
一、 引言
要完成一个 BPF 二进制程序的开发,需要搭建开发编译环境,要关注目标系统的内核版本情况,需要掌握从 BPF 内核态到用户态程序的编写,以及如何加载、绑定至对应的 HOOK 点等待事件触发,最后再对输出的日志及数据进行处理。
这几个过程对于一个刚接触 BPF 的同学会感觉相当繁琐。本文先通过对 BPF 知识的介绍,带领大家入门 BPF,然后介绍 coolbpf 的远程编译(原名 LCC,LibbpfCompilerCollection, 意为酷玩 BPF,目标把复杂的 BPF 开发和编译过程简化),以一个示例来体验 coolbpf 的享受式开发。
二、 BPF 入门
BPF 最早在 1992 年被提出,当时叫伯克利包过滤器(Berkely Packet Filter,一般称为 cBPF),号称比当时最先进的数据包过滤技术快 20 倍,主要应用场景在 tcpdump、seccomp。
2014 年,Alexei Starovoitov 对 BPF 进行彻底地改造,提出 Extended Berkeley Packet Filter (eBPF)。eBPF 指令更接近硬件的 ISA,便于提升性能,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者。其使用场景不再仅仅是网络分析,可以基于 eBPF 开发性能分析、系统追踪、网络优化等多种类型的工具和平台。我们通常不加区分,把 cBPF 和 eBPF 都称之为 BPF。
2.1 BPF 知识点总结
大家都在谈 BPF,介绍 BPF 的文章也很多,这里先总结 BPF 的知识点,最后我们从最基础的 BPF 指令架构及 map 和 prog type 去介绍如何快速入门。
risc 指令集:包含 11 个 64 位寄存器 (R0 ~ R10)。
maps:BPF 程序之间或内核及用户态间数据交互。
prog type:BPF 程序类型用来确定程序功能以及程序 attach 到什么位置。
helper functions:通过辅助函数访问内核数据,如访问 task、pid 等。
jit:将 BPF 程序的字节码转换成目标机的机器码。
object pinning:提供 BPF 文件系统,延长 map 和 prog 的生命周期。
tail call:一个 BPF 程序可以调用另一个 BPF 程序,并且调用完成后不用返回到原来的程序。
hardening:保护 BPF 程序和其二进制程序不被破坏(设置成只读)。
2.2 BPF 发展概况
BPF 经过几十年的发展,已经从原来单一的功能用途,到如今遍布各个领域的应用,包括云原生、企业服务器、安全系统等都在运用这一技术,服务生产和生活。下图是 BPF 技术的发展史(图源:https://zhuanlan.zhihu.com/p/444454862)。
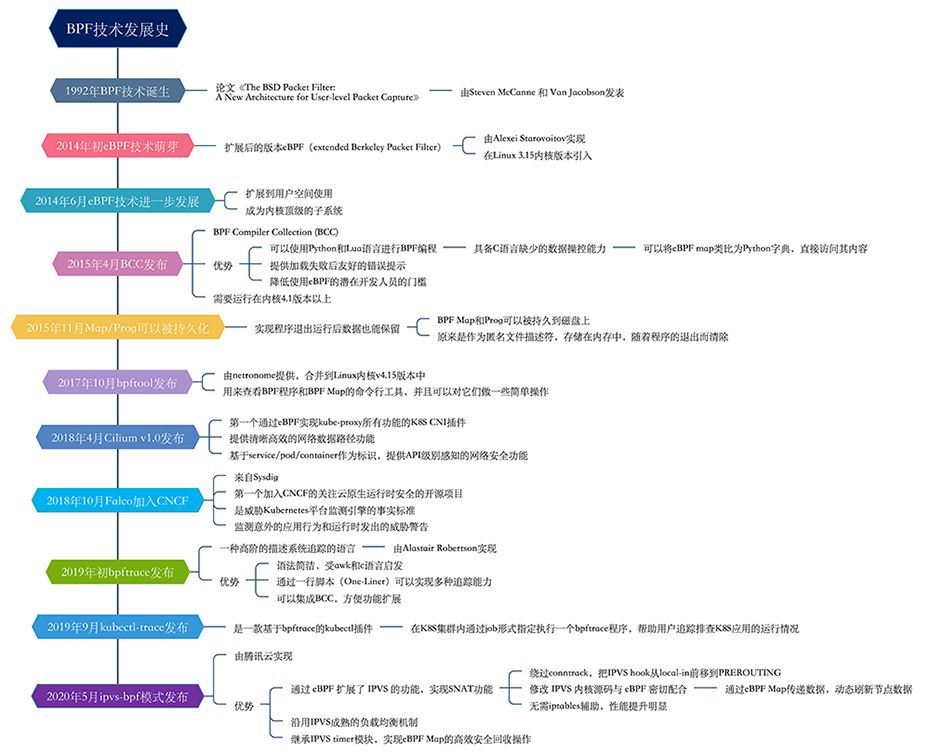
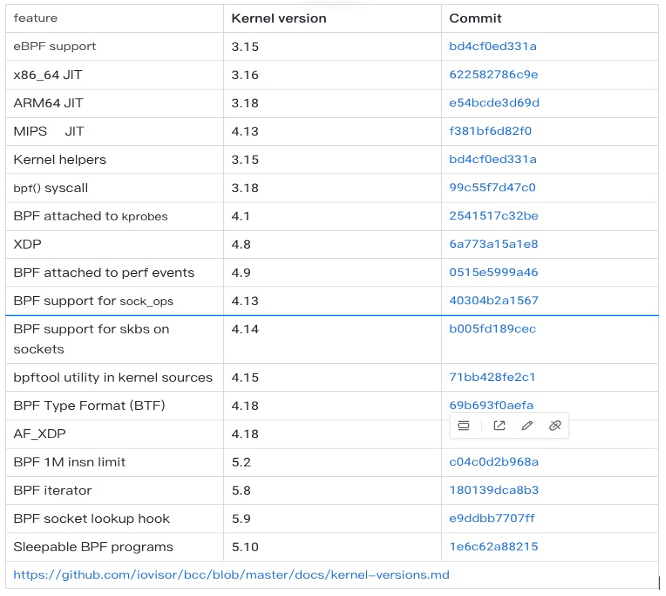
