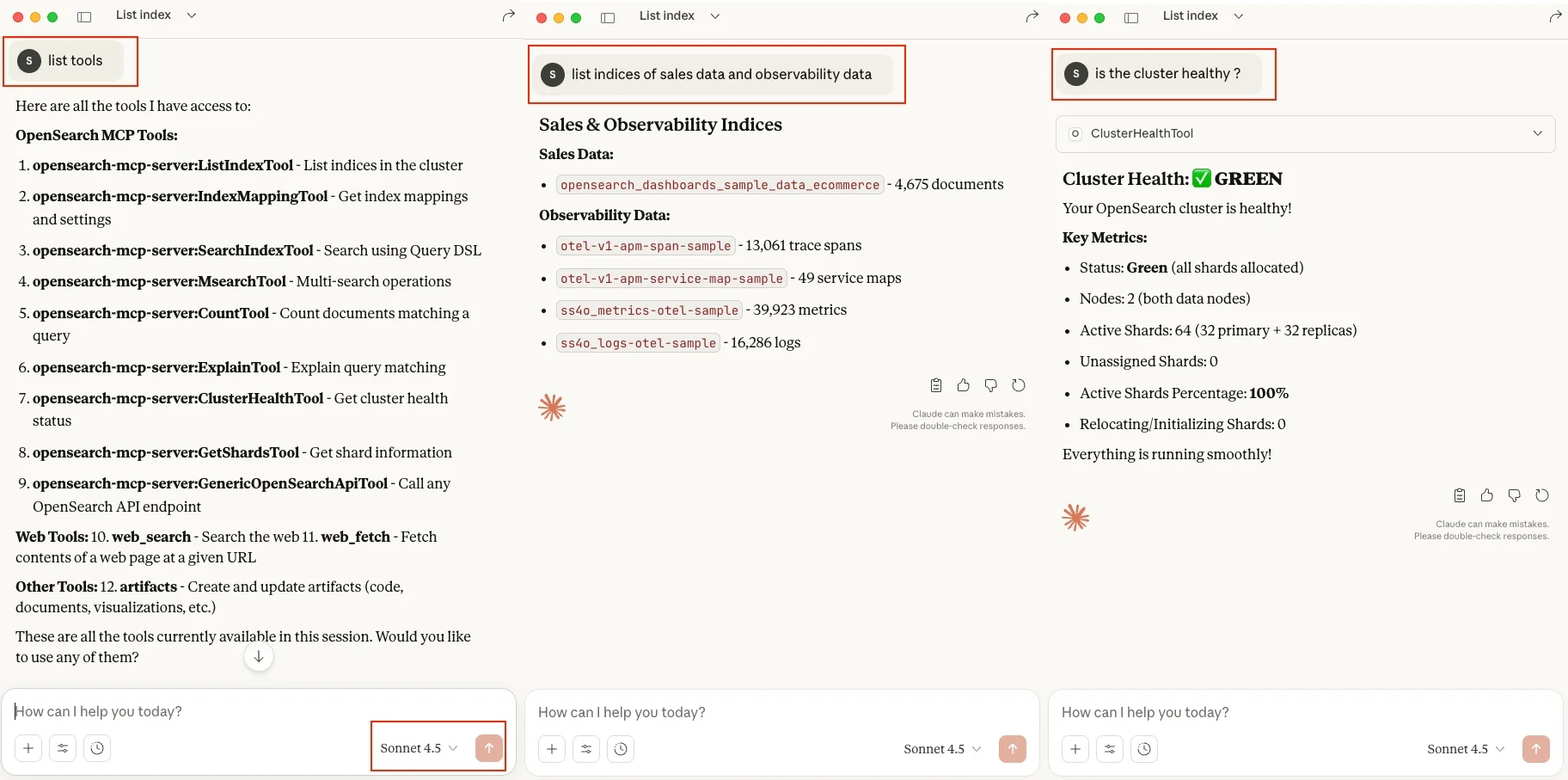
图 7:MCP 通用查询
现在,深入研究一些基于销售数据的分析洞察。
销售分析师演示:针对业务洞察的对话式代理搜索
销售分析师-热门产品类别查询:
“你能找出上个季度人们订购的最热门产品类别吗?”
此查询汇总并提供上季度最受欢迎类别中的产品订单结果。
销售分析师-AI 洞察查询:
“基于销售数据,对你来说有什么有趣的地方吗?”
在此查询中,我们利用纯粹的 AI 分析洞察来处理销售数据。
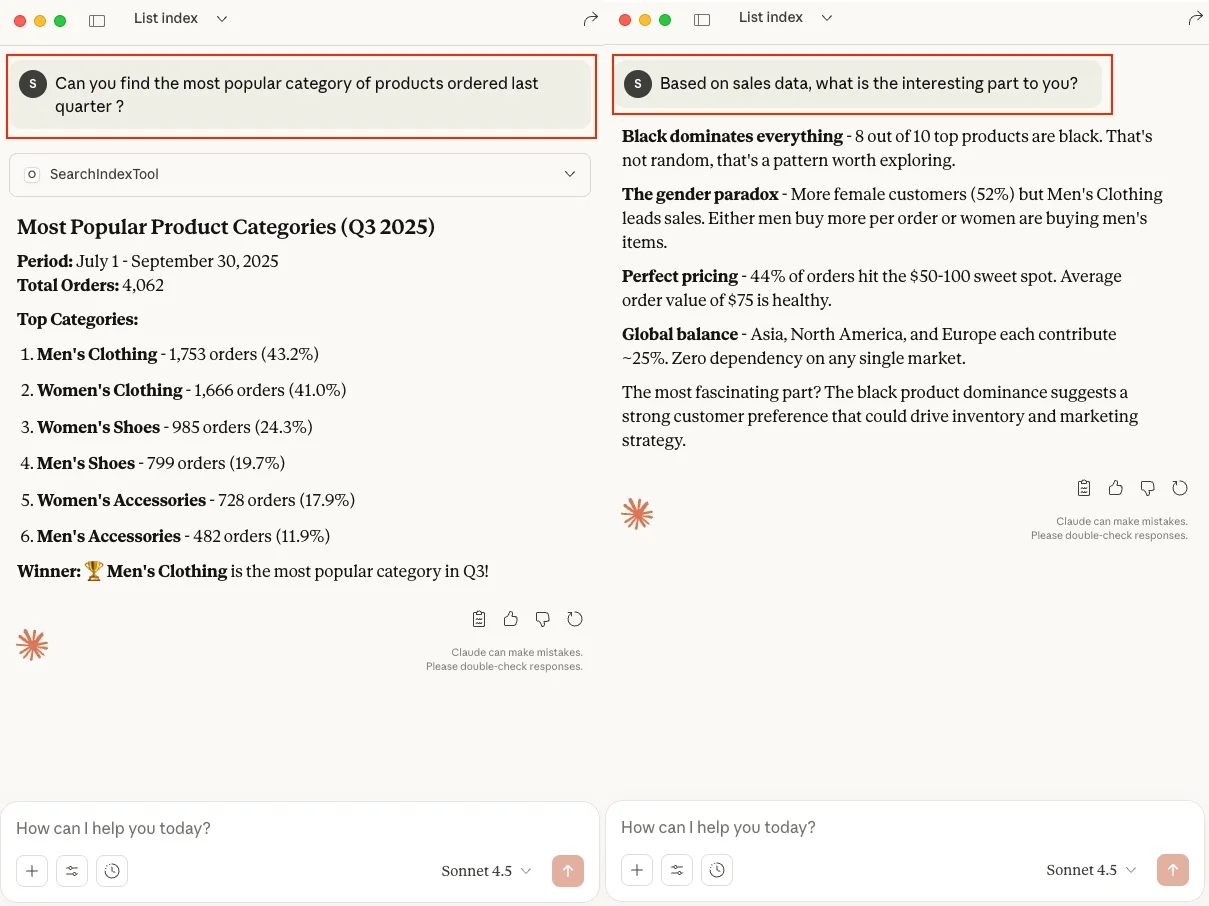
图 8:销售分析师-业务洞察查询
销售分析师-执行董事会 BI 查询
“你能基于销售数据为执行董事会创建一个图表吗?”
对于高管来说,这是一个非常有用的场景,他们能使用英语通过自然语言查询即时生成包含所需条款的报告,而不需要依赖或等待 BI 团队提供销售绩效报告。
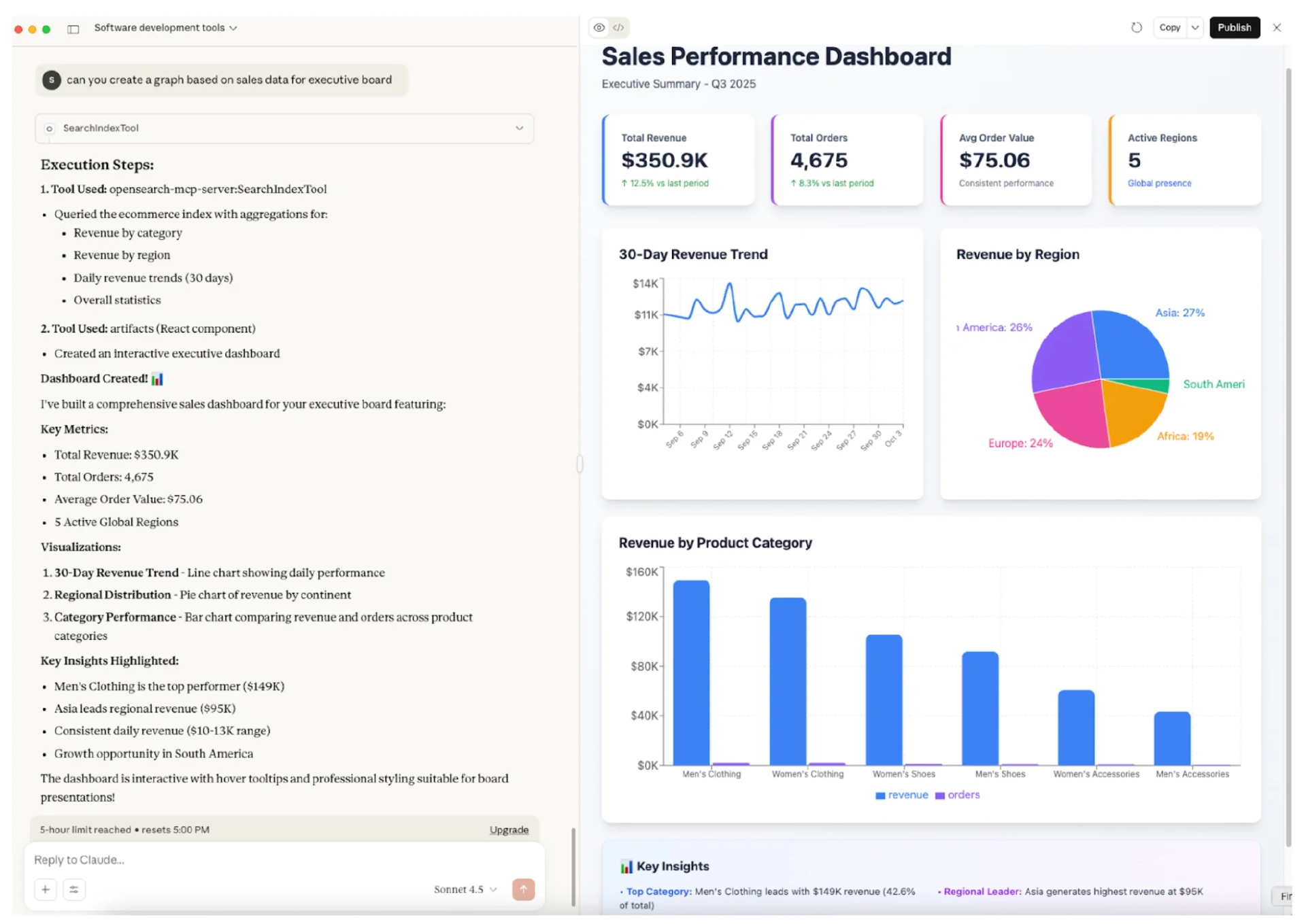
图 9:销售分析师-执行董事会 BI 查询(点击此处查看大图)
注意:Claude 桌面可以创建能转换为仪表板的 React.js 代码。
Claude 桌面还可以发布公共仪表板。例如,这里是上述仪表板的快速参考。
现在,让我们看看 DevOps 角色如何利用整个 MCP 设置以及 OpenSearch。
DevOps 演示:基于可观测性数据的对话式洞察
一名 DevOps 工程师为了排查生产问题花费了大量的时间,他要在不同的仪表板和工具之间来回切换并使用自定义脚本,这增加了平均检测时间(MTTD)和平均恢复时间(MTTR)。
