
简介
大多数构建 Apache Kafka 和 Apache Flink 管道的团队,在事件目录中的类型达到几十种左右时,都会遇到同样的瓶颈。开始的时候,系统结构清晰,每个事件都有独立的模式,但随着时间的推移,这逐渐变成了维护负担。查询变得复杂,模式变更演变成了协调工作,而数据湖也开始变得像是一片数据沼泽。
本文的重点是探讨这一具体的问题:因事件与模式的一对一映射而导致的模式泛滥。这是一个逐渐积累的结构性问题,一旦形成将难以修复且成本高昂。基于标识字段的模式整合是一种能够减少模式数量、简化下游使用,并使模式演进变得可控的模式。
本文使用的示例来自网约车领域,这个场景能直观地呈现这一问题。该模式同样适用于任何具有高基数事件类型且结构显著重叠的系统,包括呼叫中心平台、金融交易系统以及医疗健康事件管道。
大规模的一对一映射是什么样子
我们先从一个简单的例子开始。某拼车平台会跟踪司机在以下几种事件类型中的活动:
接单
行程开始
行程结束
行程取消
这四种事件类型涵盖了司机处理乘车请求的完整生命周期,从司机接受新请求的那一刻起,直至最终完成或取消。每个事件都包含时间戳、司机标识符、行程标识符以及在所有事件变体中均出现的城市上下文信息。
此外,每种事件还会因行程类型而有所不同:
标准
拼车
预约
标准行程是指单人乘车,会记录车辆等级和动态价格。拼车行程则将多名乘客合并,除记录乘客人数外,还会显示拼车效率评分。预约行程需要提前预订,包含预定的出发时间以及预订与行程开始之间的时间间隔(以分钟为单位)。
人们的本能反应是为每种组合创建一个数据模型。这种方法会带来以下结果:
DriverRideAcceptedStandardEventDriverRideAcceptedSharedEventDriverRideAcceptedScheduledEventDriverRideStartedStandardEventDriverRideStartedSharedEvent...针对四种事件类型和三种行程类型,共需要十二个模式。在实际的平台中,事件类型更多,子类型也更多,而且随着新功能的不断推出,列表还在不断增长。每个模式都映射到数据湖中一个独立的下游表。十二个模式意味着十二张表。如果你在 S3 上使用 Apache Iceberg,这就意味着需要管理十二张表、对十二个模式注册表条目进行版本控制,以及在 Flink 管道中处理十二个适配器类。系统能够正常运行,直到变得难以管理,如图 1 所示:N 种事件类型会扩展为 N 个独立的模式和 N 张独立的 Iceberg 表。跨事件变体查询需要对所有表执行 UNION 操作。
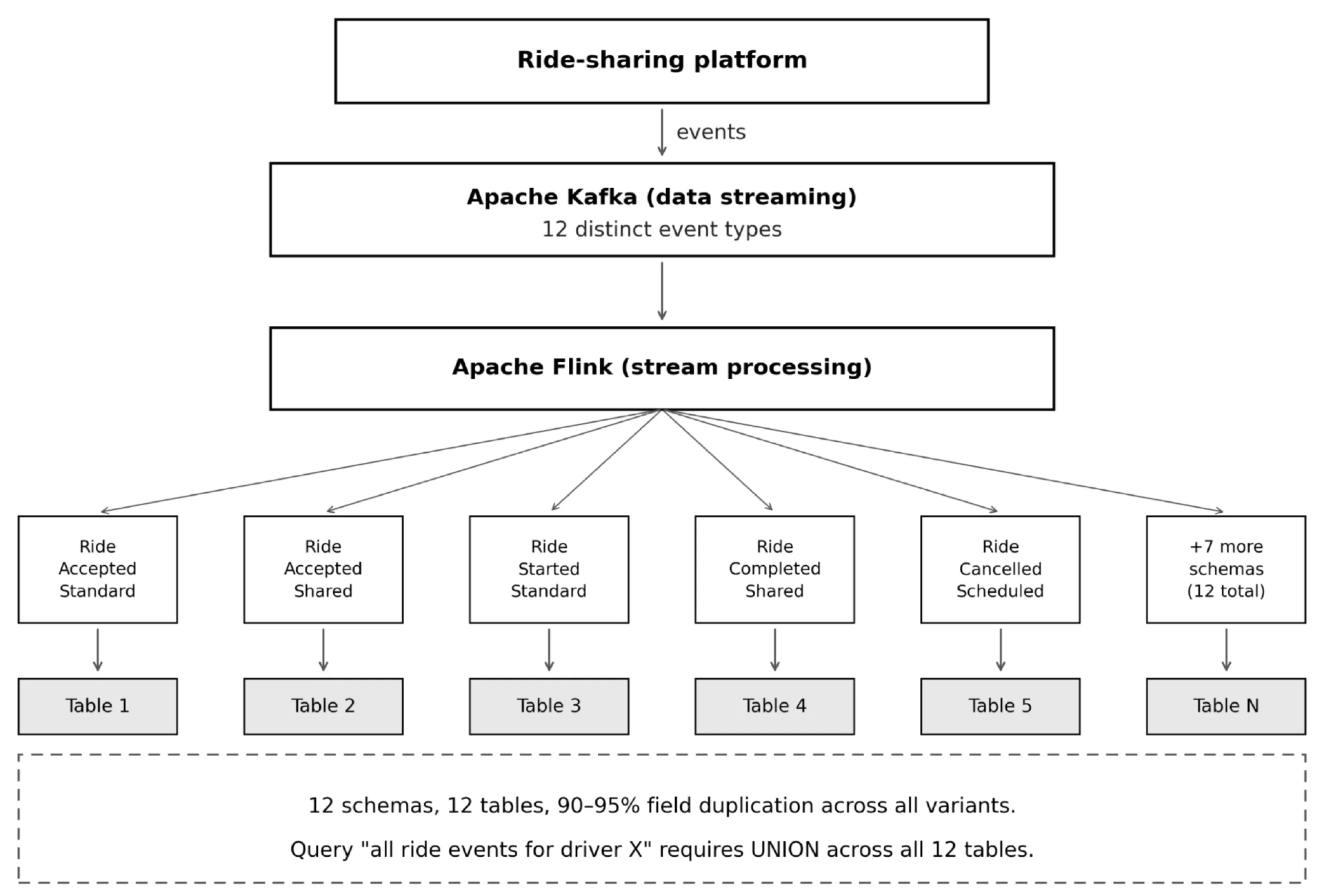
图 1. 模式膨胀(每个事件变体对应一个模式)(改进前)(图片由作者提供)
