
最近,最火的 Agent 项目 OpenClaw 又迎来一次大更新:支持 GPT-5.4、加入 Context Engine 插件接口、记忆系统可以热插拔,GitHub Star 也突破了 28 万。
表面看,这次更新内容很多:搜索、插件、通信渠道、容器部署、安全机制……几乎是一次全面升级。但如果只抓一个最关键的变化,其实是这一点:OpenClaw 开始重做 memory。
因为这段时间,OpenClaw 被吐槽最多的地方,其实就是“记性不太行”。你前面说过的东西,它后面可能就忘了;或者同一件事反复记、反复问,memory 越用越乱。很多人一开始以为这是模型不够聪明,后来才发现问题不完全在模型,而在它原来的记忆机制。
过去的 OpenClaw memory 更像“有事再去翻笔记”。系统会把内容写进日志文件和长期记忆文件,需要的时候再通过 memory_search 和 memory_get 这些工具去查。这其实是一种典型的 tools 逻辑:需要时再调用工具,把上下文找出来。
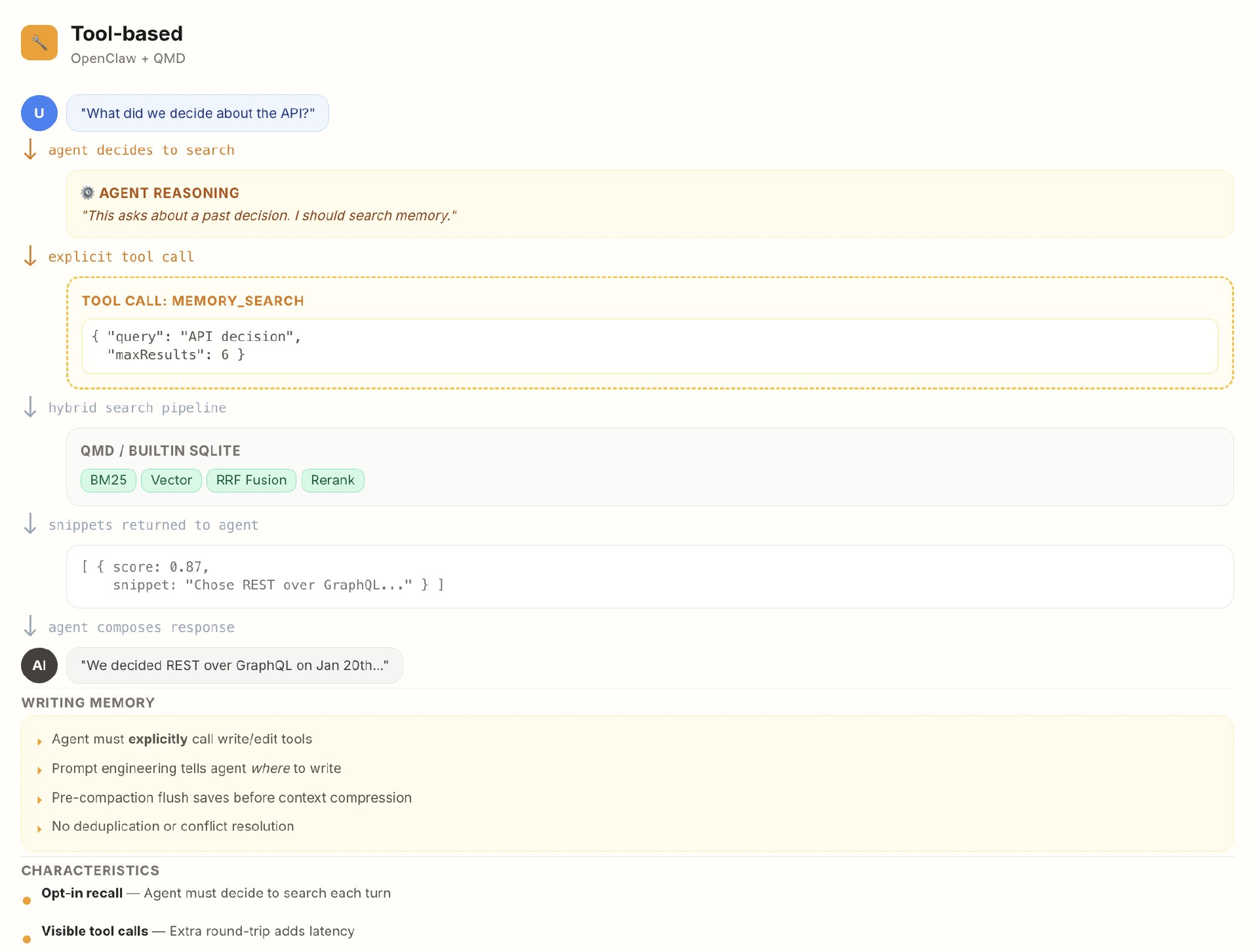
问题在于,这种方式看起来像“按需调用、更省资源”,但实际往往更慢、更费 token,因为每一次工具调用本身也有成本。而且它太依赖 Agent 自己先“想起来去查”,一旦没触发工具,这段记忆就等于不存在。