
整理 | 华卫、核子可乐
刚刚,OpenAI 的 CEO Sam Altman 对外发布重大变更计划:整合多项尖端技术的 GPT-5 将免费开放,o3 和 o4-mini 即将在几周内亮相,o3 Pro 也即将上线。Altman 还表示,他们在很多方面对 o3 之前所展示的内容进行了改进。
网友们在震惊之余纷纷表示,“OpenAI 也打算像 DeepSeek 那样把模型开源了吗?”并且,这次 OpenAI 和 DeepSeek 又是“前后脚”发布更新。
就在前日(4 月 3 日),DeepSeek 和清华大学研究人员最新发表了一篇关于奖励模型和 Scaling Law 的论文,正在 AI 社区中被广泛讨论。有许多人称:这表示“R2 马上要来了”。还有网友这样肯定其成果:“从我在 o3 推理链中读到的内容来看,这很可能是 o3 方法论。”

总的来说,DeepSeek 找到了一个能够有效实现推理时扩展、进而提升模型整体性能的新方法。主要成果如下:
提出一种名为自原则批判微调(SPCT)的方法,用于促进通用奖励建模在推理阶段的可扩展性,并由此训练出 DeepSeek-GRM 模型,又引入了元 RM 来指导投票过程,进一步有效提升 DeepSeek-GRM 的推理性能。据悉,DeepSeek-GRM 模型还将被开源。
通过实证表明,SPCT 显著提高了 DeepSeek-GRM 的质量和推理阶段可扩展性,在各种奖励建模基准测试中优于现有方法和多个强大开源模型。
将 SPCT 训练方案应用于更大规模的大语言模型,并发现相比于在训练阶段扩大模型规模,在推理时扩展的性能收益更高。
奖励建模到底是什么?
当前,强化学习(RL)作为大语言模型(LLM)的一种训练后方法,已大规模地被广泛应用,并在大语言模型与人类价值观的对齐、长期推理以及环境适应能力方面取得了显著的提升。
奖励建模(Reward Modeling)是强化学习中的一个关键组成部分,对于为大语言模型的回复生成准确的奖励信号至关重要。有研究表明,在训练或推理阶段,只要有高质量且可靠的奖励机制,大语言模型就能在特定领域中取得出色的表现。
这些特定领域中的高质量奖励主要来自于具有明确条件的人为设计环境或者来自于针对可验证问题的手工制定规则,例如部分数学问题和编码任务。在一般领域中,奖励生成更具挑战性,因为奖励的标准更加多样和复杂,并且通常没有明确的参考标准或事实依据。
通俗地讲,现在大模型在生成回复时需要对内容进行“打分”,比如判断众多答案中哪个更为准确、哪个更符合安全规范,目前它们仍然依赖于人类预先设定的规则来进行评判。但在面对实际的复杂情况时,这种方式就不太够用了,需要大模型能够实现自我学习,学会自主地应对各种情况下的“打分” 。
因此,无论是从训练后阶段(如大规模的强化学习)还是推理阶段的角度(如奖励建模引导的搜索)来看,通用奖励建模对于提升大语言模型在更广泛应用中的性能都至关重要。在实践中,要使奖励建模既具有通用性,又能在推理阶段实现有效扩展,存在着诸多挑战。
据了解,奖励建模方法主要由奖励生成范式和评分模式决定,这从本质上影响着奖励建模在推理阶段的可扩展性以及输入的灵活性,而奖励建模的性能可通过增加训练计算量和推理计算量来加以提升。现有的奖励生成范式包括标量式、半标量式和生成式方法,评分模式有逐逐点和成对式。
然而,成对式奖励建模仅考虑成对回复的相对偏好,缺乏接受单个或多个回复作为输入的灵活性;标量式奖励建模很难为同一个回复生成多样化的奖励信号,阻碍了通过基于采样的推理时扩展方法来获得更好的奖励。虽然当前已有不同的学习方法来提高奖励质量,但其中很少有方法关注推理阶段的可扩展性,也很少研究到学习到的奖励生成行为与奖励建模在推理时扩展的有效性之间的联系,导致性能提升依然有限。
DeepSeek 的主要技术突破
DeepSeek 团队在此前的研究中发现,恰当的学习方法可以实现有效的推理阶段可扩展性,这就提出了一个问题:能否设计一种学习方法,旨在为通用奖励建模实现有效的推理时扩展呢?
为此,这次他们分析了不同的奖励建模方法,并发现:逐点生成式奖励建模(GRM)可以在纯语言表示中统一对单个、成对和多个回复的评分;某些原则可以在合适的标准下指导生成式奖励建模的奖励生成,从而提高奖励质量。那么,奖励建模的推理阶段可扩展性或许可以通过扩展高质量原则的生成和准确的批判来实现。
SPCT
基于这一初步发现,该团队提出了一种新颖的学习方法——自原则批判微调(Self-Principled Critique Tuning,简称为 SPCT),以在生成式奖励建模中培养有效的推理阶段可扩展行为。通过利用基于规则的在线强化学习,自原则批判微调使生成式奖励建模能够学习根据输入查询和回复自适应地提出原则和批判,从而在一般领域中获得更好的结果奖励。
简单来说就是,SPCT 可以“教”大模型自主制定评分标准。
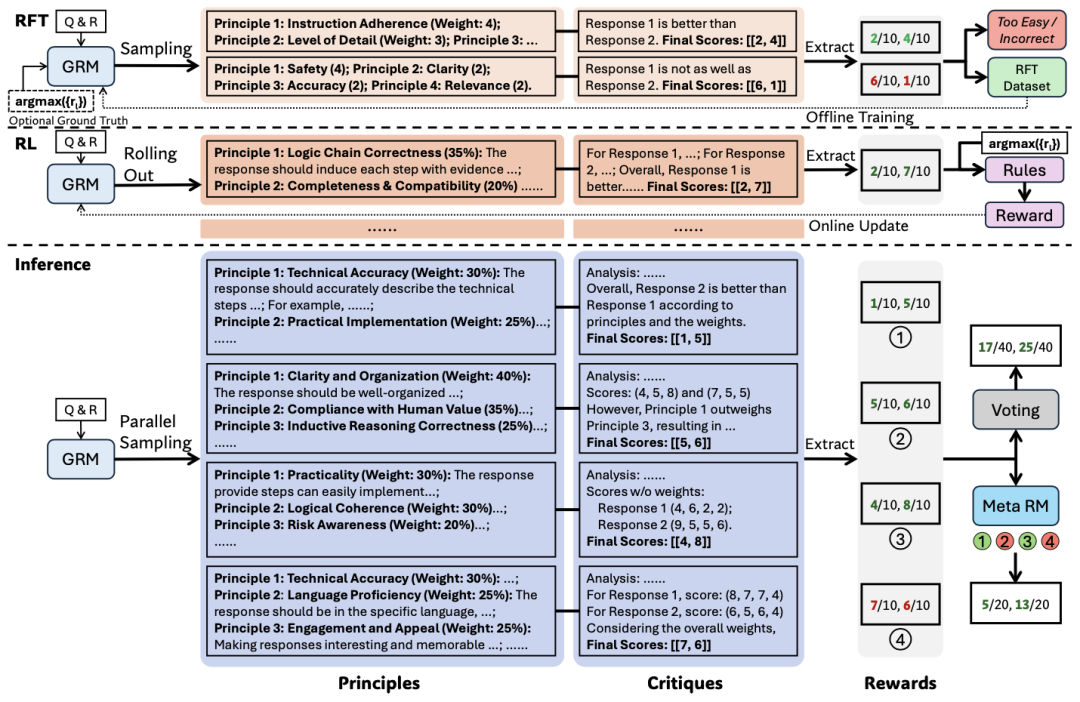
SPCT 的架构
据介绍,SPCT 包含两个阶段:作为冷启动的拒绝式微调,以及基于规则的在线强化学习,通过推进生成原则和点评以增强生成式奖励生成,同时支持推理时扩展。
其中,拒绝式微调的核心是让 GRM 生成格式正确且适用于多种输入类型的原则和批判。与以多种格式混合单 / 双 / 多响应数据的先前方案不同,逐点 GRM 灵活生成任意数量响应的奖励。数据构建时,除通用指令数据外,还使用预训练 GRM 从含多响应的 RM 数据中采样查询及对应响应。
超越以往研究的一大关键是,DeepSeek 团队观察到,提示采样轨迹可能会简化生成的批判(尤其在推理任务中),凸显了在线 RL 对 GRM 的必要性和潜在优势。
而该团队也通过基于规则的在线 RL 来进一步微调了 GRM,其采用 GRPO 的原始设置,使用基于规则的产出奖励。在滚动过程中,GRM 基于查询和响应生成原则和点评,然后提取预测奖励并与真值通过准确率规则进行比较。与 DeepSeek R1 不同,他们这次不使用格式奖励,而是应用更大的 KL 惩罚系数以确保格式并避免严重偏差。
基于 SPCT 的推理时扩展
为利用更多推理计算提升 DeepSeek-GRM 的生成式奖励生成性能,该团队探索了基于采样的策略,以实现有效的推理时扩展。
