
2024 年 8 月,ClickHouse v24.8 引入了功能强大的 JSON 数据类型。从那时起,我们持续通过引入新特性和优化手段不断改进它。
本文将介绍我们如何在 ClickHouse v25.8 中再次实现重大性能提升。
ClickHouse 一直是分析性能方面的行业标杆,而 v25.8 的最新改进也使 ClickHouse 成为处理 JSON 数据分析的领先方案。
v24.8 中 JSON 类型的工作原理
我们先快速回顾一下,在 ClickHouse v24.8 中,JSON 数据在 MergeTree 分区中的存储方式(https://clickhouse.com/blog/a-new-powerful-json-data-type-for-clickhouse)。
如下图所示,我们有一组包含 K 个唯一路径的 JSON 数据,每个路径对应一个字符串值。前 N 个路径作为“动态路径”被存储为子列。其余 K – N 个路径则被存储在一个共享的数据结构中,即一个 Map(String, String) 类型的列,包含路径和值的映射。

例如,当我们查询路径 key1 的数据时,ClickHouse 首先会通过元数据判断 key1 是属于动态路径还是共享数据。在本例中,key1 属于动态路径,因此其值被存储在独立的数据文件中,能够被高效、直接地读取。
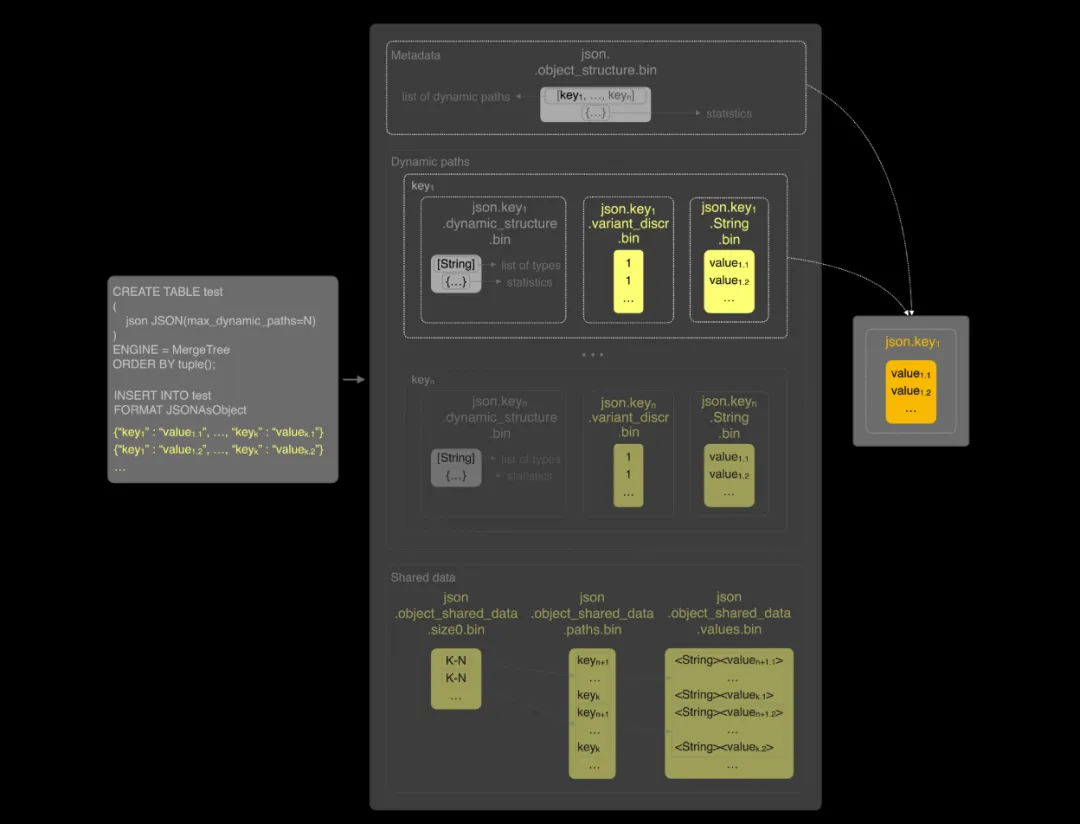
但如果我们查询的是 key_n+1,元数据会显示该路径不在动态路径中,而是存储在共享数据中。此时,ClickHouse 需要读取整个 Map(String, String) 列并在内存中进行过滤处理,效率显著下降。
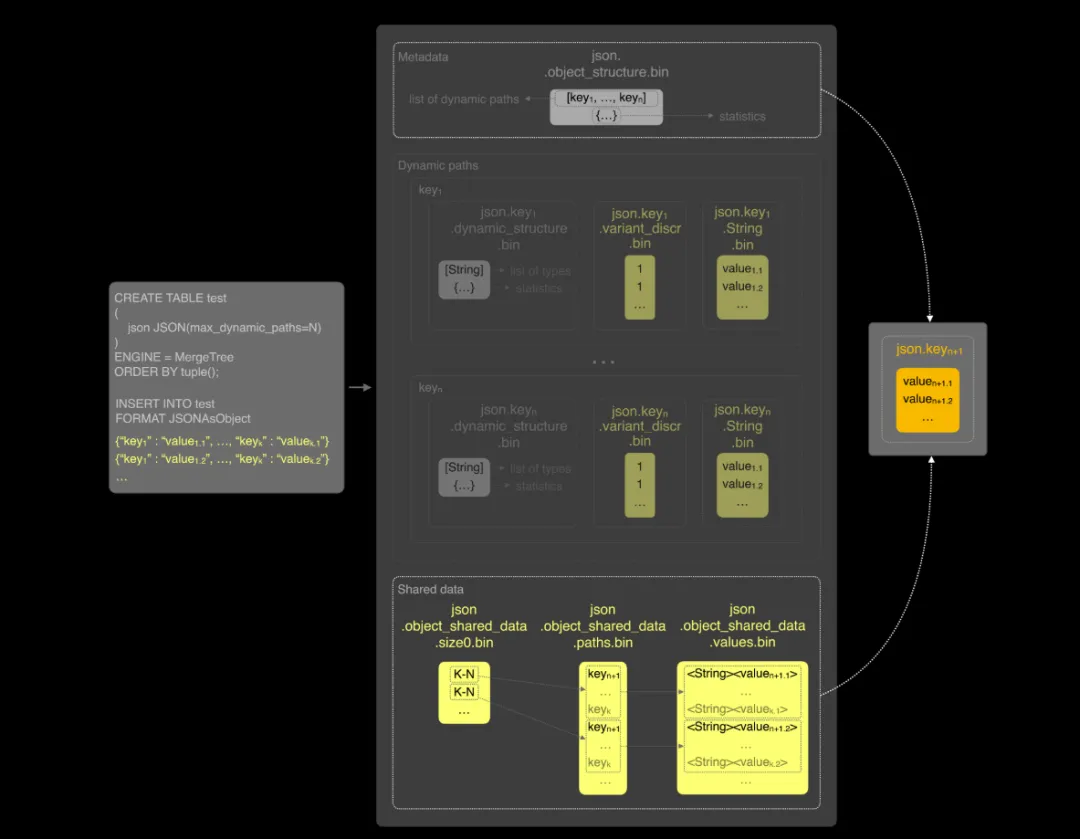
默认情况下,动态路径的数量限制为 1024。当路径数量超过此限制时,尤其是在使用 S3 等远程存储时,贸然提高该限制并不可取,因为每个分区可能生成成千上万的文件,这会在数据合并过程中显著增加内存使用量,并加剧读取复杂度。
因此,对于包含成千上万乃至数万个唯一 JSON 路径的工作负载,系统性能会明显下降。
这正是我们希望解决的难题。
v25.8 引入的新共享数据序列化格式
ClickHouse v25.8 推出了两种新的共享数据序列化格式,显著提升了读取特定路径时的效率。
分桶式共享数据
第一种新格式通过将共享数据划分为 N 个桶进行组织。每个桶包含一个各自独立的 Map(String, String) 列,并通过固定的规则将路径分配到不同的桶中。
当查询如 key_m1 这类路径时,ClickHouse 可直接判断该路径位于哪个桶中,仅读取对应的桶,其余桶则完全跳过。
相较于读取整个共享数据,这种方式大幅减少了扫描的数据量,从而提高了查询性能。但需要注意的是,若桶的数量设置过多,文件数量也会随之增加,容易带来文件系统的额外负担。
高级共享数据
第二种方式采用了更为强大的高级序列化格式。
在该格式中,每个桶包含以下三个文件:
.structure:每个 granule(数据块)的元信息,包括行数、包含的路径列表,以及在 .paths_marks 文件中的偏移位置;
.data:实际路径数据,按列式格式按 granule 存储;
.paths_marks:记录每个路径在 .data 文件中起始位置的偏移指针。
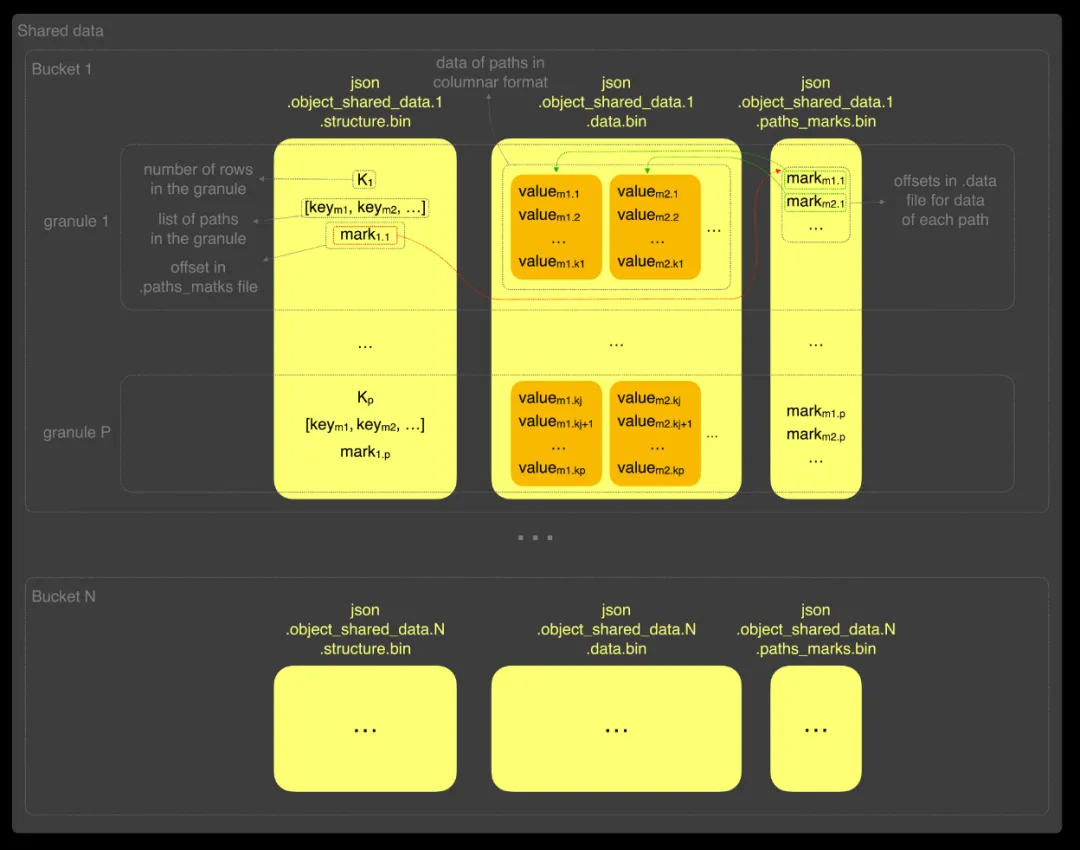
当查询路径 key_m1 时,ClickHouse 首先读取 .structure 文件,判断当前 granule 是否包含该路径;如果不包含,则跳过该 granule;如果包含,则通过 .paths_marks 文件找到其偏移位置,并直接跳转到 .data 文件中对应的路径数据进行读取。
这种方式避免了无关路径数据被加载进内存,从而极大提升了查询效率。
支持嵌套路径
许多 JSON 文档包含嵌套结构,例如对象数组。通过上述方法提取这类嵌套路径时,仍需读取整个数组,对于处理大型数据负载而言效率较低。
为了解决这一问题,我们对高级序列化格式进行了扩展,引入了用于子列处理的额外文件。
在该扩展格式中,每个桶包含以下 6 个文件:
.structure:每个 granule 的元信息,包括行数、路径列表,以及在 .paths_marks 和 .substreams_metadata 文件中的偏移位置;
.data:实际路径数据,以列式格式按 granule 存储,并被划分为多个子流(substreams)。同一路径可能对应多个子流。该结构允许 ClickHouse 仅读取重建目标子列所需的子流,而无需扫描整个路径值;
.paths_marks:指向 .data 文件中每个路径数据起始位置的偏移;
.substreams_marks:指向 .data 文件中每个子流数据起始位置的偏移;
.substreams:记录每个 granule 中各路径对应的子流列表。不同 granule 中可能存在差异,例如某些数组对象可能包含不同的嵌套字段;
.substreams_metadata:为每个路径记录其在 .substreams 和 .substreams_marks 文件中的偏移,建立路径与其子列及数据位置之间的映射关系。
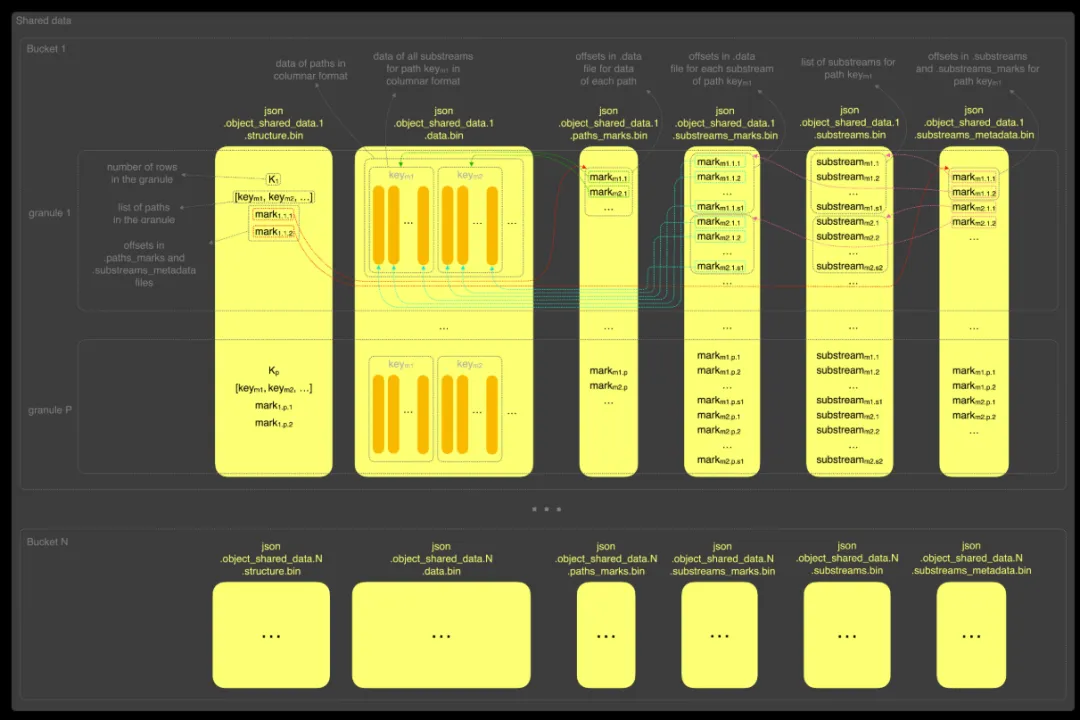
当查询路径 key_m1 的子列时,ClickHouse 首先读取 .structure 文件,判断当前 granule 是否包含该路径。如果不包含,则直接跳过该 granule;如果包含,则根据 .structure 中记录的偏移,读取 .substreams_metadata 文件中对应项,获取 key_m1 的偏移信息。
接着,ClickHouse 根据第一个偏移,从 .substreams 文件中读取该路径在当前 granule 中的子流列表。如果列表中不包含所需的子流,该 granule 会被跳过;若包含所需子流,则 ClickHouse 会根据第二个偏移,从 .substreams_marks 中读取子流位置,并仅从 .data 文件中读取这些子流的数据。
在成功重建目标子列后,ClickHouse 会继续处理下一个 granule。
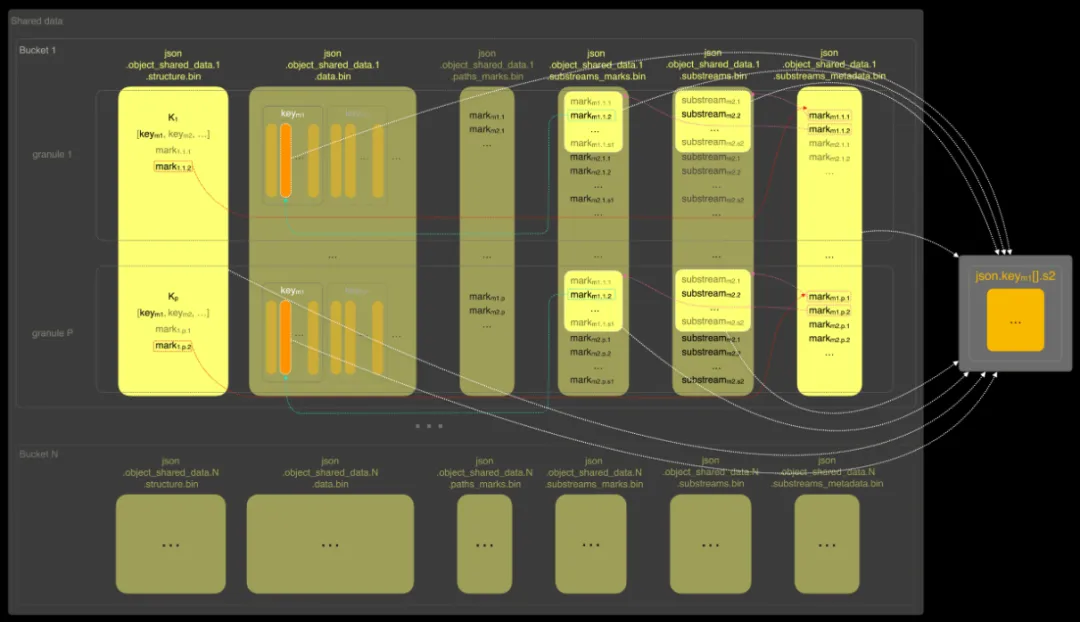
这种方式避免了加载不相关路径及其无关子流的数据,从而显著提升了嵌套子列的读取性能。
平衡效率与兼容性
高级序列化格式在支持选择性读取方面具备显著优势,但也带来了一定的性能开销:当需要读取整个 JSON 列或执行合并操作时,由于共享数据在内存中的表示方式(Map(String, String))与其存储布局差异较大,会引发较重的数据结构转换,导致性能下降。
为此,ClickHouse v25.8 采取了一种折中的方案:在保存高级格式的同时,附加存储一份原始格式的数据副本。虽然这会使存储空间需求翻倍,但可以在保留高级格式选择性读取优势的同时,避免整体读取和合并操作中的性能损失。
如下图所示,原始格式副本被存储在三个额外的文件中:
.copy.offsets:原始 Map(String, String) 列中各项的偏移信息;
.copy.indexes:跨桶路径的索引(避免重复存储所有路径);
.copy.values:原始 Map(String, String) 列中的实际值。
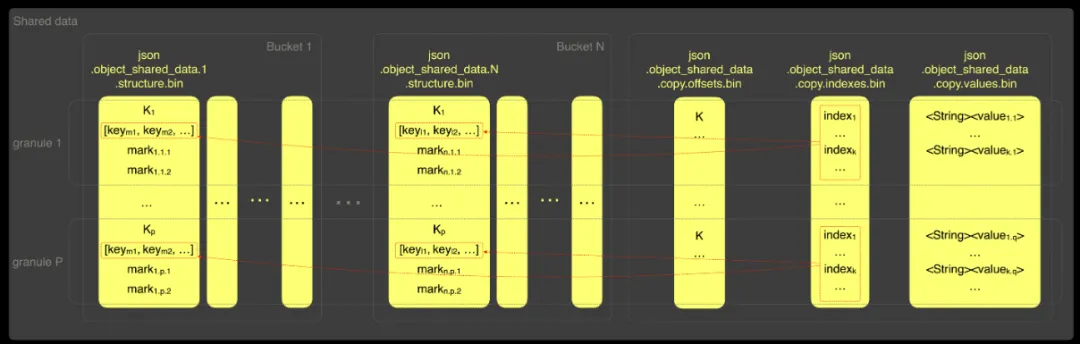
这种副本机制确保了读取完整 JSON 列和执行合并操作的性能不会下降,同时依然保留了高级格式在选择性读取中的优化效果。
性能评估
我们对包含 10、100、1000 和 10,000 条唯一路径的 JSON 数据,使用新的序列化格式进行了性能基准测试。
测试结果显示,高级共享数据序列化在查询速度和内存使用方面的表现,与将所有路径作为动态子列存储的方式相当,同时具备良好的扩展性,可应对数万路径的复杂 JSON 数据。
以下为 10,000 路径测试的一些关键结果,展示了 v25.8 中新序列化机制带来的显著优化。
性能测试 1(选择性读取)
在本项测试中,我们从包含 20 万行数据的表中读取单个 JSON 键。每行均包含一个含 1 万条路径的 JSON 文档,采用宽格式存储。
测试结果表明,使用高级序列化格式后,相较原始 JSON 序列化方式,读取时间提升约 58 倍,内存使用下降约 3,300 倍。
性能测试 2(读取完整 JSON 对象)
本测试从同一数据表中读取每一行的完整 JSON 文档。
测试结果显示,使用高级序列化格式时,读取整个文档的性能几乎与原始 JSON 序列化方式一致。这表明,在保留对选择性读取显著加速的同时,整体读取性能并未受到影响。
结论
全新的共享数据序列化机制将 ClickHouse 对 JSON 数据的支持提升至新高度。借助这一改进,用户可以高效地查询包含数万条唯一路径的复杂 JSON 文档,并在执行选择性读取时获得极佳性能。
这一增强能力进一步巩固了 ClickHouse 在处理大规模半结构化 JSON 数据分析场景中的领先地位。




