
谷歌研究人员提出了一种训练方法,通过让大语言模型学习最优贝叶斯系统的预测让其能够进行近似贝叶斯推理。该方法重点改进模型在多步交互过程中接收新信息时的信念更新方式。
该研究考察了语言模型在与用户长期交互过程中如何更新信念。在推荐系统等诸多实际应用场景中,模型需要依据新信息逐步推断用户偏好。贝叶斯推理提供了一种在获取新证据时更新概率的数学框架。研究人员探究了语言模型的行为是否符合贝叶斯信念更新规则,并探索了能够改善这一行为的训练方法。
为了进行评估,研究团队设计了一项模拟航班推荐任务。实验中,模型与模拟用户进行五轮交互。每一轮,助手和用户都会看到三个航班选项,这些包含出发时间、飞行时长、经停次数和价格。每个模拟用户对这些属性都存在隐藏偏好。每次推荐后,用户会告知助手所选选项是否正确,并揭晓偏好的航班。助手需要利用这些反馈优化后续推荐。
研究人员将多个语言模型与一个贝叶斯助手进行对比:该贝叶斯助手会在潜在的用户偏好上维护概率分布,并在每次交互后通过贝叶斯规则进行更新。实验结果显示,贝叶斯助手在正确选项选择上的准确率约为 81%;而语言模型表现较差,通常在首次交互后改进有限,这表明它们未能有效更新对用户偏好的内部估计。
研究人员随后测试了一种名为贝叶斯教学(Bayesian Teaching)的训练方法。模型不仅学习正确答案,还会模仿贝叶斯助手在模拟交互中的预测。在早期交互轮次中,由于对用户偏好存在不确定性,贝叶斯助手有时也会给出错误推荐,但其决策始终反映了基于现有证据的概率推理。
下图展示了 Gemma 与千问模型在针对贝叶斯助手或“神谕(Oracle)”用户交互进行微调后的推荐准确率。
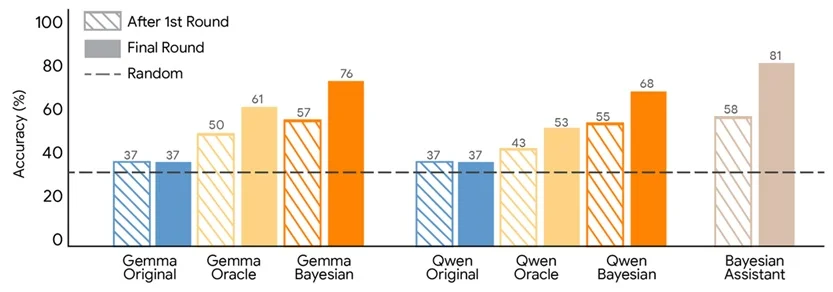
监督微调的训练数据由用户与贝叶斯助手之间的模拟对话构成。作为对照,研究人员还测试了另一种方法:让模型向一个始终能选中正确选项的助手学习,该助手拥有完整的用户偏好信息。
两种微调方法均提升了模型性能,但贝叶斯教学效果更优。采用该方法训练的模型,其预测更贴近贝叶斯助手,且在多轮交互中展现出更大的能力提升。经过训练后的模型在评估用户选择时也与贝叶斯系统具有更高的一致性。
社区对谷歌这项研究总体反馈是积极的,评论者们普遍肯定了大语言模型在概率推理与多轮自适应能力上的提升。
软件开发者Yann Kronberg评论道:
大家都在讨论推理基准,但这项工作本质上是关于信念更新。我们知道,大多数大语言模型在获取新信息后无法很好地修正内部假设,因此谷歌研究人员提出的让模型进行近似贝叶斯推理的方法对长期运行的智能体而言可能至关重要。
还有人对采用监督微调而非强化学习来进行近似贝叶斯推理的做法提出了质疑。
研究人员Aidan Li表示:
作者为何使用 SFT 而非 RL 来训练模型以近似概率推断?已有大量工作将 RL 与概率推断关联起来,甚至适用于大语言模型。或许我遗漏了某些信息,但 RL 看起来显然是更直观的选择。
研究人员将该方法归为一种模型蒸馏形式,即让神经网络学习近似一个能实现贝叶斯推断的符号系统的行为。结果表明,语言模型可以通过后训练获得概率推理能力,这种后训练使其能够在顺序交互中展现出最优决策策略。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2026/03/google-bayesian-llm/