首先是通过生成式奖励进行投票。通过用 SPCT 进行后训练,DeepSeek 基于 Gemma-2-27B 提出了 DeepSeek-GRM-27B,其通过多次采样来扩大计算量的使用。通过并行采样,DeepSeek-GRM 可以生成不同的原则集以及相应的批判,然后对最终奖励进行投票。通过更大规模的采样,DeepSeek-GRM 可以根据更多样化的原则做出更准确的判断,并输出更精细的奖励。
直观解释是:若每个原则可视为判断视角的代理,更多原则可能更准确地反映真实分布,提高扩展有效性。值得注意的是,为避免位置偏差并增加多样性,会在采样前打乱响应顺序。
除此之外,DeepSeek 团队还训练了一个元奖励模型(meta RM)来引导投票过程。DeepSeek-GRM 的投票过程需要多次采样,部分生成的原则和点评可能因随机性或模型限制存在偏差或低质量问题。元奖励模型为逐点标量 RM,训练目标为识别 DeepSeek-GRM 所生成原则和点评的正确性。
准确率超越 GPT-4o,领域偏差更小
从实验结果看,SPCT 显著提高了 GRM 的质量和可扩展性,在多个综合奖励建模基准测试中优于现有方法和模型,且不存在严重的领域偏差。
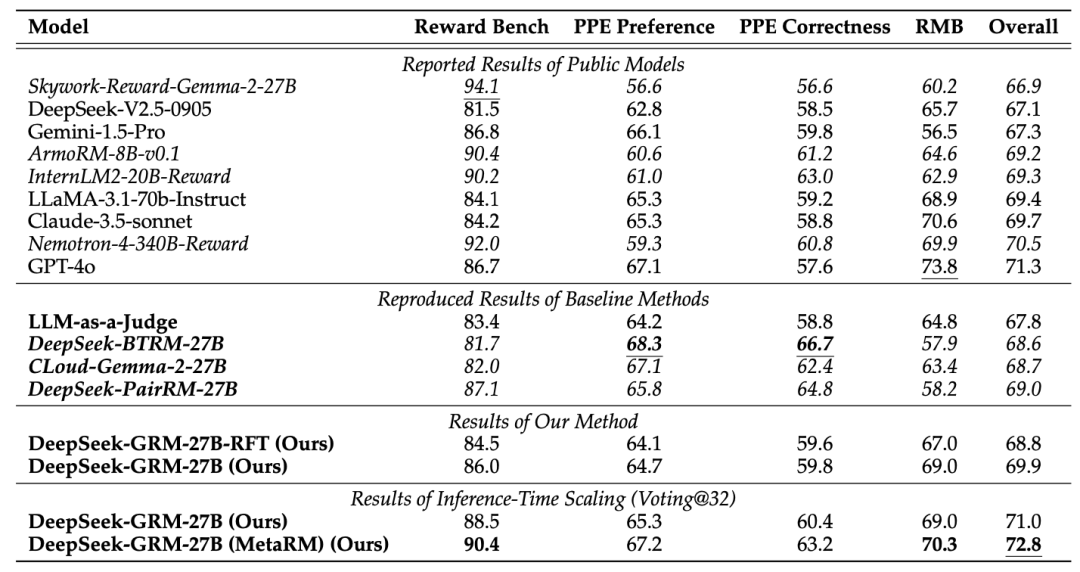
不同方法和模型在 RM 基准测试上的总体结果
该团队将 DeepSeek-GRM-27B 的性能与公开模型的已报告结果以及各基准方法的复现结果进行了比较,并发现,DeepSeek-GRM-27B 在总体性能上优于基准方法,并且与强大的公开奖励模型相比,如 Nemotron-4-340B-Reward 和 GPT-4o,取得了具有竞争力的性能;通过推理时扩展,DeepSeek-GRM-27B 能够进一步提升并取得最佳的总体结果。
详细比较中,标量 RM(DeepSeek-BTRM-27B、DeepSeek-PairRM-27B)和半标量 RM(CLoud-Gemma-2-27B)在不同基准上表现出显著领域偏差,在可验证任务(PPE 正确性)上优于 GRM,但在其他基准上不及。多数公共标量 RM 也存在严重领域偏差。LLM-as-a-Judge 与 DeepSeek-GRM-27B 趋势相似但性能较低,可能是因为缺乏原则引导。总之,SPCT 提高了 GRM 的奖励生成能力,与标量和半标量奖励模型相比,偏差明显更小。
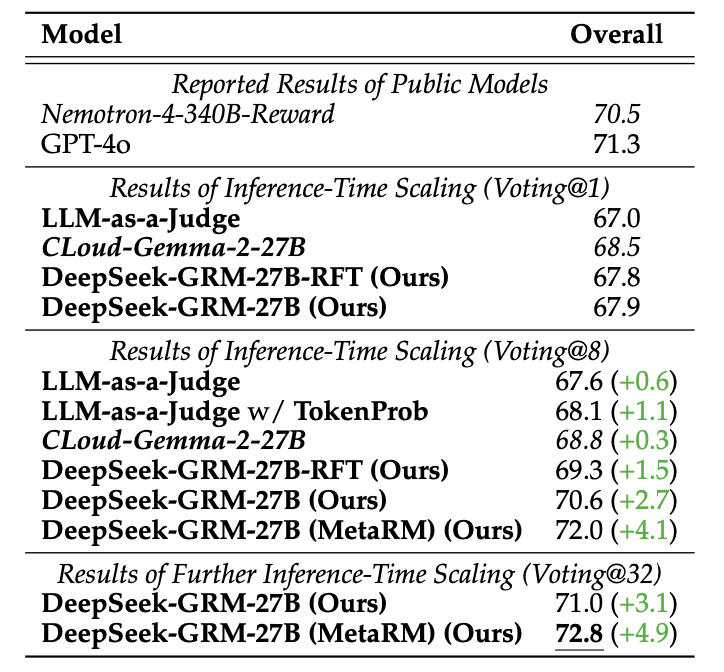