问题:模式膨胀
当系统中模式累积的速度超过团队应对其复杂度的能力时,就会发生模式膨胀。这种现象主要有四个表现。
查询复杂度
当数据使用者想要回答“司机 4821 在过去一小时内做了什么?”时,就需要对所有相关的表进行并集操作。如果问题涉及多种事件类型和行程类型,查询就可能需要涉及八到十张表。这已经不再是简单的查询,而是一项工程。
维护开销
在分布式系统中,大多数模式的字段有 80% 至 95% 是一样的。当某个共有的字段发生变更时,包含该字段的每个模式都需要进行变更。一个字段的重命名就意味着需要进行 20 次模式更新、20 次适配器更新以及 20 轮测试。
模式漂移
如果模式由不同的团队独立维护,随着时间的推移,它们就会逐渐产生差异。一个团队添加的字段,与另一个团队用于表示相同概念的字段,其名称可能会略有不同。关于字段是否允许为空的决策会变得不一致。数据类型也会出现差异。这种不一致并非有意为之,而是在缺乏强制机制来保持模式一致性的情况下自然产生的。
生产者-消费者失配
一对一的模式设计旨在优化生产端。从消费端来看,所有这些事件都是同一概念的不同表现形式:行程生命周期中发生了某些事情。消费者希望能够将这些事件一并查询,而无需考虑十二张表中哪一张存储了他们需要的记录。以生产者为中心的模式与以消费者为中心的查询方式之间脱节,是导致模式泛滥问题的根本原因。
解决方案:整合模式设计
在高基数系统中,大多数事件变体都具有相同的核心结构。DriverRideAcceptedStandardEvent 与 DriverRideAcceptedSharedEvent 之间的差异微乎其微,绝大部分内容完全相同。
与其为每个变体创建独立的模式,不如如图 2 所示,为每个逻辑域使用一个整合模式,通过标识字段来标识变体,并使用可为空的属性块来承载变体特有的数据。这种整合方法将十二种事件类型的变体合并为单一的 DriverRideActivityRecord 模式。消费者只需要查询一张表,并通过标识字段进行过滤,而不需要使用 UNION 操作。
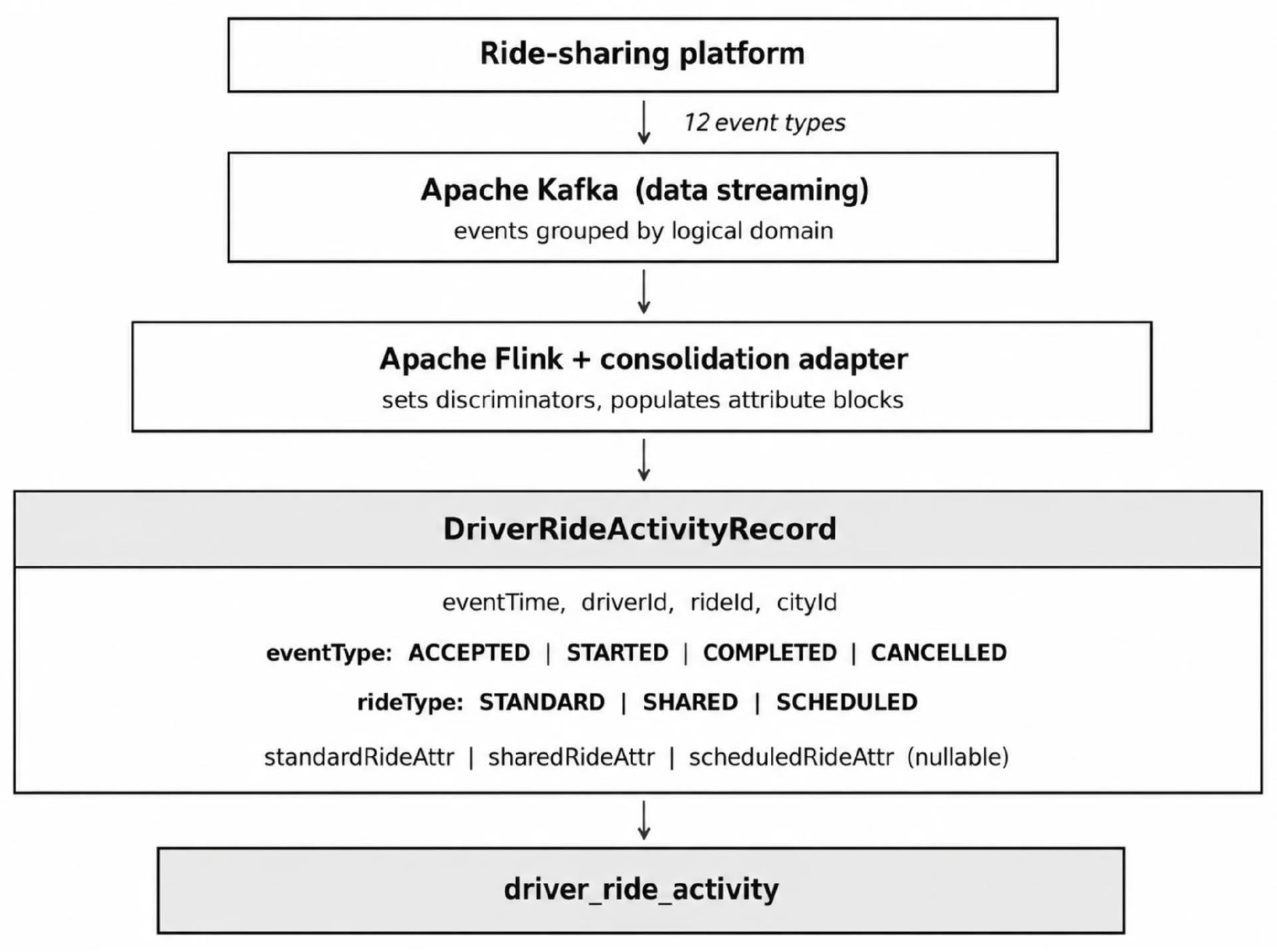
图 2. 整合模式:基于标识字段的路由(改进后)(图片由作者提供)
标识字段
整合模式中的每条记录都包含明确的标识字段,用于精确标识其所代表的事件类型:
eventType: enum (ACCEPTED, STARTED, COMPLETED, CANCELLED)2rideType: enum (STANDARD, SHARED, SCHEDULED)这些字段始终有值。用户不需要通过查询十二张表来获得已完成的行程,而只需要查询一张表并按 eventType = ‘COMPLETED’ 进行筛选即可。
