
具身智能下半场,得“第一视角”者得天下
最近几个月,具身智能赛道太火了。
这种火爆在资本侧体现得尤为明显。仅 6 月前 17 天,具身智能赛道就发生了 11 起投融资事件。6 月 16 日,极佳视界宣布完成 10 亿元 B2 轮融资,资金将用于物理 AGI 基础模型研发迭代,以及 C 端家庭场景和 B 端工业场景规模化落地,前一日,世航智能宣布完成 A 轮融资,大晓机器人完成天使+轮融资。
另据 IT 桔子数据,今年一季度,具身智能领域已发生投融资事件 132 起,融资金额合计 318.61 亿元。
资本热度背后,是行业对具身智能产业化拐点的期待。
但热钱并不意味着问题已经解决。相反,随着更多企业进入本体、模型、控制、灵巧手和场景应用,行业短板也更清晰地暴露出来:机器人要真正进入家庭、仓储、零售、医疗、工业等场景,仍然缺少足够真实、足够规模化、能够支撑模型训练和验证的数据。
这也是具身智能下半场真正困难的地方。模型需要理解人看到什么、先拿什么、为什么换一种抓取方式、遇到遮挡如何调整、失败后如何恢复。这些细节,很难只靠文本、普通视频或仿真环境补齐。
过去,具身智能数据主要来自三条路径:真实机器人原生数据、仿真数据和主从遥操作数据。真实机器人数据最贴近物理世界,但采集成本高、周期长,还容易受机器人硬件结构和动作空间限制,难以跨机型复用;仿真数据成本低、可批量生成,但始终存在虚实鸿沟,模型迁移到真实场景后容易掉性能;遥操作数据能提供机器人可执行的动作轨迹,但依赖专业设备和熟练操作人员,链路复杂,也容易和具体机型绑定。
也正因为这三条路径很难同时满足真实、低成本、可规模化和可泛化的要求,第一视角数据才变得越来越重要。
