
在搞数字化转型?
别搞虚的,先整个“湖”吧 。
信息爆炸的时代,每个行业每天都在产生数以亿计的数据,海量数据的获取、整合及分析挖掘,展现出巨大的商业价值潜力。如何让数据产生价值?首先企业需要将各类业务系统产生的数据进行汇总,其次组合不同维度从中提取有价值的信息,然后再结合业务信息,选择合适的数据分析角度去辅助决策,产生业务价值,而业务价值带来的业务增长又会产生新的数据, 因此数据产生价值是一个不断转化的闭环过程。
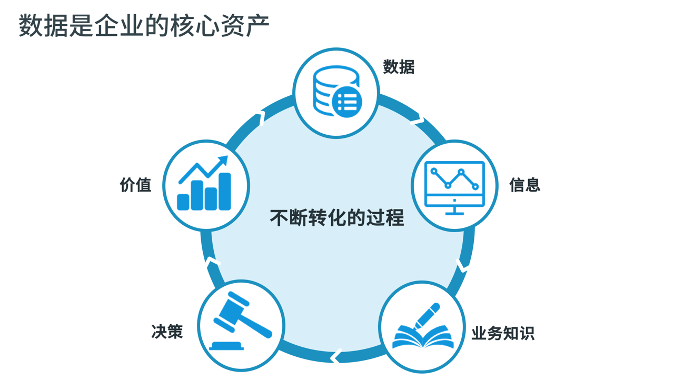
实现数据价值闭环的第一步:给数据“安家”
要想实现数据价值闭环, 第一步需要给数据找个家--建立企业数据平台。
早在 1990 年 Bill Inmon 提出数据仓库(Data Warehouse)概念和建设方法论,目的是构建面向分析的集成化数据环境,为企业提供决策支持。数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。 在数仓理论发展至今的 30 年间,越来越多企业会选用数据仓库架构作为数据平台建设的标准和核心, 分层构建多维数据模型和业务模型层。下游通过 ETL 工具对接各类数据源进行数据整合,上游数据应用进行数据消费提供分析决策。
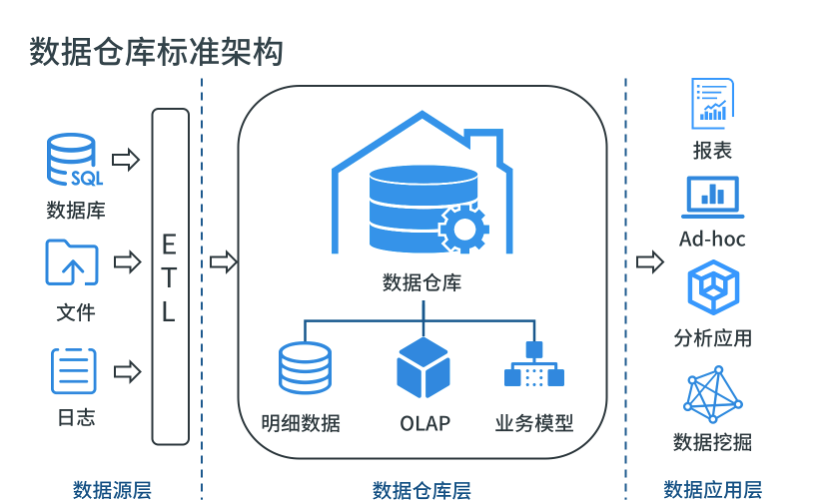
随着业务的不断发展,企业应用产生的数据量和种类不断增加,例如零售行业中常见的包括 POS 交易数据、ERP 数据、网站或小程序的数据,店面中物联网传感器收集来的相关数据,会员管理数据,以及自身内部系统数据等等,而 传统数据平台面对指数级增长的各类结构化、非结构化数据存储,以及机器学习等高级分析应用时,将会面临其功能和扩展性无法满足存储整合和分析的需求。 这时当企业想迁移至大数据平台时,又会发现各种数据库或是数仓语法各异、生态封闭导致迁移成本巨大,也有可能花了大力气迁移后因选型不当很有可能再次被厂商“绑架”,扩容成本高且无法灵活扩展。
另外,使用数据仓库进行分析有两个局限:一是只可以回答预先设定的问题,二是数据已经被筛选包装好,无法看见其最初状态。
随着企业业务场景不断拓展,在 数据分析应用方面呈现“五大转变”:
从统计分析向预测分析转变
从单领域分析向跨领域转变
从被动分析向主动分析转变
从非实时向实时分析转变
从结构化数据向多元化转变
数据分析若想真正产生价值服务于业务,业务对于数据平台的运算能力、核心算法、分析工具灵活支持及数据全面性提出了更高的要求,因此数据平台需要通过新的技术进行创新和升级,以满足业务日益增长的功能和性能需求。
数据湖(Data lake)这一技术概念在 2015 年就由 Pentaho 公司的创始人兼首席技术官詹姆斯·狄克逊(James Dixon)提出,它是一种将数据以原始格式存储在同一个系统或存储库的理念,以便于收集多个数据源的数据以及各种数据结构的数据(通常是 blob 对象或文件)。数据湖依托于无限扩展的低成本分布式存储或云对象存储,创建了一个适用于所有格式数据的集中式数据存储,可以存储包括关系数据库的数据(行和列),半结构化数据(CSV,日志,XML,JSON),非结构化数据(电子邮件,文档,PDF)甚至二进制数据(图像,音频,视频),将企业中的所有数据(从原始数据开始保存,这意味着源系统数据的精确副本)保存于同一个存储介质中,以用于各种分析用途(包括报告,可视化,分析和机器学习)。
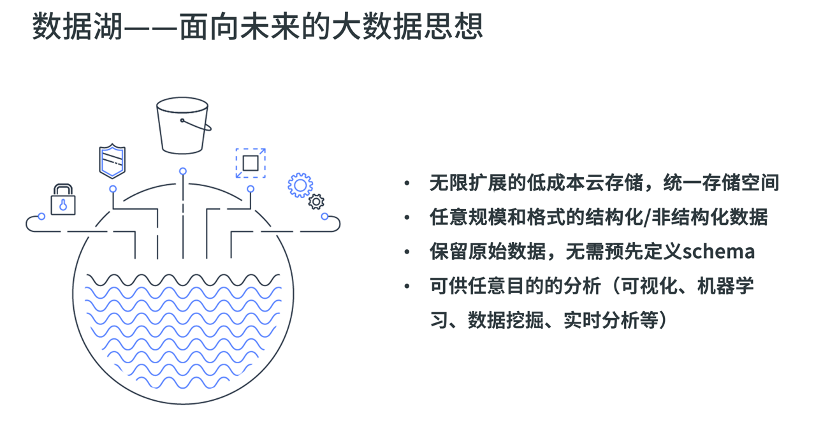
以数据湖架构建立数据分析平台能给企业带来无限的想象空间,较低的 TCO 成本可以帮助企业实现各种原始数据的集中式管理,提供统一口径和灵活的分析能力,支撑报表、BI 可视化等场景。
在此之上,结合先进的数据科学与机器学习技术,帮助企业优化运营模型,也能为企业提供其他能力,如价值挖掘、预测分析、推荐模型等,这些模型能帮助企业做出更多灵活的商业决策,促进企业业务的增长 。
随着数据湖概念的不断成熟和落地,越来越多的人也将其与数据仓库作比较,下表是关于数据仓库与数据湖的简单对比:
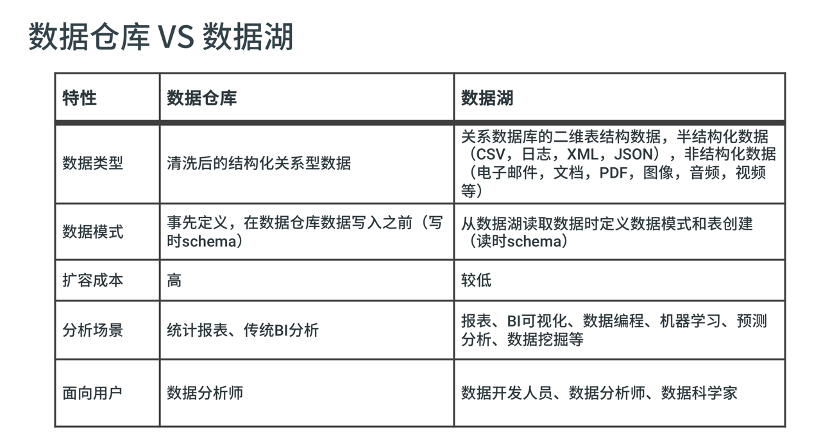
数据湖与数据仓库的差别很明显,这两者企业中两者的作用是互补的,两者的作用和应用场景不尽相同。
综上,要想建立一个适应企业未来 N 年发展的数据平台,又能支撑海量数据存储及各种分析,同时满足高并发和高性能要求,可以保证在初期有限投入的情况下兼顾灵活扩展性,并且优化运维管理,降低 TCO。 在这种需求下,数据湖就是能够承载当今企业快速发展下的数据之“家”,结合经典的数仓建模方法论,升级企业大数据平台,支撑更大数据量级和更多分析场景,满足日益增长的功能和性能需求。
实现数据价值闭环的第二步:分析平台的建设
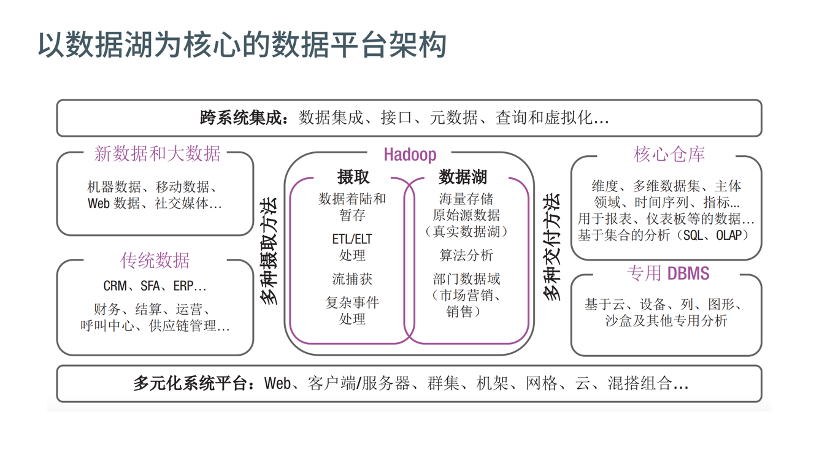
如果企业希望搭建自己的数据湖,不仅仅需要考量选择成本经济、灵活扩展的存储方案,还需要识别数据湖中的“黄金数据”并发挥价值。如果数据湖只是一味往里面灌入数据,而无实际的应用场景,没有输出或者极少输出,只会形成单向的数据沼泽,不但要为海量数据支付不菲的存储费用,还无法从中产生业务价值,无法得到令人满意的 ROI。
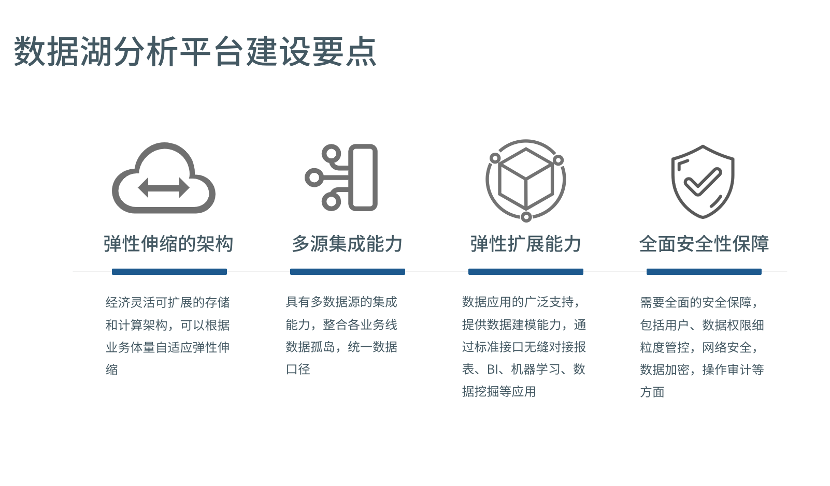
因此, 数据湖不仅需要各渠道数据的输入,还需要各种应用场景分析的输出。 数据湖分析平台建设中需要考虑的要点如下:
经济灵活可扩展的存储和计算架构,可以根据数据量、查询性能和并发自适应弹性伸缩平台架构,例如云对象存储及 Hadoop、Spark 分布式大数据计算框架,降低运维难度和 TCO
具有常见多数据源的集成能力,包括数据库、数据仓库、文件数据源等,整合企业不同业务线的数据孤岛,统一数据口径
上层数据分析应用的广泛支持,提供 OLAP 数据建模能力,通过标准接口如 ODBC、JDBC、SQL、Rest API 等无缝对接报表、BI、机器学习、数据挖掘、自研分析应用等
需要全面的安全保障,包括用户体系管理(如第三方 LDAP、SSO 集成,用户/用户组管理)、数据权限细粒度管控(表、行列单元格级的访问控制),网络安全(网络 ACL),数据加密,关键操作审计等方面能力
主流云上数据分析服务一览
近年来主流云厂商推出了各自的数据湖的服务,下面以 AWS 和 Azure 为例介绍各自的数据湖解决方案。
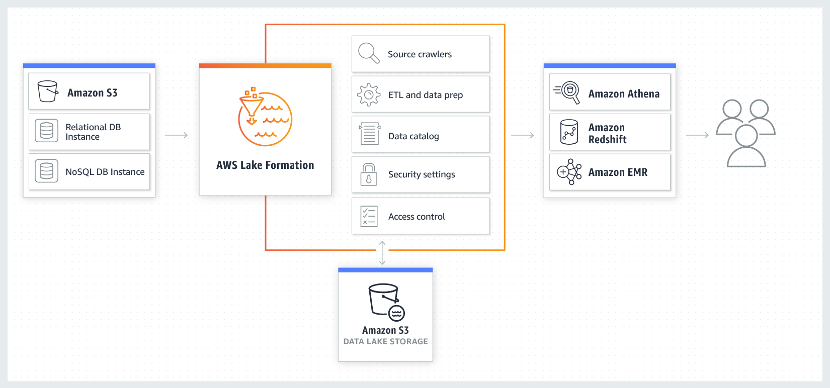
AWS Lake Formation:AWS Lake Formation 是 AWS 提供的一项服务,可以为企业快速建立安全的数据湖架构。通过定义数据源,可以识别 S3 、RDS 关系数据库以及 NoSQL 数据库中存储的现有数据,将数据移动到 S3 数据湖中,通过 EMR for Apache Spark(测试版)、Redshift (基于 PostgreSQL 的 MPP 数据库)或 Athena (Ad-hoc 查询服务)进行分析。
