Big SQL 是 IBM 的基于 Hadoop 的平台 InfoSphere BigInsights 的 SQL 接口,旨在让 SQL 开发人员能够轻松地掌握对 Hadoop 管理的数据的查询。它使数据管理员能够为 Hive、HBase 或他们的 BigInsights 分布式文件系统中存储的数据创建新表。来自 IBM 的工程师 Cynthia 和 Uttam 对 Big SQL 做了简要的介绍。
Big SQL 并没有将 Hadoop 转变为一种大型的分布式关系数据库。它是一个软件层,使 IT 专业人员可使用熟悉的 SQL 语句在 BigInsights 中创建表和查询数据。为此,程序员将会使用标准的 SQL 语法,并在某些情况下使用 IBM 创建的 SQL 扩展,使得利用某些基于 Hadoop 的技术变得非常轻松。Big SQL 的架构图如下:
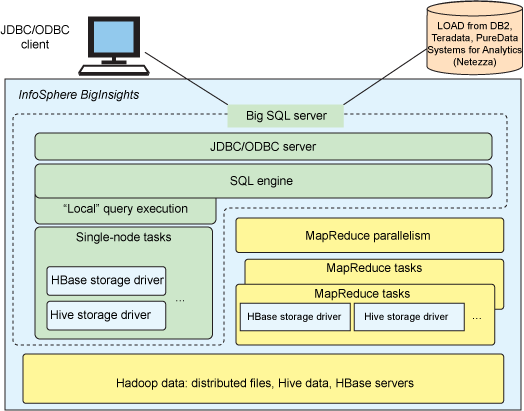
Cynthia 和 Uttam 对此做了详细的介绍:
Big SQL 支持来自 Linux 和 Windows 平台的 JDBC 和 ODBC 客户端访问。此外,Big SQL
LOAD命令可直接从多种关系 DBMS 系统以及存储在本地或 BigInsights 分布式文件系统中的文件读取数据。BigInsights EE 2.1 可配置为支持 Hadoop Distributed File System (HDFS) 或 IBM 的 General Parallel File System with the File Placement Optimizer (GPFS-FPO)。SQL 查询引擎支持连接、联合、分组、常见的表表达式、窗口函数,以及其他熟悉的 SQL 表达式。此外,通过优化提示和配置选项,您还可以改变数据访问策略。根据查询的性质、数据量和其他因素,Big SQL 可以使用 Hadoop 的 MapReduce 框架并行处理各种查询任务,或者在单个节点上的 Big SQL 服务器上本地执行您的查询,无论哪种方式最适合您的查询。
对 Big SQL 感兴趣的组织通常在内部拥有丰富的 SQL 技能,以及一个基于 SQL 的商业智能应用程序和查询 / 报告工具套件。对于不熟悉 Hadoop 的组织而言,能够利用现有技能和工具(并且可能重用部分现有应用程序)的概念可能非常有吸引力。确实如此,一些拥有构建于 DBMS 系统之上的大型数据仓库的公司正在寻找基于 Hadoop 的平台,使用该平台作为卸载 “冷的” 或不常用数据的潜在目标,同时仍然支持查询访问。在其他情况下,组织会依靠 Hadoop 来分析和过滤非传统数据(比如日志、传感器数据、社交媒体帖子等),最终将此信息的子集或集合提供给他们的关系仓库,以扩充其产品、客户或服务视图。
在这些和其他一些情况下,Big SQL 可能发挥着重要作用。但是,认为 Big SQL 会取代关系 DBMS 技术是不恰当的。Big SQL 旨在为基于 Hadoop 的基础架构提供补充并在 BigInsights 中利用该架构。关系 DBMS 系统的一些常见特性在 Big SQL 中并不存在,而且一些 Big SQL 特性在大多数关系 DBMS 系统中都不存在。例如,Big SQL 支持查询数据,但不支持 SQL UPDATE 或 DELETE 语句。INSERT 语句仅支持用于 HBase 表。Big SQL 表可能包含具有复杂数据类型的列,比如 struct 和 array,而不是简单的 “扁平” 行。而且还支持一些基础存储机制,包括:
- 存储在 HDFS 或 GPFS-FPO 中的分割文件(比如逗号分隔文件)
- 顺序文件格式、RCFile 格式等格式的 Hive 表。(Hive 是 Hadoop 的数据仓库实现)
- HBase 表(HBase 是 Hadoop 的基于键值或基于列的数据存储)
