
OpenAI 12 天的马拉松式发布活动,终于迎来了尾声。
在这长达两个多星期的系列发布期间,谷歌连续放出两款王炸大模型 Gemini 2.0 Flash 以及专攻推理的 Gemini 2.0 Flash Thinking,这种情况下,OpenAI 如果再不拿出点看家本领恐怕有些说不过去了。
在前几天无关痛痒的新功能推出后,人们都在期待 OpenAI 能放出点“猛料”。别急,“猛料”来了......
OpenAI 发布 o3 和 o3 mini 大模型
刚刚,OpenAI 宣布推出两款前沿模型:o3 和 o3-mini。它们是本月初刚刚全面发布的 o1 和 o1 mini 模型的继任者,更准确地说,o3 是一个像 o1 一样的模型系列,o3-mini 是一个更小、更精简的模型,针对特定任务进行了微调。OpenAI 正在慢慢邀请选定的用户测试这套新的推理模型。
早在今天直播之前,OpenAI CEO Sam Altman 就在 X 平台上发布推文暗示了新 AI 模型 GPT-o3 的发布。Altman 的推文中包含了“呵呵呵,明天见”和“找到线索,应该会说哦哦哦”等短语,暗示了 o3 模型即将发布。推文中“o”和“h”的反复使用被视为即将发布的预兆。
此次发布恰逢 OpenAI 的“OpenAI 12 天”活动的最后一天。在过去的 11 天里,OpenAI 发布了功能齐全的 o1 模型并推出了相关 API。此外,该公司还升级了各种功能,包括函数调用、结构化输出、推理工作量控制、开发人员消息传递和视觉输入功能。
“我们认为这是人工智能下一阶段的开始,你可以用这些模型来完成越来越复杂、需要大量推理的任务,”Altman 说。“在本次活动的最后一天,我们认为从一个前沿模型过渡到下一个前沿模型会很有趣。”
Altman 在直播中表示,公司计划在 1 月底发布 o3-mini,并在“此后不久”发布 o3。
值得一提的是,OpenAI 此次发布的新模型命名为 o3,而不是 o2,这又是为什么?据 The Information 报道,OpenAI 跳过 o2 是为了避免与英国电信提供商 O2 发生潜在冲突。Altman 在今天上午的直播中证实了这一点。Altman 表示,OpenAI“在命名方面一直很糟糕”。
o3 到底强在哪?
那么,o3 到底强在哪里?
在直播中,Altman 表示,o3 模型“在编码方面表现出色”,而且 OpenAI 分享的基准测试也支持它,甚至超过了 o1 在编程任务上的表现,具体数据如下:
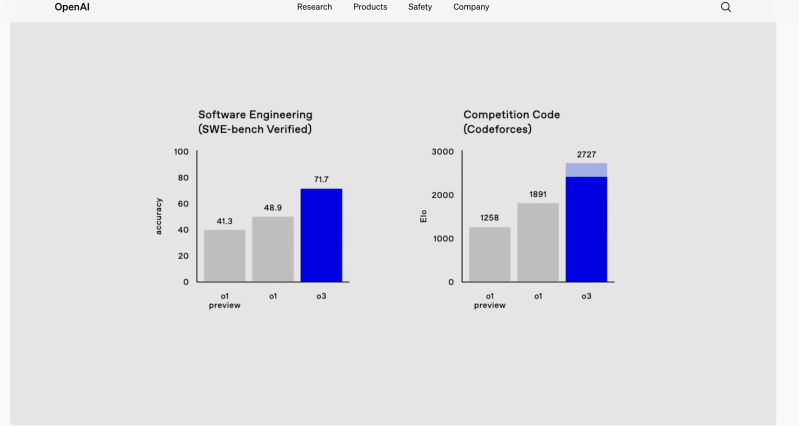
卓越的编码性能: o3 在 SWE-Bench Verified 上比 o1 高出 22.8 个百分点,并获得了 2727 的 Codeforces 评分,超过了 OpenAI 首席科学家的 2665 分。
数学和科学掌握: o3 在 AIME 2024 考试中取得 96.7% 的成绩,仅缺席一道题,在 GPQA Diamond 考试中取得 87.7% 的成绩,远远超过人类专家的表现。
Frontier 基准测试:该模型在 EpochAI 的 Frontier Math 等具有挑战性的测试中创下了新纪录,解决了 25.2% 的问题,而其他模型的解决率均未超过 2%。在 ARC-AGI 测试中,o3 的得分是 o1 的三倍,超过 85%(经 ARC Prize 团队现场验证),代表了概念推理领域的一个里程碑。
在推理能力上 o3 也比以往有了非常大的改进。
与大多数人工智能不同,诸如 o3 之类的推理模型能够有效地自我核实事实,这有助于它们避免通常会绊倒模型的一些陷阱。
这种事实核查过程会产生一些延迟。与之前的 o1 一样,o3 需要更长的时间(通常要多几秒到几分钟)才能得出解决方案,而典型的非推理模型则不然。好处是什么?它在物理、科学和数学等领域往往更可靠。
o3 经过训练,可以在做出反应之前通过 OpenAI 所称的“私人思维链”进行“思考”。该模型可以推理任务并提前计划,在较长时间内执行一系列操作,帮助它找到解决方案。
在实践中,给出一个提示后,o3 会在回答之前停顿一下,考虑一系列相关提示,并在此过程中“解释”其推理。一段时间后,该模型会总结出它认为最准确的答案。
o3 的新功能是能够“调整”推理时间。模型可以设置为低、中或高计算(即思考时间)。计算时间越长,o3 在任务上的表现就越好。
o3 系列模型加强了对安全和对齐的承诺
除了这些进步之外,OpenAI 还加强了对安全和协调的承诺。
Altman 表示,在 OpenAI 发布新的推理模型之前,他更希望有一个联邦测试框架来指导监控和降低此类模型的风险。
尽管 o3 已经非常先进了,但它也存在风险。人工智能安全测试人员发现,o1 的推理能力使其欺骗人类用户的概率比传统的“非推理”模型更高——或者说,比 Meta、Anthropic 和 Google 的领先人工智能模型更高。o3 欺骗的概率可能比其前身更高。
因此,OpenAI 表示,它正在使用一种新技术“审议性对齐”,使 o3 等模型与其安全原则保持一致。(o1 以相同的方式对齐。)该项技术还将在协调 o3 和 o3-mini 方面发挥关键作用,确保它们的能力强大而负责。
业内如何评价 o3?
此次的 o3 系列模型的发布可谓赚足了眼球,因为 OpenAI 做出了一个惊人的声明:o3 至少在某些条件下接近 AGI——但也存在重大隐患。
AGI 是“通用人工智能”的缩写,泛指能够执行人类所能完成的任何任务的人工智能。但对于通用人工智能,OpenAI 有自己的定义:“在最具经济价值的工作上表现优于人类的高度自主系统。”
实现 AGI 将是一个大胆的宣言。而且这对 OpenAI 来说也具有非同凡响的意义。根据与密切合作伙伴和投资者微软的协议条款,一旦 OpenAI 实现 AGI,它就不再有义务让微软使用其最先进的技术(即符合 OpenAI AGI 定义的技术)。
但从一项基准测试来看,OpenAI 正在慢慢接近 AGI。
在 ARC-AGI(一项旨在评估 AI 系统是否能够有效地在其训练数据之外获得新技能的测试)中,o3 在高计算设置下获得了 87.5% 的分数。在最差的情况下(在低计算设置下),该模型的性能是 o1 的三倍。
当然,高计算设置的成本非常高——根据 ARC-AGI 联合创始人 Francois Chollet 的说法,每个任务的成本高达数千美元。
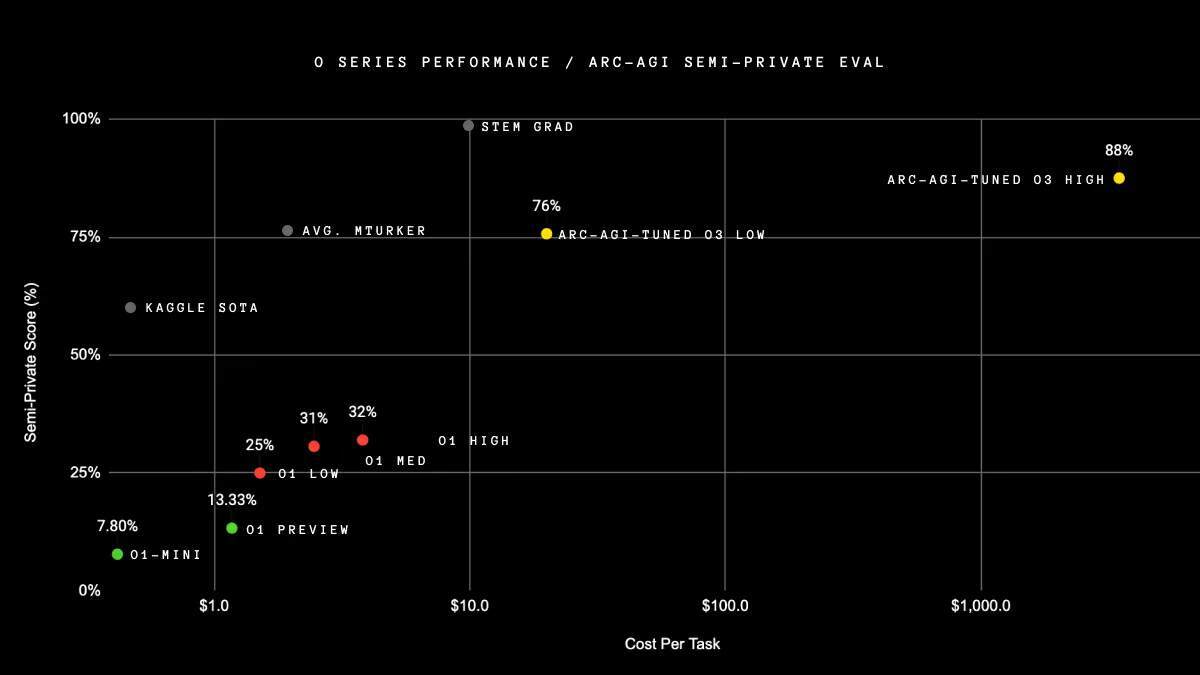
Francois Chollet 在 X 上发文称:“今天,OpenAI 宣布了其下一代推理模型 o3。我们与 OpenAI 合作在 ARC-AGI 上对其进行了测试,我们认为这代表了让 AI 适应新任务的重大突破。它在低计算模式下的半私有评估中得分为 75.7%(计算中每个任务 20 美元),在高计算模式下得分为 87.5%(每个任务数千美元)。它非常昂贵,但这不是在使蛮力——这些功能是新领域,需要认真的科学关注。”

那么,这就是 AGI 吗?Francois Chollet 表示:“虽然新模型非常令人印象深刻,代表着 AGI 道路上的一个重要里程碑,但我不认为这就是 AGI——仍有相当多的 ARC-AGI-1 任务 o3 无法解决,而且我们有早期迹象表明 ARC-AGI-2 对 o3 来说仍然极具挑战性。这表明,创建不饱和的、有趣的基准仍然是可行的,这些基准对人类来说很容易,但对人工智能来说却不可能完成——无需专业知识。只有当我们已经再也无法创建类似这种测评时,我们才算真的拥有 AGI。”
虽然,ARC-AGI 有其局限性——而且它对 AGI 的定义只是众多定义之一。但在其他基准测试中,o3 同样击败了竞争对手。
在专注于编程任务的基准 SWE-Bench Verified 上,o3 的表现比 o1 高出 22.8 个百分点,并获得了 Codeforces 评分(另一个衡量编码技能的标准)2727 分。(2400 分的评分使工程师处于 99.2 个百分点。)o3 在 2024 年美国数学邀请赛上得分为 96.7%,只错一道题,在 GPQA Diamond(一组研究生水平的生物学、物理学和化学问题)上得分为 87.7%。最后,o3 在 EpochAI 的 Frontier Math 基准上创下了新纪录,解决了 25.2% 的问题;其他模型都未超过 2%。
o3 模型的发布在 Reddit 论坛上引发了广泛讨论。有用户表示:
“Chollet 很客观地评价了这款模型,这应该具有重要意义。此外,无论 AGI 是如何定义的(当然,对于许多定义来说,这并不是定义),结果都必须得到承认。o3 现在在重要的、具有经济价值的认知任务中远远领先于其他模型。”
有看热闹不嫌事儿大的用户期待能有人将谷歌刚刚发布的 Gemini 2.0 Flash Thinking 模型和 o3 进行对比,该用户表示:
“根据他们的基准测试,o3 的表现远胜于 o1。我倒想看看它们在实际用例中的表现。我认为他们说的是,与 o1 和 o1-mini 相比,o3(至少是 API)的运行成本更低。期待他们与 Gemini Flash Thinking 的对比。激动人心的时刻即将到来……”
推理模型正成为大势所趋
OpenAI 发布首批推理模型后,包括谷歌在内的竞争对手 AI 公司纷纷推出了大量推理模型。
11 月初,国内 AI 研究公司 DeepSeek 发布了其首款推理模型 DeepSeek-R1的预览版。同月,阿里巴巴的通义千问团队发布了其声称是 o1 的第一个“公开”挑战者的产品。
那么,究竟是什么打开了推理模型的闸门?
首先,就是寻找改进生成式人工智能的新方法。因为大家逐渐发现,用于扩展模型的“蛮力”技术不再能带来像以前一样的重大技术突破。
然而,也并非所有人都相信推理模型是最佳的发展方向。首先,它们往往价格昂贵,因为运行它们需要大量的计算能力。尽管到目前为止,它们在基准测试中表现良好,但尚不清楚推理模型是否能保持这种进步速度。
有趣的是,o3 的发布正值 OpenAI 最有成就的科学家之一离职之际。Alec Radford 是 OpenAI 生成式 AI 模型“GPT 系列”(即 GPT-3、GPT-4 等)学术论文的主要作者,本周他宣布将离职从事独立研究。
最后,不得不说,作为全球顶级 AI 明星独角兽,OpenAI 技术先进是真,但比技术更先进的,或许是 Altman 高超的营销手段吧。
参考链接:




