
Nodeless技术可以让企业从节点的运维及管理中脱身,有效避免同节点 pod 互相影响,甚至是容器逃逸到节点上等情况,让用户集中精力在应用的开发上。文章将分享社区 virtual kubelet+kata 方案在公有云场景下落地的诸多局限性,以及腾讯在 nodeless 弹性容器技术上的创新与突破。
本文整理腾讯云高级工程师吴尚儒在DIVE全球基础软件创新大会 2022的演讲分享,主题为“公有云安全容器设计:腾讯nodeless弹性容器技术演进和实践”。
分享主要分为四个部分展开:第一部分是经典Kubernetes集群的问题;第二部分会介绍开源 virtual kubelet+kata 方案的探索;第三部分内容为腾讯云弹性容器服务 EKS 解决方案;第四部分则是腾讯云弹性容器服务 EKS 落地实践。
以下是分享实录。
经典 Kubernetes 集群架构
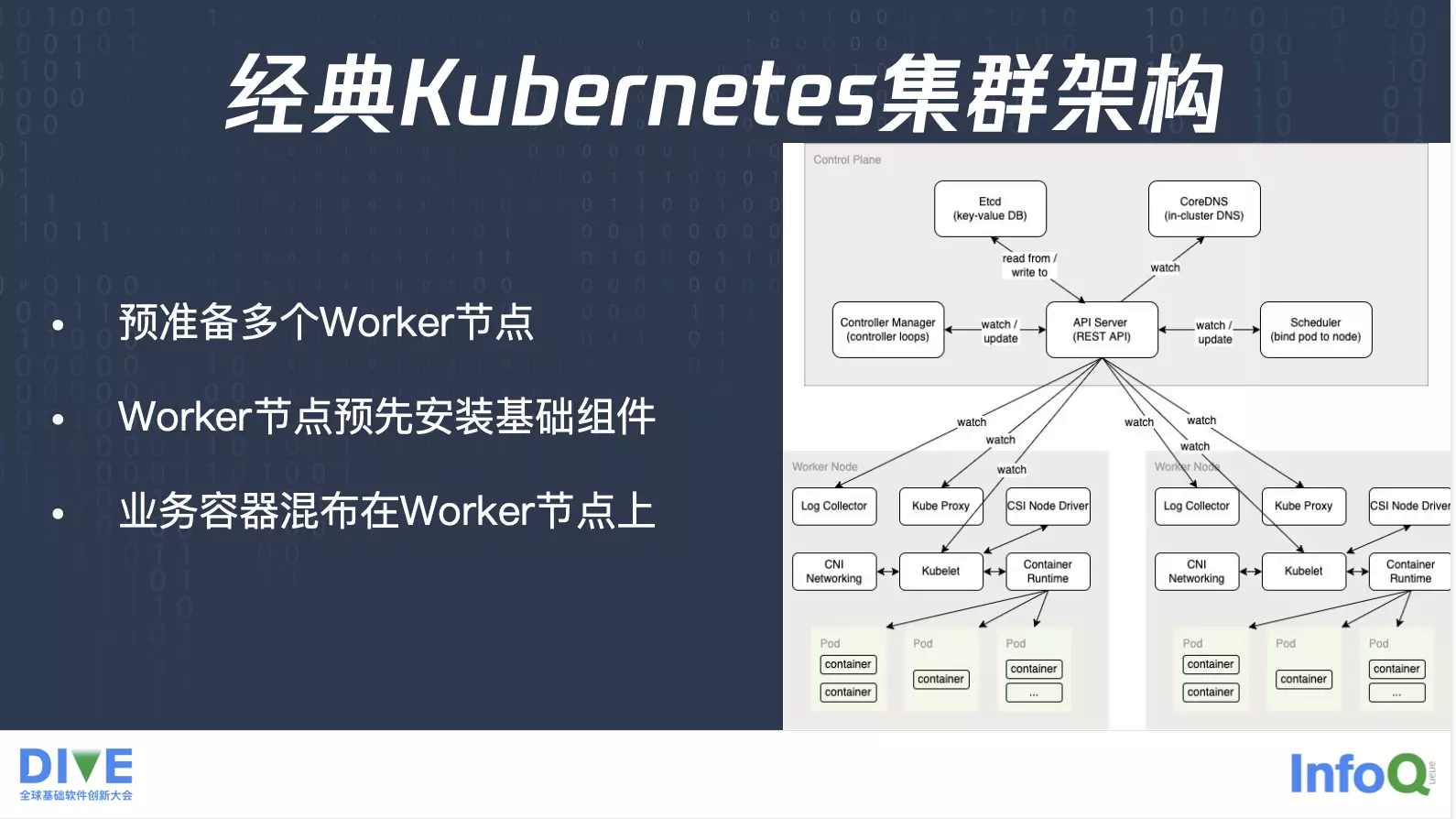
这是一个经典的 Kubernetes 集群的架构,会有一些控制面的组件如API Server,以及调度器 Scheduler,控制器Controller Manager,还有存储 etcd。除了控制面之外,还会有数据面 Worker 节点,在这些 Worker 节点上,会预先安装基础组件比如说 kubelet、Container Runtime 以及一些 Daemon Set,业务将工作负载提交到 API Server 之后,由 Scheduler 发现业务 Pod,并将 Pod 调度到合适的 Worker 节点,之后由kubelet负责将业务 Pod 启起来。这时候业务的容器会混布在 Worker 节点上面,不同业务之间可能会在同一个 Worker 节点。

这里面带来的第一个问题就是,集群里有节点,那就肯定要做一个节点的管理,特别是节点资源的规划问题。
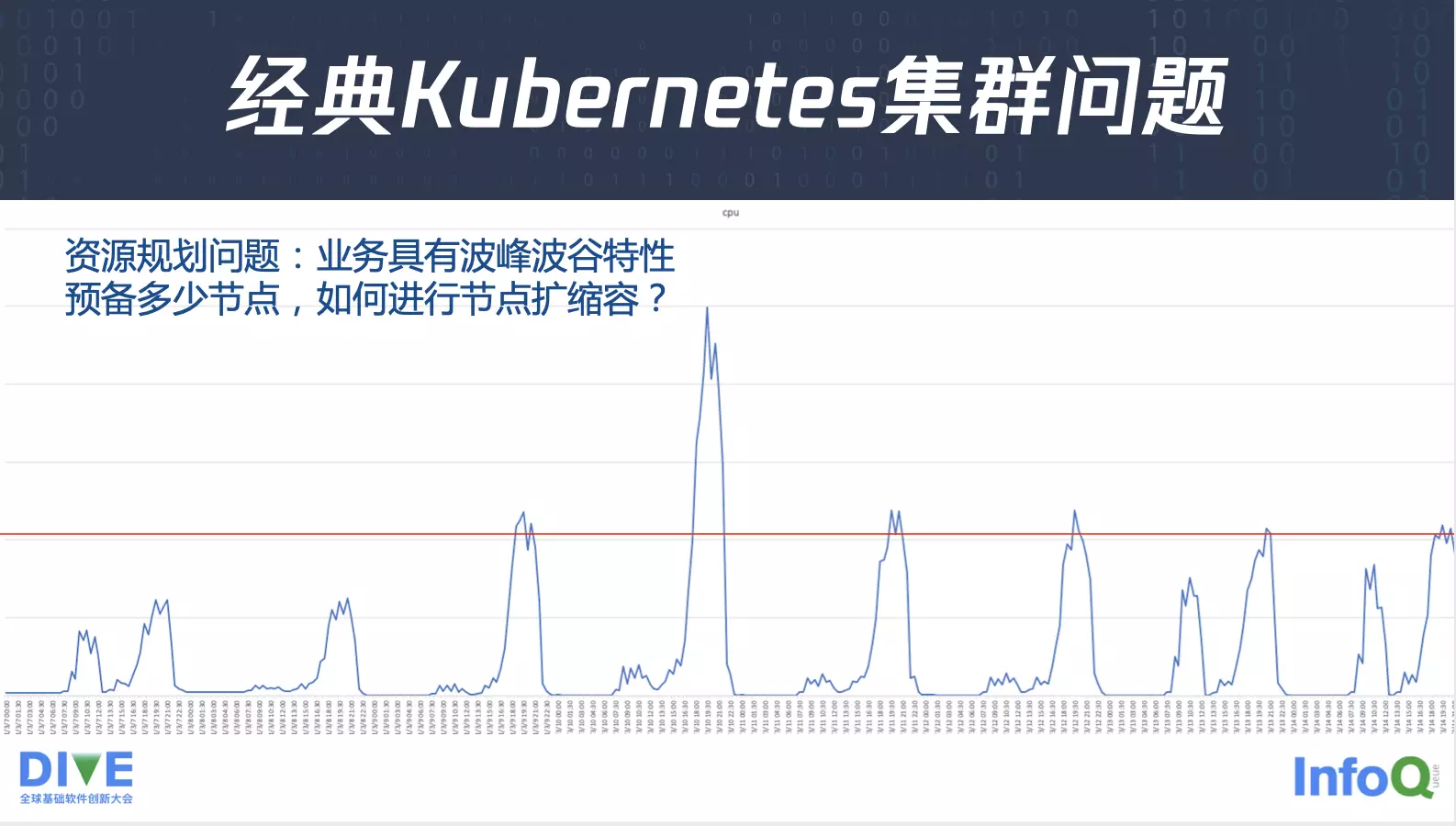
这是某个服务的 CPU 的使用量,从这张图我们可以看见这个业务有一个特别的特点,就是它会有个波峰,有个波谷,时不时 CPU 用量会有激增,也会降为 0。但是它又不是简单的重复,比如说今天这个时间点有 CPU 的突增,明天的这个时间点却没有对应的用量,但是过了几天之后业务量又会有个突增。另外业务峰值也不固定,按照平常情况来说,峰值可能是 2000 核左右,但是它会在某一个时刻忽然翻倍,达到了 5000 核这样一个量。

所以说这里面就涉及到一个问题:什么时候得进行扩缩容?业务并不是简单重复的,所以要提前在合适的时间点进行扩缩容。另外要规划给业务准备多少节点,按照平时的峰值的准备,如果它忽然有个突增,短时间内达到翻倍,这时候增量部分基本上就资源可以运行了。这就是节点带来的资源管理的问题。另外,节点本身有一个维护的问题,节点会有内核,会有 OS,这时候涉及到比如说安全问题需要修复,需要更新内核,需要更新 OS。同时节点会有容器运行时,这时候涉及到 Bug 的修复,版本的管理,还有一些节点本身运行的 Kubernetes组件,比如说 kubelet 组件,这时候 Kubernetes 集群也需要做升级。只要集群规模上了一定量之后,这种节点内核的升级,运行时的变更以及组件的维护就不可避免,这时候会变得非常麻烦。
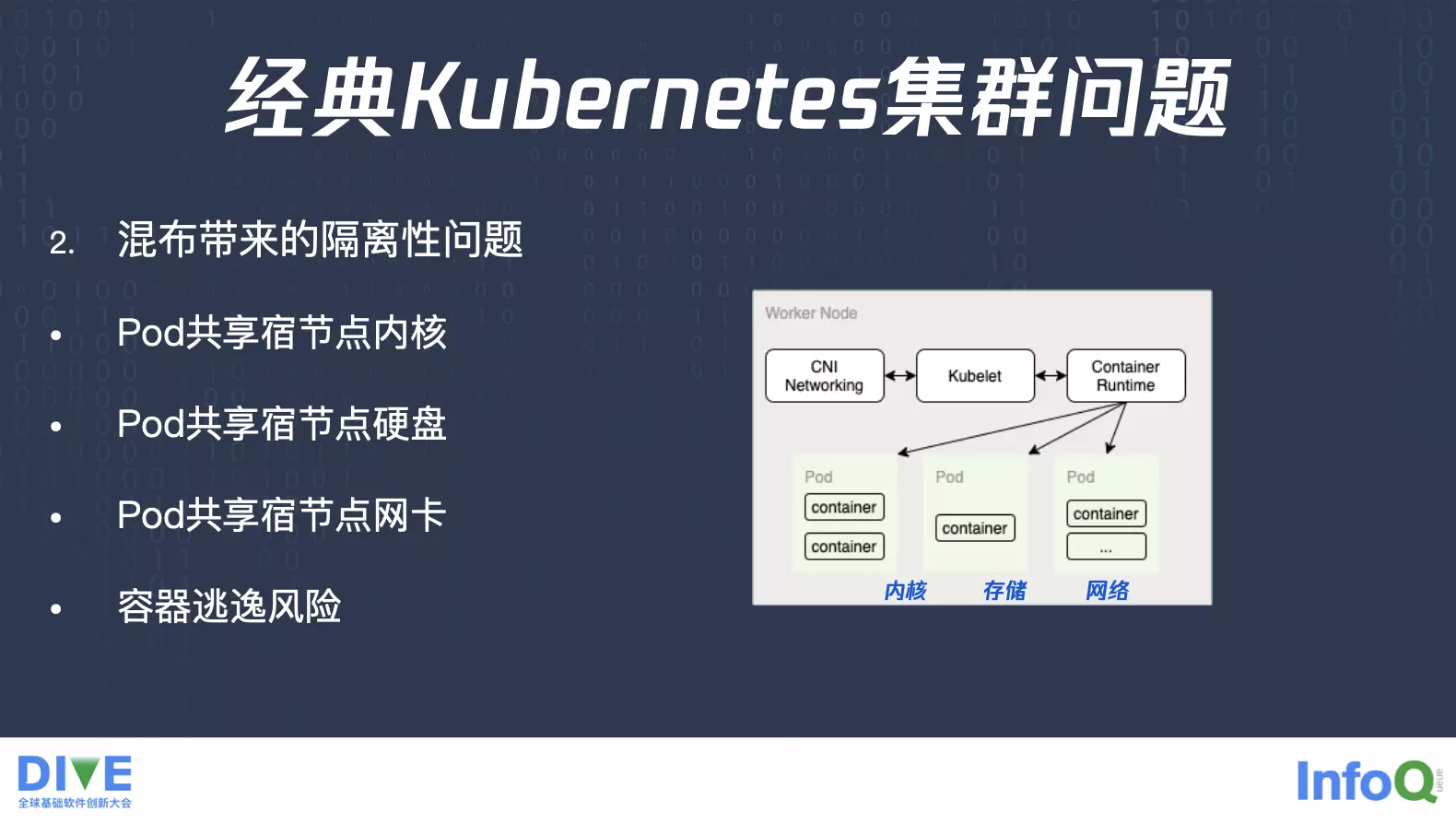
除去节点问题之后,还有另外一个就是业务混布带来的隔离性的问题,同一个 Worker 节点上面可能会混布不同的业务 Pod,这些业务 Pod 都会共享节点的内核,共享节点的硬盘,以及共享节点网卡与网络。那么共享节点会带来什么问题?比如说有些 Pod 需要开通加载某些内核模块,一些网络的模块,但是加载这个模块就对它自己有用,对其他的业务没有用,而且网络模块可能会带来收发包的拆解,会影响其他业务的网络性能,这是一个对内核的诉求。
同时还有一些内核的参数,比如说 Socket Buffer 这些配置都需要去改参数的,不同的业务会有不同的需求。另外一个就是存储,这些 Pod 它们的临时输出或者是标准输出,都会散落到这个节点上面的硬盘上面去,并且是共享同样的存储,这个时候有些业务如果它的输出的速率大于其他的业务,或者是它频繁地输出,这时候整个存储性能就会被它占用。
同时还有网络,有些业务收发包比较快,因为它使用了大量的 UDP 的小包,这个时候包量达到了整个机器的收发包的限制之后,其他业务网络性能就会受到比较大的影响。除去这些共享的内核、存储、网络之后,还有个容器逃逸的风险,假设我在 Volume 里面如果有办法逃逸,我就可以跳到父目录,再往上父目录,多跳几层父目录,这时候就可以跳到这个节点上面的根目录 rootfs,就可以看见节点上面所有的文件了。
开源 virtual kubelet+kata 方案探索