相比第三视角数据,它更接近操作者当时看到的世界;相比遥操作数据,它更容易在真实场景中规模化采集;相比纯仿真数据,它又保留了真实物理环境中的长尾变化。
近年来,英伟达 FLARE、Meta Ego4D / Ego-Exo4D、苹果 EgoDex 等项目都在加码第一视角数据。
而在今年 4 月,京东开源了当前业界最大规模的人类第一视角数据集 EgoLive ,首批开放 2000 小时视频、65,866 个 episode、346 个真实世界任务,覆盖家庭、仓储、药房等场景。 目前,EgoLive 已收到来自 8 个国家及地区的近百家高校及科研机构申请。
从使用反馈来看,高质量第一视角数据的稀缺性也得到了进一步验证。据清华大学、北京航空航天大学、中山大学、上海交通大学、南洋理工大学等海内外高校与科研机构集体反馈,EgoLive 是当前行业中极为稀缺的可用第一视角数据集,在数据规模、任务覆盖和标注质量上具备很高的研究价值。
这也从侧面说明,第一视角数据集正在成为具身模型训练和评估中的关键资源。
EgoLive 论文地址:https://arxiv.org/html/2604.23570v1
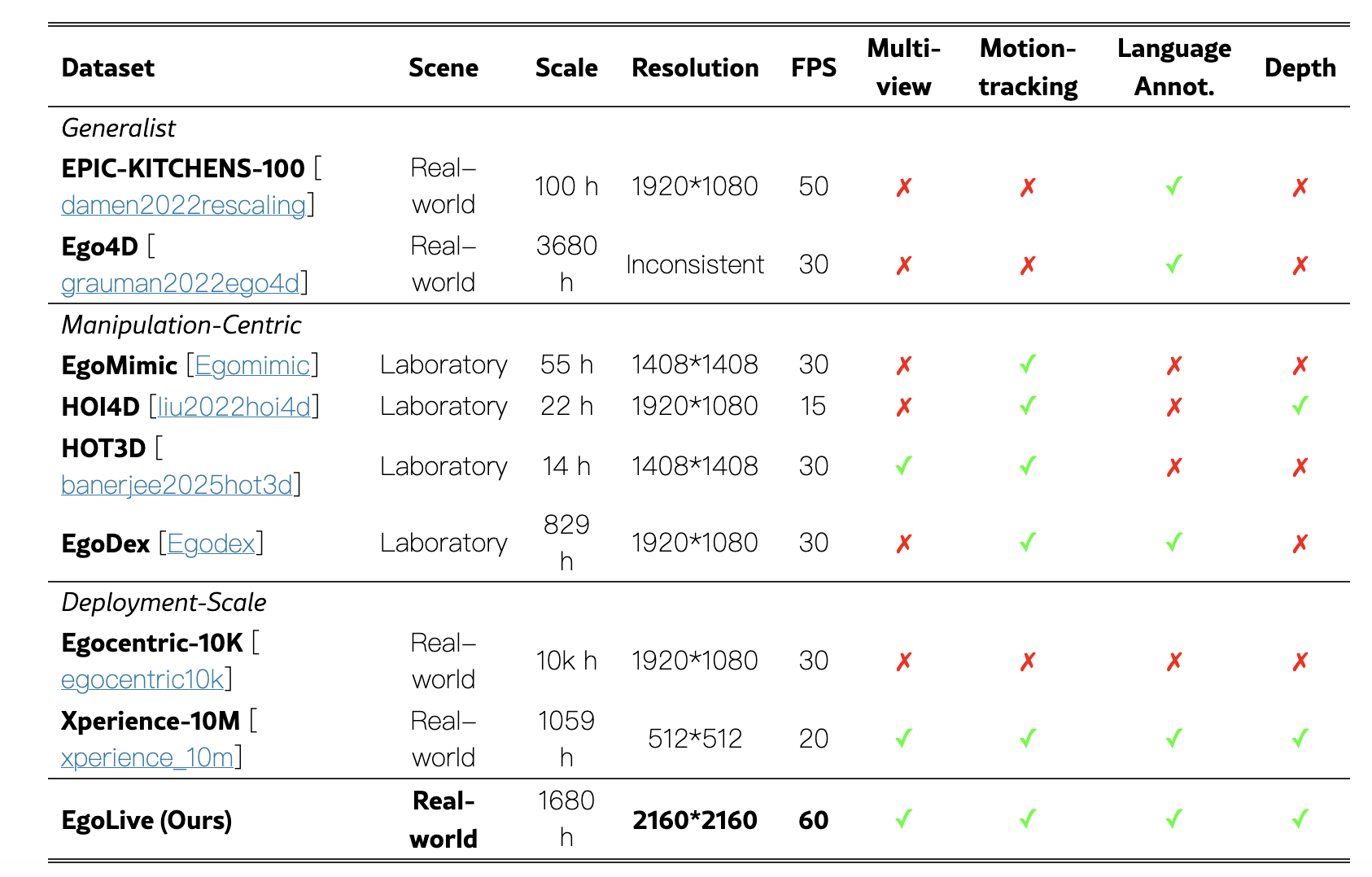
图注:与具身操作和人到机器人迁移相关的代表性人类第一视角数据集对比。只有当某一模态在该数据集的主要公开版本中提供时,表中才将其标记为具备该模态。EgoLive 面向真实世界场景,在采集时长上位居第二,同时在时空分辨率和标注完整性方面具有更优表现。
2000 小时第一视角开源王炸数据集,EgoLive 的价值是什么?
