
本文最初发布于 THENEWSTACK。

2026 年,每个前沿模型都在宣传,至少提供 100 万 Token 的上下文窗口。但实际上,几乎没有一个模型能够很好地利用所有这些信息。在MRCR v2(多参考检索基准测试实验室报告)中,最佳模型是GPT-5.5,得分为 74.0%。其他模型如 Claude Opus 4.7 得分为 32.2%,被远远地抛在了后面。
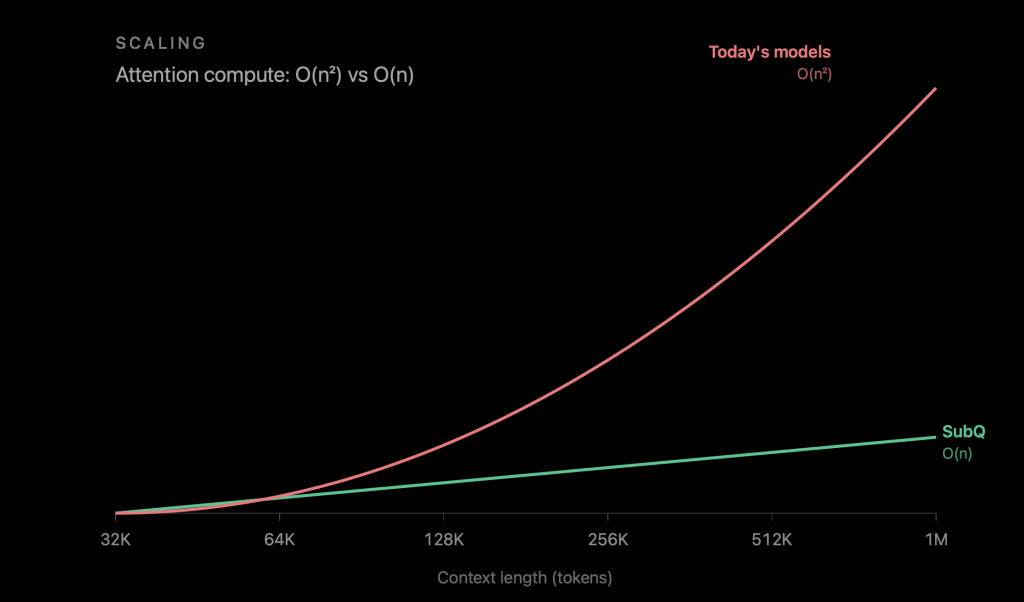
目前,100 万 Toekn 似乎是主要前沿实验室提供的最大上下文窗口。一个主要原因是,这个 100 万 Token 的最大值影响了自2017年以来每一个基于 Transformer 的模型:注意力成本与上下文长度呈二次方增长关系,输入翻倍会使工作量增加四倍。本质上,RAG、代理分解、混合模型架构以及业界构建的其他所有变通方法都是为了解决这个问题而做出的权衡。
Subquadratic是一家位于迈阿密的初创公司。他们在 5 月 5 日推出了其首个模型——一个能够处理 1200 万 Token 窗口的模型,并声称它可以绕过所有这些问题。更重要的是,该公司表示,按照计划,他们将很快提供具有 5000 万上下文窗口的模型。
该公司拥有 11 名博士研究员。他们认为,其 Subquadratic Selective Attention(SSA)架构在计算和内存方面均与上下文长度呈线性增长关系。该公司表示,在 100 万 Token 的规模下,其运行速度比密集注意力快 52 倍;在 1200 万 Token 的“大海捞针”检索任务中,准确率达到 92.1%。这一上下文长度是当前任何前沿模型都难以企及的;而且,其模型在 MRCR v2 测试中获得了 83 分,比 OpenAI 高出 9 分。
这些说法颇为大胆,而且 Subquadratic 也不是首个尝试解决这一问题的团队。该公司发布的基准测试成绩令人印象深刻,其中还包括在 SWE-bench 测试中获得 82.4%的得分,这一成绩超越了 Anthropic 的上一代模型Opus 4.6(得分 81.42%)以及谷歌的Gemini 3.1 Pro(得分 80.6%)。而且,他们的实现成本显著降低。
Subquadratic 通过 API 提供了该模型(具有 1200 万个 Token 的上下文窗口)以及一个编码代理(SubQ Code)和一个深度研究工具(SubQ Search)。
之前的技术
显然,注意力的二次方成本不是一个新问题,SSA 也不是第一个试图解决这个问题的方法。研究线可以追溯到最初的 Transformer 论文,总体模式一直没有变。每种方法都是用一个必要的属性交换另一个属性,在前沿领域里,没有一个能够取代密集注意力机制。
举例来说,在这些不同的方法中,其中一个是固定模式稀疏注意力。在Longformer等模型中,它们实现线性扩展的方式是让每个 Token 只关注一个滑动窗口。当相关信息在附近时有效,否则便无效。
像Mamba、Mamba-2、RWKV、RetNet这样的状态空间模型用一个递归状态(压缩所有迄今为止看到的内容)替换了全对比较。不过,压缩是有损的。Nvidia 在 8B 规模的研究中发现,纯Mamba-2在MMLU和电话簿查找任务上落后于Transformer,只有在重新加入注意力机制后,两者的差距才得以缩小。
对于这个问题,Jamba、Kimi Linear、Qwen3-Next和 Nvidia Nemotron v3 等采用的混合架构提供了实用的答案。它们既保证了大多数层的效率,还保留了几个密集的注意力层用于检索。但其成本效益并不如表面看起来那么理想。一个在 32K Token 时成本下降三分之一的混合模型,在 1000 万 Token 时成本下降仍然是三分之一,因为其保留的密集层仍然需执行 O(n²)的工作量。
最新的研究则另辟蹊径。它们不再试图修复模式或压缩状态,而是学习该关注哪些位置。