针对前面提到的问题,我们先来看看开源社区有哪些解决方案,首先刚才提到节点管理的问题,开源社区确实有个方案virtual kubelet,它是将一个虚拟节点添加到一个经典的 Kubernetes 集群里面,这个虚拟节点上面对应着一个大的资源池,所以说落到这个虚拟节点上面 Pod 对应着后端的资源池就会比较大,这时候就少去了刚才提到的那种节点资源的管理,你可以理解为它后端对接的是一个伸缩弹性更强的资源池。

对于隔离,开源社区有个比较成熟的方案,kata containers安全沙箱方案,原本不同容器之间是会共享内核,共享 CPU、内存、网络、存储,这时候在 kata 方案上,它会先在物理机上构建出安全沙箱,然后每个 Pod 运行在单独构建出来的安全沙箱里面,每个 Pod 会有个单独的内核。
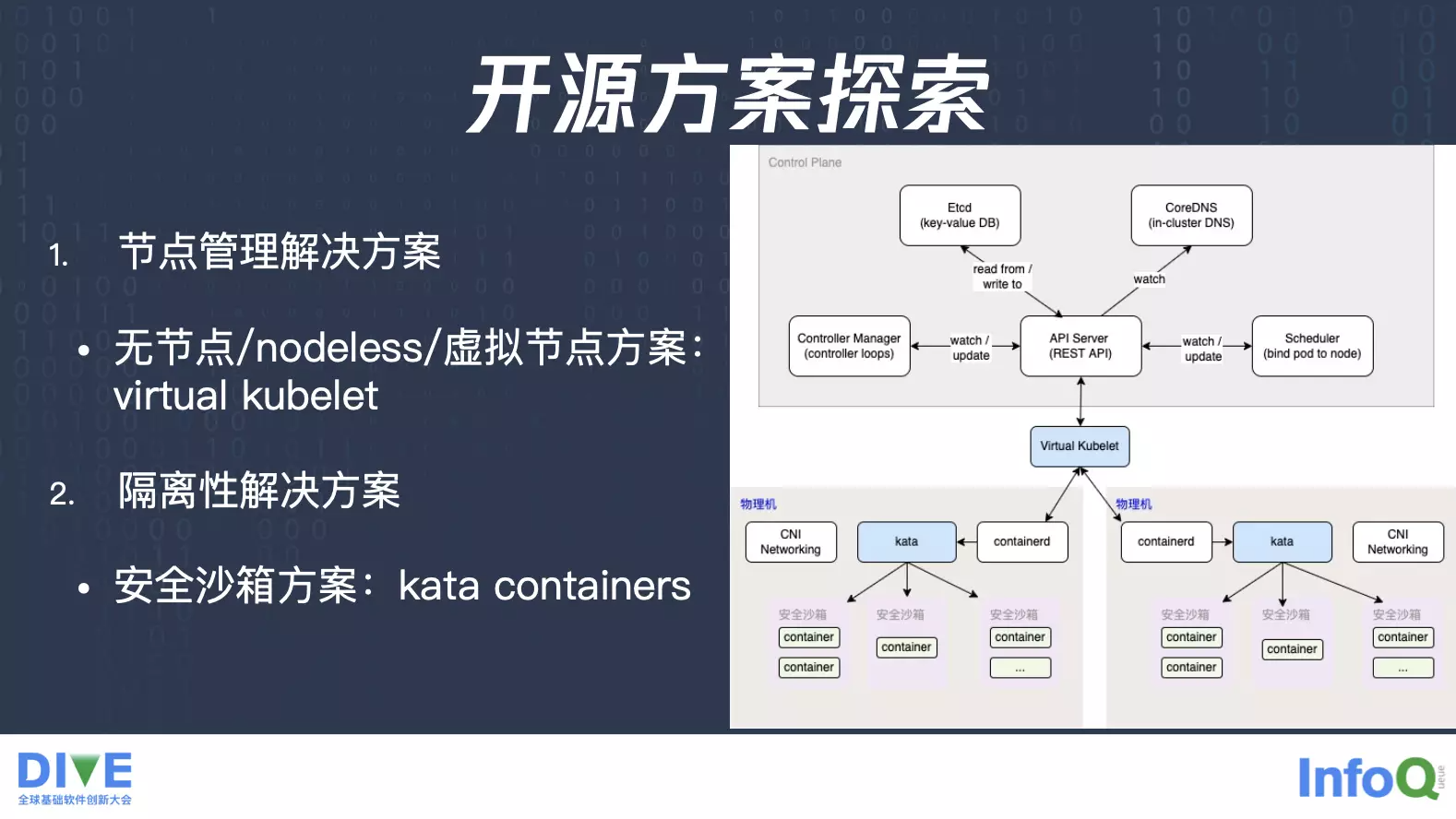
有了这两个开源方案之后,我们就可以做一个初步的探索,就相当于是我们通过 virtual kubelet 把所有的节点上面 kubelet 抽取出来,统一在一起,屏蔽了后端的资源池,搭建了一个虚拟节点。假设有个 Pod 调度到虚拟节点,我们就通过 virtual kubelet 去选择合适的物理机,把 Pod 落到有空闲资源的物理机上,业务本身就少去了一个节点资源的管理,由平台来直接对接所有的物理机池。然后对于隔离性,当 Pod 落到了物理机上的时候,上面的 kata 启动对应的安全沙箱,这时候也可以达到一个隔离性的目的。

这个 virtual kubelet + kata 的组合方案,看起来确实可以解决我们提到的问题,但是在实际落地上,却有诸多挑战,特别是在公有云场景上面。首先公有云有一个特点就是多租户,每个租户处在不同的私有网络下面,就类似于这张图,这是一个用户的私有网络 VPC,它的 API Server 就落在 VPC 里面,然后这个虚拟节点就要去承载上面 Pod 的创建,这个虚拟机节点位于用户的私有网络内。物理机位于底层的基础网络,containerd 跟 kata 是负责创建安全沙箱的,它们要位于物理机上,所以肯定就是位于基础网络,但它们创建出来的安全沙箱,里面的业务又要位于用户的私有网络,这样才可以达到公有云多租户的场景。第一个问题,就是确保私有网络的隔离性,又能满足创建容器时所需的网络打通,这里会带来一些挑战。

除去了因 kata 落在底层物理机上,带来的这样一个网络打通的挑战,本身 kata 方案在公有云上面,也会有一些挑战。首先运行时 containerd 在物理机基础网络里面,拉容器镜像也就需要在物理机的基础网络上面去实现。但拉镜像会有很多场景,不仅仅是云上的镜像,还可以去拉外部的镜像,或者是用户 VPC 里面的自建镜像仓库,这时候在物理机的基础网络里拉镜像,怎么样才可以打通外部网络或者是用户的 VPC 内网络?这是第一个问题。
当拉完容器镜像之后,镜像也是在这个物理机上的。这时候通过这个镜像会构建一个容器的 rootfs。然后再由物理机透传或者共享到安全沙箱里面,本质相当于是这个容器的 rootfs 还是在物理机层面,只是透传到容器里面去的,容器的 IO 操作还会传导过来的。另外,容器本身运行还会产生一些标准输出,这时候这些标准输出也会落在这个物理机上面,对于日志采集会有挑战,日志采集到了之后,还需要发送到用户部署在私有网络上面的 Kafka,这还涉及到一个网络的打通的问题。所以在公有云场景下,整体来说会有一些些弯弯绕绕。
另外就是这个容器的 rootfs 映射到安全沙箱里面,现在社区比较推荐的方案是 virtiofs,它对物理机的内核是有要求的,也就是说它会比较挑物理机,使用面会比较窄。另外这些安全沙箱虽然也说是个虚拟机,但是它并没有办法复用虚拟机热迁技术,因为它的状态,还是跟 kata、跟 containerd 这些跑在物理机上的组件,是有强关联的。安全沙箱里,容器运行过程中需要的一些数据,还是由运行时 containerd 存储在物理机层面的,并不是跟物理机完完全全独立的。所以说想要做热迁,单纯通过虚拟机的方式来迁移是不够的,还有一些关键的信息要做迁移。整体来说,它对于原本的物理机的运维带有一定的挑战。我们发现这些原因后,总结一点就是 kata 这种方案还不适合公有云。它可能更适合私有云,但它还不适合公有云多租户场景。
腾讯云弹性容器服务 EKS 解决方案
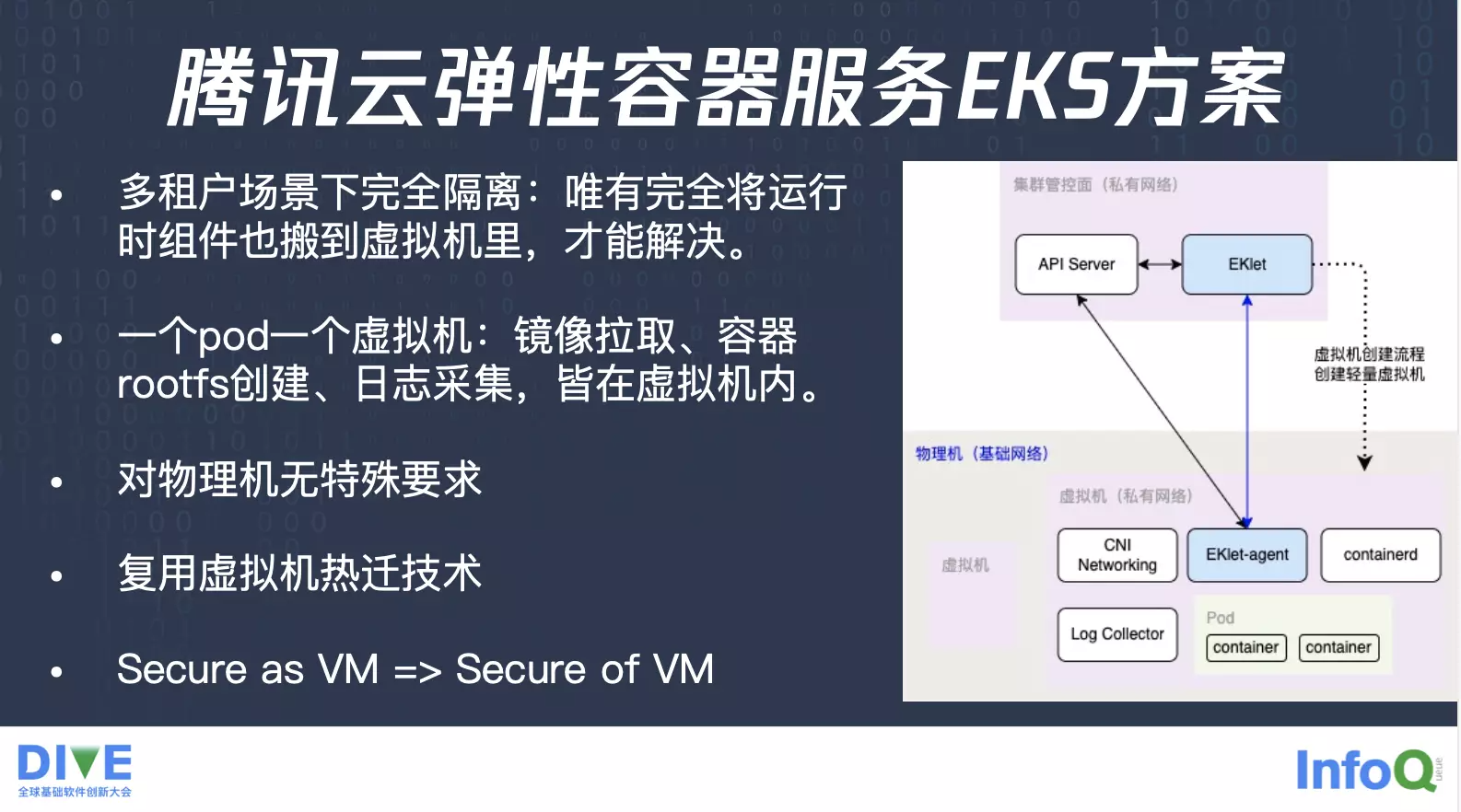
我们自研了一套解决方案,想要在多租户场景下面做到完全隔离,必须要把运行时全部搬到虚拟机里面来,相当于是在虚拟机里面有一套完完整整的运行时的组件,在物理机上面不做共享,这时候就可以做到完完全全的隔离,一个 Pod 一个虚拟机。
首先我们刚才提到的镜像拉取的过程,因为我们已经在虚拟机里有一个 containerd,所以说它拉取镜像的时候,就是在用户的私有网络里面进行拉取的,整个流程就跟原本拉取方式没有区别。并且拉取完之后,rootfs 落在这台虚拟机里面,虚拟机只要 mount 到容器里面来,做一个 overlayfs,就可以给容器使用了,也不存在从物理机共享到虚拟机里边这种情况,另外日志采集组件也可以部署在用户的私有网络底下。
所以整体来说就解决了刚才提到的问题,并且它已经对物理机没有任何的特殊要求了,就是只要这台物理机能够创建虚拟机就可以了,至于刚才提到的宿主机的组件,物理机的内核都已经没有这个需要了,而且它也没有额外的其他的依赖在物理机上面,可以直接复用原本成熟的虚拟机的热迁技术,整个方案来说就从原本的像虚拟机一样安全,直接就变成虚拟机层面的安全。
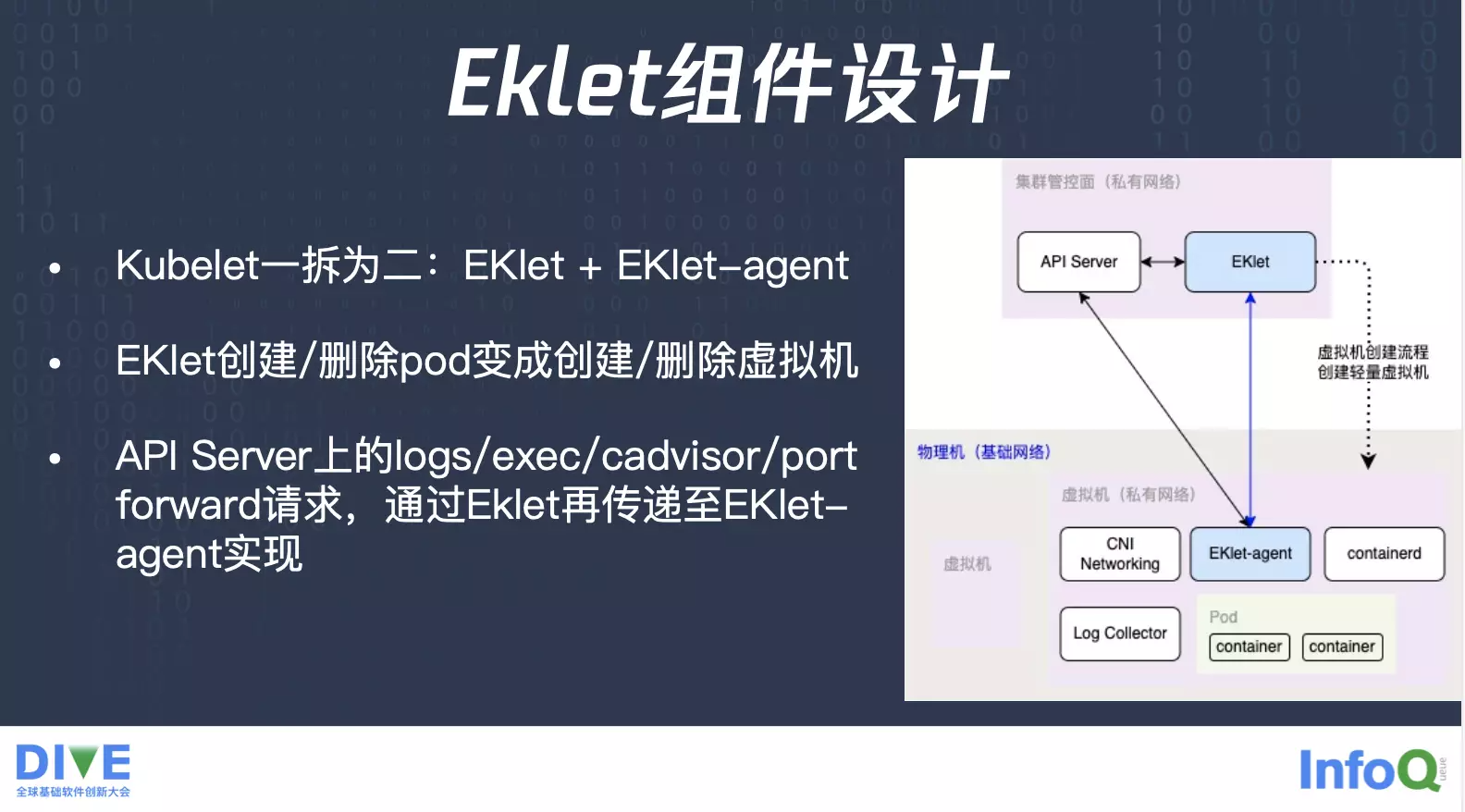
我们有了这样一个方向之后,就看下我们的具体设计,首先比较重要的组件就是 kubelet,Pod 生命周期的管理,所以说我们又想把它做成一个虚拟节点,肯定是需要把 kubelet 的一些功能能抽取出来,就是我们把 kubelet 拆成了两个,一个叫 EKlet,一个叫 EKlet-agent。EKlet 用来连接 API Server,并且承载所有的 Pod 的删除以及创建,每个 Pod 的删除创建我们把它转变成一个创建或者删除轻量虚拟机的流程,也就是说我们一开始的时候没有任何的虚拟机资源,直到你需要一个 Pod 的时候,这时候你调度到了一个虚拟节点,虚拟节点会帮你快速地去启对应的一个虚拟机出来,在上面再去启对应的 Pod。
所以说这个虚拟节点对接的还是刚才提到的物理机资源池,按需创建对应的虚拟机,并且原本 Kubernetes 里边通过 kubelet,实现了那些 logs/exec/cadvisor/port forward 请求,会通过 API Server 传导到 EKlet,再通过 EKlet 传递到 EKlet-agent 来实现。
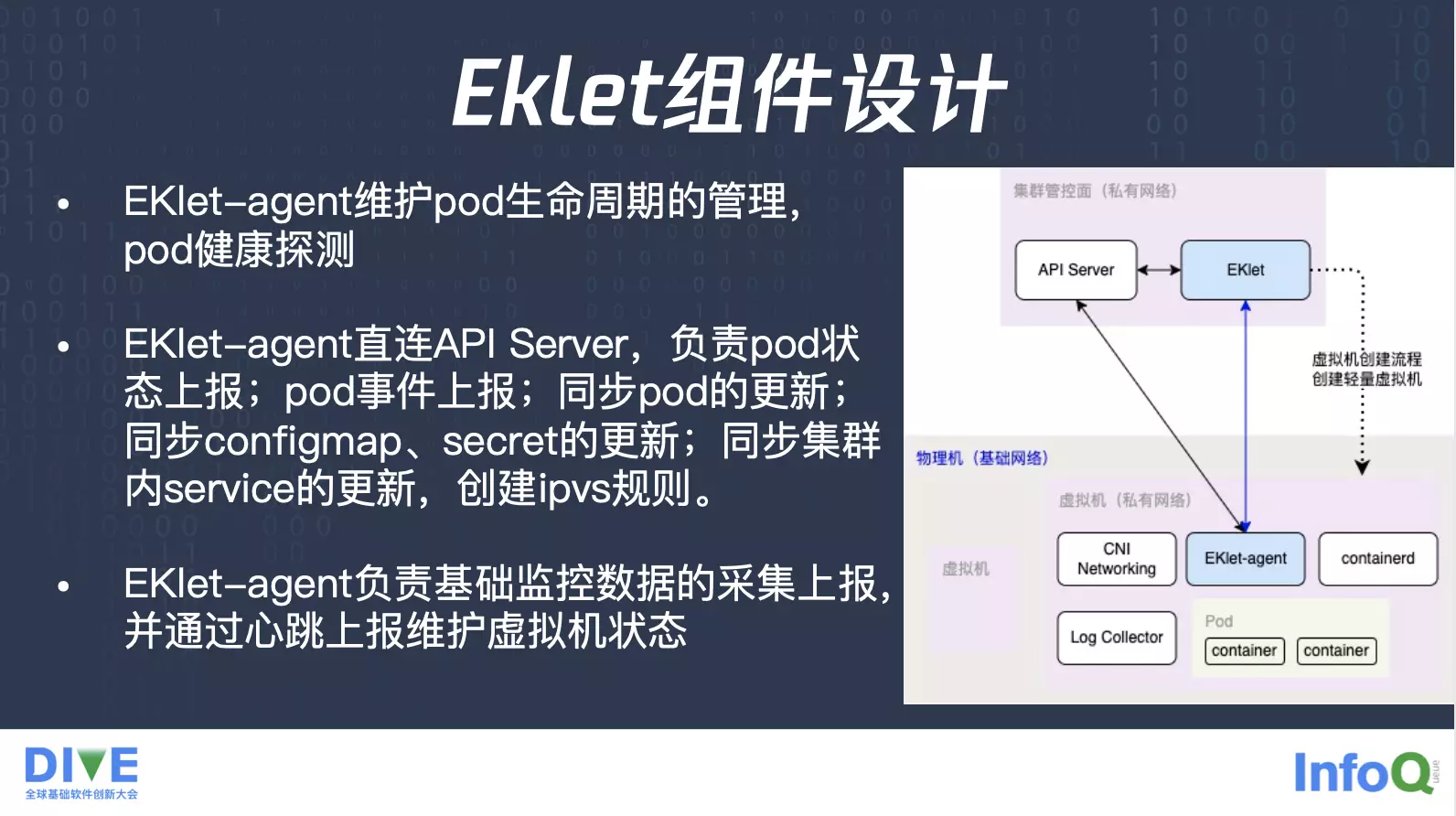
这个是 EKlet 组件的设计,主机里面的 EKlet-agent 它就是相当于你创建完虚拟机之后,要真正启 Pod 的时候,由它来负责。它类似于 kubelet,有一部分功能是由 EKlet 来实现,大部分功能会由 EKlet-agent 来实现。Pod 的生命周期管理,Pod 的健康探测,这些 kubelet 的功能都在 EKlet-agent 这边实现,并且它本身也可以直连 API Server,负责 Pod 状态上报,比如 Pod 启动了,Pod 运行终止了,或者是 Pod 的事件上报是通过 EKlet 直达 API Server,同时 Pod 有更新,它也可以通过 API Server 去 Watch 到这个 Pod 更新,做对应的变更。
当然,还有 Pod 启动的时候所需要的 configmap、secret,以及所需要的集群网络 service 的更新就是全部由 EKlet-agent 来实现,并且监控数据的上报也是由 EKlet 来实现。另外也有一个比较重要的点,就是原本的话,节点是要维护一个状态的,但是现在我们没有一个固定的节点,只有虚拟节点,每个 Pod 本身都需要维护自己一个状态,我们是通过 EKlet-agent 上报心跳来维护这台虚拟机的状态。
整体流程就相当于是你有一个 Pod,然后落到了虚拟机上面去,之后虚拟节点就会按需创建出来对应的虚拟机资源,在这个虚拟机资源,通过类似 kubelet 的操作把这个 Pod 启起来,并且把这个信息上报给 API Server,完成了一整套流程。那么当你在销毁的时候,这边 EKlet-agent 会先把这个 Pod 的一个资源给你销毁,并且上报了状态之后,到 API Server 之后,EKlet 看见就会销毁对应的虚拟机。

除去刚才整个 Pod 生命周期之后,还有个特点就是我们的网络方案比较特别,首先 Pod 会直接使用虚拟机这张网卡,所以说流量就可以直通 Pod,没有宿主机转发的损耗。
但是我们的 Pod 并没有使用 host network,它本身跟 EKlet-agent、containerd 的网络还是隔离的,用了不同的网络命名空间,这么做的好处是因为要想要避免业务容器变更,比如说 iptables 对于这些管控面组件的影响。典型的场景如 Istio,Istio 大家知道它会有个 Init Container,它启动的时候就会涉及到 iptables,把所有的流量转到 Sidecar 上面去,之后才开始启动 Sidecar 以及业务容器,就是业务容器启动完之后,它的流量就会先通过 Sidecar 再往外发。
但是在假设使用 host network 的场景,Init Container 启动完之后,就会改一个 iptables,把所有的流量转发到 Sidecar,但这个 Sidecar 还没启动,并且这个 Sidecar 启动的前提是先需要去拉镜像,containerd 去拉镜像的时候会碰到这个 iptables 规则,就会把这个流量转发到这个还没启动的 Sidecar,Sidecar 还没起来,就会报 Connection refused,也就说你永远拉不了镜像,但是 Init Container 又改了 iptables,整个流程就相当于是卡住了。我们做到了这样一个隔离,这时候就不用担心业务容器里面做任何的修改会影响管控面组件的流量。