Cynthia 和 Uttam 举例说明了 Big SQL 的基本用法,比如创建一个 Big SQL 表并向其中加载来自本地文件的数据:
create table mygosales.product_brand_lookup ( product_brand_code int, product_brand_en varchar(180) ) row format delimited fields terminated by '\t'; load hive data local inpath '/home/user1/data/product.tsv' overwrite into table mygosales.product_brand_lookup;
CREATE TABLE 语句创建一个包含两列的 Hive 表;第一列捕获一个数字代码,将它用作产品品牌的标识符,第二列捕获该品牌的一段英文描述。此语句的最后一行指定了该数据将用来存储(和想要的)输入数据的格式:以包含制表符分隔的字段的行格式。LOAD 语句,提供了本地文件系统中我们希望加载到表中的一个文件的完整路径。给定我们的表定义,此文件中的每个记录必须包含两个由 \t(制表符)分隔的字段(一个整数和一个字符串)。OVERWRITE 子句告诉 Big SQL 将表的内容替换为文件中包含的数据。
传统事务管理不是 Hadoop 生态系统的一部分,所以 Big SQL 的运行未涉及到事务或锁管理。这表明提交和回滚操作不受支持,而且一些并发操作可能导致应用程序或查询错误。
关于性能方面的考虑因素,Cynthia 和 Uttam 也做了简要的介绍:
Big SQL 将一个查询的执行分解为多个 _ 部分 _,比如连接、group-by 等。依赖于具体的查询、数据量、配置设置和其他因素,Big SQL 可顺序或并行执行这些部分。并行性是通过利用 Hadoop 的 MapReduce 框架来实现的。您可能已经想到,单个查询可能生成多个 MapReduce 作业。MapReduce 框架使用多个映射器或缩减程序 (reducer) 并行执行每个作业(任务)。这可能对针对大型数据集的复杂查询很有帮助。
但是,启动一个 MapReduce 作业涉及到一定量的处理开销。对于某些类型的查询,此开销可能超出并行处理的好处,比如助力小数据集或获取与一个特定 HBase 行键关联的数据的查询。在这些情况下,查询最好在单个节点上顺序执行。这有时称为 “本地” 查询执行,Big SQL 除了支持 MapReduce 并行性之外也支持此能力。
商用的关系 DBMS 系统采用了复杂的基于成本的优化器,参考与表大小、数据失真等相关的广泛统计信息,为它们的查询选择一种高效的数据访问策略。Big SQL 的查询优化器还会动态地参考某些统计信息来确定一种高效的数据访问策略。但是,在一些情况下,Big SQL 可能没有足够的统计信息可用。例如,它的基础数据源可能未提供这些信息。在这些情况下, Big SQL 程序员将优化提示嵌入其查询中可能有所帮助,因为这么做可使 Big SQL 生成更好的执行计划。提示可与查询执行模式(本地或并行)、连接方法、索引使用等相关。在 Big SQL 中,查询提示采用
/*+ name=value[, name=value ..] +*/的形式。Big SQL 支持使用
CREATE INDEX语句为 HBase 创建辅助索引。可以想象,这些索引可改进在加入索引的列上进行过滤的查询的运行时性能。HBase 索引可能基于单个键或复合键,使用 Big SQL 将数据插入 HBase 表中或将来自一个文件的数据加载到 HBase 表中会自动更新它的索引。但是,在 BigInsights 2.1 中,将来自远程关系数据库的数据加载到 HBase 表中不会自动更新表的辅助索引。相反,管理员需要丢弃并重新创建必要的索引。