随着越来越多的特性被合入到 Linux 内核社区,BPF 支持的功能因为这些特性加持,已经越来越丰富。
2.3 BPF 和内核模块对比
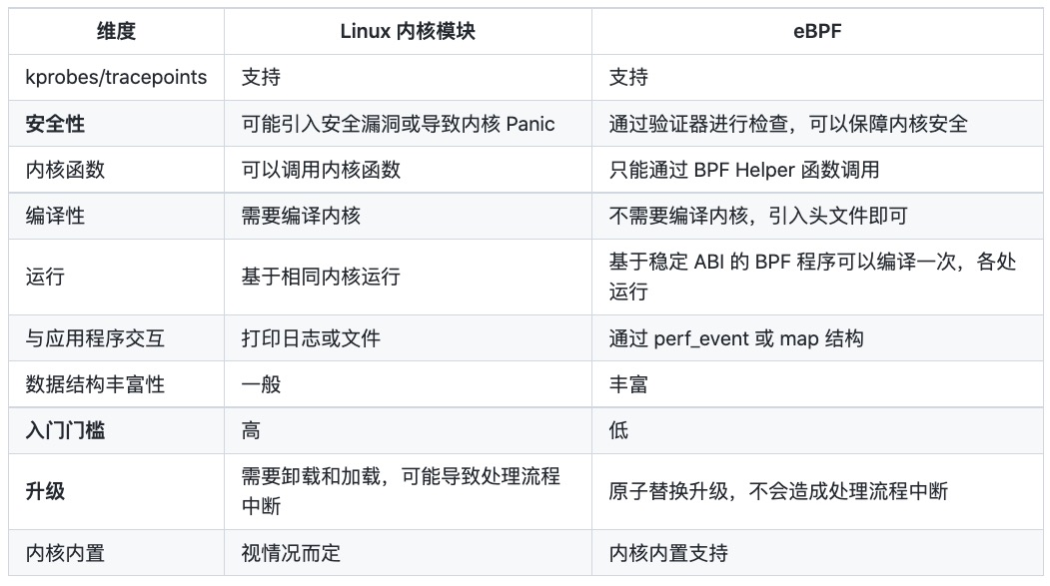
BPF 的优势是灵活、安全。在没有引入 BPF 之前,如果我们想要实现一些跟踪诊断的功能,可以使用 tracefs/debugfs 中导出的文件系统接口,或者编写内核模块插入到内核中运行。前者的功能较为固定,无法灵活地实现对数据的过滤;后者虽然灵活,但容易导致内核 crash,不够安全。ftrace 和 kernel module 给我们很大的自由去抓取内核的一些信息,但是却存在不少弊端。
下图是内核模块和 BPF 的对比(图源:https://zhuanlan.zhihu.com/p/444454862)。
2.4 BPF 指令集
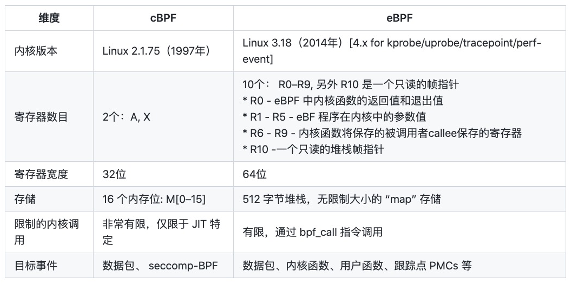
BPF(默认指 eBPF 非 cBPF) 程序指令都是 64 位,使用了 11 个 64 位寄存器,32 位称为半寄存器(subregister)和一个程序计数器(program counter),一个大小为 512 字节的 BPF 栈。所有的 BPF 指令都有着相同的编码方式。eBPF 虚拟指令系统属于 RISC,拥有 11 个虚拟寄存器、r0-r10,在实际运行时,虚拟机会把这 11 个寄存器一 一对应于硬件 CPU 的物理寄存器。下图是新老指令的对比:
BPF 指令的核心结构体如下,每一条 eBPF 指令都以一个 bpf_insn 来表示,在 cBPF 中是其他的一个结构体(struct sock_filter ),不过最终都会转换成统一的格式,这里我们只研究 eBPF:
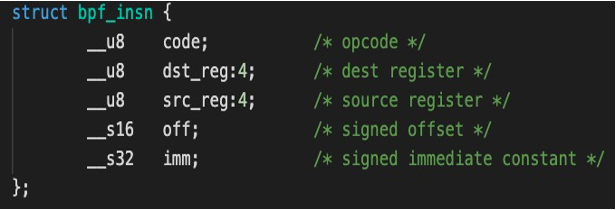
由结构体中的__u8 code 可以知道,一条 BPF 指令是 8 个字节长。这 8 位的 code,第 0、1、2 位表示的是该操作指令的类别,共 8 种:
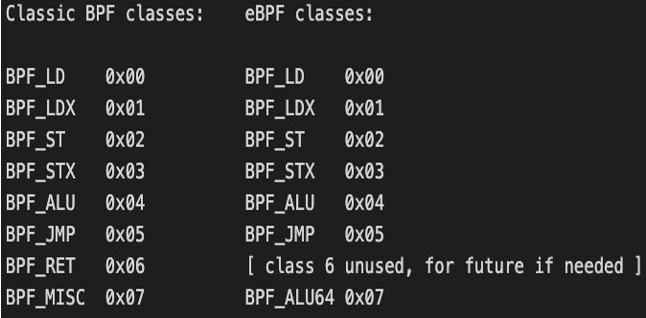
从最低位到最高位分别是:
8 位的 opcode;有 BPF_X 类型的基于寄存器的指令,也有 BPF_K 类型的基于立即数的指令。
4 位的目标寄存器 (dst)。
4 位的原始寄存器 (src)。
16 位的偏移(有符号),是相对于栈、映射值(map values)、数据包(packet data)等的相对偏移量。
32 位的立即数 (imm)(有符号)
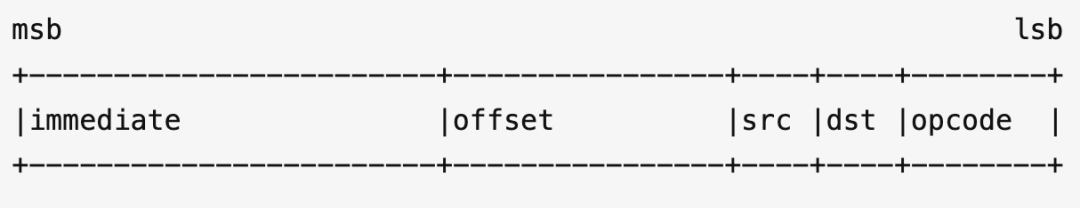
8 bit 的 opcode 进一步拆开,下图表示的是存储和加载类指令:
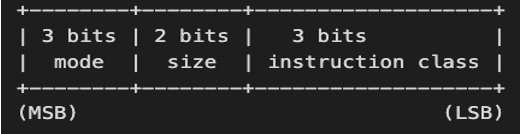
下图表示的是运算和跳转指令:
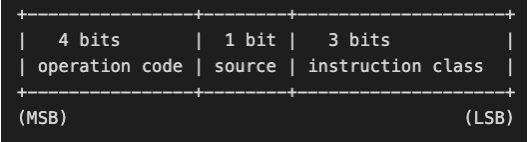
总之,BPF 指令很简洁,我们未必会在开发过程中使用它来进行代码编写(类似于纯汇编,会让人崩溃),了解这些是有助于我们更深刻的理解 BPF 的运行原理。
2.5 BPF 的 prog type 和 map
PROG TYPE
BPF 相关的程序,首先需要设置为相对应的的程序类型,截止 Linux 内核 5.8 程序类型定义有 29 个,而且还在持续增加中,BPF 程序类型(prog_type)决定了程序可以调用的内核辅助函数的子集,也决定了程序输入上下文 -- bpf_context 结构的格式。
我们经常使用 BPF 程序类型主要涉及以下两类:
跟踪
大部 BPF 程序都是这一类,主要通过 kprobe、tracepoint(rawtracepoint)等追踪系统行为及获取系统硬件信息。也可以访问特定程序的内存区域,从运行进程中提取执行跟踪信息。
网络
这类 BPF 程序用于检测和控制系统的网络流量。可以对网络接口数据包进行过滤,甚至可以完全拒绝数据包。
用户态是通过系统调用来加载 BPF 程序到内核的,在加载程序时,需要传递的参数中有一个字段叫 prog_type,这个就是 BPF 的程序类型,跟踪相关的是:BPF_PROG_TYPE_KPROBE 和 BPF_PROG_TYPE_TRACEPOINT,网络相关是:BPF_PROG_TYPE_SK_SKB、BPF_PROG_TYPE_SOCK_OPS 等。下面是描述 BPF 程序类型的枚举结构:
enum bpf_prog_type { BPF_PROG_TYPE_UNSPEC, /* Reserve 0 as invalid program type */ BPF_PROG_TYPE_SOCKET_FILTER, BPF_PROG_TYPE_KPROBE, BPF_PROG_TYPE_SCHED_CLS, BPF_PROG_TYPE_SCHED_ACT, BPF_PROG_TYPE_TRACEPOINT, BPF_PROG_TYPE_XDP, BPF_PROG_TYPE_PERF_EVENT, BPF_PROG_TYPE_CGROUP_SKB, BPF_PROG_TYPE_CGROUP_SOCK, BPF_PROG_TYPE_LWT_IN, BPF_PROG_TYPE_LWT_OUT, BPF_PROG_TYPE_LWT_XMIT, BPF_PROG_TYPE_SOCK_OPS, BPF_PROG_TYPE_SK_SKB, BPF_PROG_TYPE_CGROUP_DEVICE, BPF_PROG_TYPE_SK_MSG, BPF_PROG_TYPE_RAW_TRACEPOINT, BPF_PROG_TYPE_CGROUP_SOCK_ADDR, BPF_PROG_TYPE_LWT_SEG6LOCAL, BPF_PROG_TYPE_LIRC_MODE2, BPF_PROG_TYPE_SK_REUSEPORT, BPF_PROG_TYPE_FLOW_DISSECTOR, /* See /usr/include/linux/bpf.h for the full list. */};BPF MAP
BPF 的 map 可用于内核 BPF 程序和用户应用程序之间实现双向的数据交换, 是重要基础数据结构,它可以通过声明 struct bpf_map_def 结构完成创建。
关于 BPF 最吸引人的一个方面,就是运行在内核上的程序可以在运行时使用消息传递相互通信,而 BPF Map 就是用户空间和内核空间之间的数据交换、信息传递的桥梁。
BPF Map 本质上是以键/值方式存储在内核中的数据结构。在内核空间的程序创建 BPF Map 并返回对应的文件描述符,在用户空间运行的程序就可以通过这个文件描述符来访问并操作 BPF Map。
根据申请内存方式的不同,BPF Map 有很多种类型,常用的类型是 BPF_MAP_TYPE_HASH 和 BPF_MAP_TYPE_ARRAY,它们背后的内存管理方式跟我们熟悉的哈希表和数组基本一致。随着多 CPU 架构的成熟发展,BPF Map 也引入了 per-cpu 类型,如 BPF_MAP_TYPE_PERCPU_HASH、BPF_MAP_TYPE_PERCPU_ARRAY 等,每个 CPU 都会存储并看到它自己的 Map 数据,从属于不同 CPU 之间的数据是互相隔离的。
下面是描述 BPF map 的枚举结构:
enum bpf_map_type { BPF_MAP_TYPE_UNSPEC, BPF_MAP_TYPE_HASH, BPF_MAP_TYPE_ARRAY, BPF_MAP_TYPE_PROG_ARRAY, BPF_MAP_TYPE_PERF_EVENT_ARRAY, BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_STACK_TRACE, BPF_MAP_TYPE_CGROUP_ARRAY, BPF_MAP_TYPE_LRU_HASH, BPF_MAP_TYPE_LRU_PERCPU_HASH, BPF_MAP_TYPE_LPM_TRIE, BPF_MAP_TYPE_ARRAY_OF_MAPS, BPF_MAP_TYPE_HASH_OF_MAPS, BPF_MAP_TYPE_DEVMAP, BPF_MAP_TYPE_SOCKMAP, BPF_MAP_TYPE_CPUMAP, BPF_MAP_TYPE_XSKMAP, BPF_MAP_TYPE_SOCKHASH, BPF_MAP_TYPE_CGROUP_STORAGE, BPF_MAP_TYPE_REUSEPORT_SOCKARRAY, BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE, BPF_MAP_TYPE_QUEUE, BPF_MAP_TYPE_STACK, BPF_MAP_TYPE_SK_STORAGE, BPF_MAP_TYPE_DEVMAP_HASH, BPF_MAP_TYPE_STRUCT_OPS, BPF_MAP_TYPE_RINGBUF, BPF_MAP_TYPE_INODE_STORAGE, BPF_MAP_TYPE_TASK_STORAGE, BPF_MAP_TYPE_BLOOM_FILTER,};三、BPF 的开发姿势
3.1 BPF 开发框架图片
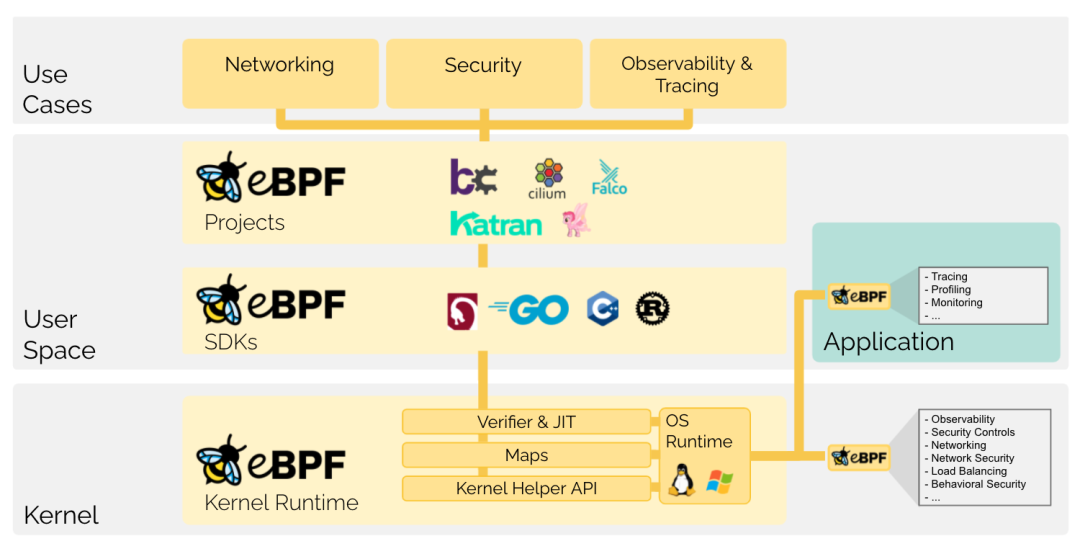
上图就是非常经典的 BPF 开发框架图了,一般开发流程都是先将用户编写的特定程序通过 LLVM 编译为 BPF 字节码,在注入到内核中时会经过 verifier 严格的检查,确保代码不会出现死循环、宕机之类的问题,然后再通过 jit 将其翻译为 native code 进行执行,用户可以通过查看内核透出的数据,了解系统的运行情况。
虽然 BPF 有非常多的应用,但使用的时候也有许多的限制。比如:
不能有不确定的循环操作;内核要确保执行流一定可以从 BPF 程序中出来。
不允许睡眠;睡眠可能导致内核执行流一直出不来。
不允许修改内核数据结构;一般不能修改数据报文。
栈空间有限;当前只有 512 字节。
不允许被直接调用内核函数;必须通过辅助函数。
3.2 开源工具和平台
BPF 的编程分为两部分,一部分是运行在内核态,这是 BPF 编程的核心;另一部分是运行在用户态,这部分代码主要用来加载 BPF,采集并处理数据等。
libbpf
libbpf 是官方的用户态库。和编译普通的 c 程序会得到一个.o 文件一样,LLVM 编译完 BPF 程序也会得到一个的.o 文件(一般我们命名为 xx.bpf.o)。这个 bpf.o 文件按照 elf 的格式组织 BPF 程序的字节码、map 定义以及符号等信息,libbpf 库负责解析这些信息,创建 map,注入 BPF 程序到内核工作。因此,对于用户来说,需要做很多繁琐的工作:
用 C 语言来编写 BPF 程序;
编写 makefile,调用 LLVM 编译生成 .o 文件;
调用 libbpf 的接口加载 .o 文件;
使用 libbpf 的接口获取 map 中的数据。
BCC
BCC 是如今最热门也是对新手最友好的开源平台。它用 python 封装了编译、加载和读取数据的过程,提供了很多非常好用的 API。
和 libbpf 需要提前把 bpf 程序编译成 bpf.o 不同,BCC 是在运行时才调用 LLVM 进行编译的,所以要求用户环境上有 llvm 和 kernel-devel。这个就会像后面我们提到的,它会出现运行时偏移导致的瞬时资源冲高问题。
bpftrace
bpftrace 是单命令工具,让用户像使用脚本一样使用 BPF。它自定义了自己的 DSL 作为前端,底层也是调用 LLVM 的。事实上,它依赖于 BCC 提供的 libbcc.so 文件。
3.3 libbpf CORE
前面提到 libbpf 开发,成为当前最主流的开发方式,但是需要为每个内核版本都开发特定的二进制程序,不能达到同一个 BPF 程序在不同内核版本上安全运行。由于不同内核版本数据的内存布局不同,就需要支持 CORE(CompileOnce、Runeverywhere),提到 CORE 我们要先来了解一下 BTF。
BTF(BPF Type Format)是一种类似于 DWARF 的格式,专用于描述程序中数据类型。其主要存在于两个地方:
一是 vmlinux 镜像内。二是用户编写的 BPF 程序内。
二者存在着一定的差异。第一个差异是:BPF 程序内除了存在 .btf 段外,还存在.btf.ext 段,专用于记录 BPF 程序内使用的数据类型的情况。第二个差异是:vmlinux 镜像内的 BTF 程序由原存在于该镜像内的 dwarf 信息简化而来,而 BPF 程序内的 BTF 段由 CLANG 编译器生成,需要在编译时指定 --target bpf。利用 BPF 程序里的 BTF 段和存放在每个系统上的 BTF 文件,我们将这些信息进行重定位,就能确定每个数据结构的偏移,达到 CORE 的目的。
关键组件:
BTF: 描述内核镜像,获取内核及 BPF 程序类型和代码的关键信息(http://pylcc.openanolis.cn/)。
Clang 释放 bpf 程序重定位信息到 .btf 段。
Libbpf CO-RE 根据 .btf 段重定位 bpf 程序。
目前在 libbpf CO-RE 中需要进行重定位的信息主要有三类:
1)结构体相关重定位,这部分和 BTF 息息相关;
Clang 通过 __builtin_preserve_access_index() 记录成员偏移量
u64 inode = task->mm->exe_file->f_inode->i_ino;u64 inode = BPF_CORE_READ(task, mm, exe_file, f_inode, i_ino);2)map fd、全局变量、extern 等重定位,这部分主要依赖于 ELF 重定位机制。通过查找 ELF 重定位段收集重定位信息,更新相应指令的 imm 字段。
skel->rodata->my_cfg.feature_enabled = true;skel->rodata->my_cfg.pid_to_filter = 123;extern u32 LINUX_KERNEL_VERSION __kconfig;extern u32 CONFIG_HZ __kconfig;3)子函数重定位,也是依赖于 ELF 重定位机制。但是目的不一样,子函数重定位是为了将 eBPF 程序调用的子函数同主函数放在同一块连续的内存中,便于一起加载到内核。例如将所有子程序拷贝到主程序所在区域, always_inline 函数。
libbpf CORE 开发步骤:
1)生成带所有内核类型的头文件 vmlinux.h
bpftoolbtf dump file vmlinux format c > vmlinux.h2)使用 Clang (版本 10 或更新版本)将 BPF 程序的源代码编译为 .o 对象文件;
