在“数据为王”的今天,越来越多的人对数据科学产生了兴趣。数据科学家离不开算法的使用,那么,数据科学家最常用的算法,都是哪些呢?
最近,著名的资料探勘信息网站 KDnuggets 策划了十大算法调查,这次调查对数据科学家常用的算法进行排名,并发现最“产业”和最“学术”的算法,还对这些算法在过去5 年间(2011~2016)的变化,做了一番详细的介绍。
这次调查结果,是基于844 名受访者投票整理出来。
KDnuggets 总结出十大算法及其投票份额如下:

图 1:数据科学家使用的十大算法和方法。
请参阅文末的所有算法和方法的完整列表。
从调查中得知,受访者平均使用 8.1 个算法,与 2011 年的一项类似调查相比大幅提高。
与用于数据分析 / 数据挖掘的 2011 年投票算法相比,我们注意到流行的算法仍然是回归算法、聚类算法、决策树和可视化。相对来说最大的增长是以 (pct2016/pct2011-1) 测定的以下算法:
- Boosting,从 2011 年的 23.5%至 2016 年的 32.8%,同比增长 40%
- 文本挖掘,从 2011 年的从 27.7%至 2016 年的 35.9%,同比增长 30%
- 可视化,从 2011 年的从 38.3%至 2016 年的 48.7%,同比增长 27%
- 时间序列分析,从 2011 年的从 29.6%至 2016 年的 37.0%,同比增长 25%
- 异常 / 偏差检测,从 2011 年的从 16.4%至 2016 年的 19.5%,同比增长 19%
- 集合方法,从 2011 年的从 28.3%至 2016 年的 33.6%,同比增长 19%
- 支持向量机,从 2011 年的从 28.6% 至 2016 年的 33.6%,同比增长 18%
- 回归算法,从 2011 年的从 57.9% 至 2016 年的 67.1%,同比增长 16%
在 2016 年最受欢迎的新算法是:
- K- 近邻算法(K-nearest neighbors,KNN),46% 份额
- 主成分分析(Principal Commponent Analysis,PCA),43%
- 随机森林算法(Random Forests,RF),38%
- 最优化算法(Optimization),24%
- 神经网络 - 深度学习(Neural networks-Deep Learning),19%
- 奇异值矩阵分解(Singular Value Decomposition,SVD), 16%
跌幅最大的算法分别为:
- 关联规则(Association rules),从 2011 年的 28.6% 至 2016 年的 15.3%,同比下降 47%
- 增量建模(Uplift modeling),从 2011 年的 4.8% 至 2016 年的 3.1%,同比下降 36%
- 因子分析(Factor Analysis),从 2011 年的 18.6% 至 2016 年的 14.2%,同比下降 24%
- 生存分析(Survival Analysis),从 2011 年的 9.3% 至 2016 年的 7.9%,同比下降 15%
下表显示了不同算法类型的用途:监督学习、无监督学习、元分析和其他算法类型。我们排除了 NA(4.5%)和其他(3%)的算法。
表 1:按行业类型的算法使用
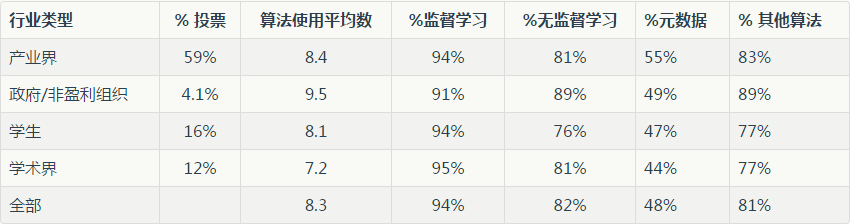
我们注意到,几乎所有人都在使用监督学习算法。
政府和产业的数据科学家们比学生或学术界使用了更多的不同类型的算法,产业数据科学家更倾向使用元算法。
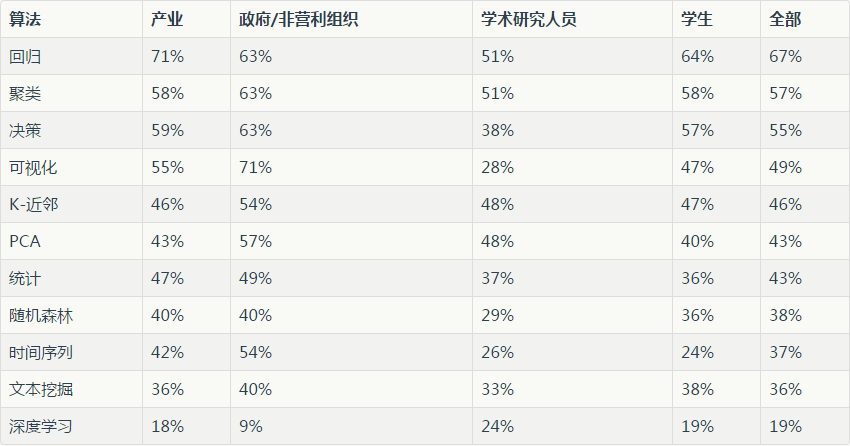
接下来,我们分析深度学习的十大算法按行业类型的使用。
表 2:深度学习的十大算法按就业类型的使用
Table 2: Top 10 Algorithms + Deep Learning usage by Employment Type
为了使差异更为醒目,我们计算特定行业类型相关的平均算法使用量设计算法为 Bias(Alg,Type)=Usage(Alg,Type)/Usage(Alg,All)-1。
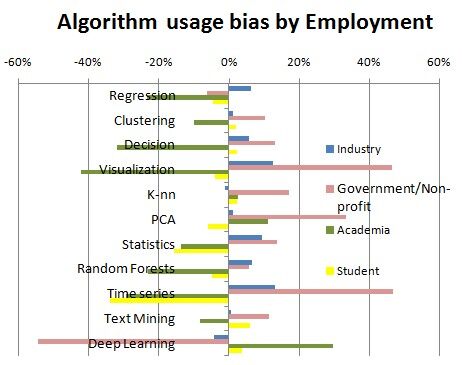
图 2:按行业的算法使用偏差
我们注意到产业界数据科学家更倾向使用回归算法、可视化、统计算法、随机森林算法和时间序列。政府 / 非盈利组织更倾向使用可视化、主成分分析和时间序列。学术研究人员更倾向使用主成分分析和深度学习。学生通常使用算法较少,但他们用的更多的是文本挖掘和深度学习。
接下来,我们看看代表整体 KDnuggets 访客的地区参与情况。
参与投票者的地区分布如下:
- 北美,40%
- 欧洲,32%
- 亚洲 8%
- 拉美,5.0%
- 非洲 / 中东,3.4%
- 澳洲 / 新西兰,2.2%
与 2011 年的调查一样,我们将产业 / 政府合并为同一个组,将学术研究人员 / 学生合并为第二组,并计算算法对产业 / 政府的“亲切度”:
N(Alg,Ind_Gov) / N(Alg,Aca_Stu)
------------------------------- - 1
N(Ind_Gov) / N(Aca_Stu)
亲切度为 0 的算法在产业 / 政府和学术研究人员 / 学生的使用情况相同。IG 亲切度约稿表示该算法越“产业”,越低则表示越“学术”。
其中最“产业”的算法”是:
- 增量建模(Uplift modeling),2.01
- 异常检测(Anomaly Detection),1.61
- 生存分析(Survival Analysis),1.39
- 因子分析(Factor Analysis),0.83
- 时间序列(Time series/Sequences),0.69
- 关联规则(Association Rules),0.5
虽然增量建模又一次成为最“产业”的算法,但出乎意料的是它的使用率如此低:区区 3.1%,在这次调查中,是使用率最低的算法。
最“学术”的算法是:
- 神经网络(Neural networks - regular),-0.35
- 朴素贝叶斯(Naive Bayes),-0.35
- 支持向量机(SVM),-0.24
- 深度学习(Deep Learning),-0.19
- 最大期望算法(EM),-0.17
下图显示了所有算法以及它们在产业界 / 学术界的亲切度:
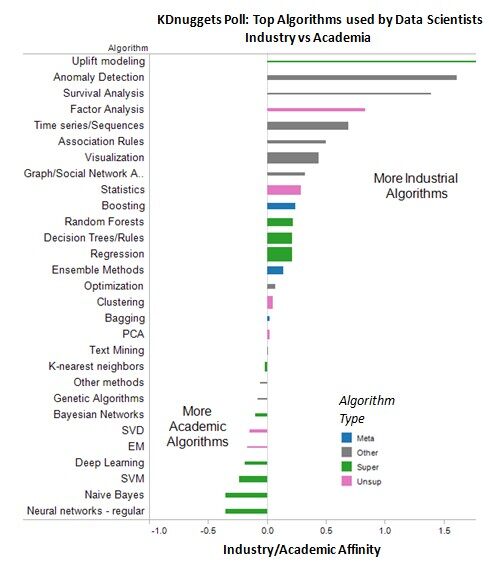
图 3:Kdnugets 调查:数据科学家使用的流行算法:产业界 vs 学术界
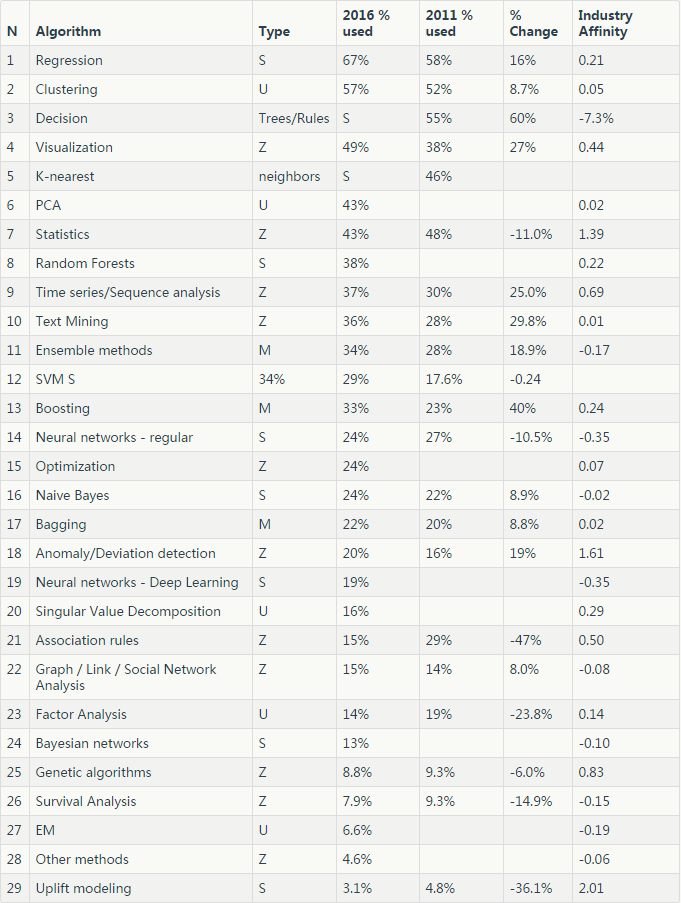
下表包含了算法的详细信息,在 2016 年和 2011 年使用它们的受访者百分比调查,变化(%2016 /%2011 - 1)和行业亲切度如上所述。
表 3:KDnuggets2016 调查:数据科学家使用的算法
下表包含各个算法的详细信息:
- N: 根据使用度排名
- Algorithm: 算法名称
- Type:类型。S - 监督,U - 无监督,M - 元,Z - 其他,
- 2016 % used:2016 年调查中使用该算法的受访者比例
- 2011 % used:2011 年调查中使用该算法的受访者比例
- %Change:变动 (%2016 / %2011 - 1)
- Industry Affinity:产业亲切度(上文已提到)
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




