本文是 5 月 12 日大数据杂谈群分享的内容。本次分享是机器学习实践内容,由携程 IT 酒店研发部 BI 经理潘鹏举给大家讲机器学习如何在 OTA 酒店行业创造价值。
分享人——潘鹏举,携程 IT 酒店研发部 BI 经理,主要负责服务相关业务的机器学习建模工作。

大家好,我叫潘鹏举,人称 PPJ,来自携程酒店研发 BI。上图是我的自我介绍,简单做了一下标签,做了词云可视化。
以下是我今天要分享的主题:机器学习如何创造价值。目录结构如下:

首先简单介绍一下 OTA 酒店行业有哪些我们关心的 KPI 及其面对的挑战,让大家有个简单概念;接着重点介绍一下算法在酒店行业是怎么用的,看一下我们的经验对各位有没有启发,也想借此机会和大家交流一下怎么才能让算法创造出更大的价值;最后分别简单介绍一下使用算法的经验和算法的上线架构等。
OTA 酒店行业

OTA 酒店和其他酒店的区别
我截取了某一个酒店的详情页,即我们的产品。在上面我也罗列出了 OTA 酒店行业和其他行业的最主要的区别。
首先最大的区分就是:我们的房型是限时限购的,从图上可以看到,我们只能 5.11 号入住,过时不候。另外每个酒店的房间数量是相对固定的,所以如果酒店超卖的话,那么就不好意思,酒店没有办法一天内加盖房型,只能协调客人到其他酒店去入住了。
然后是第二部分,代理(供应商)房型,这部分就是二房东,它从酒店拿到库存,然后放到携程售卖。这样有个什么问题呢?我没办法从酒店打听到任何库存信息、订单信息,所以我们在管理代理方面就很谨慎,因为不好的代理会拉低携程的服务水平,如果订单出了问题,只能找二房东去协调,速度慢不说,还有可能解决不了问题。
第三部分,自营:指的是携程和酒店直接谈合作的房型,这些房型中有保留房、直连、直签,自营的房型是靠谱的房型,我们直接跟酒店要库存,知道房价、房态信息,出了问题也可以跟酒店直接协商,自营房源是我们服务标杆,各项服务指标都很好。说完了行业区别,我们看看我们面对哪些挑战;

因为我们的商业模式,所以第一点挑战对我们影响很大,我们很依赖酒店行为;有些酒店虽然在我们这里售卖,但是比较无赖,会出现佣金、前台切客等行为,造成业务损失,当然我们对各种行为有相应的识别方法和会有相应的惩罚措施,另外酒店服务水平参差不齐,管理起来比较困难。
第二点提一下,有些低星酒店很落后,我们跟它联系只能用小灵通,导致我们管理一些酒店比较困难。其他的挑战都比较好理解,简单的说就是低频、长尾、季节性。
服务 KPI

服务 KPI 就是好、快、准。
稍微解释一些 KPI,到店无房指的是酒店发给了客人入住凭证,但是因为超卖导致客人无法入住,这种情况主要是酒店的违约行为,正常情况下携程会帮忙协调入住其他酒店并赔偿相应的损失,在旺季的时候会有所升高。然后是到店无预定率,跟到店无房的区别是:客人到了酒店,酒店说没有相应的订单信息,出现这个问题主要是携程和酒店传真客人入住信息的过程中有问题,出现这种情况携程会立即帮忙解决客人的入住问题。
目前来说,基于我们强大的客服力量和优质的 6sigma 管理体系,这两个指标都控制在极低的水准上。剩下的指标就不一一解释了。我们现在面对的一个挑战是,业务量持续的增长,我们没办法持续性的增加客服人员来维持一个高标准的服务水准,因此需要借助于算法来实现智能化、自动化。
评估项目收益
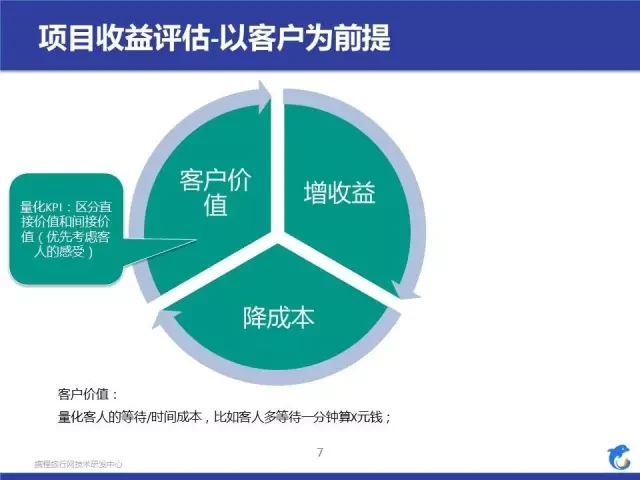
这里重点说一下客户价值。客户价值实际上传达的是一个间接收益的概念,我们会量化出每个客人的等待成本,每个环节的时间成本,每个事件的客人损失成本,把所有的这些成本量化成对应的金额,所以我们在每个事件产生了之后,不仅可以计算出直接损失还能计算出间接损失,我举了一个例子:比如一个客人出现了到店无房,除了要直接赔款损失外,我们还要额外计算间接损失,那么我们在做到店无房项目的时候,如果间接收益 + 直接收益超过了成本,那么我们就值得投入人力去做优化。对于有些公司来说,单纯提升客人感受认为价值不大,但是我们把客人感受货币化了,那么这个价值就提高了。行业背景就告一段落,我接着说重点,算法应用实践。
算法应用实践

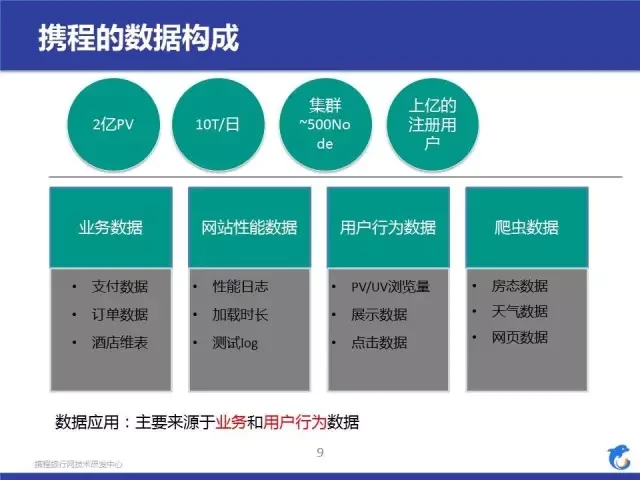
在正式说应用实践之前,我们先简要看看携程的数据量。2 亿 PV,10TB/ 日,数量还是蛮大的。我们用到的数据大体分成四块:业务数据、网站性能数据、用户行为数据和爬虫数据,其中我们的应用实践主要会用到业务数据和用户行为数据。
接着说说数据在哪块会产生比较大的价值。

我按照数据的冷热区分了一下数据价值,一般性数据时效性越高,数据价值越大。我划分了一下,如果只用冷数据,那么可以挖到银矿,用好了热数据,你就挖到了金矿,如果你都直接预测了未来,那么你就挖到了钻石。最下面我列了一个公式,未来的人工智能就是基于过去和当前的状态来预测未来,这样的一个组合是未来应用的一个趋势。按照冷热的分类,我们看看数据是怎么应用的。