如果说第一视角数据正在成为具身智能训练的重要入口,EgoLive 更值得关注的地方在于,它并没有停留在“收集更多视频”这一层,而是试图把真实世界中的人类操作过程,整理成一套可以被模型训练、评测和复用的数据资产。
这也是它和普通第一视角视频数据最大的差别。
EgoLive 的独特性主要体现在三个层面:一是用更接近人类自然行为的方式采集数据;二是把第一视角视频加工成带有几何、动作和语义信息的多模态数据;三是通过真实场景和长尾任务覆盖,提高数据对具身模型泛化能力的支撑价值。
首先是采集方式。此次数据采集是由京东自研的头戴式采集设备 JoyEgoCam 完成。设备上有双目 RGB 相机,能提供类似人类双眼的宽视场;同时集成 IMU,IMU 频率是 200Hz。视频是 2160×2160、60Hz 的双目 RGB 数据,并配套相机标定文件、触发帧时间戳和同步 IMU 数据。

图注:人体数据采集系统 该系统采用 JoyEgoCam,这是一款定制设计的头戴式设备,用于在真实环境中采集人体行为数据。它配备立体 RGB 摄像头,提供宽广的视野,并集成 IMU,测量频率为 200Hz。
这套设计的巧妙之处在于减少对人的干扰。它和 VR 头显不同,不会遮挡人的脸,也不像一些可穿戴设备那样影响手部动作,采集者可以比较自然地做日常动作。
这样一来,采集者可以在家庭、零售、药房等真实场景中更自然地完成任务,系统则从人的第一视角记录整个操作过程。
其次是标注方式,也是 EgoLive 数据集上的主要技术突破。第一视角数据的难点不只是采集,更在于标准化处理,操作者在移动、低头、转身时,画面会抖动;手与物体之间经常相互遮挡;一个完整任务又往往包含多个连续步骤。如果只把视频直接交给模型,里面大量有价值的信息仍然是“隐形”的。
围绕人类第一视角视频数据,京东探索研究院研发了一整套多模态、高精度的自动化处理算法,可提供手部关键点、深度重建、手物分割、子任务切段、语义描述等多维标注信息。尤其在 3D 场景恢复和 3D 轨迹重建方面,EgoLive 取得了业界领先精度:场景恢复达到毫米级精度,约 3~5mm;3D 轨迹重建达到厘米级精度,约 1~1.5cm。
这套能力为行业第一视角数据处理提出了具有京东特色的标准,也为具身智能模型训练提供了更充分、更精确的信息基础。
换句话说,EgoLive 并不是简单把人类第一视角视频堆成一个数据池,而是把一个连续操作视频拆解成多层结构化信息:哪只手参与了操作,手部关节和手腕在三维空间中如何运动,操作者正在接触哪个物体,物体在画面中的位置和轮廓是什么,当前动作属于整个任务的哪一步,以及这一步可以怎样用语言描述。
从技术层面来看,京东团队把这套自动标注能力拆成三个模块:运动追踪、语义理解和 3D 重建。
在运动追踪上,EgoLive 会估计手腕和手部关节的 6D 轨迹,并与相机自身运动同步,建立动作参考坐标系。系统先基于 HaMeR 估计手部 MANO 参数,再结合双目空间做优化;相机位姿则通过 ORB-SLAM3 融合双目 RGB 和 IMU 数据估计。这样,数据不只记录“手在画面哪里”,还记录“手在真实三维空间中如何移动”。
在语义理解上,系统会检测人手和被交互物体,并通过跟踪、分割和大模型生成自然语言描述。EgoLive 使用 BoT-SORT 进行跟踪,用 SAM2 生成手和交互物体的分割 mask;每个 episode 会根据手物检测与跟踪结果切分成多个 sub-task,再由微调后的 Qwen3-VL-32B 对子任务片段生成细粒度描述。这样做的目的,是让数据同时具备视觉、动作和语言层面的监督信号。
在 3D 重建上,EgoLive 利用双目视觉恢复场景深度和空间结构。系统使用 Foundation Stereo 从精细标定后的双目 RGB 视频中重建 1152×1152 分辨率的深度图。深度信息能帮助模型理解物体和手之间的空间关系,也让第一视角数据更接近机器人真实执行时需要面对的物理世界。
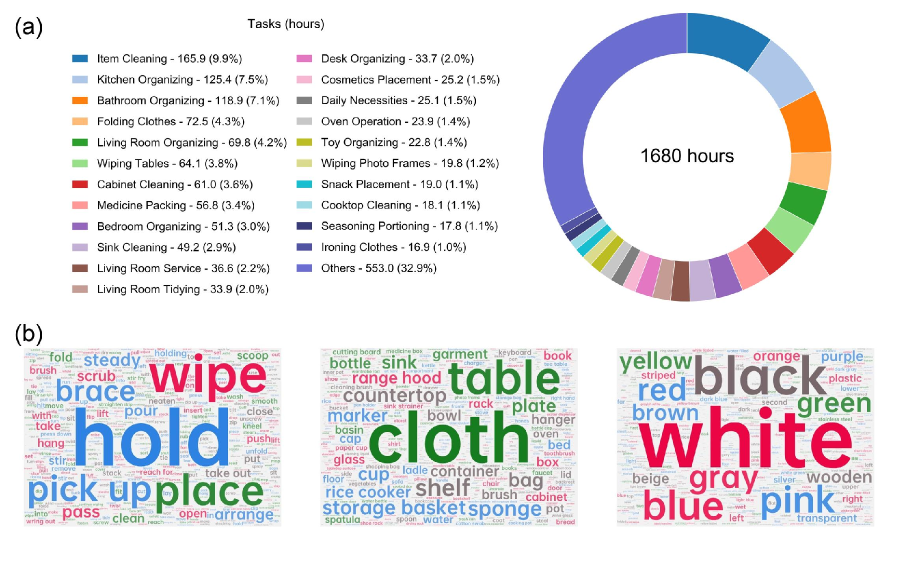
图注: 基于任务描述的 EgoLive 离散语义组合。(a) 任务类别分布,展示了对现实世界活动领域的覆盖,包括家务服务、组织、清洁、物流和其他操作密集型场景。(b) 从指令标题中提取的高频语义标签的词云,涵盖动作、对象和对象属性。
第三层价值来自场景和任务覆盖。EgoLive 首批开放约 2000 小时高精数据、65,866 个 episode、346 个真实世界任务。对第一视角数据而言,规模本身很重要,因为具身模型需要见过足够多不同任务、不同环境和不同操作方式,才可能在真实场景中获得更好的泛化能力。
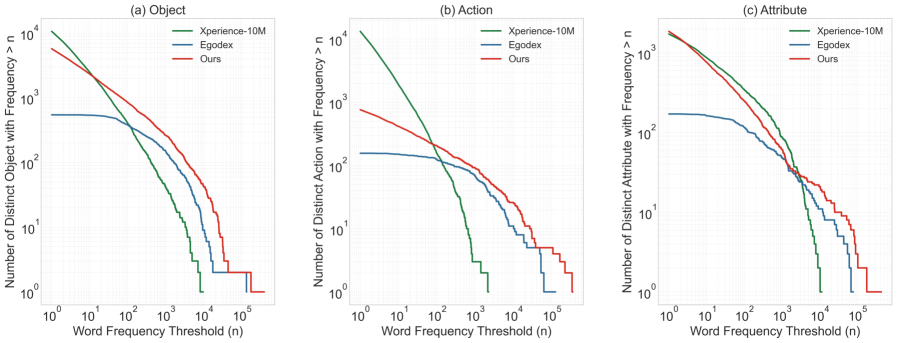
图注:从不同数据集的指令描述中提取的语义标签分布情况:(a)对象分布,(b)动作分布,(c)属性分布。x-轴表示词频阈值 n 以及是轴表示频率大于某个阈值的不同单词的数量。n(日志-日志规模)。
这一点对具身智能训练很重要。数据太窄,模型容易只记住少数场景;数据太散,模型又很难学到稳定规律。EgoLive 试图在“覆盖广度”和“局部密度”之间取得平衡,让模型既能看到长尾变化,也能从同类操作中学习可迁移的模式。
因此,EgoLive 解决的核心问题,并不是行业“有没有第一视角视频”,而是第一视角数据能否被规模化采集、标准化加工,并最终沉淀为可训练的数据资产。
最终,数据集的价值最终要回到模型表现上,EgoLive 的这些能力最终会体现在 JoyAI-RA 的训练上。
JoyAI-RA 本身采用多源、多层级预训练框架,融合网页数据、大规模第一视角人类操作视频、仿真轨迹和真实机器人数据。EgoLive 在其中提供的是人类操作先验:它让模型接触到大量真实场景下的任务流程、手物交互和空间变化,从而帮助模型弥合“人类示范”和“机器人执行”之间的差距。
从公开结果看,融入 EgoLive 数据后,JoyAI-RA 在多个 Benchmark 上获得了验证。
在 RoboTwin 2.0 中,JoyAI-RA 的平均成功率达到 90.48%;
在 RoboCasa GR1 TableTop 任务中,达到 63.2%,超过 LingBot-VLA、π0.5、ABot-M0、Motus 等主流 SOTA 模型。
Benchmark 之外,更值得关注的是模型在真实业务流程中的验证效果。
近期,搭载 JoyAI-RA 的智元 G2 与睿尔曼 RealBOT 机器人正式进驻京东 MALL,承担商品上架、货品规整、杂物收纳等理货岗位的日常运营工作。在 SKU 品类复杂、环境高度非结构化的真实零售场景下,机器人单品上架成功率稳定突破 90%。

这类场景和实验室任务不同。零售门店里的商品形态复杂,货架布局会变化,物体摆放不总是规整,顾客和工作人员也会让环境变得更加动态。机器人能够在这样的环境中完成商品上架和货品规整,说明模型能力已经开始进入真实运营环节。
这也形成了一个更完整的闭环:京东从真实场景中采集第一视角人类操作数据,通过 EgoLive 完成标准化处理和多模态标注,再将这些数据用于 JoyAI-RA 训练,最终又回到京东 MALL 这样的真实场景中接受验证。