另外因为整个虚拟机是一个轻量虚拟机,所以说我们对里面的运行操作系统是有个特别的优化的,首先内核是基于 tlinux 5.4 内核,同时会优化一些启动速度,比如说磁盘加密,随机数生成的这些模块的加载,同时会内置这些常用的日志采集组件,云上的采集组件,以及业务所需要的 GPU 驱动,还有各类文件存储的客户端组件,这些组件会按需开启,让业务可以无需去很完整加载这些组件的时候就可以达到开启的效果。另外因为整个虚拟机就只有业务这样一个容器,业务这样一个 Pod,特权模式也是可以支持开启的,用户可以通过特权模式去变更内核参数。

整个 EKS 的架构刚才提到了,它是一个 Pod 的虚拟机,做到一个虚拟机层面的完全隔离,做到 Secure of VM,Pod 间就再也没有干扰了,不同 Pod 间处在不同的虚拟机底下,Pod 对特权模式的依赖,或者是内核参数的修改,就完完全全放开了。
另外的话,我们也支持 hostpath,虽然这个 hostpath 跟原生的 hostpath 会有一点点出入,原生的 hostpath 是你在同一个节点上面可以通过 hostpath 通讯,现在是你在同一个虚拟机节点上面通过 hostpath 是不能通讯,但是我们还是支持 hostpath 这样一个功能。
除此之外,一个 Pod 一个虚拟机,所以说你也可以直接获取到真实的 CPU 了,就不会像 Go Runtime 或者是 Java JDK 里面,会根据宿主机的核数取到对应的 CPU 数。另外这种场景更适合多租户场景了,就像刚才提到的,kata 创建了一个虚拟机是会有限制的,因为它本身在宿主机上面还有一些文件,它对物理机也有要求限制,需要物理机的内核版本是多少,还会在物理机上面去共享一些东西,这个时候通过一个 Pod 一个虚拟机方案,我们更适合那种多组户的场景下的完完全全隔离。
除去安全性,这里还有个弹性的目的,就是只有在 Pod 创建的时候,我们才对应创建一个虚拟机资源。由于整个虚拟节点对接是云上的资源池,它只有在真的需要创建资源的时候,慢慢才会去创建对应的虚拟机,没有需要去预先准备固定的节点,另外每个 Pod 起来都是一个单独的虚拟机,计费方式也可以不一样,比如说你有些虚拟机是可以按竞价实例来计费,这些都可以支持的。另外性能跟云服务器一致,因为它本身就是一个虚拟机,并且它的流量是直通到业务容器里面的,是没有额外的转发跟损耗的。
另外的话也是我们刚才提到了,我们就相当于是把 kubelet 的功能分在两个地方,但是并没有说去拆解它,它的兼容性跟原生 k8s 是一致的,除了一些节点相关的,比如虚拟机节点是没有 IP,所以 node port 这种场景下,就没有节点 IP 可转发了。除去节点相关这种特性,其他特性都是复用原生 kubelet 这套逻辑,所以是兼容的,这是整个架构的优势。

当然对比一下经典 k8s 还是有一些地方不同,比如说单 Pod 启动速度,因为弹性容器服务的 Pod 每次启动前都需要创建一台轻量虚拟机,这时候如果是冷启动,什么东西都没有,单纯从头开始创建一台虚拟机,整个启动时速度会比经典的 k8s 慢十几秒。
我们也有些优化的措施,比如说通过保留沙箱的方式来启动,这时候会有有效地提升启动速度,虽然单 Pod 的启动速度会慢一些,但好处是在批量 Pod 启动的时候,比如说刚才提到那种从 2000 核到 5000 核这样的一种突增,这样情况下面在 EKS 上面你是不需要去扩容节点,因为它后面对接的就是整个云上资源池,它立马就可以批量启动这些 Pod,如果你使用原生经典的 Kubernetes ,你就需要先去添加节点,这时候添加节点的流程是分钟级别的,并且要添加多个节点才可以去启动 Pod。虽然在单 Pod 启动速度上面会慢,但是我们有一些优化措施来提升速度。
腾讯云弹性容器服务 EKS 落地实践
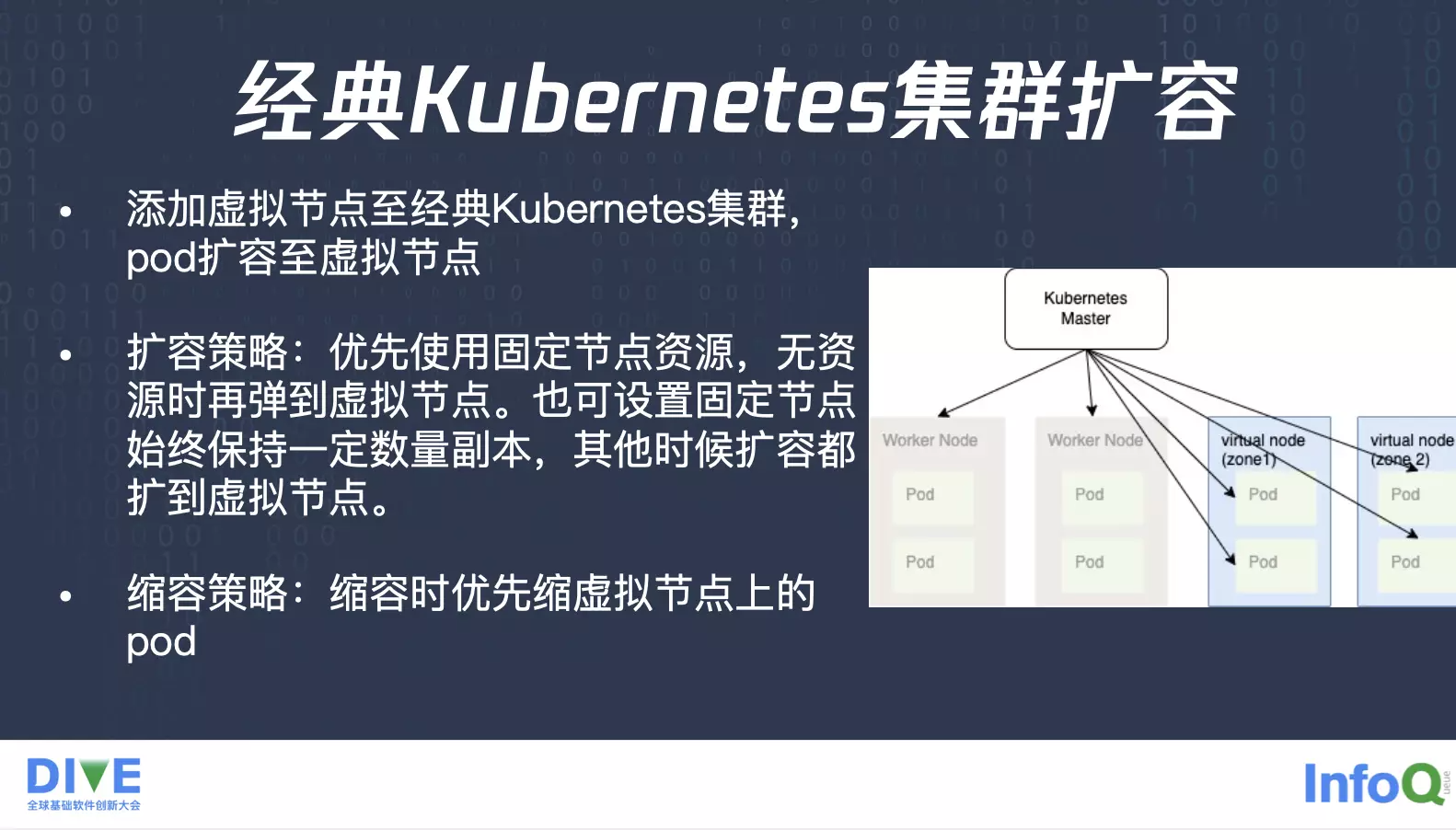
最后我们看一下落地实践的过程,首先最主要的实践过程就相当于是通过虚拟节点的方式,把弹性容器服务加入到经典的 Kubernetes 集群里面,比如我们就把整个可用区加到这个集群里面,就相当于是这个经典 Kubernetes 集群里面对接了后面整个可用区的资源池,扩容的时候就可以让业务优先使用固定节点下面的资源,直到固定节点上面没有资源池了,它再弹到虚拟节点上面来。
另外我们也支持,让业务设置它只在固定节点上面保留一定的数量的副本,业务并不一定非得要等到把整个固定节点资源耗尽,它还是希望留些 Buffer,但是它本身每个业务就有一些固定的量级,就相当于这些固定的数量的业务就保留在固定的节点上面。扩容的话,剩下的扩容的副本就跑到虚拟节点上面去,缩容的话,优先缩虚拟节点上的,这时候就可以充分利用固定节点上面的资源,这是我们提供的多种扩缩策略。

另外我们也会对原生的一些组件进行一个修改,首先是控制器,因为就像刚才提到,虚拟节点本身上报健康情况,但是虚拟节点状态的不健康其实不应该引发 Pod 驱逐,因为每个 Pod 已经是独立出来了,我们是通过一种心跳的方式来维护每个 Pod 本身的状态。
另外调度器也会做一个感知,原本调度器是感知到每个节点上面的资源,但现在整个调度器对接的是可用区资源池,它要做到可用区资源的感知,并且默认会做一个跨可用区打散的部署,充分去利用不同可用区的资源。另外刚才提到的每个 Pod 会占一个私有网络的 IP,所以说调度器也要去感知 IP 资源。除此之外创建的话也可以让业务去指定,按照某些机型顺序去创建,比如说有一些可以优先 AMD,有一些优先 Intel 来创建,并且在资源不足的时候我们是有实现了一个重调度的功能,相当于是在某个可用区上面发现资源不足的时候,我们会帮你换个可用区重试。
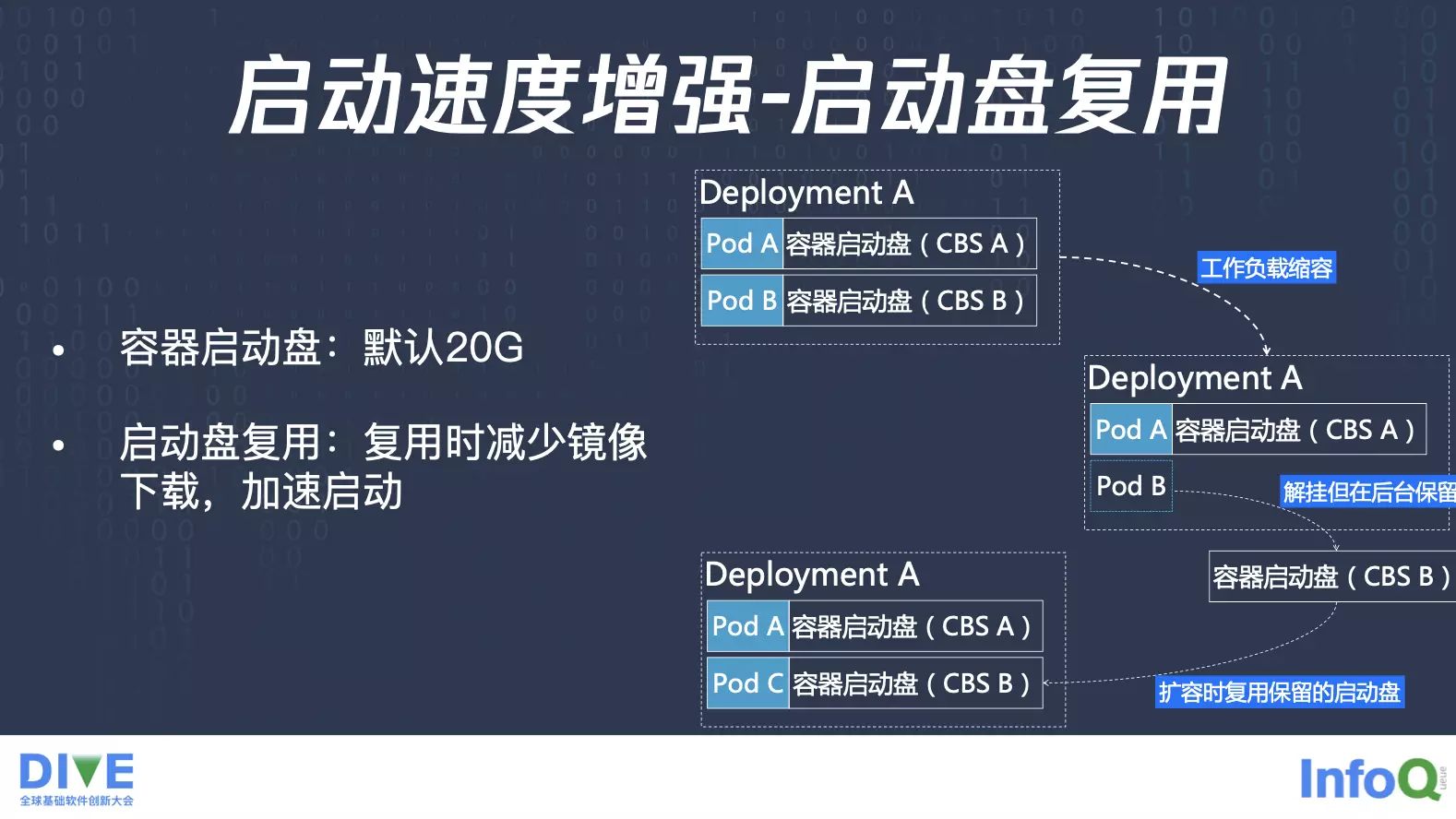
除此之外还有另外一个问题是跟固定节点相比,固定节点上面可以先去拉镜像,但是你在虚拟节点上面每次启动都是一个 Pod 一个虚拟机,这个虚拟机里面是没有镜像的,启动速度肯定会更慢,对于这种拉镜像的过程,我们有几个解决方案。首先是默认会启用的方案叫做镜像盘复用,假设你这个 Deployment 有两个副本,Pod A 跟 Pod B,它们本身就会各启一个镜像盘,之后你在滚动更新的时候,比如 Pod B 销毁了,这时候它对应的镜像盘我们在后台保留,启动下一个 Pod C 的时候,我们帮你把镜像盘挂载进来,Pod C 启动的时候,就发现这个盘上已经有那个镜像了,可以少去镜像拉取的过程,做到加速启动。
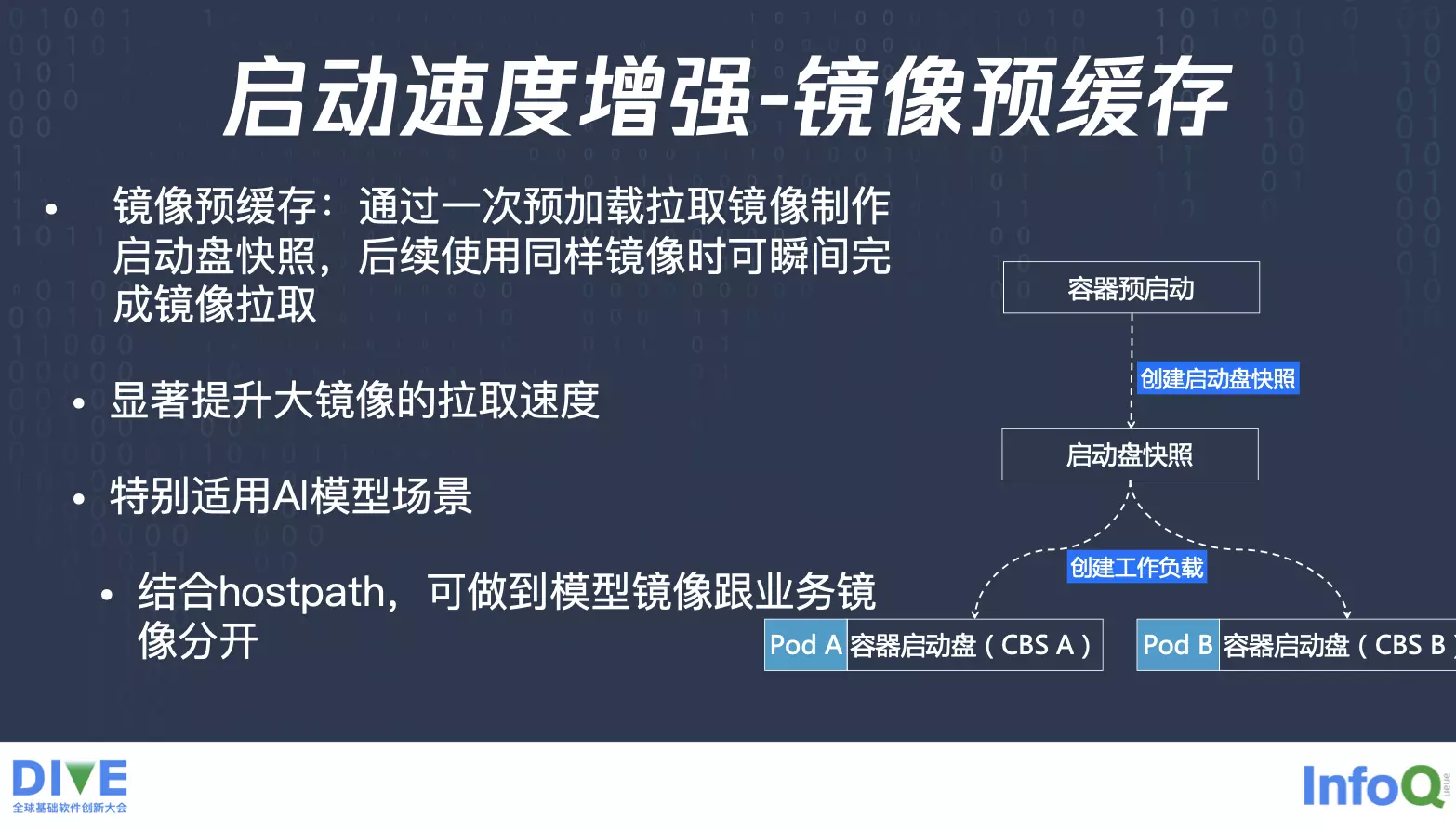
当然这种情况只能是对于有预热的过程,如果说对于冷启动,我们还有另外一个方案就叫做镜像预缓存,就相当于是一开始你推送镜像的时候,我们就会先在云上先给你预加载,做一次拉取镜像操作,拉取完之后,就会对于那个盘做一个快照,之后会生成快照 ID,你下次启动的时候就可以拿这些快照 ID 去创建对应的启动盘,这个启动盘就包含你刚才已经推上来的镜像,整个过程下来,启动的时候就相当于是瞬间完成镜像的拉取,会显著提升启动速度。
而且结合 hostpath 之后会有一个很特别的效果,就是 AI 场景下面有些业务会把模型跟业务算法镜像分开,打两个镜像做版本管理,模型是一个镜像,业务是一个镜像,这时候启动的时候,如果模型跟业务算法并没有打在同一个镜像里,业务算法容器要怎么才能读到模型镜像里的数据呢?虽然两个镜像都已经拉到了启动盘上面了,但是 overlayfs 时互相看不见的,即便用了 share volume 这种方式,本身还是需要做一个拷贝,才可以将模型数据共享到业务容器。这时候就可以结合 hostpath 来做,因为模型镜像的模型数据已经拉到了对应的磁盘上面了,只要去找到那个目录,这时候做一个软链给到业务镜像,业务镜像就可以直接去这个目录上面读了,这也是虚拟节点上,需要使用到 hostpath 的一个场景。

