
本期节选自《中国卓越技术团队访谈录》(2023年第二季)。此次我们深入采访了网易伏羲预训练及生成式人工智能平台负责人赵增博士,进一步了解文生图模型丹青的构建思路,以及网易伏羲对文生图模型未来发展的思考。
宋徽宗赵佶曾创作过一幅名为《蜡梅山禽图轴》的画作,并为该画题了一首诗:“山禽矜逸态,梅粉弄轻柔,已有丹青约,千秋指白头。”讲述的是一对白头翁立于这丹青笔墨的虚空中,没有风,没有阴影,没有俗世喧嚣、红尘侵染,一千年恩爱如初,一千年只不过黯淡些羽毛上的墨色,艺术比生命更长久。
以此诗为灵感,网易集团高级副总裁胡志鹏给网易伏羲自研文生图模型取名为“丹青”,依托于该模型之上构建的 AIGC 平台名为“丹青约”。
丹青模型基于原生中文语料数据及网易自有高质量图片数据训练,与其他文生图模型相比,丹青模型的差异化优势在于对中文的理解能力更强,对中华传统美食、成语、俗语、诗句的理解和生成更为准确。比如,丹青模型生成的图片中,鱼香肉丝没有鱼,红烧狮子头没有狮子。基于对中文场景的理解,丹青模型生成的图片更具东方美学,能生成“飞流直下三千尺”的水墨画,也能生成符合东方审美的古典美人。



近日,InfoQ 采访到了网易伏羲预训练及生成式人工智能平台负责人赵增博士,进一步了解丹青模型的构建思路。网易伏羲成立于 2017 年,主要研究方向为强化学习、自然语言、用户画像,视觉计算,虚拟人等,技术应用智能捏脸、反外挂、智能 NPC、对战匹配、竞技机器人、人机协作、数字孪生等多个方向,团队已在世界顶级学术会议发表论之 200 余篇,申请发明专利 550 余项。
文生图模型“卷”起来了
2022 年被称为 AIGC(生成式人工智能)的元年。
这一年,Stable Diffusion 正式开源,并掀起了文生图模型的热潮;这一年,ChatGPT 火遍全球,成为现象级应用。在年末 Science 杂志发布的 2022 年度科学十大突破中,AIGC 作为人工智能领域的重要突破赫然在列。
进入 2023 年,AIGC 技术助推出新的人工智能浪潮,AI 大模型的创新应用按下加速键。而其中,文生图仍是大模型最火热的应用领域之一,国内外发布的文生图模型数量不断攀升。越来越“卷”的文生图模型们,正促进模型生成效果和效率迈上新台阶。
“在过去的半年里,我深刻地感受到了 AIGC 技术的飞速发展。整体来看,去年整个行业和技术相对来说不如今年活跃。今年以来,行业和社会都开始更加关注 AIGC 的发展,AIGC 技术发展速度惊人。”
赵增在接受 InfoQ 采访时表示,AIGC 技术的飞速发展使得文生图模型不断实现更加良好的生成效果,与此同时,以 Stable Diffusion 为代表的开源项目空前活跃,很多没有强大 AI 背景的开发者也能够基于开源生态做出优秀的 AI 模型。“这对我们产生了很大的冲击,我们需要重新审视自身的工作路径,并考虑如何与有志于参与模型建设的行业伙伴建立关系。同时,我们也要考虑如何支持内部同事,尤其是那些掌握了一定 AI 生产能力的美术同事们,帮助他们更好地利用 AIGC 技术,以提升他们的工作效率和质量。”
如何构建更懂中文的文生图模型?
据了解,网易伏羲从 2018 年开始关注 AIGC 技术在产品中的应用可能性,不断尝试将其应用于实际场景。
2018 年,GPT 横空出世,其强大的生成效果令人印象深刻。在胡志鹏的推动下,网易伏羲开始尝试在游戏中使用 AIGC 技术,推出一些互动玩法。比如,在《遇见逆水寒》游戏中,网易伏羲引入了一个文字生成类的玩法——傀儡戏。
在这个玩法中,玩家可以扮演剧情角色,通过聊天的方式,与 AI 共同创作剧本,共同协作达成一些目标。这也是国内首个将 AI 接入游戏中,与玩家共同创作剧本的玩法。2019 年,网易伏羲尝试将这一设计正式大规模上线,并在训练应用、工程加速等多个方面进行直接探索。
与其他 AI 研究机构相比,网易伏羲的优势在于能够快速在产品中验证 AI 技术,根据实际应用效果不断迭代优化。赵增表示,网易有多款产品,可以通过类似“实验田”的方式验证 AI 产品在游戏或其他产品中的可行性,“这也是网易的一个良好机制,可以快速验证和实现 AI 的应用。”
2021 年,网易伏羲正式启动大规模预训练研发项目,并得到了浙江省政府的支持。根据项目规划,网易伏羲计划开发文本、图像、音乐等一系列 AI 大模型。在与网易集团多个业务的专家交流后,网易伏羲判断多模态将是未来发展趋势,决定优先专注多模态相关的工作,如文本到图像、文本到音乐、图像到音乐的理解和生成。
文生图模型丹青正是其中的主要工作之一。2022 年上半年,网易伏羲开始启动丹青模型的各项工作,该模型基于原生中文语料数据及网易自有高质量图片数据训练,100% 自研。
“生产好的内容之前,需要先理解好的内容”
在丹青模型出现以前,国内外已有多个文生图模型,随着去年 Stable Diffusion 的开源,文生图模型数量激增,很多创业公司直接基于 Stable Diffusion 模型进行适配训练和推理生成,并利用 API 的翻译接口将中文的输入转化成英文,实现对中文用户的支持。
不过,Stable Diffusion 使用的核心数据集是开放图像-文本对数据集 LAION-5B,存在一些偏西方化的特点。比如,海外数据的内容组成大多由当地的人文地理、生活历史构成,对中文语言、美食、文化、习俗缺乏理解,直接地英译中可能引起语义的缺失,由此生成的图片也容易引发争议。像淮扬名菜“红烧狮子头”,一些模型会生成狮子头的图片;河北小吃驴肉火烧,也有模型直接生成一头驴和一团火。
此外,海外数据集在合规性和安全性方面存在一定风险,比如,存在种族不平等、大量裸露、暴力等内容,直接将这些数据模型用于国内的生产,存在巨大的隐患。
“网易伏羲的观点是,生产好的内容之前,需要先理解好的内容。”赵增认为,Stable Diffusion 的确给文生图模型领域带来了一些参考和启示,但 Stable Diffusion 在很大程度上仍是“黑盒”,如果在其基础上进行修改,对模型的优化和控制力是相对有限的。做文生图模型,如果只是简单的重复并无意义,需要走出自己的一条路子。
具体来说,网易伏羲的关注点主要有三大方面:
第一,网易伏羲需要构建的是一个对中文领域以及中文的艺术知识有更深理解的生成模型,满足国内用户的使用需求。
第二,从技术的可控性、安全性和规则性出发,需要打造一个完全开放的基础模型,知道它是如何构建和运作的,以及如何对其进行优化,而不是始终等待别人开源新版本。
第三,AIGC 并不代表只是大模型,大模型只是其中的重要环节,要真正将生成的内容用于生产,还需要做很多大模型以外的工作。比如建立生产管线,将专家及 AI 能力整合起来,提供专业化解决方案。
基于这一认识,网易伏羲选择兼容开源数据的同时,又分为四步推进丹青模型的研发工作:建设高质量的大规模中文数据集;构建中文领域的优质理解模型;基于数据集和理解模型重构图文生成算法,做到语义的有效提升;引入专家和人类的反馈,引导模型生成用户更加需要的高质量内容。
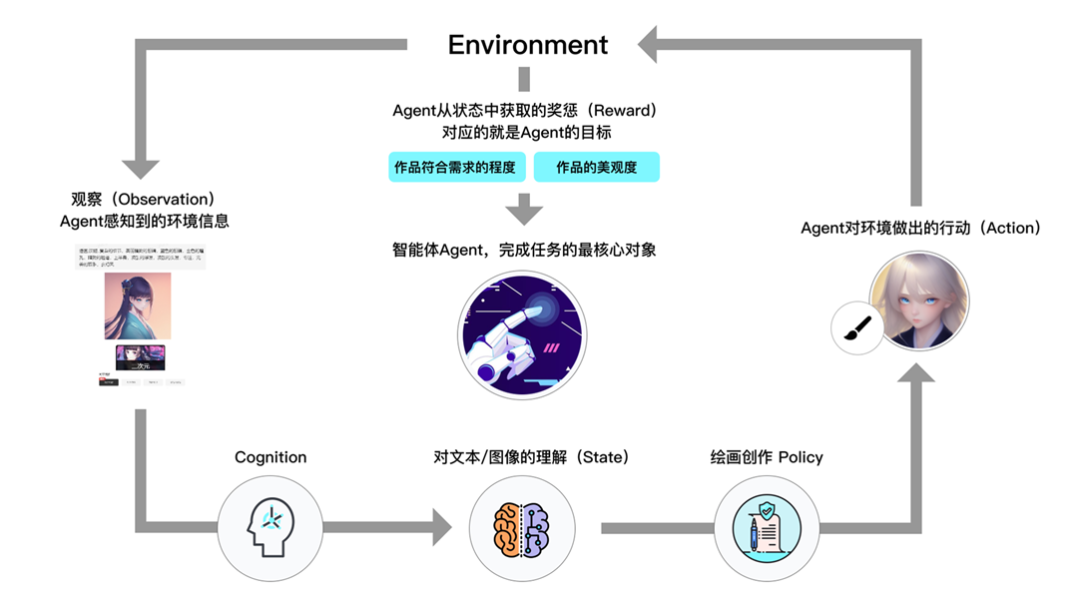
数据集方面,网易伏羲联合网易多个部门,包括网易雷火、传媒、云音乐等核心业务,从用户和业务维度提供对数据的理解和需求,完成对于优质数据的定义,建设包括文本质量、图像美观度、版权合规性以及伦理评估等评价标准。以此框架作为约束共同推进数据构建,同时设计了一套基于分布式任务的数据可信系统,各专家团队各自提供数据质量评审模型,完成共同打分后再交由数据治理引擎统一管理。
大模型方面,网易伏羲自主研发了中文文本预训练大模型系列“玉言”,“玉言”先后登顶知名中文榜单 FewCLUE 和 CLUE 分类榜单,在多项任务上超过人类水平。在文本理解的基础上,网易伏羲自 2021 年起着力打造“玉知”多模态图文理解大模型,采用图片-文本双塔结构和模块化的训练思想,基于亿级别的中文图文数据对,先后迭代了三种规格的模型版本。
基于数据集和理解模型,网易伏羲对图文生成算法进行重构,依托于扩散模型的原理,在广泛的(8 亿)图文数据上训练以达到较好的生成结果。具体来说,丹青模型侧重文本与图片的交互,强化了在文图引导部分的参数作用,能够让文本更好地引导图片的生成,因此生成的结果也更加贴近用户意图。同时,丹青模型进行了图片多尺度的训练,充分考虑图片的不同尺寸和清晰度问题,将不同尺寸和分辨率的图片进行分桶。在充分保证训练图片训练的不失真的前提下,保留尽可能多的信息,适应不同分辨率的生成。
在数据策略方面,丹青模型在初始阶段使用亿级别的广泛分布的数据,不仅在语义理解上具有广泛性,可以很好地理解一些成语、古文诗句,在生成的画风上也具有多样性,可以生成多种风格。在之后的阶段,丹青模型分别从图文关联度、图片清晰度、图片美观度等多个层面进行数据筛选,以优化生成能力,生成高质量图片。
此外,丹青模型在训练和生成阶段还引入了人工反馈。在训练阶段,人工从多个维度的评估,筛选出来大批高质量图文匹配、高美观度数据,以补足自动流程缺失能力,帮助基础模型获得更好的效果;在生成阶段,人工对模型的语义生成能力和图片美观度进行评分,筛选出大批量优质生成的结果,引入模型当做正反馈,实现数据闭环。
丹青约背后的东方美学
丹青模型是底层基础,在实际场景中进行应用需要依赖于上层平台的建设。依托于丹青模型,网易伏羲和雷火艺术中心联合研发了 AI 绘画平台“丹青约”。
在赵增看来,丹青约的优势在于对中文和美的理解,依赖于较强的中文理解能力,以及对美学的专业理解,丹青约创作出的作品更能满足中式审美。“我们会请一些美术专家对模型进行把控。目前来看,国内具备美术专家群体的 AI 机构寥寥无几,网易在这一领域具有显著优势,我们知道什么样的模型生成内容更符合大家的审美需求。”
比如,雷火艺术中心会派遣艺术家前来指导,从艺术的角度对生成图片效果、插件、版本给予专业意见。丹青约也会为艺术家提供定制化的生成工具,及时获取艺术家们的反馈意见,进一步迭代优化。
此外,丹青约还充分结合了网易游戏美术设计的工作流,无论是生成图片的美观度,还是满足高质量要求的图片生产(如原画、美术资产等),都做了深入的探索和研发,并且支持用户跨文字、图片等多模态给予多轮修改建议,直到生成满意的图片效果。


目前,网易伏羲正在推进丹青约的建设,并携手网易集团内部生态共同参与艺术风格和算法模型的设计和训练。此外,网易伏羲还积极推动将 AI 技术应用于企业美术资产的生产创作流程中。即将上线的网易伏羲有灵美术平台集成了丹青约等多种美术工具,涵盖了美术资产制作、工具管理、审核验收等生产全链路功能,大幅提升了美术创作的生产效率,为艺术家们提供了更加灵活的生产力工具。
“大模型业务不仅包括模型算法本身,还需要一个非常完善的数据计算和人工智能系统支撑。我们系统地从多个方面来建设大模型能力,以满足实际应用需求,并不断持续关注和发展大模型技术。”赵增说道。
文生图模型如何应对版权争议?
文生图作为大模型最火热的应用领域之一,近几年取得了突破性的进展,并成功在多个领域落地应用。与热度随之而来的也有争议,其中,最大争议点在于版权。
今年 1 月份,三位艺术家曾对 Stable Diffusion 背后的公司 Stability AI,AI 绘画工具 Midjourney,以及艺术家作品集平台 DeviantArt 提起诉讼,称这些组织通过在“未经原作者同意的情况下”从网络上获取的 50 亿张图像来训练其人工智能,侵犯了“数百万艺术家”的权利。
该案的代理律师 Matthew Butterick 指出,从法律的角度来看,几乎没有艺术家明确同意他们的作品用于训练 AI 系统。即使系统生成的图像作为原始图像传递,生成系统仍将基于未经授权的数据。“因为系统中的所有视觉信息都来自受版权保护的培训图像,所以产生的图像无论外观如何,必然是从这些训练图像中衍生出来的。”
版权争议是文生图模型继续向前发展必须解决的问题。赵增认为,能够真正训练好 AI 模型并使其发挥作用的并不是技术人员,而是具有行业需求和美术能力的专家。“我们需要聚集这些专家,让专家们围绕这个生态进行创作。必须考虑到专家的版权和原始利益,否则整个生态无法运转。”
在版权问题上,目前网易伏羲团队正与网易区块链团队搭建相关平台,通过区块链和 Web3.0 的模式,将大家在整个生产链路过程中的贡献记录下来。例如,有人提供了原始训练图片,有人提供模型,有人提供创意,将这些生产日志记录下来,并通过回报分配的方式尽可能给予大家相对公平的激励。“这是我们现在非常明确要做的非常重要的事情。但是这个事情比较新,我们目前还在与网易的区块链团队搭建平台,并在内部进行验证。”
写在最后
目前,丹青模型还在持续的迭代优化中,团队的短期目标是将丹青模型打造成一个更完善的产品。“我们正在努力提升大模型的效果,包括丰富其知识和提高生成的稳定性。其中,丰富知识是指对一些特定领域的理解,例如对于中国传统文化或海外知识的掌握。当我们需要生成一个中国古代建筑或榫卯结构的建筑时,我相信许多模型缺乏相关的知识。此外,我们的模型对于海外支持相对较弱,这也是需要进一步提升的地方。”赵增表示,除了将基础生成模型发展为一个更完善的产品,网易伏羲还希望构建一条更高效的生成图片的路径,以帮助美术专家进行创作。这涉及到多个模型能力的整合和闭环学习系统的建设,“这些都是我们接下来的重点努力方向”。
在技术之外,开源生态同样值得关注。“今年以来出现了很多基于开源生态的大模型,包括图文、文本等。未来基于这些开源生态,工具和模型的版本迭代一定会发生非常有趣的变化,这个可能是我们现在都想象不到的。因此,我们需要保持关注并适应这些变化。”赵增说道。
采访嘉宾
赵增,计算机博士,网易人工智能专家,预训练及生成式人工智能平台负责人、计算效能部门负责人。网易集团技术委员会机器学习分委会、音视频分委会委员。研究领域包括大规模人工智能系统、生成式预训练及基础算法优化。浙江省重点研发项目-超大规模预训练云平台主要研发人员,组织多项超大规模预训练模型研制及平台示范工作,参与申请发明专利近 30 项、高质量论文 5 篇。主导研发人工智能平台“丹炉”,日调用量超百亿次。曾参与国产芯片基础数学库优化、国产万亿高性能集群、“十四五”数字人等多个国家、省部级重点研发计划。
中国卓越技术团队访谈录(2023 年第二季)深入采访了腾讯、网易伏羲、阿里云、QQ 等技术团队,呈现了这些团队在向量数据库、大模型、前端和研效等方面的技术落地、产品演进和团队建设等方面的多年实践经验和相关心得体会。点击下载电子书,查看更多精彩内容。




