
过去几十年,软件工程有一个稳定不变的前提:系统的行为写在代码里。工程师读代码,就能推断系统在大多数场景下会怎么运行;测试、调试、上线,也都围绕“确定性”展开。但 Agent 的出现正在动摇这个前提:在 Agent 应用里,决定行为的不再只是代码,还有模型本身——一个在代码之外运行、带着非确定性的黑箱。你无法只靠读代码理解它,只能让它跑起来、看它在真实输入下做了什么,才知道系统“到底在干什么”。
在播客中,LangChain 创始人 Harrison Chase 还把最近一波“能连续跑起来”的编程 Agent、Deep Research 等现象视为拐点,并判断这类“长任务 Agent”的落地会在 2025 年末到 2026 年进一步加速。
这也把问题推到了台前:2026 被很多人视为“长任务 Agent 元年”,现有的软件公司还能不能熬过去?就像当年从 on-prem 走向云,并不是所有软件公司都成功转型一样,工程范式一旦变化,就会重新筛选参与者。长任务 Agent 更像“数字员工”——它不是多回合聊天那么简单,而是能在更长时间里持续执行、反复试错、不断自我修正。
在这期与红杉资本的对话中,Harrison 抛出了一个判断:构建 Agent,已经不只是把软件开发“加一层 AI”,而是工程范式本身在变。为什么他说“光读代码不够了”?为什么 tracing、评估、记忆这些原本偏“辅助”的东西,突然变成主角?他在对话里给出了非常具体的解释。
而更现实的问题是:如果范式真的在变,那些靠数据、流程、产品形态建立壁垒的传统软件公司,优势还能不能延续?它们手里握着的数据与 API 可能依然是王牌,但能否把这些资产变成 Agent 时代的生产力,取决于一套全新的工程打法。Harrison 的观察与判断,都在下面的完整对话里:
主持人:AI 领域的变化速度快得惊人。当前最受关注的话题,我觉得没有人比你更合适来聊。我们会先谈 长任务 Agent(Long Horizon Agents) 和 Agent Harness(智能体运行框架)。
接着,我们会讨论:构建长任务 Agent 与构建传统软件到底有什么不同,以及你如何看待 LangChain 在整个生态系统中的角色。最后,我想和你聊聊未来。你怎么看红杉资本这篇关于 Long Horizon Agents 的文章?哪些观点你认同,哪些地方你不太同意?

“在去年的一篇文章中,我们曾提出:推理模型(reasoning models)是 AI 领域最重要的新前沿。而“长任务 Agent”(long-horizon agents)则在这一范式之上更进一步——它们不只是思考,还能够采取行动,并在时间维度上不断迭代。”
来源:https://sequoiacap.com/article/2026-this-is-agi/
Harrison Chase:你们这个概念命名得非常好,那篇文章也写得很棒。我整体上是认同的——长任务 Agent 终于开始真正“跑起来”了。
一开始对 Agent 的设想,本来就是让一个 LLM 运行在一个循环里,自主决定接下来该做什么。
AutoGPT 本质上就是这个想法,这也是它当初能迅速走红、抓住那么多人想象力的原因:一个 LLM 在循环中运行,完全自主地决定行动。但当时的问题在于:模型还不够好,围绕模型的 scaffolding(支架)和 harness(框架)也不够成熟。
这几年,模型本身变得更强了;与此同时,我们也逐渐搞清楚了,什么样的 harness 才是“好”的。于是现在,这套东西开始真正奏效了。最明显的例子是在编程领域,Agent 的突破首先发生在那里。之后,这种能力正在向其他领域扩散。
当然,你仍然需要告诉 Agent 你想让它做什么,它也需要配备合适的工具。但现在,它确实可以持续运行更长的时间,而且表现越来越稳定。所以,用“长时序”来描述这一类 Agent,我觉得非常贴切。
主持人:你最喜欢的长任务 Agent 案例有哪些?你觉得它们正在呈现出哪些形态?