解决了这个镜像的拉取之后,当然还是有一个问题,相较经典的 Kubernetes 集群,还需要去创建轻量虚拟机,我们还提出另外一个优化,就是保留沙箱的一个功能,在没有保留沙箱情况下面,你每次创建的时候都要新建一个轻量虚拟机,启动速度肯定是会比固定节点来的慢。通过保留沙箱就相当于是你第一次创建完之后,销毁之后我们帮你把这个沙箱保留,在下一阶段创建一个新的 Pod 时候,我们就去复用这个沙箱,你就少去了一个轻量虚拟机创建的一个动作,整个 Pod 启动就可以达到秒级启动了,这个就是我们在启动速度方面做的一些实践。

因为弹性容器有个特点,就是即用即销毁,销毁完之后底层资源也就跟着销毁了,有时候需要去排障,需要去看日志,就会找不到,除去日志采集之外,还可以通过原生的 terminationMessagePolicy,将退出日志保留在 terminationMessagePolicy 上面去,除此之外,我们也提供延迟销毁的能力,就是 Pod 退出之后保留底层资源一段时间,这时候就可以方便排障。

另外,就是一些 Annotation 的定制了,比如说固定节点上面,你想要去改 DNS 服务器,你想要去改内核参数,或者你想要去改运行时的一些配置,这时候你登到固定节点上面去做相应的操作就可以了,虚拟节点上面已经没有节点这个概念了,所以说我们就可以通过 Annotation 的方式,实现跟固定节点一样的操作过程,相当于是在固定节点上面常见的需要做一些配置,我们通过 Annotation 暴露给用户。在 Pod 启动之前,我们就会对 Pod 所在的宿主机进行相应的初始化,达到相应的效果。另外因为 Pod 本身就是虚拟机,我们更推荐用安全组的方式来实现 network policy,相当于是每个 Pod 或者是 Deployment 你可以绑对应的安全组,这时候你就可以达到你想要的 network policy 方案。
总结

整体来说,今天从经典的 Kubernetes 集群开始讲起,经典 Kubernetes 集群涉及到节点管理的问题,以及节点上面混布带来的隔离性问题,之后探索了开源社区对应的解决方案,发现开源的方案在公有云上多租户场景是有很大挑战的,特别是探索 kata 方案后,发现它会更加适合私有云场景,还不适合公有云场景。
所以我们就提出了自研的方案,我们的这个方案复用了成熟虚拟化的技术,做到完全网络的隔离、IO 隔离、内核隔离,并且我们在实现过程之中,兼容了整个 Kubernetes 逻辑,虽然会对它做改造,但是只是把功能拆分,并没有做功能删减,所以它会完全兼容除节点相关的 Kubernetes 特性,兼容特权模式。
当然我们这样的方案,会带来一些跟固定节点不一样的,比如说镜像的预拉取,以及虚拟机的启动这些额外的操作,所以提供一个镜像盘的复用,以及镜像预缓存的这样的功能,去对齐固定节点,并且通过保留实例的方案来提高启动速度。另外本身固定节点上面可以做的操作,我们是通过 Annotation 暴露给用户,所以说可以达到同样的效果。
后续除了进一步优化启动速度外,我们还会在节点相关的特性上发力,做到 Kubernetes 节点特性的对齐。




