
介绍过去几年来,随着深度学习库与软件创新成果的蓬勃发展,机器学习问题的研究已经成为令人兴奋的热门议题。大多数库从负责处理大量密集问题的专业计算代码演变而来,其中自然也包括将图像分类为通用框架以构建起能够为稀疏模型提供间隔支持的神经网络模型。
在 Netflix 公司,我们的机器学习科学家们需要立足广泛领域应对各类复杂问题:从根据您的喜好作出针对性影视作品推荐,到优化编码算法等等。作为实际任务中的一部分,我们需要处理极为稀疏的数据资源——尽管每一次观察到的非零项数量非常有限,但待处理问题的总体维度数量却往往会轻松达到数千万级别。
在这样的背景之下,我们认为有必要开发出一款专门针对单一设备、多核心环境的轻量库,并针对浅前馈神经网络的训练进行专门优化。我们希望相关成果拥有体积小、易于调整等特点,而 Vectorflow 项目正是由此而生,并成为 Netflix 内部机器学习科学家们常用的重要工具之一。
开源地址:
https://github.com/Netflix/vectorflow
设计考量 **** 敏捷性我们希望数据科学家能够以全自治方式轻松运行并迭代其模型。因此,我们决定用 D 语言编写 Vectorflow——这是一种现代系统语言,且提供较易接受的学习曲线。凭借着高速编译器与函数编程能力,其可为新人们提供类似于 Python 的使用体验,但同时亦可将性能水平提升几个数量级。
另外,经验丰富的开发人员亦能够利用其出色的模板引擎、编译时功能以及低级功能(例如 C 接口、内联汇编器、手动内存管理以及自动向量化等等)。Vectorflow 中并不存在任何第三方依赖关系,因此能够显著简化部署流程。其提供的基于回调的 API 能够在训练当中轻松插入定制化损失函数。
稀疏感知设计稀疏数据库与浅架构库意味着运行时瓶颈往往体现在 IO 方面:举例来说,与大型密集矩阵上的卷积层不同,其运行每行时所需要的运算量极低。
Vectorflow 能够尽可能避免在正向与反向传递过程中进行任何内存复制或分配 ; 事实上,各个层都会从其父级与子级处引用所需数据。矩阵 - 向量操作拥有稀疏与密集两种实现方式,其中密集型表现为 SIMD 向量化,而 Vectorflow 的出现则为我们带来了处理稀疏输出梯度时进行稀疏反向传递的可行途径。
IO 未知如果您进行 IO 绑定,那么根据定义,训练器的运行速度将直接由您 IO 层的速度决定。Vectorflow 立足于底层数据模式采取非常宽松的要求(仅提供包含一条‘features’属性的行迭代器),因此大家能够根据数据源编写出高效数据适配器,从而在无需任何预处理或数据转换步骤的前提下始终使用同一编程语言。如此一来,您能够将代码移动至数据,而非将数据移动至代码。
单一设备分布式系统调试难度极高且会带来无法消除的固定成本(例如任务调度)。而在新型机器学习技术方案当中实现分布式优化则更为困难。
考虑到这些因素,我们决定立足单一设备建立高效解决方案,从而在降低建模迭代时间的同时继续保持中小型规模任务(1 亿行级别)的可扩展能力。我们决定使用 Hogwild 的通用异步 SGD 解算器作为免锁定方案,旨在以无通信成本方式将负载分发至各个计算核心当中。
只要数据稀疏程度得当,这种方法即适用于大多数线性或者浅网络模型 ; 由于从用户角度来看,一切皆运行于非分布式场景之下,因此能够避免在算法分布层面分散过多精力。
应用程序在项目启动后的几个月中,我们陆续观察到多种围绕该库建立的泛用性用例 ; 亦有不少研究项目及生产系统开始利用 Vectorflow 进行因果推论、生存分析、密度估算或者推荐排名计算。事实上,我们已经在利用 Vectorflow 对 Netflix 主页的部分使用体验进行测试。此外,Vectorflow 亦被纳入到 Netflix 机器学习从业者所使用的基础实例内的默认工具箱中。
举例来说,我们立足 Netflix 在营销工作当中遭遇的一项宣传问题对该库的性能水平进行调查。在此案例中,我们需要配合一条生存指数分布对最大似然估算进行加权计算。要实现这贡目标,我们向 Vectorflow 传递出以下定制化回调函数:
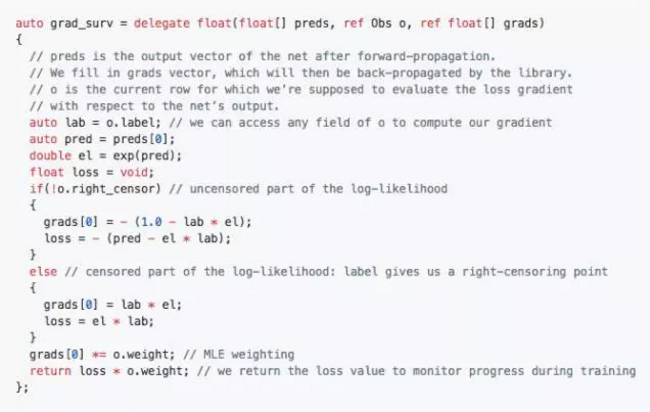
利用此回调进行训练,我们可以轻松比较三种模型:
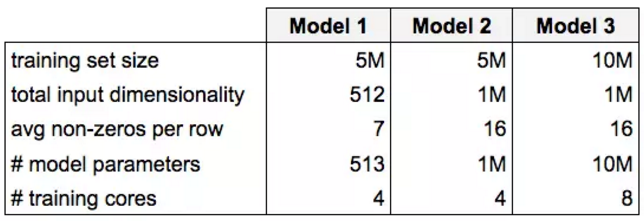
- 模型 1:小型稀疏特征组上的线性模型(需要学习约 500 项参数)
- 模型 2:大型稀疏特征组上的线性模型(需要学习 100 万项参数)
- 模型 3:稀疏特征组上的浅层神经网络(需要学习 1000 万项参数),训练数据量翻倍

此处的数据源为存储于 S3 上的一套 Hive 表,其中的列式数据格式为 Parquet。另外,我们通过将该数据流引入一个 c4.4xlarge 实例并构建内存内训练集的方式进行直接训练。具体结果如下:
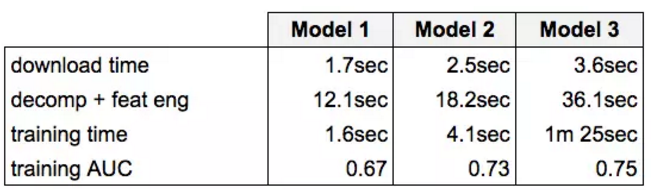
这里的压缩与特征编码皆利用单一线程实现,因此这套方案仍有改进的空间 ; 不过从端到端运行时表现来看,并不需要在中等规模稀疏数据集及浅架构场景下使用分布式解决方案。需要注意的是,训练时间与数据稀疏度及行数存在线性关联。线性可扩展性面临的一大阻碍在于,当存在多个异步 SGD 线程访问同一组权重时,CPU 内在结构将创建无效缓存 ; 这意味着如果模型参数访问模式的稀疏度不足(点击此处查看原论文以了解更多信息,英文原文),则可能破坏 Hogwild 的理论结果。
下一步计划接下来,我们计划在简单的线性、多项式或者前馈架构之外,进一步开发更为专业的层(例如周期性单元)以扩大拓扑支持能力 ; 并在探索新型并行策略的同时,继续维持 Vectorflow 项目的“极简”设计理念。
编者注稀疏数据是指,数据框中绝大多数数值缺失或者为零的数据。在现代社会中,随着信息的爆炸式增长,数据量也呈现出爆炸式增长,数据形式也越来越多样化。在数据挖掘领域,常常要面对海量的复杂型数据。其中,稀疏数据这一特殊形式的数据正在越来越为人们所注意。
稀疏数据绝对不是无用数据,只不过是信息不完全,通过适当的手段是可以挖掘出大量有用信息的。然而在一些情况下,数据的稀疏程度甚至会达到 95% 以上,这使得传统的统计方法不适于处理此类数据。
AI 前线微信社群
入群方法
关注 AI 前线公众账号(直接识别下图二维码),点击自动回复中的链接,按照提示进行就可以啦!还可以在公众号主页点击下方菜单“加入社群”获得入群方法~AI 前线,期待你的加入!





