
前段时间 Current 2024 在 Austin 圆满结束,这是全球范围内 Kafka 和数据流处理领域的顶尖会议。今年是我第三次参加,和往常一样,会议聚集了来自全球的专家。但今年又让人感到分外不同—— Kafka 未来的不确定性明显增加。这个项目将走向何方?其生态系统将如何演变,Kafka 在快速发展的 AI 领域中将扮演什么角色?这些问题在我思考 Kafka 未来时一直萦绕心头。
现代数据架构新需求
大约 13 年前研发于 LinkedIn 的 Kafka ,最初被定位为一个 分布式、持久化、高吞吐量的消息系统,旨在低延迟地收集和传输大量数据。2011 年 Kafka 开源,后来被捐赠给 Apache 基金会,最终演变为现代软件中最成功的项目之一。2014 年,其创始人离开 LinkedIn 创办了 Confluent,该公司于 2021 年上市,并成为数据流处理领域的领导者。然而十多年间技术日新月异,Kafka 如今面临更加复杂的生态。
Kafka 最初被定位为一个分布式、持久、高吞吐量的消息系统。
在 2011 年,Kafka 主要有三个用例:
收集日志数据
将日志数据输入在线应用
将衍生数据部署到生产环境
Kafka 的日志结构设计在这个应用背景下是完全合理的。但随着上下游基础设施、应用程序和数据栈的快速演变,虽然其核心用例至今依然类似,来自现代数据架构的新需求却为 Kafka 带来了新的挑战。
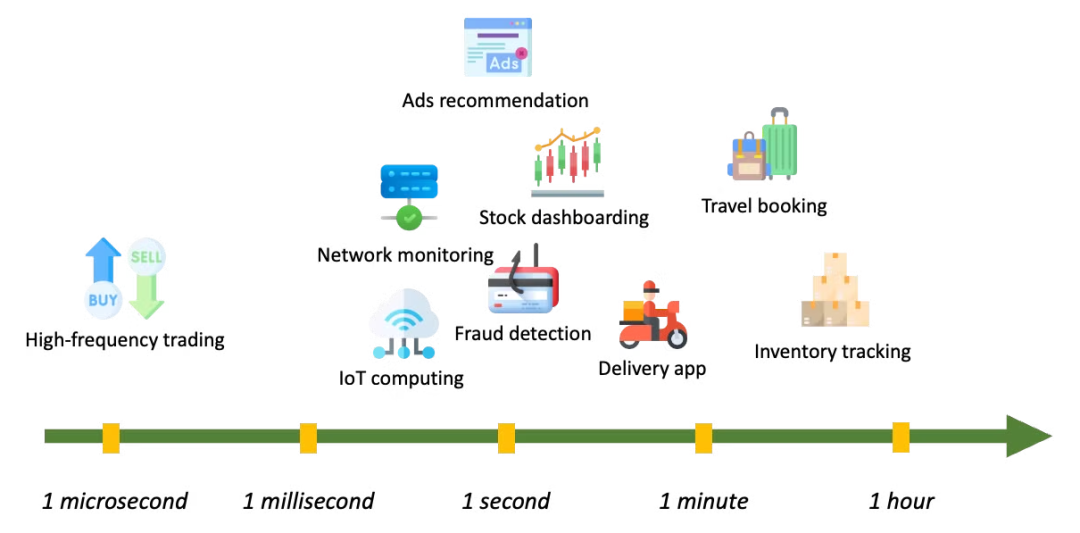
不同应用程序有不同的延迟要求。
新的挑战
延迟要求多样化:现代系统的延迟需求变得更加两极化。比如金融服务中股票交易对于延迟的需求达到微秒级,而如日志记录或在操作数据库和分析系统之间同步数据等场景,秒级延迟就能满足需要。因此一刀切的解决方案已不再适用,为什么一个使用 Kafka 进行简单日志记录的公司要与用其构建核心低延迟应用的公司支付相同的费用呢?