Harrison Chase:目前最成熟、我自己用得最多的,还是 编程 Agent。
再往外延一点,我觉得非常优秀的一类是 AI SRE。比如 Traversal(我记得它是一家红杉投资的公司),他们的 AI SRE 可以在更长的时间跨度内运行。再往抽象一点,其实这类 AI SRE 本质上属于“研究型 Agent”。比如:给它一个事故,它会去翻日志、分析上下文、追溯原因。研究任务本身非常适合 Agent,因为它们最终产出的往往是一个“初稿”。
Agent 的问题在于:它们还达不到 99% 的可靠性,但它们可以在较长时间内完成大量工作。所以,只要你能把任务框定为:让 Agent 长时间运行,产出一个初步版本,由人来审阅,这在我看来就是目前长任务 Agent 最“杀手级”的应用形态。
编程就是一个例子:你通常是提交 PR,而不是直接推到生产环境(当然,vibe coding 现在也在不断进步)。AI SRE 也是一样:结果会交给人来 review。报告生成也是如此:你不会直接发给所有用户,而是先看一遍、改一改。我们在金融领域也看到了大量这样的用法,这是一个非常大的研究机会。客服领域同样如此。最早的客服 Agent 主要是做“第一响应”:用户一发消息,马上给出回复,这类用法现在也做得很好。
但现在开始出现新的形态,比如 Klarna 这个产品:人类和 AI 协同工作。当第一层自动回复失败后,不是简单地转交给人工,而是让一个长任务 Agent 在后台运行,生成一份完整的事件报告,然后再交给人工客服处理。
这里“agent”这个词在客服语境下会变得有点混乱,但核心逻辑是一致的。总结来说,这些应用的共同点是:先由 Agent 生成一个“初稿”,再由人类接管。
主持人:那么,“为什么是现在”?你觉得主要是因为模型本身变得足够强,还是因为人们在 harness 侧做了非常聪明的工程设计?在回答这个问题之前,能不能先帮听众梳理一下:在一个 Agent 系统中,模型、框架和 harness 各自扮演什么角色?
Harrison Chase:当然可以。我也顺便把“框架”这个概念一起带进来。一开始,我们把 LangChain 描述为一个 Agent Framework,现在我们又推出了 Deep Agents,我更愿意称它为一个 Agent Harness。
很多人都会问,这两者有什么区别。模型很简单,就是 LLM:输入 token、输出 token。框架(Framework) 是围绕模型的一层抽象,让你更容易切换模型,封装工具、向量数据库、记忆等组件,本身比较“无偏好”,强调灵活性,更像是基础设施。Harness 则更“有主张”。以 Deep Agents 为例:我们默认就提供一个 规划工具(Planning Tool);这个工具是直接内建在 harness 里的,带有明确的设计立场:我们认为这是“正确”的做法。
我们还做了 上下文压缩(Compaction)。长任务 Agent 会运行很久,哪怕上下文窗口已经很大,也终究是有限的,总会有需要压缩的时候。怎么压缩?压缩什么?这是一个正在被大量研究的问题。
此外,几乎所有 Agent Harness 都会提供文件系统交互能力,不管是直接操作,还是通过 bash。这一点其实很难和模型本身完全分开,因为模型训练数据里已经大量包含了这类操作。
如果回到两年前,我不确定我们是否能预见到:基于文件系统的 harness 会成为最优解之一。那时模型还没被充分训练过这些模式,而现在模型和 harness 是在一起“共同进化”的。
所以总结来说,这是一个组合效应:模型本身确实在变强,推理模型带来了巨大提升。同时,我们也逐渐摸索出了 compaction、planning、文件系统工具等一整套关键原语。这两者缺一不可。
设计范式的演进
主持人:我记得在我们第一次对谈时,你把 LangGraph 描述为 Agent 的“认知架构”。现在来看,这是不是也可以理解为 harness 的一种形态?
Harrison Chase:是的,这个理解是对的。我们现在的 Deep Agents 是构建在 LangGraph 之上的。可以把它看作是一个非常具体、非常有主张的 LangGraph 实例,更偏向通用目的。
早期我们讨论过“通用架构”和“专用架构”的区别。现在我们观察到一个很有意思的变化:过去需要写进架构里的任务特异性,正在转移到工具和指令里。
复杂性并没有消失,只是从结构化代码,转移到了自然语言中。因此,prompt 的设计、修改,甚至自动更新,正在成为系统的一部分;而 harness 本身,反而变得更加稳定。
主持人:在你看来,harness 工程中最难做对的是什么?你觉得单个公司是否真的有可能在这一层形成显著优势?有没有你特别佩服的团队?
Harrison Chase:说实话,目前在 harness 工程上做得最好的,基本都是编程类公司。Claude Code 就是一个非常典型的例子。我认为它能如此受欢迎,很大程度上是因为它的 harness。
主持人:这是否意味着:harness 更适合由模型公司来做,而不是第三方创业公司?
Harrison Chase:我不确定。比如 Factory、AMP 这些编程公司,也都做出了非常强的 harness。
确实存在一个现实:harness 往往和模型家族绑定得比较紧密。不一定是某一个具体模型,而是一整个模型体系。Anthropic 的模型会针对某些工具进行微调,OpenAI 则针对另外一些。这和 prompt 类似:不同模型,需要不同的 prompt;同样,不同模型家族,也需要稍微不同的 harness。当然,它们也有很多共性,比如几乎都会使用文件系统。
我自己也没有一个确定答案。但一个很明显的现象是:几乎所有做编程 Agent 的公司,现在都在自研自己的 harness。你去看 Terminal Bench 2 这样的榜单,会发现他们不仅展示模型,还展示 harness。Claude Code 并不总是在榜首。这说明:性能差异并不完全来自模型,而来自对“模型如何在 harness 中工作”的理解。
主持人:你觉得,排行榜上表现最好的 harness,究竟在哪些地方做得特别好?
Harrison Chase:首先是对模型训练偏好的理解。比如 OpenAI 的模型对 Bash 非常熟悉;Anthropic 提供了显式的文件编辑工具。顺着模型的“母语”来设计 harness,本身就能带来性能收益。
其次是 上下文压缩(Compaction)。随着任务时间跨度变长,如何处理上下文窗口溢出,已经成为一个核心问题。这显然也是 harness 的一部分。
此外,还有 skills、子 Agent、MCP 等机制。目前这些能力还没有被系统性地训练进模型中,仍然属于比较新的探索方向。
在我们的 harness 中,一个典型挑战是:主 Agent 如何与子 Agent 高效通信。主模型需要把所有必要信息传递给子 Agent,同时还要明确告诉它:最终只需要返回一个“最终结果”。
我们见过一些失败案例:子 Agent 做了大量工作,最后却返回一句“请查看我上面的分析”,而主 Agent 根本看不到那些内容,于是完全不知道它在说什么。
所以,如何通过 prompt 设计让这些组件协同工作,是 harness 工程中非常重要的一部分。
如果你去看一些公开的 harness prompt,它们往往有几百行之长。
主持人:我想从演进角度问一个问题。你一直站在模型“如何落地”的最前沿。如果用一种简化视角来看过去五年的几个关键拐点:ChatGPT 带来了预训练的拐点;o1 带来了推理能力的拐点; 最近,Claude Code + Opus 4.5 带来了长任务 Agent 的拐点。但从你这个“围绕模型做设计”的世界来看,拐点会不会是另一套划分?从认知架构到框架、再到 harness,这中间经历了哪些真正的跃迁?
Harrison Chase:我大概会把它分成三个阶段。
第一阶段:最早期。那时 LangChain 刚刚出现,模型还是“纯文本输入、纯文本输出”,甚至还不是 chat 模型。没有工具调用,没有 reasoning,没有结构化输出。人们主要做的是单一 prompt 或简单 chain。
第二阶段:工具与规划开始进入模型。模型开始支持 tool calling,也尝试学会“思考”和“规划”。虽然还不够强,但已经能做出基本决策。这时,人们大量使用自定义的认知架构,通过显式提问来引导模型行动,但整体仍然依赖大量外部 scaffolding。
第三阶段:长任务 Agent 的真正起飞。大概是在今年 6~7 月,我们看到 Claude Code、Deep Research、Manus 等产品同时爆发。它们在底层使用的是同一个核心算法:让 LLM 在循环中运行。
真正的突破来自于 上下文工程:压缩、子 Agent、技能、记忆——所有这些,都是围绕上下文展开的。这正是我们开始做 Deep Agents 的时间点。
对于很多程序员来说,Opus 4.5 可能是一个心理上的分水岭。也可能只是碰巧遇上假期,大家回家开始大量使用 Claude Code,突然意识到:它真的很好用。无论是 2025 年初还是 2025 年末,总之在某个时间点,模型“刚好强到足以支撑这种形态”,于是我们从 scaffolding 迈向了 harness。
Coding Agent 是通用 AI 的终局形态吗
主持人:接下来会发生什么?
Harrison Chase:我也希望我知道答案。这个“让 LLM 在循环中运行、让它自己决定要拉什么上下文进来”的算法,本身极其简单、也极其通用。这正是 Agent 从一开始的核心设想,而我们现在终于走到了“它真的能工作”的阶段。
接下来,可能会有大量围绕上下文工程的技巧出现:有些手动设计的部分可能会消失;比如压缩类的,现在仍然高度依赖 harness 作者的决策。Anthropic 已经在尝试让模型自己决定何时压缩上下文,虽然目前用得还不多。
另一个我们非常关注的方向是 记忆(Memory)。从本质上说,记忆也是一种上下文工程,只不过是跨更长时间尺度的上下文。核心算法本身已经非常清晰:运行 LLM 循环。未来的进步,很可能来自更聪明的上下文工程方式,或者让模型自己参与上下文管理。模型当然也会继续变强,越来越擅长长时序任务。
我目前思考最多的一个问题是:我们看到的大多数 harness 都是高度偏向编程任务的。这是长任务 Agent 最先爆发的领域。但即便是在非编程任务中,你也可以认为:写代码本身是一种非常强的、通用的工具。
主持人:我本来想问你:编程智能体(coding agents)到底算不算一个子类别?还是说编程智能体就是智能体本身?换句话说,智能体的工作,本质上是想办法让计算机去做一些有用的事情,而“写代码”本来就是让计算机做有用事情的一种很好的方式。
Harrison Chase:我也不确定。但有一点我非常非常坚信:现阶段只要你在做长时序智能体,你就必须给它文件系统的访问能力。因为文件系统在“上下文管理”方面能做的事情太多了。比如我们说 compaction(上下文压缩),一种策略是把内容总结掉,但把完整的消息都放进文件系统里,这样如果智能体后续需要回查,它还能查到。
另一种策略是,当你遇到很大的工具调用结果时,不要把全部内容都塞回模型上下文里;你可以把结果放进文件系统,然后让智能体需要的时候再去查。
而这些操作,其实不一定需要真实的文件系统,也不一定要让它真的去写代码。我们有一个概念叫“虚拟文件系统”:它底层可能只是 Postgres 之类的存储,扩展性更强。当然,“真实代码”能做的事情,虚拟文件系统做不了。比如你没法在虚拟文件系统里直接运行代码。所以写脚本在很多场景下确实非常有用。
我也认为编程智能体有潜力成为通用智能体,但我不确定这是否意味着“今天的编程智能体”就是通用智能体——如果你能理解我这句话。因为我觉得现在很多编程智能体还是为编程任务做了大量优化的。
所以“一个通用智能体可能长得像编程智能体”,但反过来,“今天的编程智能体就是通用智能体”,这件事我并不确定。
传统软件面临的挑战
主持人:那我们能不能转到另一个话题:构建长时序智能体和构建传统软件之间的差异?你能不能先描述一下“1.0 时代”的软件开发栈是什么样的,然后说说现在到底哪里不一样?我记得你在 X 上写过一篇很不错的文章,也许你可以总结一下核心结论。
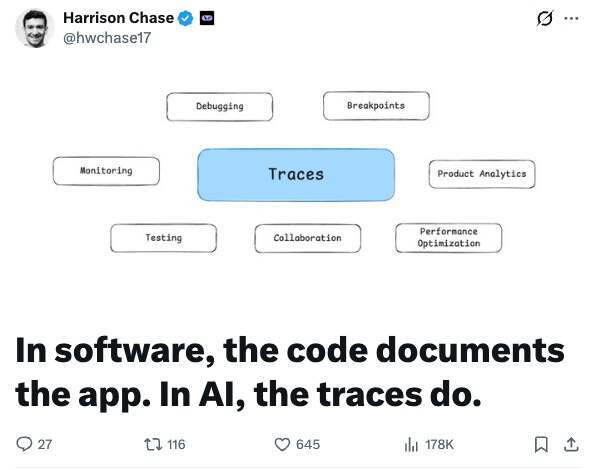
来源:https://x.com/hwchase17/status/2010044779225329688
Harrison Chase:我这段时间一直在反复想这个问题:我们经常说“做智能体和做软件是不同的”,而且很多人也同意。但问题是:到底哪里不同?
我觉得很容易、也很偷懒地说“不同”,但“具体不同在哪里”才是关键。下面这些可能听起来很显然,但也许显然是好事,希望它们不太有争议。
当你在做传统软件时,所有逻辑都写在代码里,你能直接在软件代码中看到它。但当你在做智能体时,你的应用如何工作的“逻辑”,并不全部在代码里,其中很大一部分来自模型本身。
这意味着:你不能只看代码,就判断智能体在某个具体场景下会做什么。你必须真的把它跑起来。而我认为,这就是最大的不同:我们引入了这种非确定性系统,它是一个黑箱,它在代码之外。我觉得这就是核心差异。
一个直接后果是:为了弄清楚应用到底在做什么,你不能看代码,你必须看它在真实运行中做了什么。这也是为什么我们做的产品里,最受欢迎的之一是 LangSmith。LangSmith 的一个核心能力是 tracing(追踪/执行轨迹)。为什么 trace 这么受欢迎?因为它能把智能体每一步内部发生的事情都清清楚楚地展示出来。
而这跟传统软件里的 trace 又不一样。传统软件里,你的系统在那边跑,它会吐出很多日志和事件;你通常是在出现错误时才去看,而且你不需要“每一步的全部细节”。而且本地开发时,你可能直接打个断点就够了;很多时候日志追踪是上线到生产环境后才会更重度开启。但在智能体里,人们从一开始就会用 trace 来理解“底层到底在发生什么”。
而且它在智能体里的影响力,远大于在单一 LLM 应用里的影响力。因为在单一 LLM 应用里,如果模型回答得不好,你知道你的 prompt 是什么,也知道输入上下文是什么(由代码决定),然后你得到一个输出。
但在智能体里,它在循环中运行、不断重复。你并不知道第 14 步时上下文里到底有什么,因为前面 13 步可能会把任意东西拉进上下文。所以,“上下文工程(Context Engineering)”真的是一个非常好的词。我真希望这是我发明的。它几乎完美描述了我们在 LangChain 做的一切——只是当时我们并不知道这个术语已经存在。
trace 的价值就在于:它能直接告诉你此时此刻上下文里到底有什么,这太重要了。那这又意味着什么?这意味着:对传统软件来说,“真相的来源(source of truth)”在代码里。但对智能体来说,真相来源变成了代码与 trace 的组合——而 trace 是你能看到真相的一部分地方。
从技术上说,真相当然也“存在于模型的数百万参数里”,但你基本没法直接对参数做什么。所以现实上,trace 就成了你可以抓住的“事实载体”。
因此,trace 也会成为你开始思考测试的地方。你仍然可以对 harness 的某些部分做单元测试,也可以离线做一些 unit test,但要获得真正的测试用例,你很可能需要用 trace 来构建。而且在智能体里,在线测试(online testing) 可能比传统软件更重要,因为行为不会在离线环境里完整显现出来,只有在真实世界输入驱动下、系统被真正使用时,行为才会“涌现”。
我们也看到 trace 正在成为团队协作的中心:如果出了问题,不再是“去 GitHub 看代码”,而是“去看那条 trace”。我们在开源项目里也一样。有人说:“Deep Agents 这里跑偏了,发生了什么?”我们的第一反应是:“把 LangSmith trace 发给我们。”如果没有 trace,我们基本没法帮你 debug。过去大家会说“把代码给我看看”,但现在已经转变了。
这就是我写在 X 上那篇文章的核心内容,反馈很好。我也还在琢磨怎么把它表达得更精确,但我觉得这一点很关键。
另外一个点我也还在继续想:我觉得构建智能体是一个更偏迭代式的过程。
我们过去也会这么说,但我以前会有点翻白眼,因为软件开发本来也是迭代式的:你发布、收反馈、不断迭代,这就是软件开发的常态。但我觉得差别在于:在传统软件里,你的迭代是围绕“你希望软件做什么”来进行的。你有一个想法,你发布,你收反馈。比如“这个按钮让人困惑”,或者“用户其实想做 X 而不是 Y”。但你在发布之前,其实你是知道软件会怎么运行的。
但在智能体里,你在发布之前并不知道它到底会怎么做。你当然有一个预期,但你并不能在发布前真正确定它会做什么。因此,为了让它更准确、让它更“对”、让它能通过某种“概念上的单元测试”,你需要更多轮次的迭代。
在这个基础上,我也认为记忆(memory)非常重要。因为记忆就是在从这些交互中学习。如果你的开发过程变得更迭代、更难,那么作为开发者,我为了让系统表现正确,可能需要反复改系统 prompt——这种频率甚至可能比我改代码还高。
这就是记忆进入的地方:如果系统能够以某种方式自己学习,那就能减少开发者必须进行的迭代次数,让构建这类智能体变得更容易。
所以,这是我认为“构建智能体确实不同于构建软件”的另一个角度。我也承认,这么说有点老套,所以我一直在逼自己想清楚“到底不同在哪里”,目前我总结出来的就是这两点。
主持人:我也很想追问这一点。现在公开市场上有一个很大的争论:现有的软件公司还能不能熬过去?如果类比当年从本地部署软件(on-prem)转向云(cloud),实际上真正成功转型的公司并不多,因为事实证明,“做云软件”和“做本地软件”确实差异很大。你现在处在“人们如何用 AI 构建产品”的核心地带。你怎么看这件事?
我不是要问公开市场的投资问题,而是想问:这个变化到底有多大?你有没有看到很多人:过去很擅长“旧方法做软件”,现在也能很擅长“新方法做软件”?还是说更像是:你要么在“新方法”里长大,要么就很难真正理解它?你觉得人能跨越这个鸿沟吗?
Harrison Chase:我注意到现在有很多年轻创始人,这让我觉得,也许年轻人因为没有太多对“旧软件开发方式”的先入之见,反而可以更快把这些东西学起来、用起来。而且我们确实一再听到一个现象:很多在做 agent engineering 的团队成员,反而是更初级的开发者、更初级的构建者——他们确实没有那些先入之见。我们内部的应用 AI 团队,确实整体更偏年轻一些。我觉得这里面既有“人的因素”,也有“公司的因素”。
先说公司层面:数据依然非常非常非常有价值。如果你从 harness 的角度去看——顺便说一句,我其实不认为长期来看大多数人都会自己去写 harness,因为它比做 framework 难太多了。所以我觉得大家最终会用我们提供的 harness,或者用别人的。
那一个 harness 里面有什么?主要就是:prompt、指令,以及它连接的工具。而现有公司在这方面最大的资产之一,是他们已经拥有数据和 API。如果你过去在这块做得不错,那么把这些东西接入到 agent 上,其实会非常容易产生真实价值。
我们前阵子和金融行业的人聊,他们就说:数据的价值只会越来越高、越来越高、越来越高。所以如果你是一个传统软件厂商,你手上有这些高价值数据,你应该能够把它暴露给智能体,让智能体去用,从中拿到很大的收益。
不过这里还有另一部分:关于“如何使用这些数据”的指令(instructions),这一块可能更偏“新增”。
你作为软件厂商也许一直对“怎么用这些数据”有一些想法,但你并没有把这些想法系统化、固化成可执行的“操作说明”,因为过去这件事更多是由人来完成的——很多智能体现在在做的事情,本来就是人类会做的事情。
你当然会给人配工具,但你以前不会、或者也很难成功地把它完全自动化。而到了“智能体”这一代,这部分才真正变得可行。所以我觉得这块是新的。
我们也看到大量需求来自“垂直领域创业公司”。Rogo 就是一个很好的例子:他们团队有人有金融行业经验,把这种行业知识带进了智能体系统里,而这之所以有效,是因为很多智能体的驱动力来自“知识”——但不是那种通用世界知识,而是如何执行特定流程、特定模式的知识。
所以问题就变成:做传统软件的人是不是做智能体的合适人选?我觉得我们确实看到很多非常资深的开发者在采用 agentic coding,所以某种程度上这更像是“心态问题”。但确实也可能会呈现出一种“年轻化倾向”。而公司层面,则很大程度取决于它手上的数据资产。
主持人:所以看起来,你认为 trace 是这个新世界里 agent 开发的核心“产物”,LangSmith 在这方面帮助很大。那你觉得还有哪些核心的“产物”——或者说,可能“产物”这个词不对,应该说组件(components)?
Harrison Chase:对,组件。我觉得构建软件与构建智能体之间另一个差异是:评估软件时,你可以相当可靠地依赖程序化测试和断言。但智能体做的很多事情,本质上是“人类会做的事情”。因此要评估它,你必须把人的判断引入进来。
这也是我们在 LangSmith 里努力解决的问题之一:你已经有了这些 traces,那么你怎么把人类判断带到 traces 上?最直接的方法当然就是:把人引进来。所以我们也看到数据标注类创业公司做得很好。我们在 LangSmith 里有一个概念叫 annotation queues(标注队列),就是把人带进来参与。因此,实际的、真实的人类判断,是其中非常重要的一部分。
主持人:这里的“人工标注”的 trace,比如,智能体做了这些步骤,这是好还是不好。
Harrison Chase:有时候,人会给自然语言反馈:这很好、这很差、这里应该怎么做。有时候,人会直接“纠正它”:把正确步骤完整地写出来。这具体怎么做取决于用例,而且对做 RL 的模型公司,和对做 agent 应用的公司来说,也可能不一样。但核心就是:把人类判断带进来。
同时,我们也看到另一条路:尝试为这种人类判断建立一些“代理指标”(proxy)。这就是 LLM-as-a-Judge 这类方法的来源:你可以跑一个 LLM 或其他模型,让它承担某种“类似人类判断”的角色,去给那些本来需要人类判断的东西打分。
我们一直在思考的一件事是:怎么让“构建 judge”这件事变得容易。因为 judge 的关键很大一部分在于:它必须和你的人的判断、人类偏好保持一致。如果做不到,那你的 grader(评分器)就很糟糕。
所以我们在 LangSmith 里做了一个概念叫 align evals:人类先去标注一些 traces,然后基于这些标注,构建一个 LLM judge,使它在这些样本上被校准(calibrated)。
因为关键就在于:你要把人类判断引入进来;如果你要用 proxy 来替代它,那就必须确保这个 proxy 校准得足够好。
主持人:有意思。我记得我们最开始和你做业务合作的时候,还在邮件里讨论过:LLM-as-a-Judge 到底是否可行。看起来它已经进步很多了。
Harrison Chase:是的。LM-as-a-Judge 其实有几个不同层面的用法。
最常见的一种,是用于 eval:拿一条 trace,直接给它一个分数,比如 1 到 0,或者 0 到 10。这个我认为是可行的,而且很多人确实在做。他们会离线做,也会在线做,因为有些判断并不需要 ground truth(标准答案)。
但我觉得另外一个更重要的场景,是你在 coding agents 里也能看到的:coding agent 往往会先工作到某一步,然后遇到错误,触发纠错。它实际上是在“评判自己刚才做的工作”。我们也在 memory 上看到同样的模式:记忆很大一部分就是反思 traces,然后更新某些东西。所以问题是:LLM 能不能去反思 traces——无论是它自己的 trace、以前 session 的 trace,还是别人的 trace?我觉得完全可以。我们在 eval、纠错、记忆里到处都能看到这种模式,本质上其实是一回事。
Eval 是 RL 的奖励信号,还是工程反馈机制?
主持人:我明白了。那接下来就很自然会问:你有了所有 traces,也有了 eval。那么这些 eval 到底是什么?它是强化学习的 reward signal?还是一种反馈机制,让工程师去改进 harness、让 agent 工程师去优化 harness?
Harrison Chase:因为现在大家都不再手动写太多代码了,大家都在用这些 agent 工具。我们观察到一个很重要的模式:我们有一个 LangSmith MCP,也有 LangSmith fetch(一个 CLI)。因为 coding agents 特别擅长用 CLI。你把这些给智能体,它就能把 traces 拉下来,诊断哪里出了问题,然后把这些 traces 带进代码库里,从而修复它。这是我们正在看到的真实模式,而且我们非常非常非常想支持这种模式。
所以在这一点上,相比“用 eval 做强化学习奖励信号”,我对“把 eval 当作工程反馈、用于改 harness”的路径更乐观——至少对今天做 agent 应用的公司来说是这样。
主持人:这听起来像是递归自我改进啊。
Harrison Chase:我觉得是,但还是有一个人类在环。
回到前面那个点:当它产出“初稿”时效果最好——它改 prompt,然后人类 review,这能让系统保持不跑偏。但我们确实……我们最近发布了 LangSmith Agent Builder,这是一个 no-code 的 agent 构建方式。其中一个很酷的功能就是 memory。
现在 memory 的工作方式是这样的:当你和 agent 交互时(注意它还不是后台自动跑的那种;它不会自己拉 traces),如果你对它说:“你不该做 X,你应该做 Y”,它就会去改自己的指令——这些指令本质上就是文件——然后直接编辑这些文件。这样未来它就会按新的方式表现。
这也是一种“自我改进”的形式。我们确实还想加入另一种机制:比如每天晚上跑一次任务,查看当天所有 traces,更新自己的指令。
主持人:就是那种“做梦”的机制。
Harrison Chase:对,“睡眠时间算力(sleep-time compute)”。
记忆与自我改进会成为护城河吗?
主持人:我们再多聊聊未来。你现在最兴奋的是什么?听起来你聊了很多 memory。
Harrison Chase:我很看好 memory。我觉得让智能体去改善自己,这非常酷,而且在很多场景下也很有用。
但也不是所有场景都用得上。比如 ChatGPT 加了 memory 功能,我其实用得不多,我也不觉得它显著增加了我对产品的粘性。我觉得原因之一是:我去 ChatGPT 时,大多数问题都是一次性的。我不太会反复做同一件事:我可能问软件,也可能问吃的、旅行……都很零散。
但在 agent builder 里,你通常是为特定任务构建特定工作流。比如我有一个 email agent。而且我其实……它已经给我发邮件两年了。我之前在 agent builder 之外就有一个 email agent,它带有 memory。后来我们做了 agent builder,我想把它迁移进去,但它没有我之前的那些 memories。即便它的起始 prompt 一样、工具也一样,但因为缺了记忆,它现在的体验就明显差很多。我到现在都还没完全切过去,因为它现在确实不如之前那个好用——说白了,它现在“有点烂”。
当然,如果我持续和它交互,它会变好,它会不那么烂。但这也恰恰说明:memory 可能会成为真正的护城河(moat)。而且我绝对相信,我们已经到了一个阶段:LLM 可以看 traces,然后改变自己代码里的某些东西。问题在于:怎么把这件事做得安全、并且在用户层面可接受。但我认为,在一些特定场景里(不是所有场景),我们会越来越多看到这种能力。至于 ChatGPT 这种通用聊天产品,我仍然不确定这种形态的 memory 是否有用,至少目前我不确定。
主持人:你觉得和长时序智能体一起工作的 UI 会如何演化?
