
最近,Cloudflare 宣布在R2 SQL中支持聚合功能。这是一个新特性,使开发者可以通过 SQL 查询存储在 R2 中的数据。这一功能增强使得 R2 SQL 不再局限于基本的过滤功能,而是可以在不依赖单独的数据仓库工具的情况下,更好地满足分析工作负载的需求。
R2 SQL现在支持 SUM、COUNT、AVG、MIN 和 MAX,以及 GROUP BY 和 HAVING 子句。这些聚合函数使开发者可以直接在 R2 上通过 R2 数据目录运行 SQL 分析,快速汇总数据、发现趋势、生成报告以及识别日志中的异常模式。除了聚合之外,本次更新还引入了模式发现命令,包括 SHOW TABLES 和 DESCRIBE。
Cloudflare 资深软件工程师Jérôme Schneider、高级软件工程师Nikita Lapkov和高级产品经理Marc Selwan总结道:
无论是生成报告、监控大量日志中的异常,还是仅仅试图发现数据中的趋势,现在你都可以在 Cloudflare 提供的开发者平台上轻松完成所有这些工作,而无需管理复杂的 OLAP 基础设施或将数据从 R2 中移出。
CloudZero 研究主管 Jeremy Daly 在他的新闻资讯中评论说:
通过在 R2 SQL 中支持聚合,Cloudflare 继续将数据推向边缘,扩展了开发者可以实际在边缘运行的工作负载类型。
图片来源:Cloudflare 博客
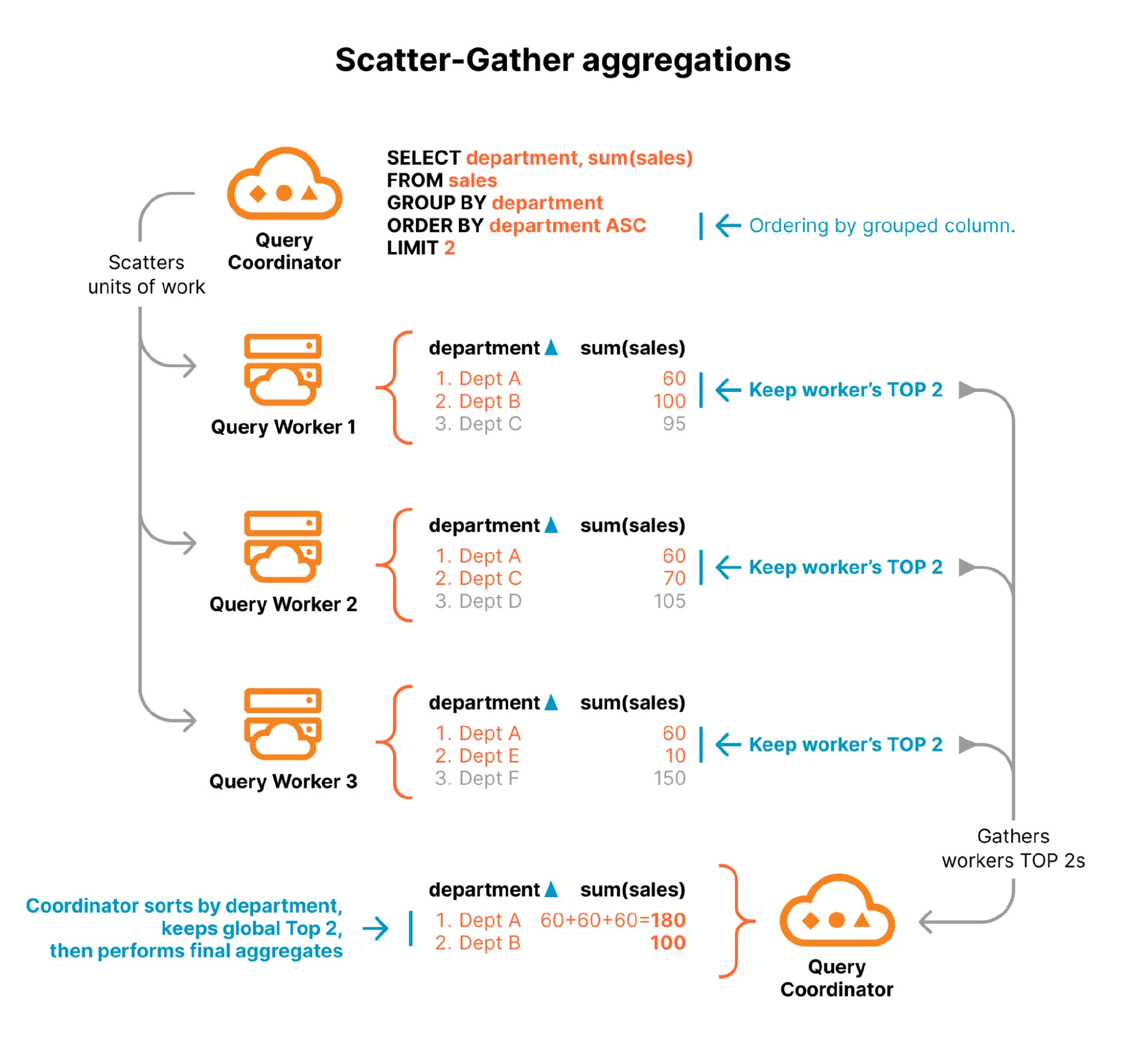
Schneider、Lapkov 和 Selwan 阐述了他们如何使用 scatter-gather 和 shuffling 策略构建分布式 GROUP BY 执行,以便直接在 R2 数据目录上运行分析:
不包含 HAVING 和 ORDER BY 子句的聚合查询可以用和过滤查询类似的方式执行。对于过滤查询,R2 SQL 会选择一个节点作为查询执行的协调者。这个节点会分析查询并查看 R2 数据目录,以便确定哪些 Parquet 行组可能包含与查询相关的数据。每个 Parquet 行组代表单个计算节点可以处理的相对较小的工作量。协调节点将工作分配给多个工作节点,收集结果后返回给用户。
Cloudflare 还单独宣布,R2数据目录现在支持Apache Iceberg表的快照自动过期,完善了自动压缩——通过将小数据文件合并成比较大的文件来优化查询性能。Selwan评论道:
这两者是相辅相成的,因为快照过期所带来的一系列元数据清理/管理操作能够提高这些聚合查询的执行效率,在启用了压缩功能的情况下更是如此。
这家超大规模云服务商最近发布了一篇深度解析文章,详细阐述了其分布式查询引擎的工作原理。
由于 R2 SQL 仍处于公测阶段,所以支持的 SQL 语法可能会随着时间的推移而变化。文档页介绍了当前存在的限制和最佳实践。
原文链接:
https://www.infoq.com/news/2026/01/cloudflare-r2-sql-aggregations/