使用枚举而非自由格式字符串,这一点至关重要。枚举能在适配器代码中提供编译时安全性,在下游查询引擎中实现高效的谓词过滤,并明确记录哪些值是有效的。如果使用普通字符串字段,则无法阻止生产者将 “COMPLETED” 写成 “complete”,在不知不觉中破坏下游过滤器。
共有字段
无论何种变体,在每条记录中都出现的字段应放置在整合模式的上面:
eventTime: timestampdriverId: stringrideId: stringcityId: stringfareAmount: double (预完成事件为 null )durationMins: int (预完成事件为 null )可空属性块
仅适用于特定行程类型的字段被归类到可为空的嵌套结构中。每条记录仅填充其中的一个字段块,其余均为空。
{ "type": "record", "name": "DriverRideActivityRecord", "fields": [ {"name": "eventTime", "type": "long"}, {"name": "driverId", "type": "string"}, {"name": "rideId", "type": "string"}, {"name": "eventType", "type": {"type": "enum", "name": "EventType", "symbols": ["ACCEPTED","STARTED","COMPLETED","CANCELLED"]}}, {"name": "rideType", "type": {"type": "enum", "name": "RideType", "symbols": ["STANDARD","SHARED","SCHEDULED"]}}, {"name": "standardRideAttributes", "type": ["null", { "type": "record", "name": "StandardRideAttributes", "fields": [ {"name": "vehicleClass", "type": "string"}, {"name": "surgeMultiplier", "type": "double"} ] }], "default": null}, {"name": "sharedRideAttributes", "type": ["null", { "type": "record", "name": "SharedRideAttributes", "fields": [ {"name": "passengerCount", "type": "int"}, {"name": "poolingScore", "type": "double"} ] }], "default": null}, {"name": "scheduledRideAttributes", "type": ["null", { "type": "record", "name": "ScheduledRideAttributes", "fields": [ {"name": "scheduledTime", "type": "long"}, {"name": "advanceBookingMinutes","type": "int"} ] }], "default": null} ]}如图 3 所示,拼车记录会填充 sharedRideAttributes 字段,并将所有其他属性块设为 null。标识字段 rideType = SHARED 用于告知消费者应该检查哪个块。
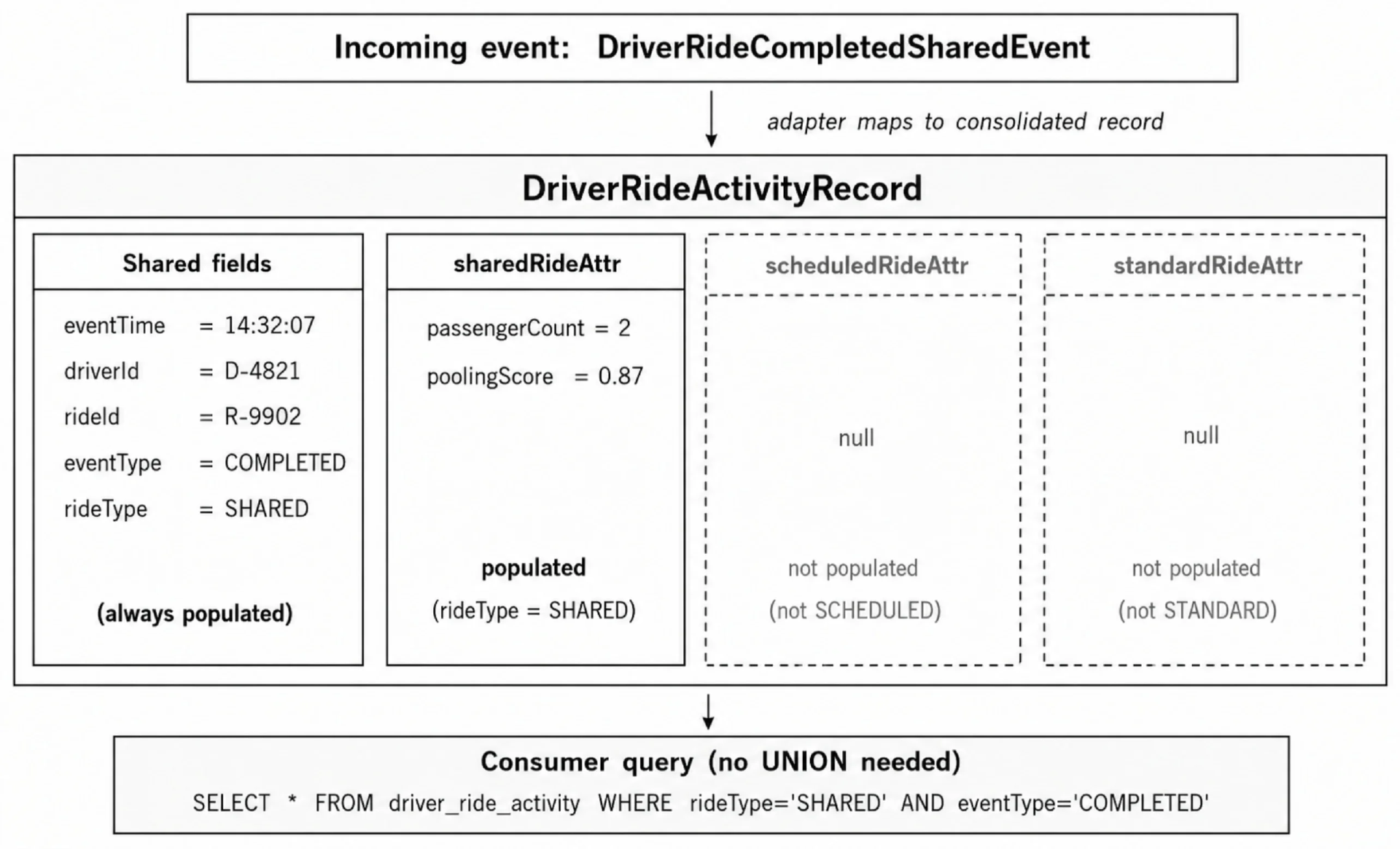
图 3. 可为空属性块:每条记录中仅填充一个块(图片由作者提供)
在 Flink 管道中实现这个模式
在 Kafka-Flink 管道中,数据整合发生在 Kafka 数据摄取与下游序列化之间的处理层。该架构采用两层结构。
第一层:转换逻辑
每种源事件类型都有一个专用的适配器类,负责将该事件映射到整合模式:
public class SharedRideAcceptedAdapter implements RecordAdapter<DriverRideAcceptedSharedEvent, DriverRideActivityRecord> { @Override public DriverRideActivityRecord adapt(String orgId, DriverRideAcceptedSharedEvent event) { DriverRideActivityRecord record = new DriverRideActivityRecord(); record.setEventTime(event.getTimestamp()); record.setDriverId(event.getDriverId()); record.setRideId(event.getRideId()); record.setCityId(event.getCityId()); record.setEventType(EventType.ACCEPTED); record.setRideType(RideType.SHARED); SharedRideAttributes attrs = new SharedRideAttributes(); attrs.setPassengerCount(event.getPassengerCount()); attrs.setPoolingScore(event.getPoolingScore()); record.setSharedRideAttributes(attrs); return record; }}这些适配器类不依赖于 Flink 框架。它们纯粹是转换逻辑,不需要做任何框架配置就可以轻松地进行单元测试。