Harrison Chase:我觉得大概率需要同步模式(sync)和异步模式(async)。
长时序智能体运行时间可能很长,默认应该是异步管理:如果它要跑一天,你不会一直坐在那里等它结束。你很可能会启动一个、再启动一个、同时跑很多个。所以这里会涉及到异步管理:我觉得像 Linear、Jira、看板,甚至 email,都可以作为 UI 设计的参考——如何去管理一堆异步运行的 agent。
但与此同时,很多时候你又会想切换到同步交流。因为 agent 最后给你返回一份研究报告,你可能需要立刻指出:它这里写错了,你要给反馈。聊天界面在这方面其实已经挺不错的。
我唯一想补充的是:现在很多 agent 不仅是在“对话”,它还会去修改文件系统里的文件。所以你必须有一种方式去查看“状态”(state)——也就是它改了什么。
这在编程领域尤其明显:IDE 依然被使用,是因为当你想手动改代码时,你需要看见那个“当前状态”。即便我启动 Claude Code,它跑完后,我有时也会打开来看它到底写了什么代码。所以“能看到状态”这件事很重要。
Anthropic 在 Claude “co-work”(这里指那类协作式工作流)里做了一个很酷的设计:你设置它时要选择一个目录,等于你在告诉它:“这就是你的环境。”
这在编程里当然也是常态:你打开 IDE 到某个目录。但我觉得把它明确成一个心智模型很有帮助:这就是你的 workspace(工作区)。
这个 workspace 也不一定非得是本地目录:它可以是 Google Drive、Notion 页面,或者任何能存储状态的地方。你和 agent 就是在这个状态上协作:你启动它,让多个任务异步跑;然后切到同步模式,在 chat 里和它讨论,但同时你还能看到它正在协作的“状态”。这就是我目前看到的形态。
主持人:所以这也就是你说的“agent inbox”的想法:为了进入 sync 模式,agent 需要能联系到你。
Harrison Chase:对,没错。我们大概一年前发布过 agent inbox,理念是“ambient agents”:它们在后台跑,必要时来 ping 你。但第一版其实没有 sync 模式:它 ping 你,你回一句,然后你就等它下一次再 ping 你。
但很多时候,我切到邮件去回复它时,我其实只回很短的话,而且我不想再切出去然后干等——我(对方)很重要,所以我更想直接进入一种“同步对话”的模式,跟 agent 把这个问题当场聊完。所以我们后来做了一个关键改动:当你打开 inbox 时,会直接进入 chat,而 chat 是非常同步的。这是一个很大的 unlock(突破点)。
我现在认为:只有 async 模式,目前还不太够。也许未来如果 agent 强到你几乎不用纠正它,那么纯异步会更可行。但至少现在,我们看到人们在 async 和 sync 之间来回切换。
主持人: 你怎么看 code sandboxes(代码沙箱)?是不是每个 agent 最终都会配一个 sandbox?也包括“能用电脑”、能上网用浏览器这种能力?
Harrison Chase: 这是个特别好的问题,我们也一直在想。就目前的经验来看,“写代码/跑代码”这条路明显比“直接操作浏览器”更成熟、更好用。
所以短期内,如果要在这些能力里挑一个最可能成为标配的,我更看好的是代码执行(code execution)——也就是给 agent 一个能安全运行脚本、验证结果的环境。
另外,文件系统(file system)我几乎是“坚定派”:不管是本地目录、还是背后用数据库实现的“虚拟文件系统”,agent 总得有个地方能存状态、存中间结果、随时回查,这对上下文管理太关键了。比如:
做 compaction(上下文压缩)时,把完整内容丢到文件里,需要再查就去读;
工具调用返回特别长时,不塞进上下文,改成写文件、让 agent 自己按需读取。
至于“coding”(让 agent 真正去写代码),我没那么绝对,但我大概 90% 站在“需要”这一边。因为很多长尾任务里,写脚本依然是最通用、最强的手段——你很难找到同等级的替代品。
当然也可能出现另一类场景:如果你做的是高度重复、流程固定的事情,未必每次都要写很多代码;但即使这样,文件系统仍然重要,因为重复流程会不断产生上下文和状态,你还是要做上下文工程。
再说浏览器使用(browser use):从我们目前看到的效果来说,模型还不够稳定。也许可以让 coding agent 通过 CLI 的方式“间接”完成一些浏览器相关任务(算是一种近似解),我确实见过一些挺酷的实现。
而所谓 computer use(直接操作电脑界面)则更像是介于两者之间的混合形态,目前还有不少不确定性。
所以总结一下:我非常喜欢 code sandboxes,我觉得它会成为 agent 能力栈里很关键的一块。
主持人:太棒了。Harrison,真的非常感谢你今天来参加节目。你一直都能在 agent 这条路上看到未来,能和你聊“上下文工程如何演化到今天的 harness 与长时序智能体”,真的特别过瘾。感谢你推动这个未来,也感谢你一直愿意和我们聊这些。
Harrison Chase:谢谢邀请。我希望未来还能再来一次,然后证明我今天说的全部都是错的。因为预测未来真的很难。
参考链接:




