
Atlassian 近日介绍了自家 Forge 计费平台背后的技术架构。该系统负责支撑 Forge 平台的按量计费能力,将分散在各个云服务中的使用数据转换成准确的计费记录。Forge 是 Atlassian 面向 Jira、Confluence 等产品推出的无服务器扩展开发平台,而这套计费系统则承担着在大规模分布式环境下完成使用量统计和费用核算的任务。
随着 Forge 从早期简单的扩展机制逐渐发展成一个按使用量收费的平台,计费依据也变得越来越细。例如函数调用次数、存储使用量以及各种运行时遥测数据,都会直接影响最终费用。这意味着 Atlassian 必须建立一套新的系统,用来收集来自不同服务的大量事件数据,并确保这些数据能够被正确校验、准确归属到对应租户,同时在不重复、不遗漏的前提下转换为可计费记录,并向开发者提供接近实时的使用情况反馈。
从整体架构来看,这套系统由几个部分组成:负责产生使用事件的 Forge 服务、统一的数据接入与流处理层、使用量追踪系统,以及下游的计费和商业系统。所有 Forge 服务都通过统一的事件模型输出结构化事件,从而保证无论数据来自哪个服务,下游系统都能以一致的方式进行解析和处理。
Atlassian 表示:
UTS(Usage Tracking Service,使用量追踪服务)是 Forge 计费体系中的“神经系统”。
UTS 扮演着整个使用数据协调层的角色,负责对进入系统的事件进行校验、标准化、补充上下文信息,并为后续计费流程做好准备。同时,它还负责将使用数据准确关联到对应的授权或订阅对象,然后再写入存储并传递给下游系统。
这些事件通过基于 Kafka 的流处理基础设施以及 Atlassian 内部的数据传输抽象层进行传递。该层不仅负责模式校验,也保证数据能够可靠地送达后续消费者。通过将生产者和消费者解耦,平台降低了服务之间的依赖关系,同时也让数据接入和处理能力能够分别独立扩展。
Atlassian 指出:
这里最复杂的问题在于归属关系和数据格式:每个事件都必须准确归属到正确的授权或订阅上下文,同时还必须符合 UTS 的数据契约要求,才能被下游系统正确处理。
进入系统之后,使用事件会经过追踪层进一步处理,包括数据校验、标准化、上下文补充、去重以及排序等步骤。即使出现事件乱序到达,或者因为重试机制导致同一事件被重复发送,系统仍然能够保证最终计费结果的准确性。
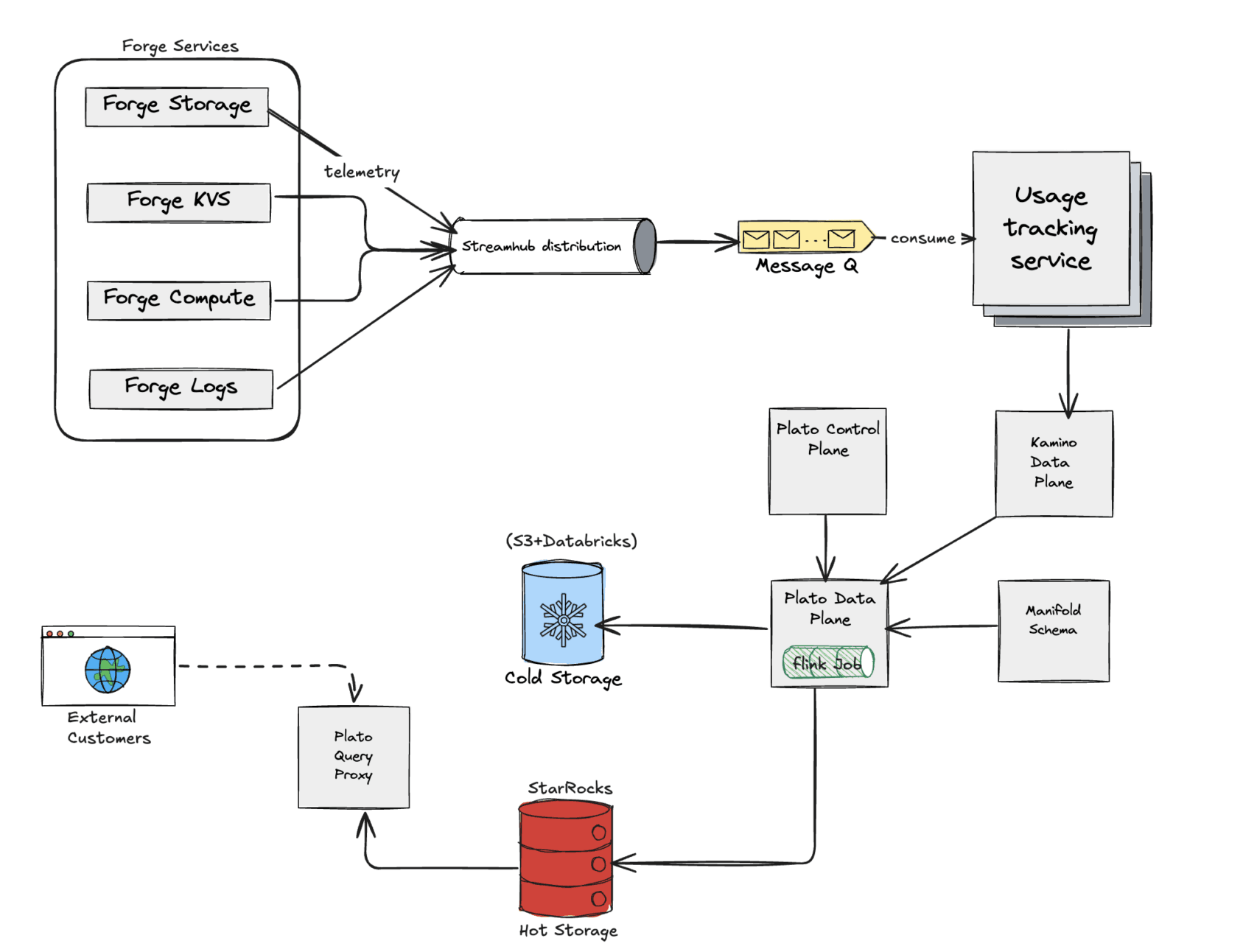
数据接入流水线(来源:Atlassian 博客)
为了应对分布式环境中的一致性问题,这套系统采用了幂等事件设计和基于时间窗口的聚合机制。重复投递的事件不会导致重复计费,而延迟到达的数据也能够通过窗口处理机制被重新纳入统计范围。
在此基础上,流处理引擎会将原始使用事件转换成可用于计费和分析的聚合指标。数据则分别存储在不同层级的系统之中:长期存储层采用不可变数据结构,以满足审计和追溯需求;低延迟分析层则为仪表盘和 API 提供实时查询能力。
最终,所有使用量数据都会映射到对应的开发者空间,实现按应用维度的使用统计和统一计费。通过这种设计,Forge 能够在大规模环境下提供透明的按量计费能力,同时保证财务数据的准确性以及完整的可追溯性。
查看英文原文:Inside Atlassian’s Forge Billing Architecture for Distributed Usage Tracking at Scale - InfoQ