从这个 ppt 可以看到,越冷的数据,越不能影响到线上的实时业务,起的作用也越小。如何利用好当前的数据,对于应用,效果会更好。看最下面的备注,特意说一下,这样区分确实不严谨,但是从实践的角度看,越是过去的东西对未来的指导意义是越差的。接着我说说我们在实际应用中的一些观点和想法;
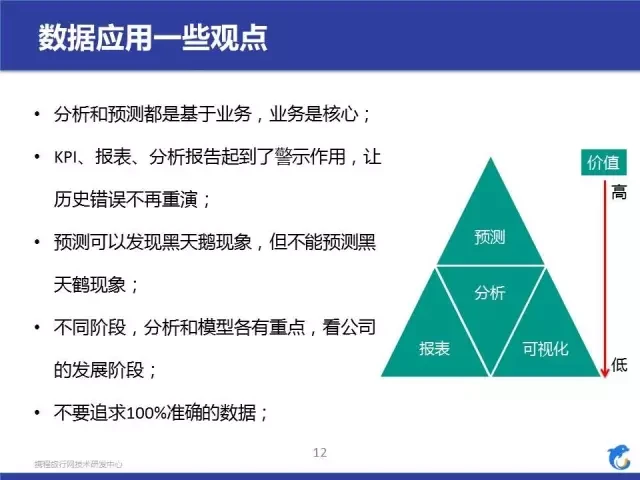
这里面主要是说一下分析和模型之间的差别。
对公司来说,不同阶段,重点会不同,对模型的态度也不同,我们也花了很长的时间慢慢积累,才会有一个又一个的应用。右边的图主要是从数据应用的层面上说的,里面没有提到 DW 层,但是 DW 层是地基,没有一个好的地基是没有办法说数据应用的。但是从价值上看,越往上,数据价值越大。最后提一下,我们可能会有一个误区,我要追求 100% 准确的数据,实际上,我们的数据很难 100% 准确,特别是像用户行为数据,任何一种采集方式都会有 PV 漏记、错记的情况。
我们要能容忍一定的数据采集偏差,在现有的数据中看一下怎么利用数据创造价值。反过来说,如果数据一直都存在这个偏差,那么对你未来的应用影响就小,数据已经适应了你的偏差。说了模型这么多好话,我们看看一个算法应用的完整闭环是怎么样的。
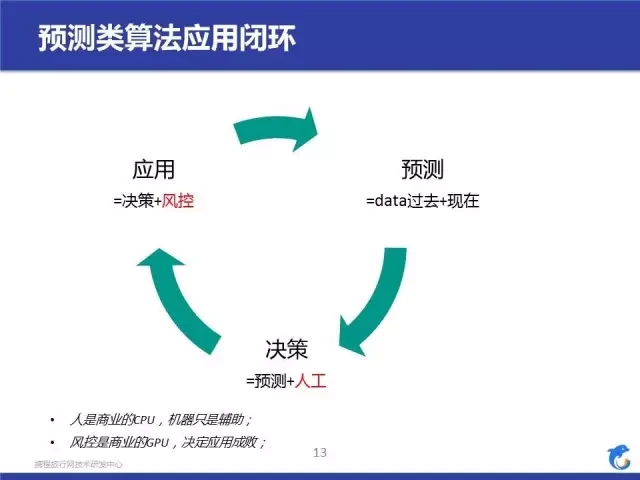
这里提一下标红色部分,人工和风控。在算法应用到线上的过程中,人工经验、人工过滤以及风控会起到很关键的作用。如果没有做到这点,那么在实际应用中会大打折扣。就像我左下角写的那样,人是商业的 CPU,决策过程中要依赖人来调整方向。而风控是决定应用快慢的 GPU,如果没有做好风控措施,不仅可能会导致业务损失也有可能让算法没有发挥出作用,后面的实例中我会提到一些。说了一些概念后,我先说说我们怎么评估模型,然后就讲讲我们的实践实例。
评估模型

这里列出了三种常用的模型评估方法。
第一种 A/BTest,用的最多,几乎所有的项目如果没有 ABTest 是不能拿出来讲的。第二种是为了替代 A/BTest 想到的简单办法,针对有些情况下面很难做 AB 实验。最后一种情况是我们评估 + 风控的方式,先上线模型,但是业务不采纳模型结果,然后我们用 log 来解析模型是否运转正确,效果好不好。说完了评估,我们说说酒店服务用到了哪些模型;
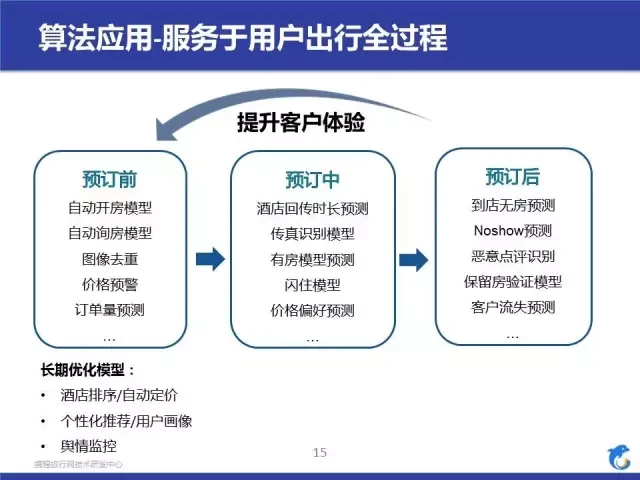
按照预定流程,区分了预订前、中、后流程,主要目的是为了提升客户体验和提高服务效率。预订前的主要目的是为了让信息更加准确、预订中主要是为了提升预订效率和速度,预订后就是为了订单风控、酒店风控和客人风控。左下还罗列了一些常见的算法应用,排序、推荐和画像,这里就不细说了。这边说了一个整体的应用的架构,接下来我举一些具体的例子。
实践具体例子
首先看第一个:
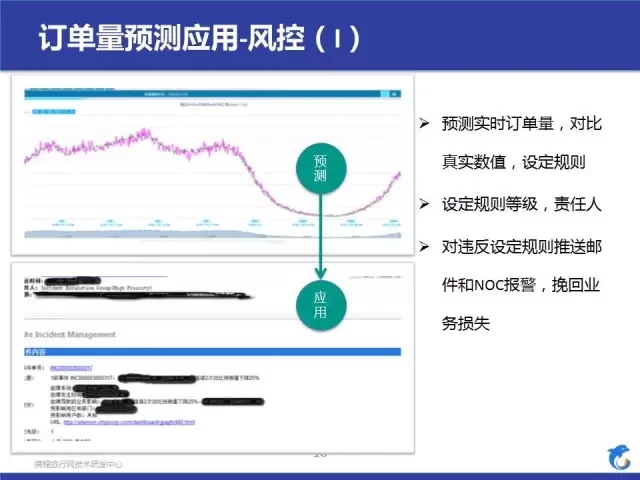
订单量预测的作用,我们一个应用是用来做业务监控,做到了准实时,延迟一分钟预测。右边写了应用的大致流程,跟我之前写的算法应用闭环是同步的,从预测到应用,接下来我们看看用了什么算法。

其实就是简单的 ARIMA+ 季节系数 + 一些人工调整,把模型做了出来,没有用很复杂的算法。最后的效果是平均误差~5%。评估指标我也列了一下,主要是看漏报率,不同阶段重点不同,在稳定期间,我们比较关系误报率,因为系统稳定了,我们就要尽量减少人力损失。
关于预测误差,我这里也提到,预测总是有误差的,不可能 100%,我们可以根据我们的预测的精准度来进行一些规则的设定,看最下面的规则,这个规则让你有些弹性空间来防止预测错误导致的误报。在时效性上,我们以前是吃过亏的,最老的版本我们上线过 T+1 预测,就是预测昨天的结果,看昨天是否异常,我们发现这个对业务一点帮助也没有,你的业务损失已经产生了,再去看异常没有特别大的作用,后面我们就慢慢的提高了时效性并做了可视化,目前这块的监控效果和可视化都很好,也监控了各关键 KPI 的异常情况。
第一个例子说完了,接着看第二个例子。

可能有人觉得,怎么会有怎么长的确认时长,我在右边的解释了一下,并且罗列了相应的挑战,针对这些挑战,我们是怎么做的呢,继续接着看。
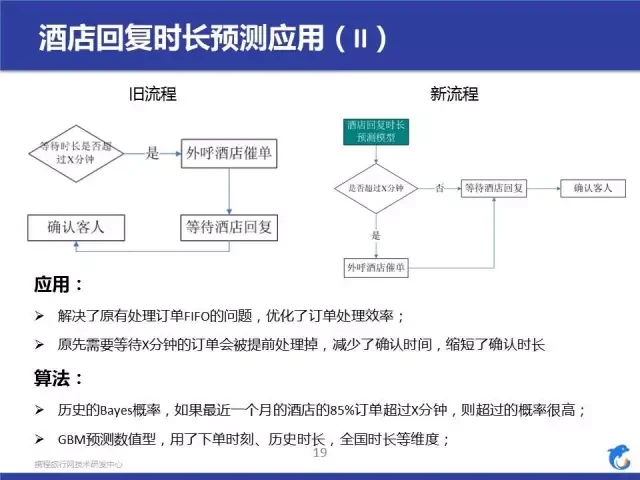
我们看一下旧流程和新流程的差别,最大的差别就是我们在新流程中植入了一个预测模型,根据模型的预测结果来调整业务流程。
这样做的好处就是,以前回复慢的订单要白白等待 X 分钟,通过模型预测之后,我们就调整了顺序,把原来确认慢的订单提早确认了,可以提高确认速度,这个应用点是个很好的一个案例,它让我们来思考那些流程有同样的问题,促进我们进行相应的优化。这个模型准确率为 93%,召回率 53%,取得了一个不错的效果。
这是第二个案例,接着看第三个案例。

询房模型,罗列了一下碰到的问题和需要解决的问题。针对这么庞大的房态数据,如果用人肉的办法肯定是没办法做的很好的。针对这些问题和困难,我们也花了很长的时间来去解决这个问题,最后的解决方案请接着看 PPT。
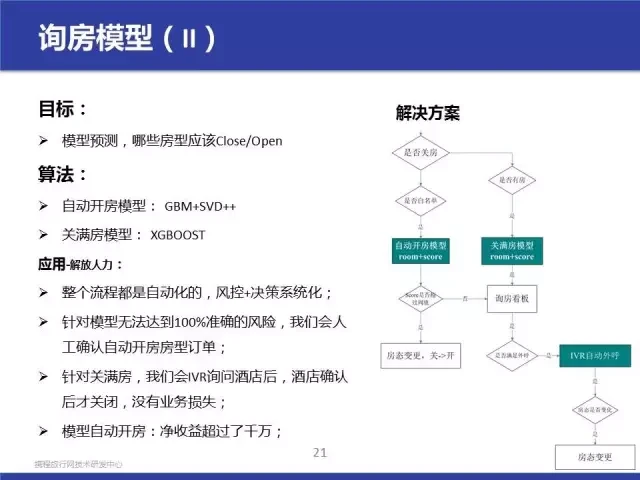
我们的解决方案见右边的流程图,核心是两个模型和 IVR 自动化工具。我稍微简单的描述一下,简单的说,针对关掉的房型,我们会用自动开房模型预测出当前状态下每个房型的可定的概率 score,我们统计出 score 的准确率,在可接受的准确率下,把高于这个分数的房型全部自动打开,然后让客人在网站上可以进行预订。针对那些不能自动打开的房型,我们会把这些房型放在询房看板上去。
另外一边,针对现在可订的房型,我们去预测房型无房的概率,然后把这些数据放在询房看板上。这样我们的询房看板上就有两部分的得分结果,开房分数和关满房分数,针对这些房型,我们有个 IVR 自动外呼工具把概率高的房型优先外呼到酒店,如果酒店告知房态有变化,我们会做对应的房态变更。通过这一整套流程,我们完全实现的开房和关房的自动化,针对高准确率的房型,系统自动操作。对准确率不高的房型,我们采用酒店介入(即人工介入)的方式来平摊风险,把损失降到最低。
所以决策过程中,会有很多人工的接入,然后针对风险的高低,我们会有不同的风控和措施,这样的结合才能让算法的作用最大化。这个案例针对那些数据量大,花费人力多,重复性工作多的事情具有很大的启发意义。
案例三说完了,接着说第四个案例把。
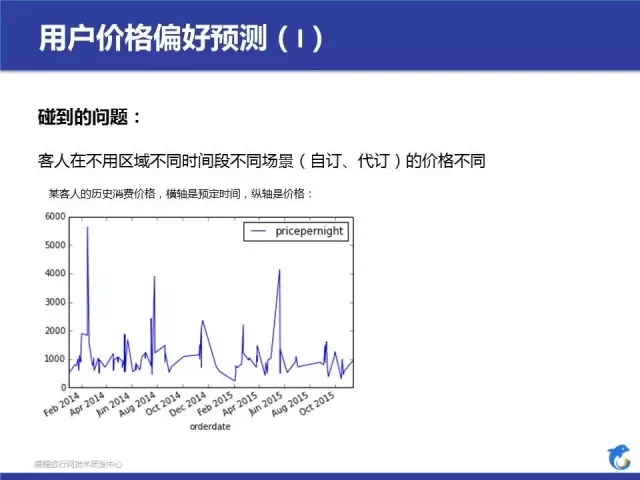
用户价格偏好,是用户画像的一个很小的子集。为什么会单独拎出来说,我等伙会讲。我们先看看我们碰到了什么问题,一个用户根据不同场景,价格是一直在波动的,我提供了一个例子,某个客人在历史上的消费价格。我们后面用了一个算法来进行预测,没有用简单的规则来刻画用户价格偏好,花这么多力气做这个预测是因为猜中了客人的价格偏好,对产品和推荐都很有帮助。
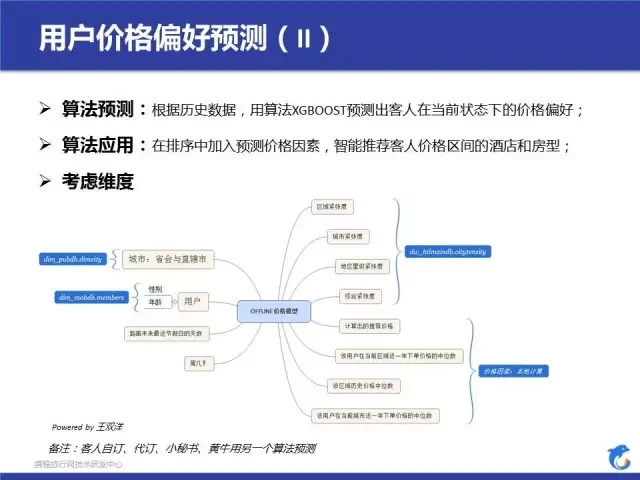
看一下我们是怎么做的,图里面罗列了相应的思考维度,用了 xgboost 来进行预测。我们考虑了很多的实时场景,包括了客人的入住天距离节假日的天数,区域、星级紧张度等,这都是为了刻画客人在当前状态中会变成什么样。最后这个模型的效果还可以,77% 的用户预测价格和实际价格偏差在 50 元以内。模型说完了,看看这个应用给我们的启示。

这上面说了一件事情,画像不是一成不变的,一直在变,要场景化。所以如果只是为了画像而画像的话,意义不大,我们会根据应用场景的不同进行调整。
以上就是第二部分,算法的应用实践分享,接着我分享一下在算法方面的经验。
算法经验分享

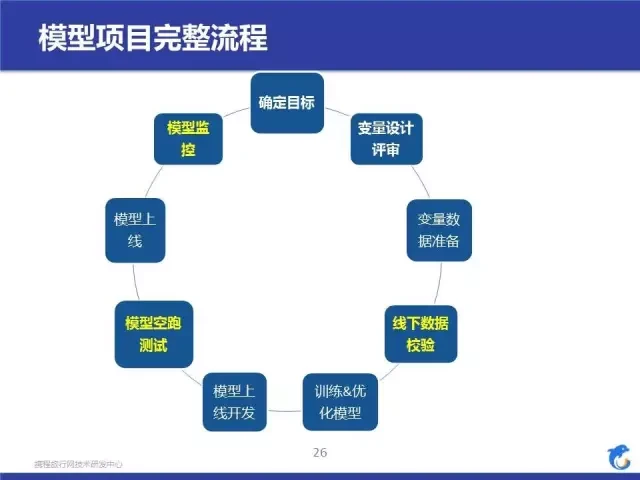
这个是我们实验下来比较好的模型项目流程,给大家参考一下,其中标黄色字体是我们比较关心的,数据校验是为了让模型产生效果,因为俗话说的好:垃圾进,垃圾出。接着说一下 Feature Engineering 的事情;

这个没有特别好说的,跟其他人的做法雷同。提一下缺失值预测。如果我们觉得某些变量对业务帮助很大,但是有一定量的缺失值,那么我们就会用另一个模型来预测缺失值,做法就是取出关键变量不存在缺失值的样本来进行训练,然后再对有缺失值的变量进行预测。
然后说一下归一化,我们这里没有罗列,因为我们现在用的常用的机器学习方法 gbm,xgboost 对量纲不敏感,所以我们为了减少数据分布的损失较少做归一化。你们在实际应用中,有些模型是一定要求你归一化的,所以还是需要进行归一化处理。
类别变量处理方法罗列了一些,大家可以找资料看一下。

模型融合方法,我们常用这两种,有对应的链接,大家看看资料,这里不细说。

对整个模型的总结见图。特意提一下倒数第二点,线下模型上线,根据线上数据进行调优。主要是担心线上上线过程中有人为失误导致数据计算有偏差,所以可以直接根据线上模型来进行模型优化来适应线上的开发错误,并且能够快速的定位出开发中的数据错误。
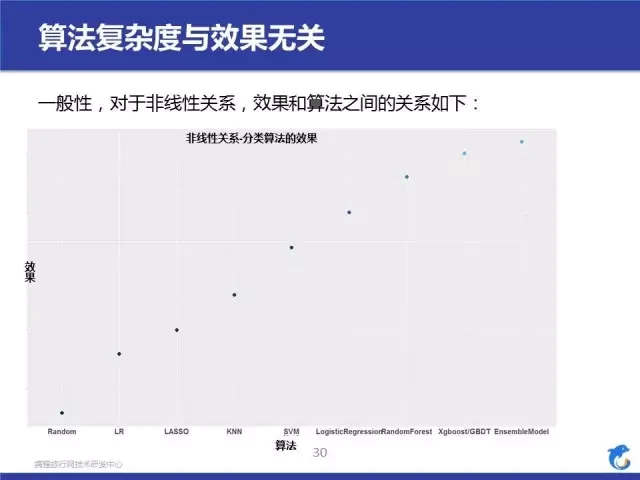
列了一下一般情况下,分类算法的优劣对比,大家可以试验一下。算法经验分享结束,我们最后说一下上线架构。
上线架构

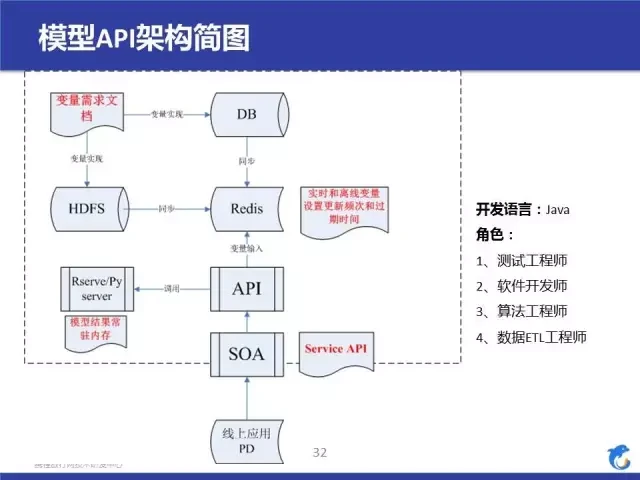
大家看一下模型 API 架构简图,我们的开发语言是 Java,我们会用 Java 封装模型的所有输入参数,然后把模型训练的结果存储成文件 xx.Rdata 或者 xx.Py 文件,最后 Java 把模型结果常驻内存,最后去调用 Rserver 和 Pyserver 来进行预测。整个过程涉及的角色比较多。

最后说一下数据校验,我们非常关注的,罗列了一下我们的常用校验逻辑,供大家参考。我的分享就是这些,谢谢大家。
Q&A
Q1. 请问特征工程和模型构建哪个对最后预测效果的影响更大些?
A1: 实际应用中是特征工程,如果参加比赛是后者,模型构建,多个模型嵌套
Q2: 怎么学习机器学习?
A2: 我有个链接 https://github.com/josephmisiti/awesome-machine-learning 这里面罗列了很全的各方面的机器学习的知识,先理解一下。然后再参加一些竞赛,kaggle,天池什么的,锻炼一下怎么建模流程。然后再用一些实际生活中的数据,比如预测房价,从爬数据,准备数据、清洗数据、建模,优化都做一遍,那基本上算可以了。多动手实践 !
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