批处理系统构建自有数据摄取工具:像 Snowflake 的 Snowpipe、Amazon Redshift 的 noETL 以及最近收购了 PeerDB 的 ClickHouse 等,这些平台现在都提供内置的流数据摄取工具,使得 Kafka 不再是不同环境间移动数据以及将数据输入分析系统的唯一选择。
云基础设施存储成本降低:像 Amazon S3 这样的对象存储解决方案已经比像 EC2 这样的计算节点解决方案成本显著降低。在优化云上成本的趋势背景下,Kafka 需要拥抱能利用成本更低存储选项的架构,否则其自身可能成为数据管道中的昂贵组件。
鉴于以上挑战,Kafka 不能再依赖其原始架构。它需要演变并适应现代数据生态系统的新需求,以求在云优先趋势化的世界中保持领先。
Kafka 使用成本降至十分之一
Current 2024 上最令人兴奋的消息之一就是 Confluent 收购 WarpStream——一个兼容 Kafka 的系统,可将运行 Kafka 的成本惊人地降低为原来的十分之一。WarpStream 使用 S3 作为主要存储,消除了对本地磁盘的需求,并显著降低了网络传输费用。通过将存储层转移至成本更低的基于云的对象存储,WarpStream 使得 Kafka 更加经济实惠。
收购 WarpStream 的战略目标非常明确——在这个日益崛起的竞争对手干扰市场并迫使所有玩家利润减少之前,先将其拿下。通过将 WarpStream 的高性价比架构整合进 Kafka 生态系统,Confluent 就不会因更便宜的替代品冲击而失去其行业领导地位。
但是,不仅仅只有 WarpStream 在降低 Kafka 的使用成本。以下是其他推动 Kafka 使用成本降低的公司:

Kafka 使用成本必降低是大势所趋,尤其是对于那些仅需要 Kafka 进行日志记录或系统解耦的用户来说。他们通过采用以 S3 作为主要存储层的架构消除了对昂贵本地磁盘的需求,从而轻松降低成本。
进军批处理、拥抱 Iceberg
Kafka 一直是实时流处理的首选工具,但如今 Kafka 必须在批处理领域拥有一席之地。挑战与机遇并存——越来越多的数据仓库和分析数据库正构建自己的数据摄取工具,这意味着用户不一定需要选择 Kafka 。
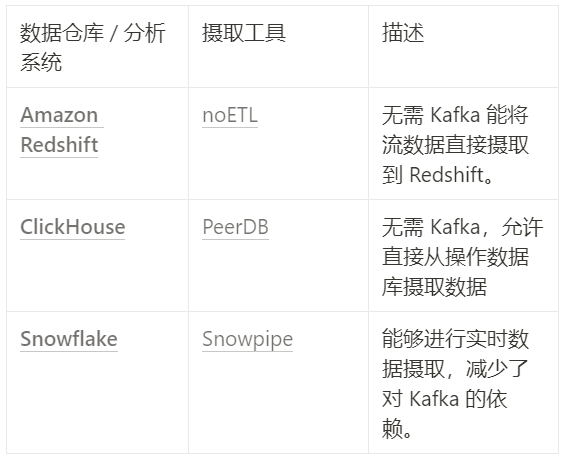
如果 Kafka 不进军批处理,其在数据生态系统中的重要性可能会逐渐下降。
随着数据架构逐渐转向在 S3 上存储冷数据以节省成本,Kafka 必须重新定位自己,要既能处理实时数据也能处理历史数据。这时 Apache Iceberg 的出现至关重要。Iceberg 是一种用于处理大规模数据集的开放表格格式,迅速成为现代数据湖的重要组成部分。通过拥抱 Iceberg,Kafka 可以让用户无缝存储和查询流数据及批数据。
与其使用 Kafka 保留短期数据,另外使用单独的数仓或湖仓存储历史数据,不如将 Kafka 作为所有数据的中央存储库——无论是流数据还是批数据,通过扩展其能力以处理长期存储而不需要依赖数据保留策略,Kafka 可以演变成真正的数据湖。而 Iceberg 在这一转型中扮演了关键角色,为用户提供了如架构演进、分区和优化查询性能等好处。随着 Iceberg 的广泛采用,组织可以利用它以开放格式查询 Kafka 数据,为流处理和批处理工作负载开启新的用例。
如果不拥抱批处理并与 Iceberg 等集成,Kafka 将可能被能以统一、经济高效的方式同时处理批处理和流处理的系统所取代。Iceberg 弥补这一差距的能力是其在数据工程师和架构师中日益受欢迎的主要原因之一。
拥抱流处理优先的查询引擎
为了充分实现 Kafka 在流处理和批处理领域的潜力,它需要一个流处理优先的查询引擎。虽然像 Trino 这样的批处理优先查询引擎在对大型数据集进行即席查询时表现优秀,但在处理连续查询时却捉襟见肘——而这又是 Kafka 用户的一个关键需求。
几种引擎已经站出来填补了这个空白。RisingWave 和 Flink 是流处理优先引擎的佼佼者,擅长处理实时、不断更新的数据。RisingWave 特别适合在事件流上运行 SQL 查询,使用户能够实时获得洞见,而无需面对传统流处理的复杂性。同样,Flink 的分布式流处理能力使其成为要求低延迟、高吞吐量应用的最优选择之一。
此外,ksqlDB 是 Kafka 的扩展,提供了一个简单的基于 SQL 的接口,用于实时查询和处理 Kafka streams。它与 Kafka 的深度集成,使其成为已在使用 Kafka 生态系统用户的优先选择。
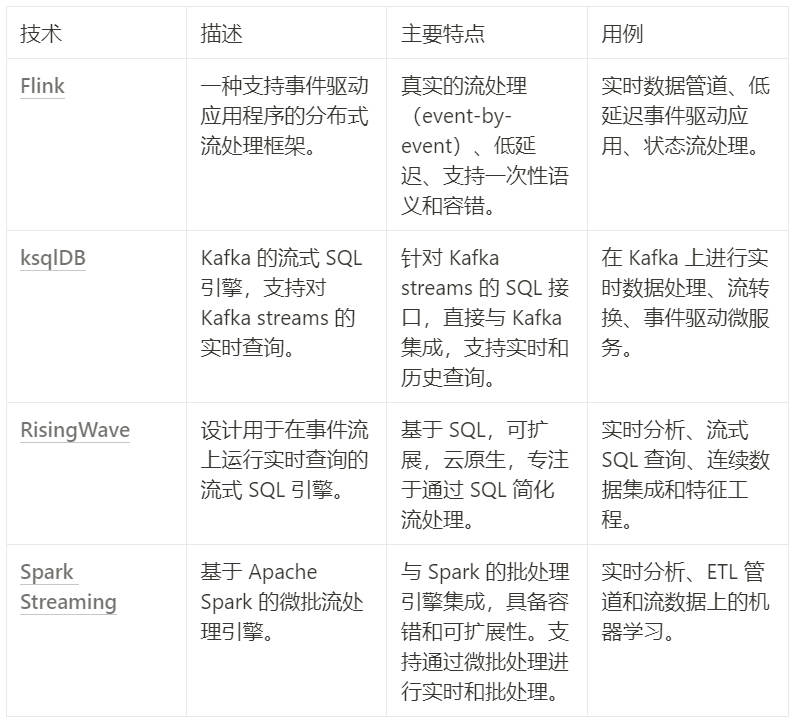
这些流处理优先引擎对于使 Kafka 数据(无论新数据还是历史数据)能够实现即时查询至关重要。通过解锁无缝查询实时和历史数据集的能力,RisingWave、Flink 和 ksqlDB 正在为 Kafka 保持领先地位铺平道路,因为流处理和批处理之间的界限越来越模糊。
结论
像 Warpstream 这样更具成本效益的解决方案的崛起,标志着 Kafka 使用成本的必然降低。此外,扩展批处理功能并支持实时和历史数据查询将是其未来保持领先的关键。如 RisingWave、Flink 和 ksqlDB 这些技术领先的流处理优先查询引擎,是 Kafka 需要充分拥抱的。
通过适应这些发展趋势:降低成本、整合批处理功能并采用流处理优先查询引擎,Kafka 可以在未来数年依旧保持现代数据基础设施中心地位并屹立不倒。
今日好文推荐
下载量超 5000 万的知名应用,开发团队“全军覆没”,从此发版人唯剩老板一个
突发!上交所系统被买崩了?股票交易量火爆挤瘫系统,IT 部门天塌了!