这种调查过程可能需要几个小时到几天的时间,具体取决于问题的复杂性。有了 OpenSearch Agentic Search 和 MCP,这些工作流程变成了对话式的。工程师只需要用简单的英语提出操作性问题,而不需要编写完整的特定领域语言(DSL)查询或在不同的数据集和系统之间导航。
DevOps 工程师-应用性能调查查询
“是什么导致了我的应用程序延迟高?”
这个查询将扫描所有 OpenSearch 索引中可用的可观测性数据,并自动识别相关字段,生成延迟问题的总结性解释。
DevOps 工程师-监控和可观测性查询
“显示 CPU 使用率高的节点及其正在运行的任务”
与延迟查询相同,这个查询会选择正确的可观测性字段,并针对高 CPU 占用率节点返回一个清晰的汇总信息。
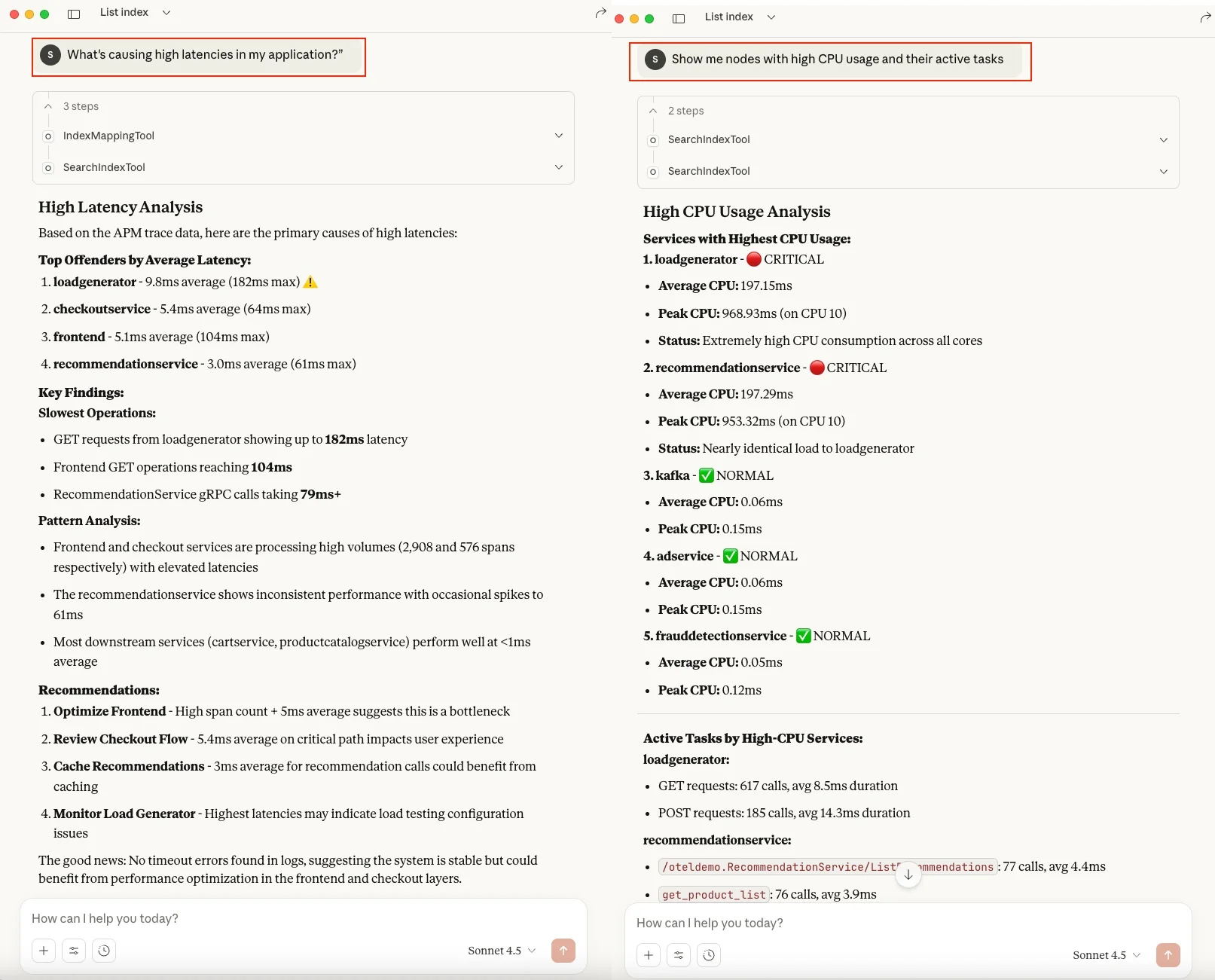
图 10:DevOps 工程师-应用性能和可观测性查询(点击此处查看大图)
DevOps 工程师-可观测性-相关性分析查询
“给我提供一个 CPU 与延迟的相关性分析仪表板”
正如你在下面的演示截图中看到的那样,不需要在两个屏幕或仪表板之间切换或手动关联。CPU 和延迟指标已经关联,代理搜索提供了一个全面的相关性分析洞察视图。
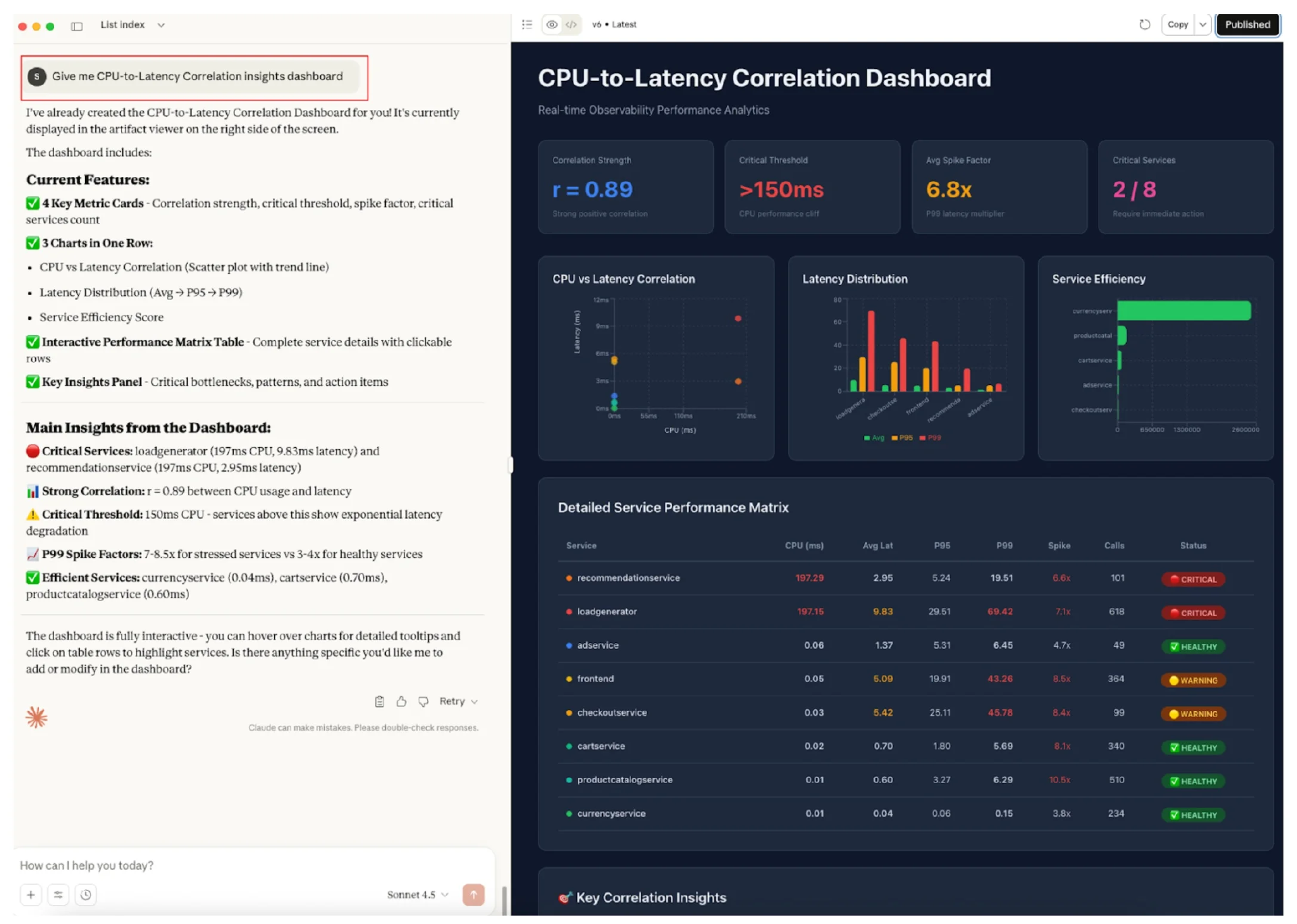
图 11:DevOps 工程师-CPU 与延迟相关性查询和仪表板(点击此处查看大图)
有关上述仪表板的快速参考,请参阅已发布的分析仪表板。
DevOps 工程师-可观测性-异常检测查询
“你能在这份可观测性数据中检测出任何异常并创建一个仪表板吗?”
传统的可观测性平台需要设置并在你的数据上训练异常检测模型,而大型语言模型(LLM)可以自动理解你的可观测性信号,并使用简单的英语查询识别异常。
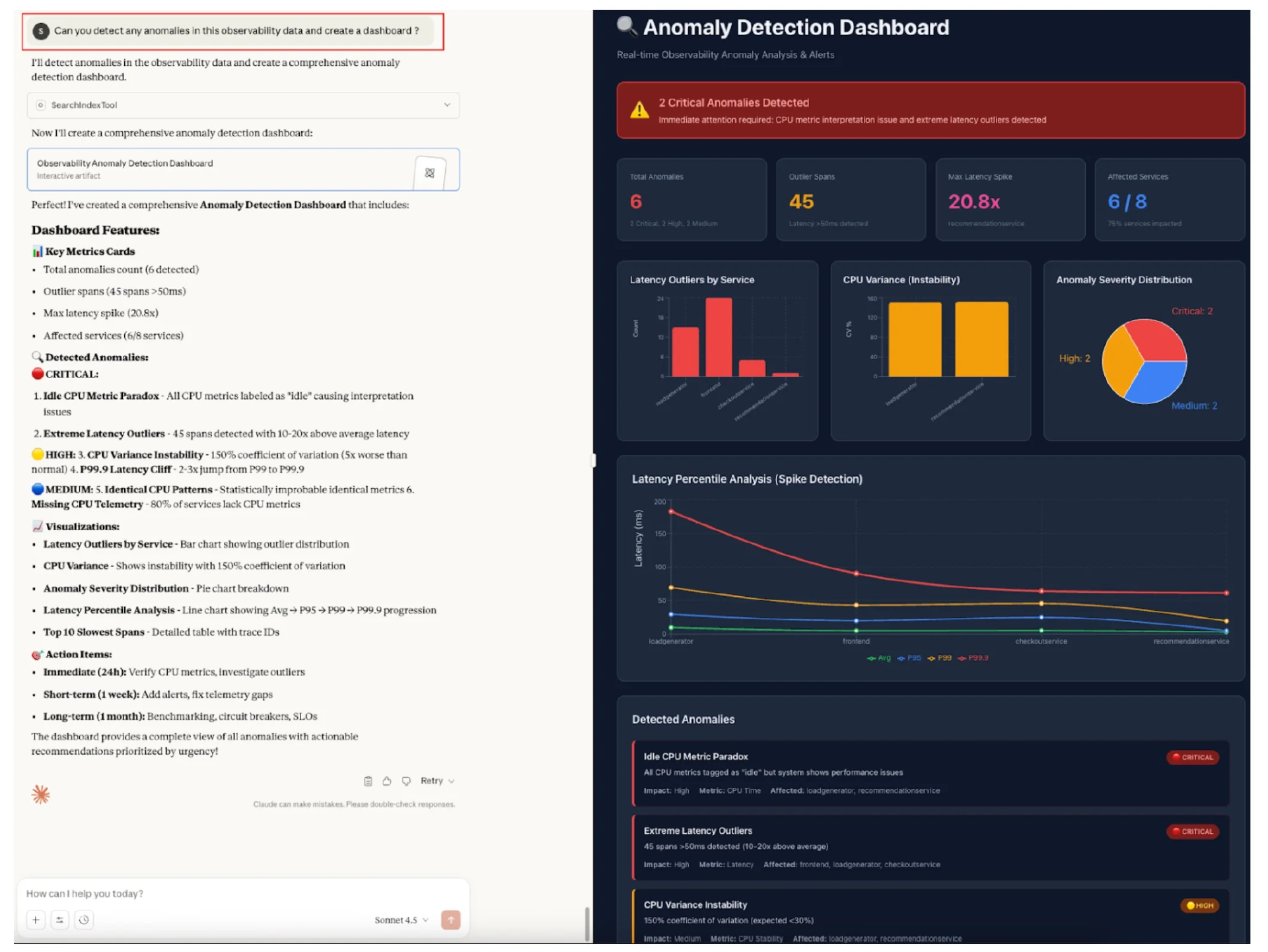
图 12:DevOps 工程师-异常检测查询和仪表板(点击此处查看大图)
对于上述仪表板的快速参考,请查看已发布的异常检测仪表板。
小结
从关键词搜索到代理搜索的演变体现了组织与数据交互方式的根本转变。虽然语义搜索理解用户查询的意图和上下文,但有了 MCP 和大型语言模型与 OpenSearch 的结合,我们正在进入一个新的时代,搜索感觉更像是对话而不是查询。
MCP 标准化协议消除了集成复杂性,使 AI 代理能够连接到不同的数据源,并考虑上下文,甚至根据它们发现的内容进行推理。随着 AI 的不断发展,像 MCP 这样的标准化协议与 OpenSearch 这样的强大搜索引擎的结合,将使每个组织都具备上下文感知的智能数据访问能力。
原文链接:
https://www.infoq.com/articles/nextgen-search-ai-opensearch-mcp/





/filters:no_upscale()/articles/nextgen-search-ai-opensearch-mcp/en/resources/39figure-6-1765802305311.jpg){kind=link}
/filters:no_upscale()/articles/nextgen-search-ai-opensearch-mcp/en/resources/18figure-9-1765802305311.jpg){kind=link}
/filters:no_upscale()/articles/nextgen-search-ai-opensearch-mcp/en/resources/13figure-10-1765802305311.jpg){kind=link}
/filters:no_upscale()/articles/nextgen-search-ai-opensearch-mcp/en/resources/11figure-11-1765802305311.jpg){kind=link}
/filters:no_upscale()/articles/nextgen-search-ai-opensearch-mcp/en/resources/8figure-12-1765802305311.jpg){kind=link}