Apache Kylin 在 1.5.0 推出了从流数据进行准实时(Near Real Time)处理功能,可以直接从 Apache Kafka 的主题(Topic)中消费数据来构建 Cube。Apache Kylin 1.5.0 的流处理是一次实验性的探索,它打破了以往只能从 Apache Hive 表构建 Cube 的局限,将数据从产生到可查询的延迟从小时级降低到了分钟级,满足了一些对实时性要求比较高的场景;但它在实现上存在一些局限︰
- 不可扩展︰ 由于是利用单个 Java 进程(而不是利用某种计算框架)对数据做处理,当遇到流数据高峰时,可能由于资源不足而导致构建失败 ;
- 可能会丢失数据︰ 由于使用一个起始时间 + 结束时间在 Kafka 队列中使用二分查找近似地寻找消息的偏移量 (offset),过早或过晚到达的消息将会被遗漏,从而使得查询结果有误差 ;
- 难以监控︰ 用于构建的任务是单独通过 shell 脚本执行的,而不是像其它 Cube 那样由任务引擎统一调度和执行,所以这些任务是在 Web 界面和 REST API 上都无法查询到的,使得用户无法方便地使用工具进行监控和管理;
- 其它︰ 必须持续执行,如果有系统宕机将会造成某些时间窗口的任务没有被执行,从而必须依靠管理员手动恢复;如果宕机时间较长,管理员不得不将长时间窗口切成多个小时间窗口依次来恢复,非常繁琐 。
为了克服这些限制,Apache Kylin 团队基于 Kafka 0.10 的 API,开发了新版的准实时流式处理,它已经在内部测试了一些时间,目前正在公开测试中。
新版流式构建是在Kylin v1.5 的"可插拔 "架构下的一个完美实现︰ 将Kafka 主题视为一种数据源,实现相应的适配器,将数据先抽取、转换和保存到 HDFS,接下来使用各种Kylin 的构建引擎(MR/Spark 等)对数据进行并行计算 。图 1 是高层次的架构图。
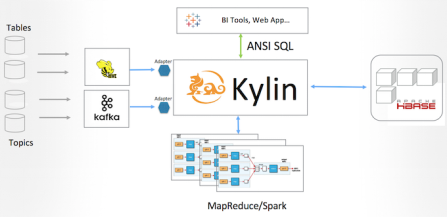
Kylin 的 Kafka 适配器参考了 kafka-hadoop-loader 的思路和部分代码, 将 Kafka 主题抽象成 Hadoop 输入文件格式(InputFileFormat),为主题的每个分区(partition)分配一个 Mapper 消费数据 ; 之后 Kylin 将利用现有框架进行并行处理,从而使得方案变得可扩展且具有容错性。
要解决"数据丢失"问题,Kylin 将开始 / 结束消息的偏移量(offset)计入了每个 Cube segment,并使用偏移量作为分区值 ,offset 是顺序递增的且不能有重叠和遗漏(如果主题有多个分区,使用各分区偏移量之和作分区值); 这将确保没有数据丢失,一个消息只会被消费一次。晚到达的消息会被稍后的 segment 统计进来;每个 Segment 有"最早时间”和"最晚时间"; 当用户按时间条件查询时,Kylin 将扫描与查询时间范围相匹配的所有段。图 2 解释了这个设计。
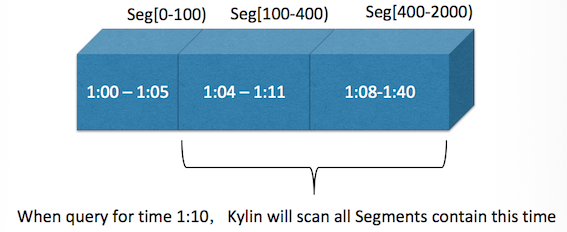
上图中有三个 segment,它们的 offset 依次连续且无重叠(左包右闭),Seg[100-400] 中的消息时间跨度是 1:04 – 1:11,Seg[400 - 2000] 的时间跨度是 1:08 – 1:40;当用户要查询 1:10 的统计信息时,Kylin 发现这两个 Segment 都可能有这个时间的消息,故而会扫描这两个 Segment 然后再次做汇总计算。
新版流计算引擎也进行其它一些更改和增强︰
- 允许同时构建 / 合并多个 segment,前后的构建任务都是独立的
- 自动从前一个 segment 或从 Kafka 寻找消息的开始及结束的 offset
- 支持嵌入格式(结构化)的 JSON 消息
- 增加了触发流式构建的 REST API
- 增加了来检查和部分填补 segment 空洞的 REST API
内部的集成测试结果初步验证了当初的目标 ︰
- 可伸缩︰ 它能够在一次构建中轻松处理上亿条消息 ;
- 灵活︰ 可以在任何时候,以你期望的频率触发构建,例如︰ 在白天每隔 5 分钟触发一次, 在夜间将频率降低到每个小时,在需要做的维护可以随时暂停 ; 由于是 Kylin 管理所有主题的 offset,再恢复时它可以自动从上一次的结束位置继续 ;
- 稳定︰ 稳定性大大提高,在上一版中经常发生的 OutOfMemory 错误再没有出现过;
- 易于管理︰ 用户可通过 Kylin 的"Monitor"页面或 REST API 检查所有构建任务的状态 ;
- 构建性能︰相比于前一版构建时间略长(因为有 Hadoop 任务的调度),但延迟依然在可接受的分钟级别。
在一个小规模的测试群集 (8 台 AWS 实例,消费 Twitter Sample 消息流) 中,创建一个有 9 个 维度和 3 个度量的 Cube, 每秒约一万条消息,当构建间隔是 2 分钟的时候,平均每次构建需 3 分钟 ; 当构建间隔是 5 分钟的时候,平均每次构建需要 4 分钟 ; 这里是几个测试中的截图 ︰
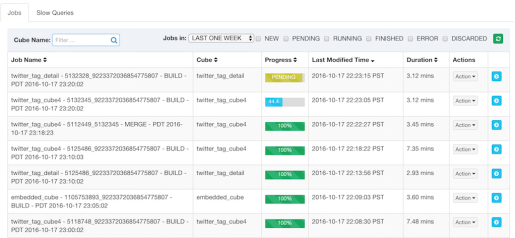
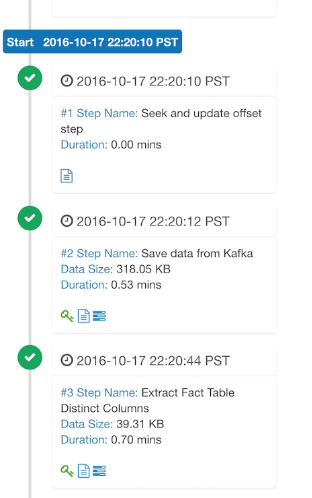
总结,这是比前一版本相比更加健壮和完善的流数据 OLAP 解决方案。现在你可以从 Apache Kylin 的下载页面下载到 1.6.0-SNAPSHOT 的二进制包,然后按照此教程生成第一个流式Cube。
作者介绍:
史少锋,Kyligence 技术合伙人& 资深架构师 Apache Kylin 核心开发者和项目管理委员会成员(PMC),专注于大数据分析和云计算技术。曾任eBay 全球分析基础架构部大数据高级工程师,IBM 云计算部门软件架构师;曾是IBM 公有云Bluemix dev&ops 团队核心成员,负责平台的规划、开发和运营。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