不同方法在 RM 基准测试上的推理时扩展结果
在最多 8 次采样下,DeepSeek-GRM-27B 相比贪心解码和单次采样性能提升最大,且随计算量增加(最多 32 次采样)展现出强扩展潜力。在每个基准测试中,元奖励模型也显示出其在为 DeepSeek-GRM 过滤低质量轨迹方面的有效性。LLM-as-a-Judge 通过 token 概率加权投票也显著提升性能,表明定量权重可提高多数投票的可靠性。Cloud-Gemma-2-27B 性能提升有限,主要因标量奖励生成缺乏方差。
总之,SPCT 提高了 GRM 的推理时可扩展性,并且元奖励模型进一步提升了扩展性能。
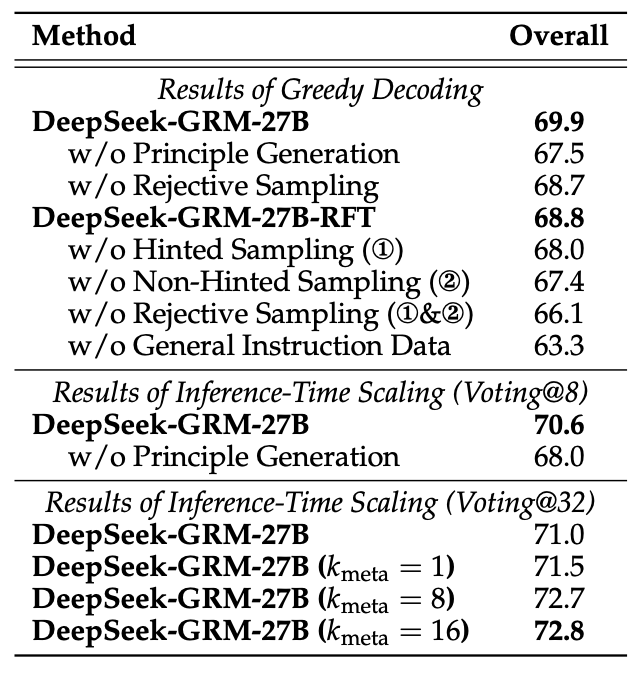
拟议 SPCT 不同组成部分的消融研究,粗体数字表示最佳性能
令人惊讶的是,即使没有使用拒绝采样的评估数据进行冷启动,经过在线 RL 后,通用指令微调的 GRM 仍然有显著提升,从 66.1 到 68.7。此外,非提示采样似乎比提示采样更重要,可能源自提示采样轨迹中的捷径问题。这些结果表明在线训练对 GRM 的重要性。与以往的研究发现一致,DeepSeek 团队确认通用指令数据对 GRM 性能至关重要。原则生成对 DeepSeek-GRM-27B 的贪心解码和推理时间扩展均至关重要。
该团队还通过在不同规模的大语言模型上进行训练后处理,进一步研究了 DeepSeek-GRM-27B 在推理时间和训练时间方面的扩展性能。其发现,DeepSeek-GRM-27B 使用 32 个样本进行直接投票可以达到与 671B 混合专家模型(MoE)相当的性能,而元奖励模型引导的投票在 8 次采样时可以取得最佳结果,这表明与扩大模型规模相比,DeepSeek-GRM-27B 的推理时扩展是有效的。
最后,他们使用包含 300 个样本的下采样测试集对 DeepSeek-R1 进行了测试,发现其性能甚至不及 236B MoE RFT 模型,这表明为推理任务扩展思维链长度并不能显著提升 GRM 的性能。
尽管当前的方法在效率和特定任务方面面临挑战,但 DeepSeek 相信,通过 SPCT 之外的努力,具有更高可扩展性和效率的 GRM 可以作为通用奖励系统的通用接口,推动大语言模型训练后阶段和推理的前沿发展。
参考链接:




