
11 月 27 日晚,DeepSeek 在毫无预告的情况下,于 Hugging Face 和 GitHub 上开源了全新数学推理模型 DeepSeek-Math-V2,685B 参数,从模型名称就可以直接分辨出这是一款专注于数学方面的模型。这是业内首个达到国际奥林匹克数学竞赛(IMO)金牌水平且全面开源的数学模型,一经发布便引发全球学界与开发者的高度关注。

它的上一个版本 ——DeepSeek-Math-7B 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。
模型地址:
https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
https://github.com/deepseek-ai/DeepSeek-Math-V2
数学能力击败 Gemini DeepThink
那么,这款模型性能到底如何?
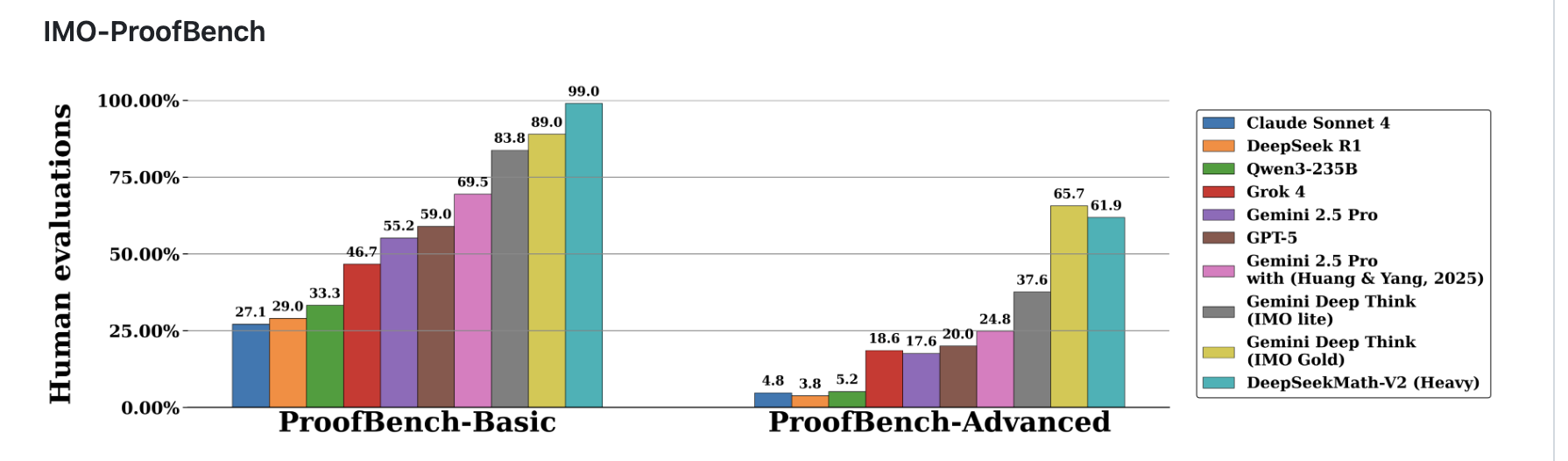
据 DeepSeek 官方介绍,在性能方面,DeepSeek-Math-V2 在权威基准 IMO-ProofBench 中表现突出。
在 Basic 子集上,该模型拿下近 99% 的高分,领先第二名 Gemini DeepThink(IMO Gold)的 89%;在更具挑战的 Advanced 子集上,Math-V2 取得 61.9%,略低于 Gemini DeepThink 的 65.7%。
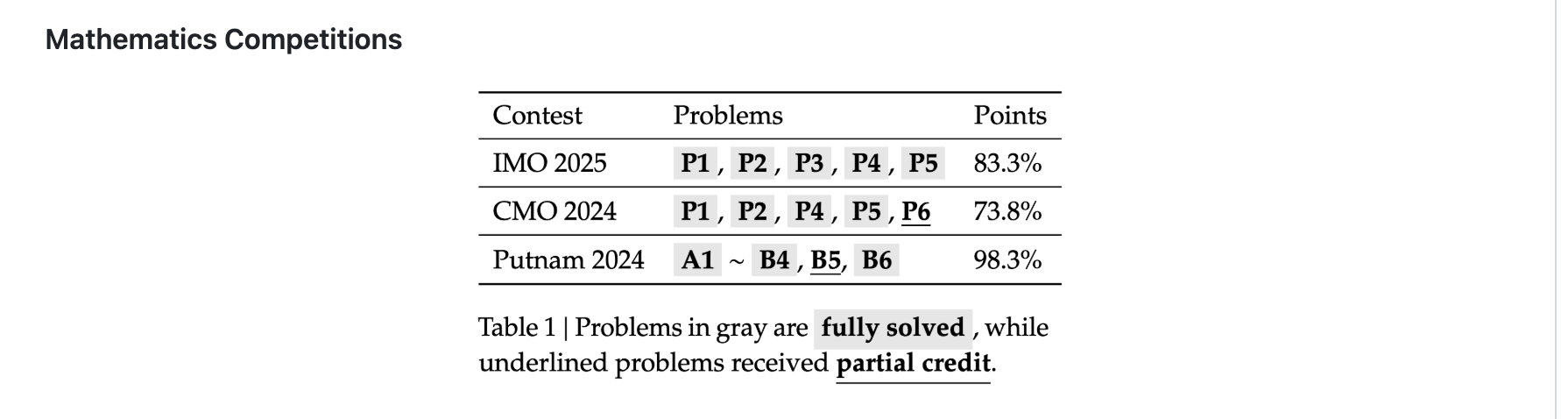
更具标志性的是,在真实竞赛题上的表现:Math-V2 在 IMO 2025、CMO 2024 上达到金牌水平,并在 Putnam 2024 以扩展测试算力获得 118 分(满分 120),显示出强劲的定理证明能力,而这一成绩是在未依赖大规模“题库答案”训练的前提下取得的。
伴随模型同步亮相的技术论文《DeepSeek Math-V2:迈向可自验证的数学推理》显示,该模型在数学推理严谨度、定理证明能力以及多项权威基准上均取得显著突破,部分能力超越了谷歌旗下的 Gemini DeepThink(IMO Gold)。
论文地址:
https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf

论文指出,过去一年,随着强化学习技术将“最终答案正确率”作为奖励信号,大语言模型在数学推理任务上的表现快速提升,从较低水平跃升至接近占满 AIME、HMMT 等高中难度竞赛榜单。
然而,这类方法的根本缺陷也逐渐暴露:正确答案并不等同于正确推理,而定理证明等数学核心任务依赖严谨的逐步逻辑推导,无法用“答案对错”简单衡量。对于没有标准答案的开放问题而言,更无法根据“最终答案”奖励模型。因此,要想推动数学推理能力真正突破,需要验证推理链条的完整性与严谨性,而“自验证机制”成为关键。
这种自验证机制也正是这款 DeepSeekMath-V2 模型的核心突破。
这种自验证机制为什么很重要?因为它正面解决了数学 AI 长期存在的核心问题:算对答案,并不意味着真正懂得推理。

数学尤其强调推导过程的严谨性,任何一步出现跳跃或漏洞,最终结论都不成立。因此,如果只依据“答案是否正确”来训练模型,AI 顶多学会更准确地“猜结果”,却无法保证推理过程本身是可信的。
自验证机制的重要性在于,它让模型具备“检查自己”的能力。
一方面,它能判断自己的推理链是否完整、逻辑是否自洽,从而避免“答案对了但过程错了”的常见问题;另一方面,对于那些没有标准答案的开放难题,自验证使得模型能够在没有人工标注的情况下继续提升能力,这对于真正推动数学研究至关重要。
此外,自验证还让模型在推理过程中能够多次检查和修正自己的思路,让它在使用更多算力时获得更高的正确率——这与人类数学家反复核查草稿的习惯非常相似。
基于这一判断,DeepSeek 在 Math-V2 的研发中将重点从“结果导向”转向“过程导向”。团队首先训练出一个基于大模型的高精度验证器,用于检查定理证明的逻辑正确性;随后再利用该验证器作为奖励模型训练证明生成器,促使模型在提交最终证明前主动发现并修正推理中的漏洞,以提升推理的真实性与可靠性。
为保持验证器的领先性,团队进一步引入“扩展验证算力”,自动标注复杂、难验证的推理样本并用于迭代训练,使验证器与生成器形成持续进化的闭环。
DeepSeek 在论文中强调,自我验证的数学推理不仅适用于标准化竞赛任务,更重要的是,它为处理“无标准答案的开放问题”提供了路线图,使数学 AI 不再局限于“算对题”,而向“像数学家一样思考”迈进。尽管距离真正强大的数学推理系统仍有距离,但 Math-V2 的成果表明,自我验证机制是可行且具有重大潜力的研究方向。
网友怎么看?
值得注意的是,Reddit、Hacker News 等海外开发者社区对这次开源给出了强烈反响,不少人称“DeepSeek 这头鲸鱼终于回来了”。
有网友惊叹,Math-V2 在 Basic 基准上以 10 个百分点的优势击败谷歌 Gemini DeepThink(IMO Gold),远超市场预期;还有人表示,“如果他们稍后发布编程模型,我敢打赌那会更加震撼。”
有 Reddit 用户表示,一直在闷声干大事,因为数学就是大事。
“没有数学,我们不可能达到奇点。随便翻开一篇人工智能论文,你会发现里面全是数学。”
还有用户希望 DeepSeek 能将强大的数学能力用户代码编写上。该用户表示:
“它能够编写代码吗?我希望能有一个数学能力强大的大语言模型来生成我那些复杂且数学性强的代码。虽然不同的模型或许都能写出不错的代码,但在数学软件领域,数学上的正确性至关重要。我已经注意到,针对我感兴趣的一些问题,不同模型在数学正确性上存在分歧。”
还有国外用户表示,其实中国的模型在数学方面的能力都很强,DeepSeek 如此,Qwen 也是这样。
在 X 上,有用户表示,V1 已经发布近两年了,在大家以为数学产品线已经被放弃时,DeepSeek 一直没有放弃,并且一出手性能就很强大。

在国内社区知乎平台上,也有用户表示,DeepSeek 里面搞数学推理的团队可能是最有潜力的一张王牌。
因为数学推理是所有 AI 推理任务里最苛刻的那一个。没有情绪、没有模糊答案、没有‘差不多就行’,每一步都是严格逻辑链,一处错误会全盘报废。

随着 DeepSeek-Math-V2 的开源,大模型数学推理研究的竞争格局正在被重新定义,而“可自验证推理”也正成为推动下一代数学型 AI 的关键技术路径。
参考链接:
https://github.com/deepseek-ai/DeepSeek-Math-V2
https://www.reddit.com/r/singularity/comments/1p7ztyj/deepseek_released_deepseekmathv2/