第二层:框架集成
public class RideActivityConsolidationJob { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.enableCheckpointing(60_000, CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30_000); KafkaSource<RawRideEvent> source = KafkaSource.<RawRideEvent>builder() .setBootstrapServers(config.getKafkaBrokers()) .setTopics("ride-events") .setGroupId("ride-consolidation-consumer") .setValueOnlyDeserializer(new RawRideEventDeserializer()) .build(); env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka ride events") .map(new ConsolidationAdapter(adapterRegistry)) .sinkTo(icebergSink); env.execute("Ride Activity Schema Consolidation"); }}该任务从单个 Kafka 主题读取原始事件,将每个事件路由至 ConsolidationAdapter。该适配器会根据事件类型查找正确的适配器并调用 adapt() 方法,随后将整合后的记录写入 S3 中的 Iceberg 表。
adapterRegistry 是一个映射表,其中记录了事件类型和与其对应的适配器实例。它在作业启动时初始化一次,并传递给 ConsolidationAdapter 类。调用 WatermarkStrategy.noWatermarks() 是有意为之的,因为模式整合是一种无状态转换,不涉及事件时间分窗,所以无需推进水印。“恰好一次”检查点机制用于协调 Kafka 偏移量提交与 Iceberg 的事务性提交协议。因此,在故障后重启时,作业会从最后一个一致的检查点开始重放,而不会产生重复的记录。30 秒的最小暂停时间可防止一个执行缓慢的检查点立即触发下一个检查点。检查点间隔控制了重启时重放的数据量,你应该根据吞吐量和可接受的恢复时间进行调整。
使用 Apache Avro 进行模式演进
Apache Avro 是一种基于模式的二进制序列化格式,在 Kafka 管道中被广泛使用。它与模式注册表配合使用,用于管理模式版本并强制执行兼容性规则。随着系统规模的扩大,这两点都变得愈发重要。团队在讨论模式整合时提出的主要担忧之一是模式演进。如果所有内容都纳入一个模式,那么添加新的事件类型是否需要修改每个消费者?
不。规则是:新的属性块必须始终为可空类型,而且默认值为 null。当推出新的乘车类型时,模式更新会新增一个可为空的属性块 premiumRideAttributes (默认值为 null),并在 rideType 枚举中添加 PREMIUM 选项。
基于旧模式编译的现有消费者在读取新记录时,会发现 premiumRideAttributes 字段的值为 null。这些消费者不会出现故障,也无需重新部署。
有一点值得注意:向 Avro 枚举添加新值并非在所有模式注册表兼容模式下都是安全的。在向后兼容模式下,基于旧模式编译的消费者可能会遇到未知符号并抛出反序列化错误。向前兼容则涉及相反的方向,即旧版生产者写入的记录需要由新版消费者读取。对于随时间演进的整合模式,完全兼容(Full)或完全传递兼容(Full_Transitive)是最安全的设置,因为它同时验证了两个方向,并在枚举项添加到达生产环境之前将其捕获。
与之形成对比的是“一对一”方法。添加一种高级行程类型意味着需要新的模式、新的表、新的适配器代码以及新的 Schema Registry 条目,而希望查询所有行程类型的消费者现在需要在他们的联合查询中添加另一张表。
权衡取舍
更宽的记录
整合模式包含可为空的字段块,而对于大多数记录而言,这些字段块是空的。使用 Avro 并配合适当的空值处理,虽然序列化开销微乎其微,但并非为零。在极高的吞吐量下(例如每天数十亿个事件),在最终确定方案之前,有必要对额外的序列化开销进行基准测试。
模式治理
由多个团队共同拥有的整合模式需要有明确的责任归属。虽然具备强制兼容性规则的模式注册表能够自动处理技术层面的事务,但仍然需要有人负责决策哪些内容应纳入模式、哪些应排除在外。若是没有这一责任主体,虽然避免了模式泛滥,却会引发另一种形式的模式漂移。
故障排除
当特定事件类型出现问题时,该问题往往与其他众多的事件类型混杂在同一个表中。虽然增加一个筛选步骤并不费事,但这确实是对调试工作流的一项变更,有必要向团队单独说明。例如,如果不带 WHERE 条件,执行 SELECT * FROM driver_ride_activity LIMIT 100 这样的查询,返回结果将是包含所有事件类型的混合数据。这个问题虽然容易解决,但团队需要养成新的习惯。
何时不应该使用该模式