同时,它在知识更新、时间推理、多会话上下文上的表现也不理想:写入新内容时,往往不知道旧记忆里已经有什么,结果就是重复记录、旧信息不更新。再加上它几乎不会遗忘,时间一长,memory 就容易变成一个越来越大的信息堆,什么都在,但真正重要的反而找不出来。
所以这次更新真正重要的地方,是 OpenClaw 开始从 tools 逻辑转向 hooks 逻辑。
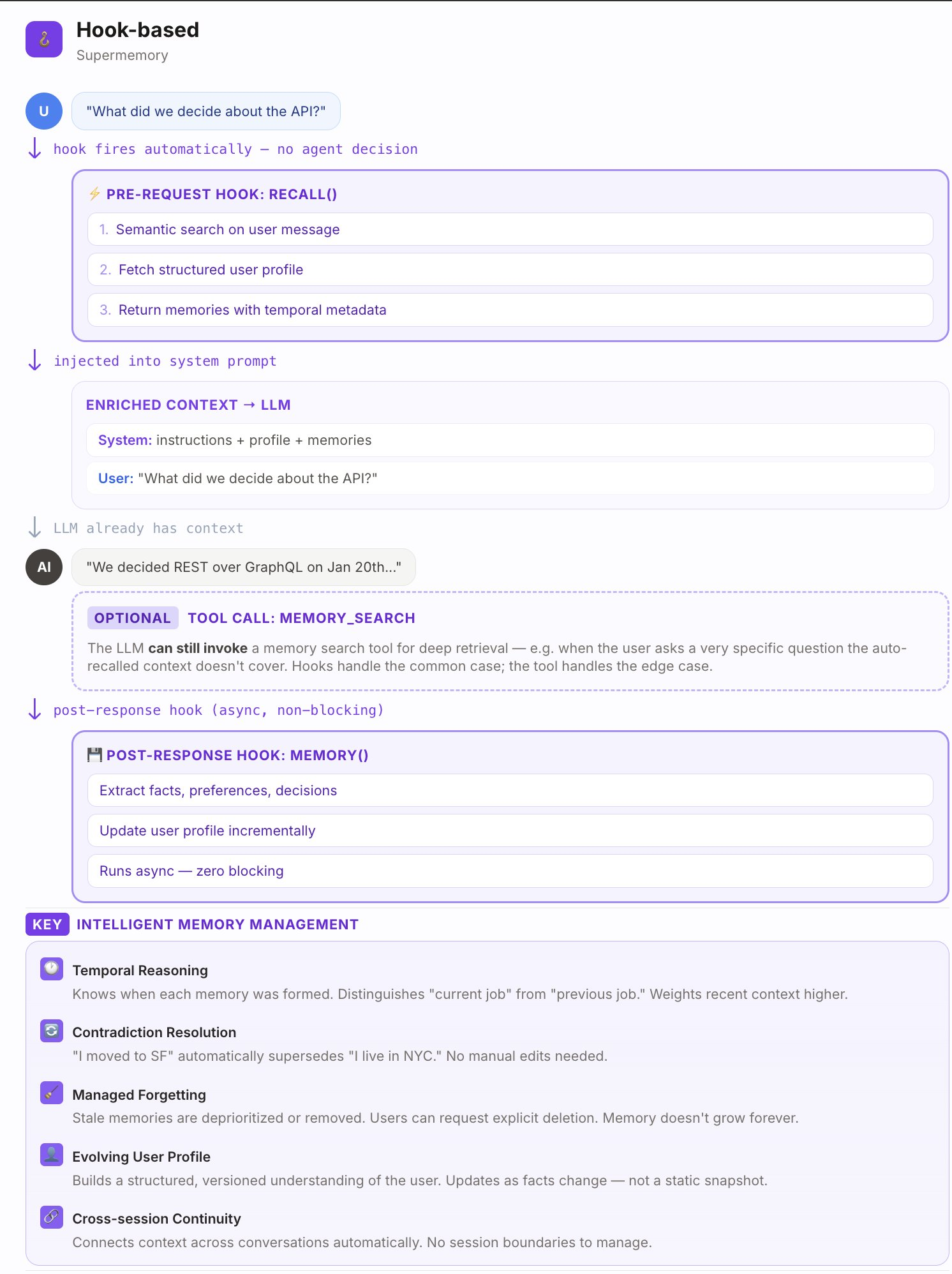
简单说,tools 是“需要时再查”,hooks 是“在关键节点自动处理”。通过 Hook,memory 的保存和上下文补充可以在后台自动发生,而不是每次都依赖 Agent 主动调用工具。这样系统既能提取结构化记忆,也能保留原始上下文,并在需要时补充信息,还可以让长期无关的信息逐渐衰减、被清理掉。
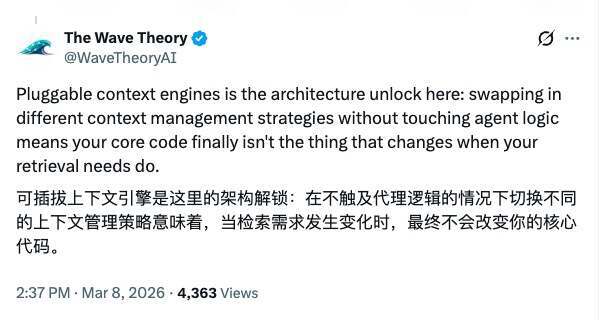
在这个基础上,OpenClaw 又把上下文处理抽象成可插拔的 Context Engine。这意味着开发者不需要改动 Agent 本身,就可以替换不同的上下文管理策略,比如 RAG、知识图谱折叠或无损压缩等。Agent 的逻辑不变,真正变化的是“上下文怎么被组织和注入”。

所以这次更新里,最容易被忽略、但可能最重要的,其实就是 memory。 新模型、新搜索当然都很热闹,但一个 Agent 能不能真正长期好用,关键还是看它能不能把“记住、更新、遗忘”这件事做好。




