
调度不准根因分析
在字节跳动的业务生态中,HTTPDNS 承担着为抖音、今日头条、西瓜视频等核心应用提供域名解析服务的重任。但目前我们所采用的业界主流缓存机制,却存在着根本性缺陷:当自身 IP 库与权威 DNS 服务器不同,易发生调度不准,可能影响用户体验。
主流调度修正机制的局限性
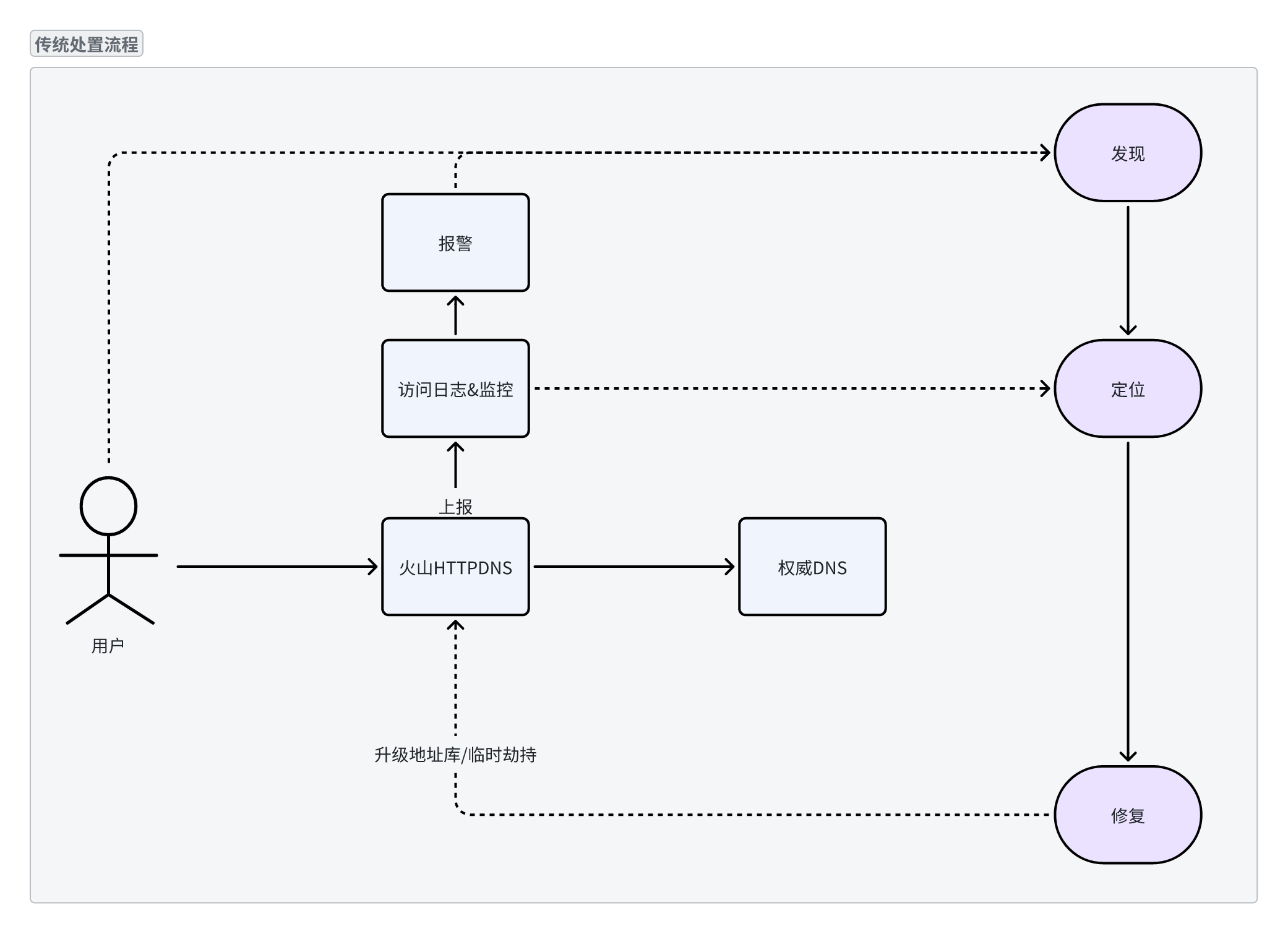
针对 HTTPDNS 调度不准风险,业界主流处置流程采用 “发现 - 定位 - 修复” 三步式闭环机制,具体如下:
发现:通过监控告警、业务异常反馈等方式,识别存在调度偏差的解析场景;
定位:结合访问日志、链路追踪数据等,定位调度不准的具体域名、源 IP 段和目标 IP 段;
修复:通过技术手段修正解析结果,核心修复方式包含以下两类,但均存在显著局限性:
地址库升级:基于外部供应商数据聚合构建的 IP 地址库,即使实时更新,仍难与外部 CDN 厂商的映射保持一致。
临时劫持:通过手动配置解析劫持规则临时修正解析结果,不仅操作流程繁琐、耗时长,且需人工维护大量静态配置;若后续未及时清理或更新规则,易引发配置冲突、解析路径异常等长期维护风险。
Cache2.0 架构优化
缓存粒度技术方案对比
缓存粒度设计直接影响 DNS 解析精准度和 CDN 调度效率,主流厂商的方案存在明显差异:
缓存键精细化重构
我们综合考量调度精准度、工程复杂度以及成本,决定将缓存粒度由“城市 + 运营商”细化为“网段”。
传统方案(国内某厂商/火山 Cache1.0)

缓存粒度:城市+运营商
污染范围:整个城市运营商
调度准确性:低
Cache2.0 方案
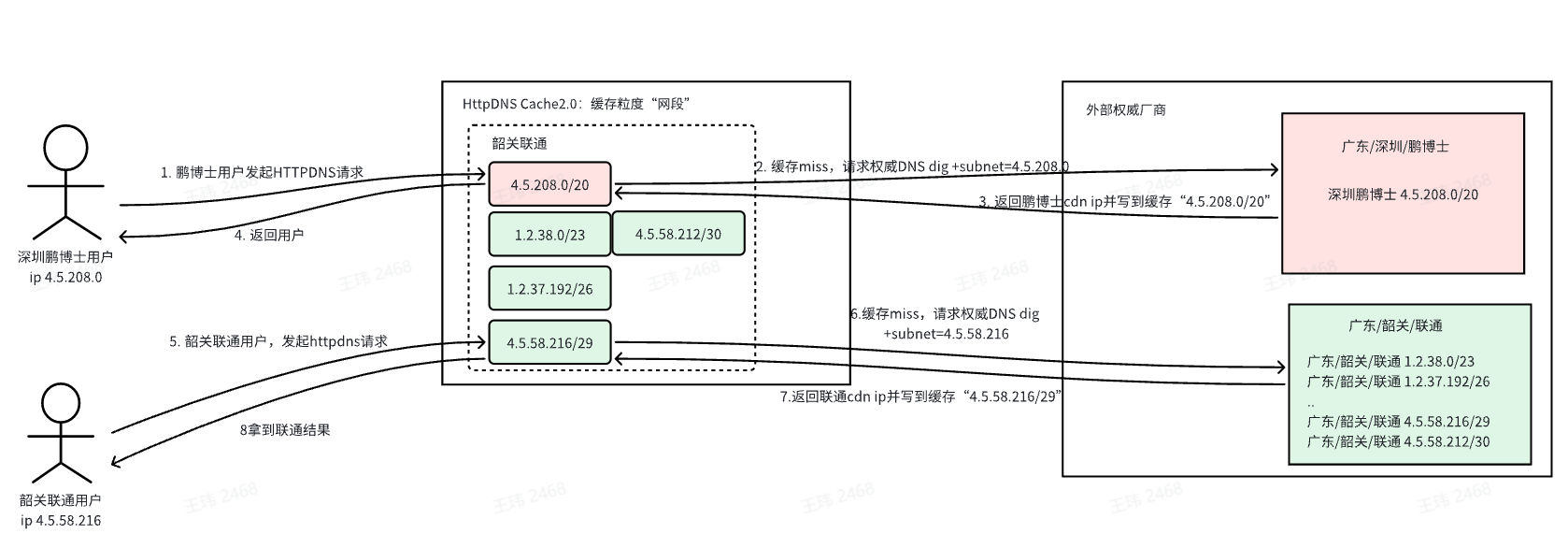
缓存粒度:网段
污染范围:单个网段
调度准确性:高
网段自适应划分算法
背景:外部 CDN 厂商的调度结果会随网络拓扑和调度策略持续变化,而静态网段库划分方式固定,难以实时跟踪调度结果变化。为解决这一问题,网段库动态划分算法通过“数据输入—一致性校验—网段调整—结果输出”的闭环流程,实现了网段库的自适应动态划分。
具体流程如下:
数据输入
收集 客户端 IP(ClientIP)—CDN IP(CDNIP) 映射数据
数据来源:主动拨测结果;HTTPDNS 递归节点日志(包含 cip、cdn ip、记录类型等)。
数据范围:主流 CDN 厂商的解析结果。
网段归属判断:
若相邻 CIP 的 CDN IP 归属同一运营商,则可合并为连续网段
输出 CIP–CDN IP 数据集,作为后续网段划分依据
一致性校验
将整合后的数据集与存量 CidrDB(现有网段库)逐网段进行对比,检查 “映射一致性”。
若存在映射不一致,则触发网段调整流程。
网段调整
合并:探测数据集的网段比现有网段库更粗,合并为更大网段。
拆分:探测数据集的网段比现有网段库更细,拆分为更小网段。
结果输出
生成优化后的 New CidrDB。
替换存量网段库,实现动态更新。
持续迭代
重复上述流程,实现对真实网络拓扑的动态追踪。
缓存策略优化
为解决缓存粒度细化可能导致的命中率下降问题,Cache2.0 引入了四重优化策略,最终实现了如下收益:
缓存命中率提高了 15%,缓存量、CPU 使用和出网流量降低了约 70%。
两级一致性哈希分流
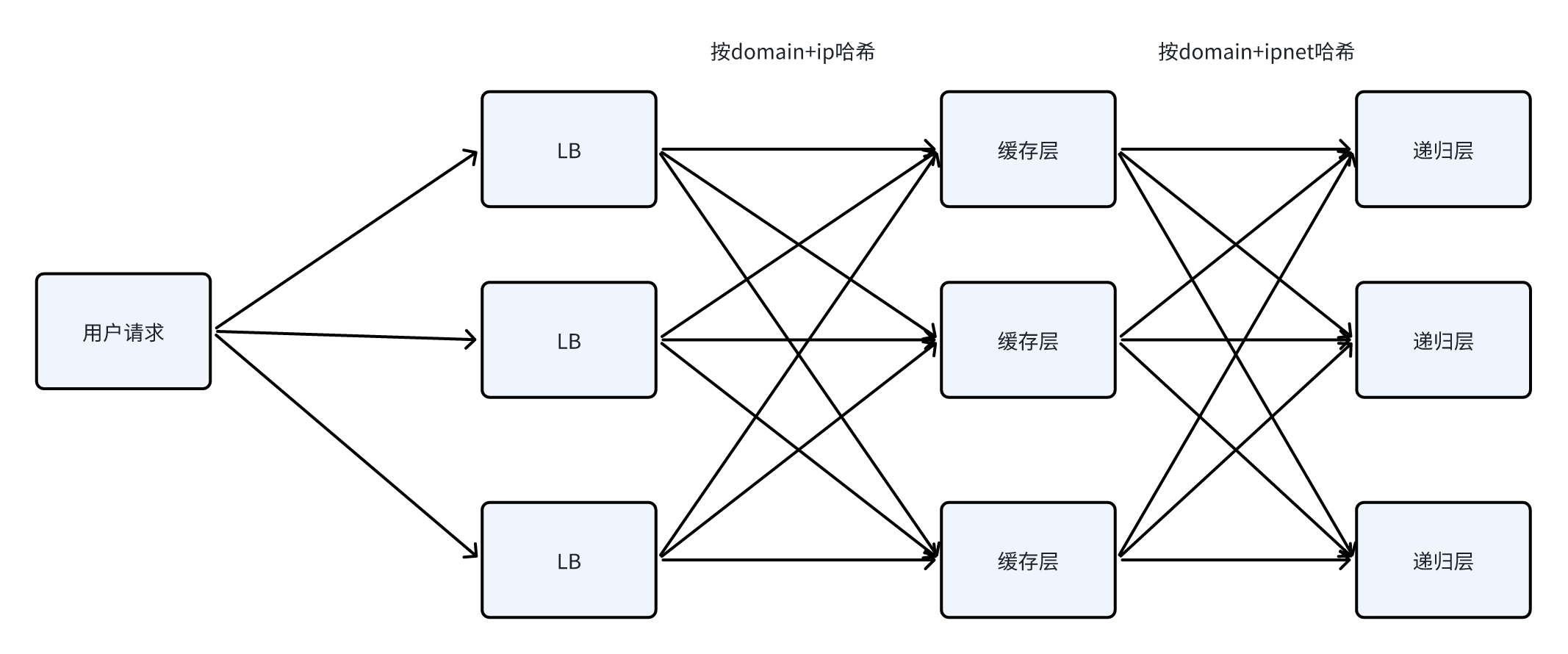
火山 HTTPDNS 的流量转发以一致性哈希思想为核心,将用户请求链路(用户→LB→缓存层→递归层)拆分为两级哈希调度:
一级调度(LB→缓存层):以“源 IP + 域名”为哈希键。使用 LB 的一致性哈希策略,将同一用户对同一域名的请求统一路由至固定的 HTTPDNS 节点,避免传统轮询导致的请求分散。
二级调度(缓存层→递归层):以“域名 + 网段” 为哈希键。以 “域名 + 客户端网段” 作为哈希键,对递归层集群进行调度,确保某一 “域名 + 网段” 对应的所有查询请求均定向到唯一的递归层节点。
两级哈希协同调度,实现 “缓存块 - 节点” 绑定,解决了缓存的碎片化问题,同时单一节点故障仅影响极小范围缓存。
缓存分级管理
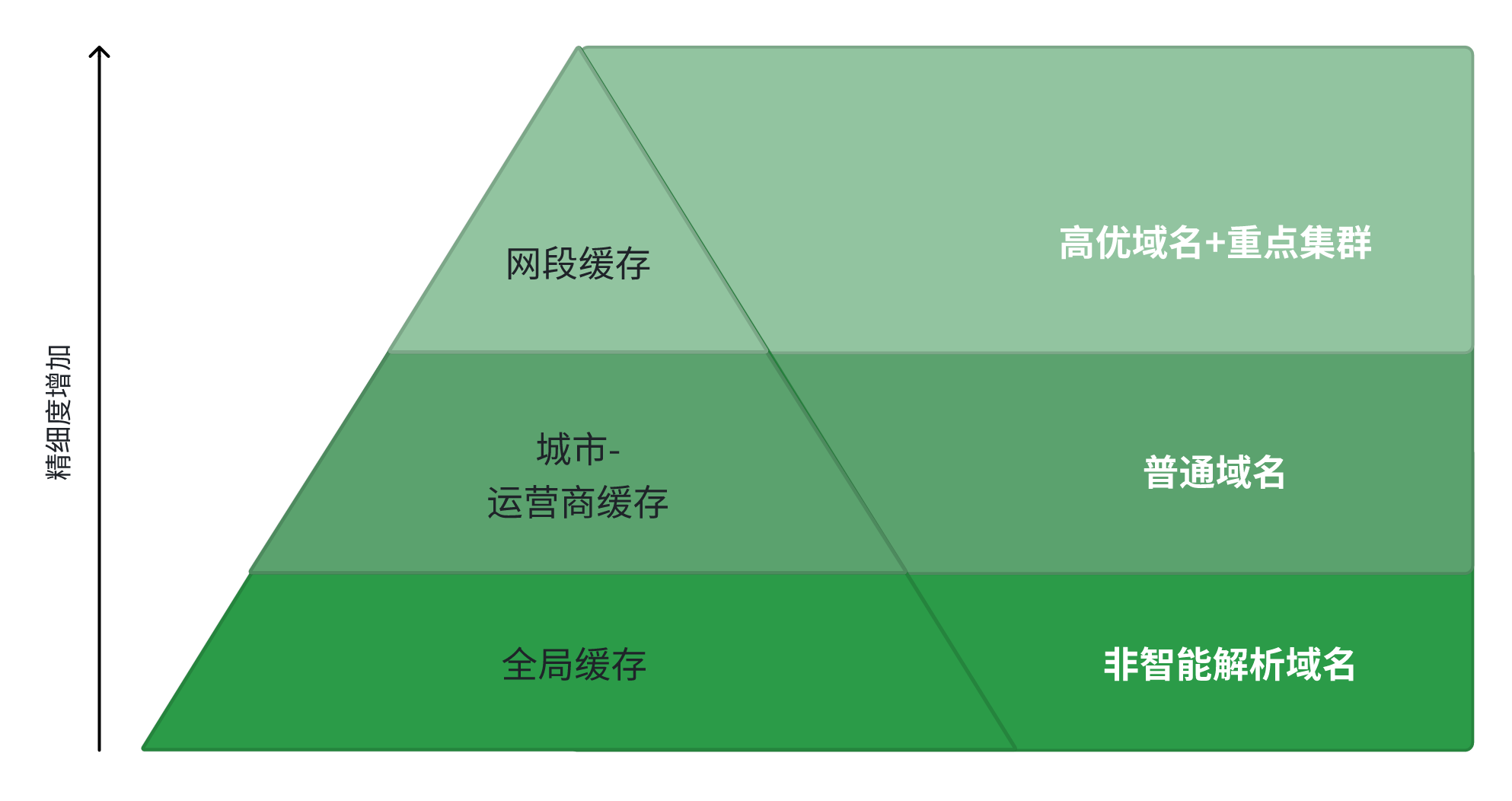
在 HTTPDNS 场景中,不同域名对解析精度的需求不同。高优先级域名(如 API 调用、直播 / 点播流媒体分发)对解析精准性要求高,缓存不够精细可能导致跨网访问延迟增加;而低精度需求域名(如 302 域名)采用过细缓存会浪费存储资源,频繁回源请求也会增加权威 DNS 压力。
为实现缓存资源的精细化分配,火山 HTTPDNS 将缓存体系划分为 “网段缓存、城市 - 运营商缓存、全局缓存” 三级,各级缓存适配不同应用场景。
网段缓存:作为最高精度层级,聚焦高优先级业务场景 :一方面适配高优域名(如抖音 API 调用、图片分发、点播 / 直播流媒体传输等对精准性敏感的域名),另一方面服务重点集群(如 ToB 企业 HTTPDNS 服务、ToB 专属公共 DNS 服务),通过网段级细粒度缓存确保解析结果与用户实际网络链路高度匹配,降低跨网访问延迟;
城市 - 运营商缓存:定位为中等精度层级,适配普通域名场景:针对调度精准度要求较低的域名,以 “城市 + 运营商” 为缓存单元,平衡缓存命中率与存储开销;
全局缓存:作为基础精度层级,专门适配非智能解析域名:针对不支持 CDN 动态调度、解析结果无地域 / 运营商差异的域名(如静态官网、通用工具类服务域名),采用全局统一缓存策略,所有用户查询共享同一缓存结果,最大化提升缓存命中率,降低对权威 DNS 的回源请求压力。
缓存更新分级策略
在 HTTPDNS 系统,统一的主动刷新策略虽然能保证缓存命中率,但存在明显问题:对不需要精细调度的域名浪费资源,同时大量后台线程的集中刷新增加了下游压力。
基于以上问题,火山 HTTPDNS 引入 “主动刷新 + 被动刷新”分级策略,以域名优先级和业务需求差异为依据,将缓存更新分为两类:
后台线程主动刷新机制:针对高优域名(白名单),保留后台线程主动刷新,确保缓存持续有效、用户请求直接命中最新数据;
用户请求被动刷新机制:针对普通域名或非智能解析域名,由请求触发缓存更新,按需刷新,无需常驻后台监控线程,降低系统资源消耗。
通过这种分级更新策略,高优先级域名仍能保证低延迟和高命中率,同时普通域名的刷新开销被显著降低。
缓存预取机制
依托 “缓存空间局部性原理”,火山 HTTPDNS 设计了缓存预取机制。当某条缓存请求(如 A 网段域名解析)触发更新时,系统不仅刷新目标网段缓存,还会同步更新与其具有 “亲缘关系” 的网段缓存(“亲缘关系”指地理相邻、同运营商节点覆盖的网段)。这种 “单次请求触发批量预取” 的设计能够提前将关联网段缓存置于准备状态,提升后续请求的命中率。
以抖音直播域名的实际访问场景为例,预取机制的运作过程如下:
本网段更新:当用户 A(IP 归属北京联通 10.0.1.0/24 网段)发起直播域名解析请求时,系统首先刷新其所属的 10.0.1.0/24 网段缓存。
预取更新:系统同时刷新与 10.0.1.0/24 网段具有亲缘关系的网段缓存,例如北京联通下的相邻网段(10.0.2.0/24、10.0.3.0/24),确保这些网段缓存也处于最新状态。
随后,当用户 B(10.0.2.0/24)或用户 C(10.0.10.0/24)发起相同直播域名的解析请求时,由于对应网段缓存已提前预取,无需等待回源即可直接命中缓存,显著降低访问延迟。
全链路效能提升
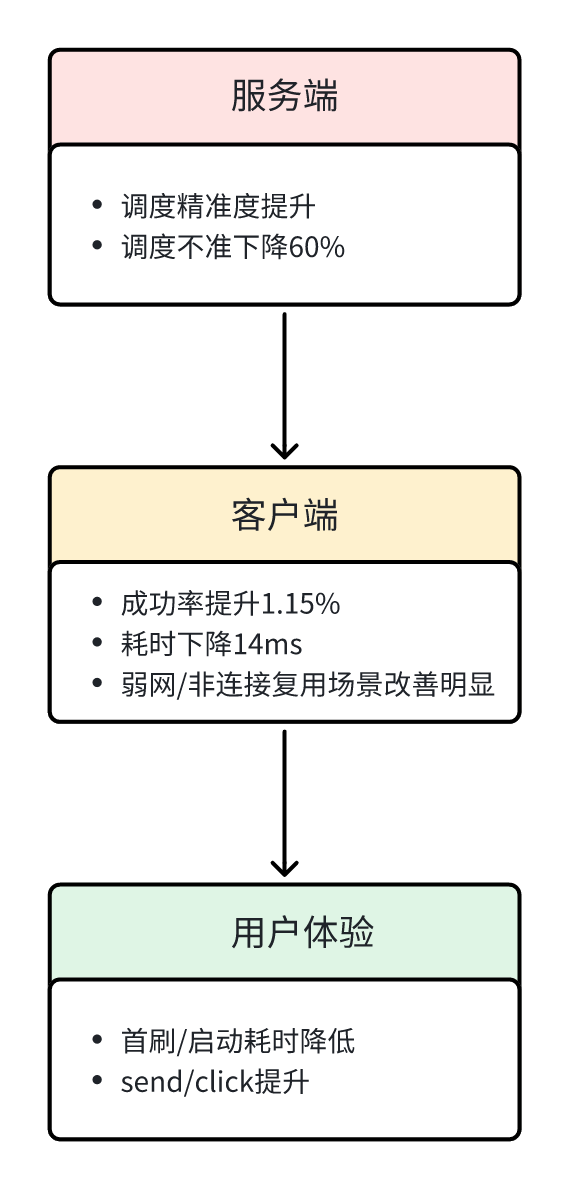