例如,DeepSeek 的Native Sparse Attention赢得了 ACL 2025 最佳论文奖。它的继任者 DeepSeek Sparse Attention(DSA)正在DeepSeek V3.2-Exp中交付。DSA 的闪电索引器将注意力路由到一小部分选定的键,而且这些键上的注意力确实是稀疏的。不过,负责筛选的索引器必须针对每个键对每个查询进行评分,这意味着筛选步骤本身的时间复杂度为二次方。
SubQuadratic 首席技术官Alex Whedon告诉 The New Stack,“稀疏注意力的基本含义是:与 Transformer 模型的做法不同,后者在处理 1000 个单词时,会考察这 1000 个单词之间所有可能的关系,即组合个数为 1000 的平方。而稀疏注意力则意识到,其中只有一部分关系真正重要,因此只处理这些重要的部分。“
SSA 的不同之处
SSA 的卖点在于它做到了 DSA 试图完成的工作,但避免了索引器陷阱。选择是内容依赖的。对于任何给定的查询,模型都会根据查询和键中实际包含的内容来挑选重要的关系——最重要的是,选择机制本身不会呈二次方增长。
Whedon 说,“对于提示 A,第一和第六个词对彼此来说很重要。对于提示 B,可能是第二和第三个词。每个输入情况都不同。”
根据 Whedon 的说法,混合模型提供了“标量效益”,但纯粹的次二次方机制提供了一个缩放法则优势。在基准测试中,SubQ 报告了 128K 时 7.2 倍的速度提升,以及 1M 时 52.2 倍的速度提升。
基准测试
在 128K 的RULER上,SubQ 的得分为 97.1,而 Opus 4.6 的得分为 94.8。在 MRCR v2 上,它与其他前沿模型的差距比其他前沿模型之间的差距要大。
在SWE-Bench Verified上,SubQ 报告了 82.4%的得分,略高于 Opus 4.6 的 81.4%和 Gemini 3.1 Pro 的 80.6%。在没有前沿模型运行的 1200 万个 Token 处,SubQ 在一项大海捞针的基准测试中保持了 92.1%的得分。
需要注意的是,按照该论文的说法,因为推理成本高,每个模型只运行了一次。正如论文所承认的那样,在 SWE-Bench 测试中,模型得分差异可能来自于模型治理工具(Harness),也可能来自于模型。而且,根据 Whedon 自己的描述,SubQ 模型“比大实验室的模型小很多”。
Subquadratic 现在正准备推出什么
该公司正在推出两款 Beta 产品:一个是 API,暴露完整的 1200 万 Token 的窗口和 SubQ Code;一个基于同一模型构建的 CLI 代理。两者都在 neoclouds 上运行,而不是在主要的超大规模云服务提供商那里——首席执行官 Justin Dangel 说,“那非常昂贵”。
该公司不会开源权重,但计划为企业提供免费培训工具,方便他们自己进行岗位培训。5000 万 Token 的上下文窗口预计将在第四季度推出。
然而,这里有一个警示性的故事。Magic.dev 在 2024 年 8 月宣布了一个 1 亿 Token 的上下文窗口模型,声称有1000倍的效率优势。凭借这一点,他们筹集了超过5亿美元。但截至 2026 年初,没有公开证据表明LTM-2-mini 在 Magic 之外的地方被使用。
融资
迄今为止,Subquadratic 已经筹集了 2900 万美元,估值为 5 亿美元,投资者包括前软银愿景基金合伙人 Javier Villamizar 和 Tinder 联合创始人 Justin Mateen。该公司之前名为Aldea,在转型之前专注于语音模型的研发。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://thenewstack.io/subquadratic-12-million-context-window/