对具身智能来说,这条从真实场景中来,又回到真实场景中去的链路比单一 Benchmark 更重要。它意味着数据、模型和场景不再是割裂的,而是能够互相反馈、持续迭代。
夯实具身智能“根技术”,突围可用数据荒
从京东的布局看,EgoLive 并不是一个孤立的开源动作,它更像是京东具身智能数据体系中的一个外溢节点,也是京东构建“全球最大的物理世界运营中心”整体布局中举足轻重的一环。
很有前瞻性的一点是,EgoLive 的开源时机,正踩在具身智能行业前所未有的机遇上。
今年行业出现一个明显趋势:人形机器人正在从样机展示走向量产交付。新华网今年初的报道提到,2026 年人形机器人产业将迈入规模化放量阶段,行业主题从技术收敛切换到量产落地与商业化提速。报道还援引预测称,2026 年国内人形机器人出货量有望继续攀升。
机器人一旦进入更大规模交付,数据、场景、售后、验证都会成为瓶颈。 很多机器人公司可以做本体和算法,但未必拥有足够复杂、足够高频的真实业务场景。
京东的价值在其中尤为凸显。
不久前,京东提出构建“全球最大的物理世界运营中心”,这不是一个孤立的口号,是京东对其过去二十多年核心能力的一次重新定义。
在外界传统认知里,京东更多是一家零售公司,优势在于供应链、仓储物流和履约服务。进入 AI 时代,京东过去积累的零售、物流、供应链和履约能力,被赋予了新的含义:它们成为 AI 理解和介入物理世界的基础场景。仓储分拣、配送路径规划、门店理货、家庭服务等任务,都是高频发生的真实物理操作。
围绕 AI 时代的数据基础设施底座,京东开始建设全球最大的具身智能数据采集中心,依托零售、物流、健康、工业、外卖、家政等场景,发动内部员工和外部人员参与采集,覆盖家庭、办公室、工厂、物流、商店、餐厅、医疗、环卫等超百个细分场景。京东计划一年内积累 500 万小时人类真实场景视频数据,两年内突破 1000 万小时,并同步采集 100 万小时机器人本体数据。
宿迁具身智能数据采集社区,则是这套体系进入生活场景的一步。居民在擦桌子、叠衣服、整理收纳等日常劳动中,佩戴 JoyEgoCam 采集终端,即可记录上肢轨迹、手物交互和家居环境关系。这类数据更碎、更杂,也更接近机器人未来要面对的真实世界。

京东这套布局放到行业里看,最直接的意义,是补上具身智能最缺的真实数据。
但往更深层次理解,它把行业里分散的数据采集,推向更标准化的基础设施。现在很多数据采集还是项目制、实验室制,流程不一、标注不一、流通也难。京东把“采、存、标、训、评、仿、测”串起来,实际上是在往平台化、工程化方向走。
这对机器人企业也有现实价值。很多公司有本体、有算法,但缺少复杂、高频的真实业务场景。京东开放数据集、建设交易平台、提供采集和标注能力,相当于把自身场景能力部分释放给产业链,减少重复采集和重复验证成本。
更关键的是,它试图建立一个闭环:真实场景产生任务,采集系统沉淀数据,训练平台优化模型,机器人再回到场景中验证。这样,模型迭代就不必长期停留在实验室指标上。
这也对应了行业从展示阶段走向运营阶段的变化。当具身智能真正产业化,还是要看它能不能在仓储、零售、家庭、医疗、工业等场景长期稳定作业。如果京东这些复杂、高频、产业化的物理场景能被系统转化为训练和验证资源,也可能成为中国具身智能产业的一种场景优势。
相关论文地址:
https://arxiv.org/html/2604.23570v1
https://arxiv.org/abs/2009.13303
https://arxiv.org/abs/2110.07058
https://arxiv.org/abs/2505.11709
其他参考链接:
https://developer.nvidia.cn/flare