当事件类型在结构上存在重叠且经常被一起查询时,这种模式是有意义的。如果两种事件类型的字段完全不同,并且从未在同一上下文中被查询,那么将它们合并就没有实际的好处。
这种方法在实践中的具体表现
部署整合设计后,最直观的变化体现在数据层。一个此前需要跨十张独立的表进行查询的事件组,现在只需查询两张表。对于分析师而言,这意味着他们只需要写一个五分钟就能完成的查询,而不是一个需要了解哪些表存储了哪些变体、以及如何正确地进行联合查询的复杂查询。
模式变更的传播变得简单许多。当模式之间有 90% 至 95% 的字段共有时,以往对任何一个共有字段的修改,都需要更新所有包含该字段的模式,协调适配器的变更,并跨团队管理下游表的更新。而采用整合模式,同样的变更只需更新一个模式即可。
添加新的事件变体也遵循同样的模式。这种操作是可叠加的。它不会影响现有消费者,不需要新建表,也不需要从头编写新的适配器。
不只是适配器:原生多事件支持
当现有的管道框架每个映射仅处理一种事件类型时,本文所描述的双层适配器模式是理想的解决方案。这种模式既能带来所有的整合优势,又不需要对底层框架做任何修改。对于正在构建或扩展处理框架的团队而言,还有一种更简洁的方案:在框架层面原生支持每个映射处理多种类型的事件。
在适配器方案中,框架仍然认为自己处理的是一种事件类型。整合工作发生在在上面添加的那一层中。当框架原生支持将多种输入事件类型映射到单一输出模式时,便不再需要自定义路由层。转换逻辑本身——即负责将每个源事件映射到整合模式的适配器类——仍然存在。消失的是那个手动将事件路由到正确适配器的调度器。框架会原生地接管这一职责。
大多数团队实际采取的做法是:先实现适配器模式,用于验证整合后的模式设计是否可行。一旦其价值得到确认,原生框架支持的必要性便不言而喻。无论采取哪种方式,整合后的模式设计都保持不变,适配器层才是最终会被移除的部分。
小结
模式膨胀是一种看似尚可应对,实则并不好处理的问题。等到问题变得棘手时,分析师们正在编写涉及十二张表的联合查询,工程师们则为了重命名一个字段而不得不更新二十个模式。这些模式已然变成了承重墙。要解决这个问题,就需要跨团队协调、更新下游消费者,并迁移历史数据。这些并非无法实现,但代价都十分高昂。
此处的聚合模式并不适用于所有系统。当事件类型具有相似的结构且需要一起查询时,该模式效果良好。但它会增加治理开销,需要进行有意识的管理。对于某些团队而言,这种权衡并不值得。
但如果你面对的是一个不断膨胀的模式目录,且其中大多数模式的字段有八成到九成是相同的,那么值得思考的问题就不再是“是否要进行整合”,而是“还要等多久”。
参考实现可以从 GitHub 存储库中获取。
原文链接:https://www.infoq.com/articles/schema-proliferation-problem/