服务端调度精准度提高
借助网段级缓存,用户获取的 IP 地址更加精准。服务端调度不准比例从万分之六下降至万分之二,降幅 60%,有效缓解了传统粗粒度缓存导致的“省份/城市级缓存污染”问题。
客户端性能优化
成功率:核心 feed 接口,在弱网+非连接复用场景下提升 1.15%
耗时:非连接复用场景耗时减少 14ms
用户体验提升
性能指标:首刷及启动耗时下降
用户指标:用户行为指标(send 与 click)正向,用户活跃度提升
本方案通过服务端精准调度 → 客户端性能优化 → 用户行为改善的闭环,实现了全链路效能提升,既保证了调度精度,也优化了客户端访问体验和用户活跃度。
持续演进方向
共享缓存
目前,各机房的负载均衡策略与缓存策略未能完全对齐(部分采用随机转发,部分虽然使用一致性哈希但粒度不一致),导致同一数据在多个实例中被重复缓存,资源利用率偏低,缓存命中率也有待提升。
未来,我们计划构建一个分层共享的高可用缓存体系:
在同一机房内,实例通过一致性哈希协同分工,每台既承担分片缓存,也能代理转发请求,从而减少重复存储并提升命中率;
在跨机房层面,按区域部署二级缓存节点,作为容量更大、延迟更低的共享中心,承接一级未命中的请求,降低跨区域访问和上游压力。与此同时,引入热点数据副本、请求合并和故障转移等机制,保证高并发和异常情况下的稳定性与可用性。
通过这一演进,整体架构将逐步升级为层次化、分布式且具备高可用能力的缓存网络,为未来大规模业务的持续扩展提供坚实支撑。




