
Pinterest 推出了新一代数据库摄取框架,旨在突破传统批处理系统的局限性,提升实时数据的可用性。旧有的基础设施依赖于多条独立维护的数据管道和全表批处理任务,导致延迟高、运维复杂且资源利用率低下。包括数据分析、机器学习和产品功能在内的关键应用场景亟需更快、更可靠的数据访问能力。
传统系统面临着几个关键的挑战。数据延迟经常超过 24 小时,拖慢了分析和机器学习工作流程。许多表每日的数据变化量不足 5%,但全表批处理会重复处理未更改的记录,浪费计算和存储资源。此外,传统系统未提供对行级删除的原生支持,管道之间的操作碎片化导致数据质量不一致且维护开销高。
正如 Pinterest 的一位工程师所强调的那样:
基于 Change Data Capture(Debezium/TiCDC)、Kafka、Flink、Spark 和 Iceberg 构建的统一数据库摄取框架仅处理有变化的记录,在几分钟内(而不是几小时或几天)就可以提供对在线数据库更改的访问,显著节省了基础设施成本。
该框架是一个配置驱动的通用框架,支持 MySQL、TiDB和 KVStore,便于快速部署,集成了监控且提供至少有一次的送达保证。
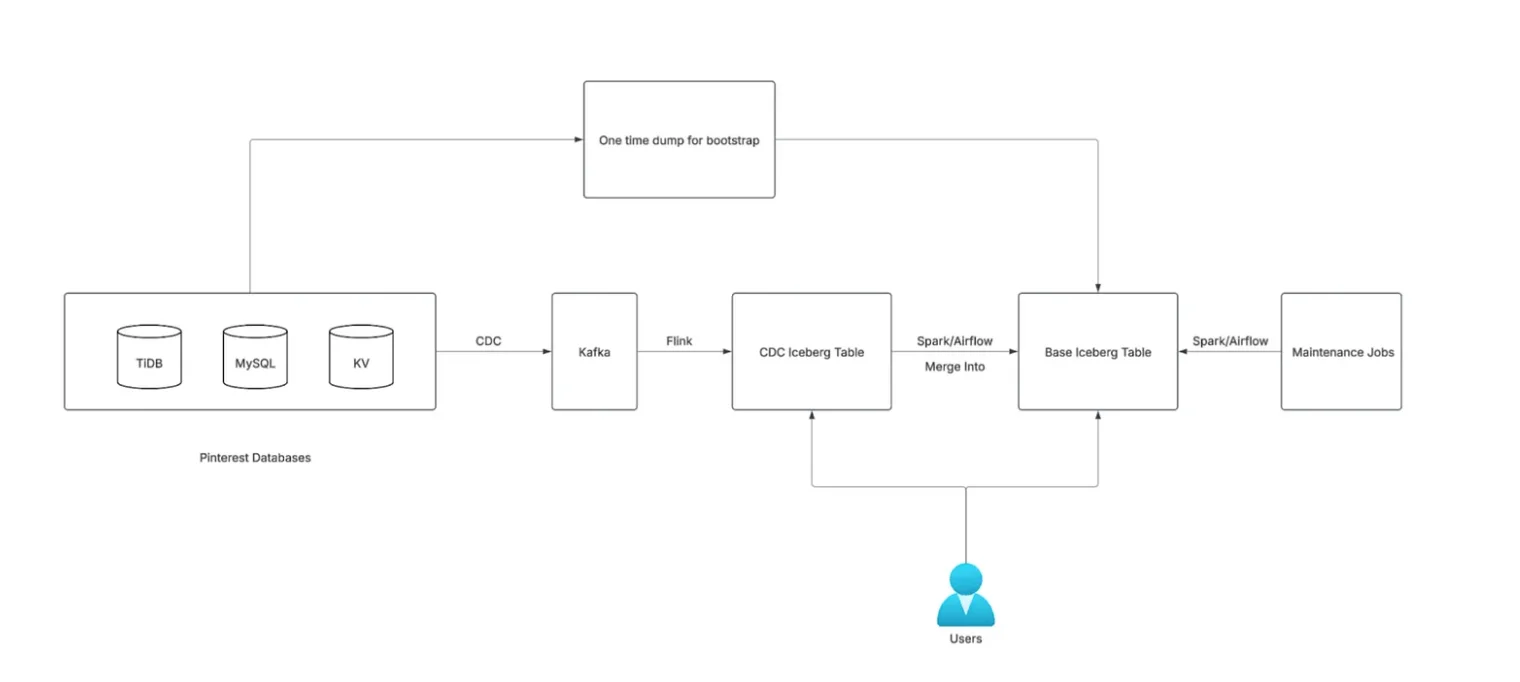
下一代数据库摄取架构概述(图片来源:Pinterest博客文章)
该架构将 CDC 表与基表分开。作为只追加账本,CDC 表记录每个变更事件的延迟通常低于五分钟。基表维护完整的历史快照,每 15 分钟至 1 小时通过 Spark Merge Into操作进行更新。Iceberg 的合并操作提供两种更新策略:写时复制(COW)和读时合并(MOR)。写时复制策略在更新时重写整个数据文件,增加存储和计算开销。读时合并策略将变更写入独立的文件并在读取时应用,从而降低写入放大效应。经过评估,Pinterest 最终采用了读时合并策略,因为在多数工作负载中,写时复制产生的存储成本远超它所带来的收益。该方案既支持增量更新,又使基础设施成本在 PB 级数据规模下仍然可控。
Spark 作业首先对 CDC 表中的最新更改去重,然后在基表上应用更新或删除。历史数据最初通过引导管道加载,后续维护作业负责处理压缩和快照过期。
该框架的优化包括:使用 Iceberg 分桶通过主键哈希对基表进行分区,允许 Spark 并行化 upsert 操作,以及减少每次操作扫描的数据量。该框架还通过指示 Spark 按分区分布写入来解决小文件问题,减少了每个任务多个小文件造成的开销。
测量结果包括将数据可用性延迟从超过 24 小时降低到低至 15 分钟,避免不必要的全表操作,仅处理每天变化的 5%的记录,降低基础设施成本。该系统可以处理 PB 级规模的数据,跨数千个管道,同时支持增量更新和删除。
Pinterest 基于 CDC 的摄取框架提供了对数据库更改的实时访问,其中,Iceberg 表存储在 AWS S3 上,Flink-Spark 处理流和批处理工作负载。未来的改进将集中在自动化模式演变上,如何安全地将上游更改传播到下游,增强大规模管道的可靠性和可维护性。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2026/02/pinterest-cdc-db-ingestion/