3)从编译好的 BPF 对象文件中生成 BPF skeleton 头文件 bpftool gen 命令生成;
4)在用户空间代码中包含生成的 BPF skeleton 头文件;
5)编译用户空间代码,这样会嵌入 BPF 对象代码,后续就不用发布单独的文件。
6)生成的 BPF skeleton 使用如下步骤加载、绑定、销毁:
四、 coolbpf 享受式开发
前面我们已经对 BPF 有了一个认识,到此已经入门了,同时也学习了 BPF 的高阶知识:libbpf 的 CORE,它也是未来的一个方向,但是我们也看到这里面,还需要写一堆代码:open、load、attach 等等。我们能否把这一切进行简化呢?能不能享受式的进行开发。别急,先来看看常用的开发方式:
4.1 BPF 开发常用方案对比
1)原生 libbpf,无 CO-RE (内核 samples/bpf 示例)
优势:资源占用量低
缺点:
需要搭建代码工程、开发效率低;
不同内核版本兼容性差;
2)BCC(BPF Compile Collection、python 代码)
优势:开发效率高,可移植性好,支持动态修改内核部分代码
缺点:
部署依赖的 Clang/LLVM;
每次运行都要执行 Clang/LLVM 编译,争抢内存 CPU 内存等资源;
依赖目标环境头文件;
3)BPF CO-RE(libbpf-tools 下面的代码)
优势:不依赖在环境中部署 Clang/LLVM,资源占用少
缺点:
仍需要搭建编译编译工程;
部分代码相对固定,无法动态配置;
用户态开发支持信息较少,缺乏高级语言对接;
综上所述,上述方案不能很好适配生产环境中,多内核并存、快速批量部署等需求
4.2 Coolbpf(可以酷玩的 BPF)解决的问题
通过将 BPF 的三种开发方式对比,我们发现都不能完美的在生产环境中解决如下几个问题:
安装依赖库和内核头文件;
CPU 和内存等资源瞬时冲高;
BTF 需要按版本随 BPF 二进制程序发布。
为解决这几个问题,我们提出一个 coolbpf 的开发编译平台,目前包含 pylcc、rlcc、golcc 等目录,分别是高级语言 python、rust 和 go 语言支持远程和本地编译的能力。
代码链接地址:
https://gitee.com/anolis/coolbpf
https://github.com/aliyun/coolbpf
这里不对 coolbpf 过多介绍,具体内容请参考《龙蜥社区开源 coolbpf,BPF 程序开发效率提升百倍》。
4.3 pyLCC 的享受式
为了介绍什么叫享受式开发,在这里我们拿 coolbpf 的 pyLCC 进行演示:
import sysfrom pylcc.lbcBase import ClbcBase, CexecCmd //import pylcc base库bpfProg = r"""struct data_t { int cpu; int type; // 0: irq, 1:sirq u32 stack_id; u64 delayed;};LBC_PERF_OUTPUT(e_out, struct data_t, 128); //定义perf event output array mapLBC_STACK(call_stack, 256); //定义stack 的mapSEC("kprobe/check_timer_delay")int j_check_timer_delay(struct pt_regs *ctx){ struct data_t data = {}; data.cpu = PT_REGS_PARM2(ctx); data.type = PT_REGS_PARM1(ctx); data.delayed = PT_REGS_PARM3(ctx); data.stack_id = bpf_get_stackid(ctx, &call_stack, KERN_STACKID_FLAGS); bpf_perf_event_output(ctx, &e_out, BPF_F_CURRENT_CPU, &data, sizeof(data)); return 0;}"""class Crunlatency(ClbcBase): def __init__(self, lat=10): self._exec = CexecCmd self.setupKo(lat >> 1) //只需要简单的init,就可以把open load attach 等动作做好,然后专注于数据处理 super(Crunlatency, self).__init__("runlatency", bpf_str=bpfProg) def _cb(self, cpu, data, size): stacks = self.maps['call_stack'].getStacks(e.stack_id) print("call trace:") //call back函数里专心处理数据 for s in stacks: print(s)大家看到上面的示例,只需要以下三步,就可以完成一个程序的开发:
1)pip install coolbpf。
2)编写 bpf.c 代码。
3)编写 python,通过 init() 加载之后,就专注功能开发。
你可以不用关心 BPF 的汇编、字节码,也不用安装 Clang,不用安装 kernel-dev 头文件,不用自己生成 BTF 文件(它会自动到远程服务器下载),只需专注你的功能开发,比如分析网络流量、监控文件打开和关闭、跟踪系统调用。
总结来看,BPF 技术还在如火如荼的发展着,但只要掌握了这些基础的知识点,就能够触类旁通,利用好已有的工具或平台,更加能如虎添翼。通过前面的介绍,我们不仅对 BPF 有了比较深刻的理解,还能借助 coolbpf,非常酷的玩了一把享受式的开发,简洁如此,谁能不爱呢?