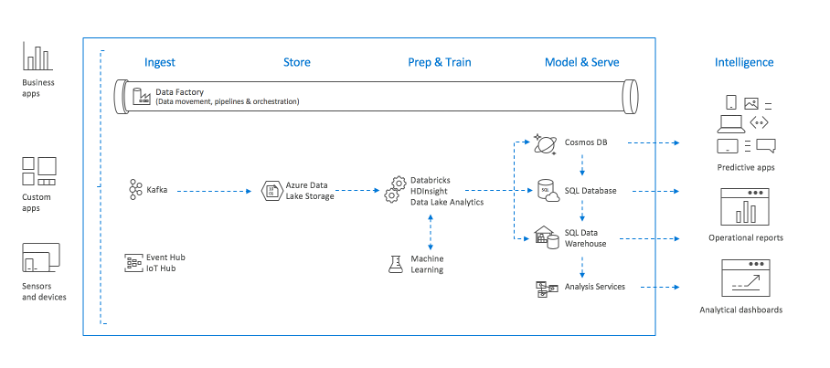
Azure Data Lake Storage Gen2:Azure Data Lake Storage Gen2 是 Azure 推出的一项存储服务,将现有的两个存储服务(Azure Blob 存储和 Azure Data Lake Storage Gen1)的功能进行整合。Azure Data Lake Storage Gen1 的功能(例如文件系统语义、目录、文件级安全性和规模)与 Azure Blob 存储中的低成本分层存储、高可用性/灾难恢复功能进行了组合,适合作为构建数据湖的存储。
借助 Azure Data Factory 对多数据源的 ETL 进行编排和自动化,将 Databricks 或 HDInsight 等分布式计算引擎对数据进行准备和训练,再通过不同的分析型数据库如 Synapse(前 SQL Data Warehouse)和数据模型服务(Analysis Services)为各种分析场景提供数据服务,结合 Power BI 及 Machine Learning 支撑 BI 报表及机器学习等数据分析场景。
由此可见,各家云厂商正在积极拥抱和布局数据湖生态,整合自有优势服务组件,为企业打造云上数据湖分析服务。 由于服务组件功能各异,不同云厂商数据湖解决方案架构设计也存在一些差异,对于企业来讲,还需要根据自身需要选择合适的解决方案。
本期我们探讨了企业数字化转型及数据湖分析平台建设要点,在下一期,我们会详细介绍企业如何借助 Kyligence Cloud 平台实现云上数据湖自助分析,心动不如行动,让我们一起遨游数据湖!
个人介绍: 孔帅,Kyligence 云产品总监 & 增长负责人,负责 Kyligence Cloud 新一代 AI 智能数据湖分析平台产品功能规划设计及获客增长。专注于传统 IT 向虚拟化、云计算、大数据转型的痛点识别和解决方案设计,帮助客户完成 IT 架构和业务的数字化转型。
本文转载自公众号 Kyligence(ID:Kyligence)。
原文链接:




