
Instacart重新设计了其搜索基础设施,用 PostgreSQL 替换了 Elasticsearch,将基于关键词的检索和基于嵌入的检索整合到了一个系统中。通过将目录和搜索数据整合到 Postgres 中,该公司旨在简化操作,减少数据同步开销,并提高搜索结果的精确度和召回率。
重新设计的一个关键部分是改进检索结果的方式。传统的关键词搜索擅长匹配确切的产品属性,例如,像“pesto pasta sauce 8oz”这样的查询就受益于精确的词汇匹配。但是,更宽泛的意图驱动查询,如“健康食品”,通过语义检索来处理会更好,因为后者理解术语和概念之间的关系。通过在 Postgres 中结合这两种方法,Instacart 可以在精确度(只返回相关结果)和召回率(尽可能多地捕获相关项)之间取得平衡,确保客户既能看到他们正在寻找的确切产品,也能发现其他有意义的选项。
根据 Instacart 工程团队的说法,迁移提高了开发速度,消除了在系统之间协调数据的需要。混合基础设施还提供了更大的灵活性,方便处理动态库存和复杂的用户偏好,使平台每天能够处理数百万的搜索请求。价格、库存和折扣信息都可以实时更新,为顾客提供了更高效、更个性化的购物体验。
正如 Instacart 工程师Ankit Mittal所说:
与之前在 Elasticsearch 中使用的非规范化数据模型相比,规范化数据模型使我们的写入工作负载减少了 10 倍。这带来了将近 80%的存储和索引成本节省,减少了死胡同搜索,并改善了整体客户体验。
以前,Elasticsearch 处理全文查询,而事务性数据存储在 Postgres 中。维护两个独立的数据库会面临同步数据的挑战和更高的运营成本。为了增加语义搜索能力,团队最初实施了FAISS,然后过渡到使用 Postgres pgvector扩展的混合模型。这种方法允许基于词汇和基于嵌入的检索在同一个系统中运行,减少了数据重复和复杂性。
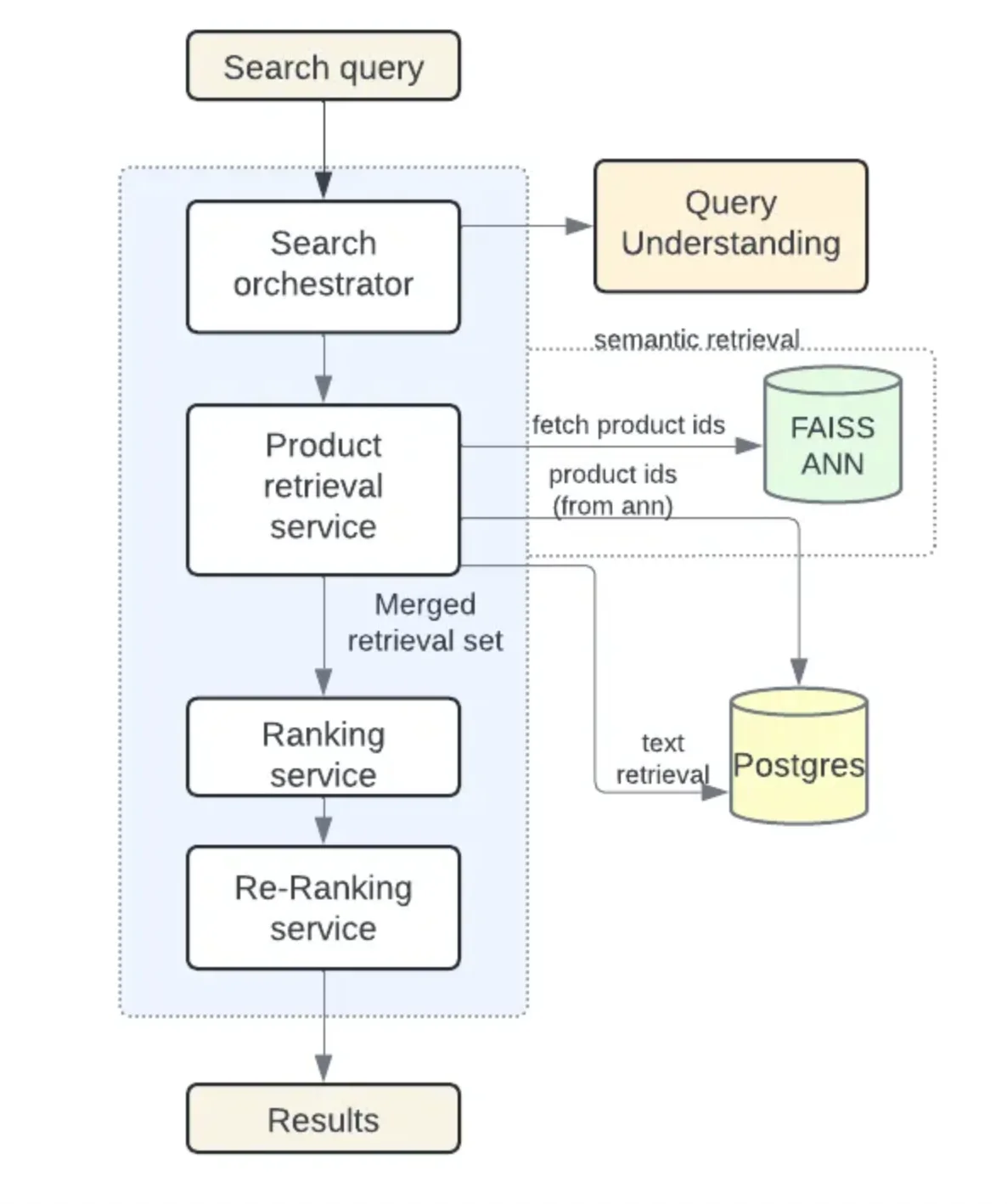
之前使用 FAISS 和 Postgres 的检索架构(来源:Instacart工程博客)
经过重新设计的架构使用分片的 Postgres 实例和规范化的数据模型来实现水平扩展。每个分片都包含目录和搜索索引,查询通过服务层路由到适当的分片。根据 Instacart 工程师的说法,他们利用 Postgres GIN索引和经过修改的ts_rank函数实现了高性能的文本匹配,而关系模型允许 ML 功能和模型系数存储在单独的表中。与 Elasticsearch 相比,规范化使写入工作负载减少了十倍,降低了存储和索引成本。与此同时,它还支持数百千兆字节的 ML 特征数据,可实现更高级的检索模型。
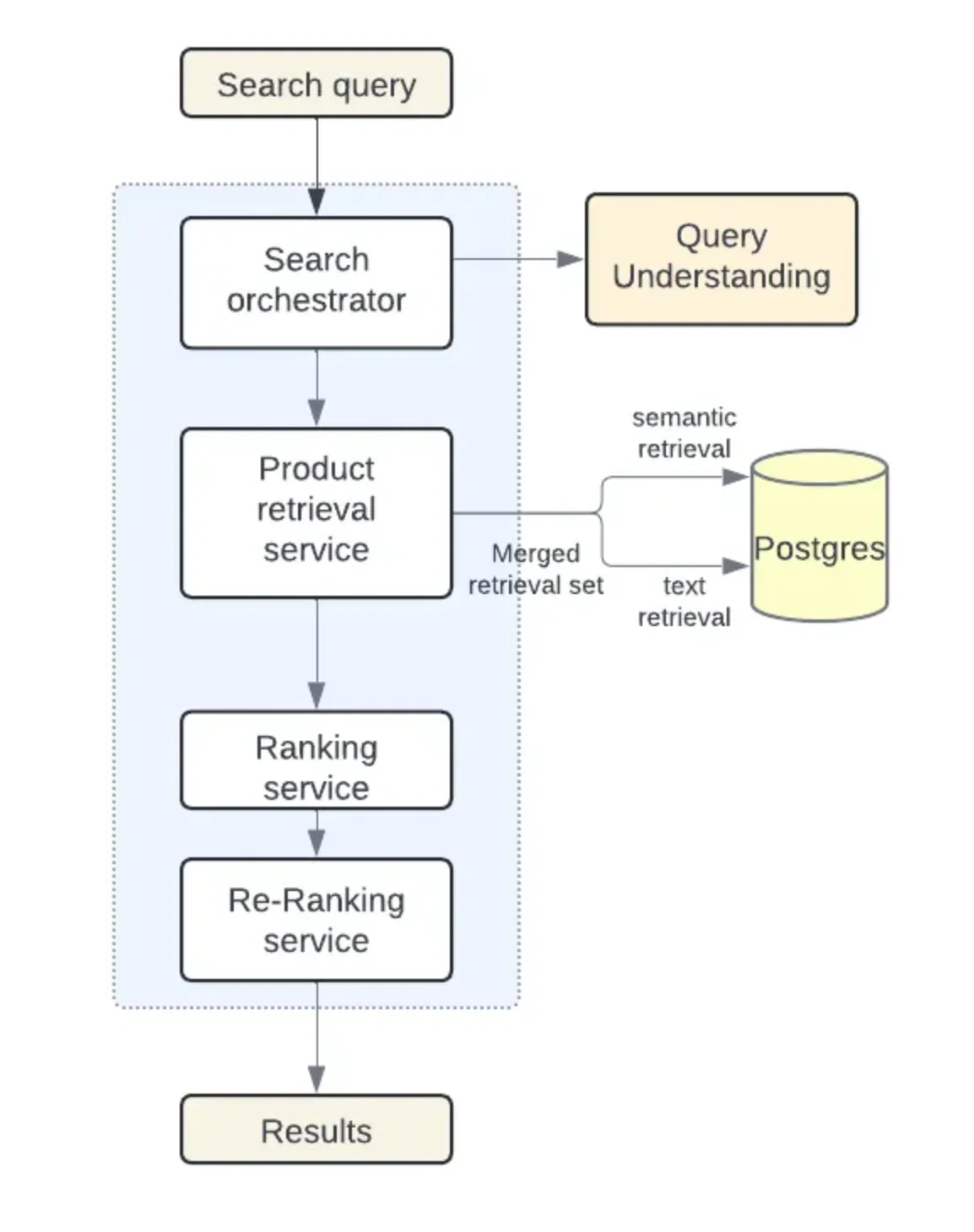
使用 pgvector 和 Postgres 的混合检索架构(来源:Instacart工程博客)
Postgres 扩展是重新设计的核心。例如,将pg_trgm用于基于三元组的文本搜索,将pgvector用于基于嵌入的搜索,从而使数据库既能处理传统的关键词搜索,又能处理语义搜索。查询通过路由层传递到包含必要索引的分片,因为无需跨系统同步,所以能高效地返回结果。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:
https://www.infoq.com/news/2025/08/instacart-elasticsearch-postgres/




