
亚马逊云科技是 AI 时代最大的“造星平台”吗?
恐怕是的。
在拉斯维加斯 re:Invent 2025 的主舞台上,年轻 AI 公司的接连登场,再次验证了这位云计算老大哥的号召力:在啤酒和轮盘的烘托下,亚马逊云科技在新一代创业者眼中依旧性感,还没有成为年轻人口中的 “Boring Old Guy”。

比如,成立不到两年、估值已达 31 亿美元的 Decart AI,凭借全球首个实时视频生成模型迅速蹿红。其创始人在 re:Invent 上表示:“Amazon Trainium3 是我们创造出‘实时视觉智能’这一全新技术的关键推动力。”
另一家以视频理解见长的 TwelveLabs,则把自己的数据基础设施核心建立在 Amazon S3 之上。创始人 Jay Lee 形容公司是“诞生于亚马逊云科技的公司”,Amazon S3 Vectors 的加入,让他们具备了规模化交付视频智能解决方案的能力。
更抢戏的是苹果的再次现身。
去年,苹果首次站台,宣布采用亚马逊云科技芯片训练 Apple Intelligence。今年,苹果进一步分享了一项技术实践成果:苹果已经将部分核心服务用 Swift 语言重写,并将工作负载迁移至 Amazon Gravition 芯片运行,最终实现 40%的性能提升与 30%的成本降低。

“从 x86 架构的过渡几乎是无缝的,Java 服务的迁移近乎直接替换,这要归功于 Amazon Graviton,”云系统和平台部门副总裁 Payam Mirrashidi 分享,“苹果早在十多年前就已转向 ARM 架构以驱动我们的设备。如今,我们同样看到了基于 ARM 的 Amazon Graviton 在基础设施层面带来的价值——它让我们从基础设施中获得了更高回报。更高的吞吐量意味着所需实例更少、成本更低、环境足迹更小,这对我们的客户和地球而言是一场双赢。”
可以说,这些估值飙升的新锐和谨慎的大厂,都对亚马逊云科技的考量达成了共识。这种共识这可能来自亚马逊云科技于基础设施层面,大胆的自我革命和不知疲倦的工程优化。
一场果决的自我革命
都说“船大难掉头”,但对于奉行“两个披萨原则”的亚马逊云科技而言,倒也未必如此。当 AI 工作负载的复杂性与苛刻要求,撞上云计算固有的服务形态,亚马逊云科技几乎没什么犹豫——作为曾经最坚定的无服务器(Serverless)倡导者,他们主动打破了亲手建立的概念边界。
2014 年,亚马逊云科技推出 Amazon Lambda ,初衷是让开发者彻底摆脱“服务器管理”这件繁重又低效的事情。
随着云计算进入更复杂、更大规模的应用场景,亚马逊云科技发现客户的需求已经远远超出了当年的假设——他们一方面希望希望接入 Amazon EC2 技术、需要大规模场景下的可预测性能、更高的网络吞吐量、亚毫秒级延迟 ,也不愿为了这些需求牺牲 Amazon Lambda 与生俱来的简洁性。
亚马逊云科技很早意识到这一结构性矛盾。几年前,它就将 Amazon Lambda 团队与 Amazon EC2 团队整合到同一个组织下,不再将计算僵硬地分类为 “服务器、容器、无服务器” ,而是将其看作一个选择光谱。
今年的 re:Invent,亚马逊云科技给出了这一战略的关键拼图——Amazon Lambda 托管实例(Amazon Lambda Managed Instances)。它允许开发者在专用的 Amazon EC2 上运行 Lambda 函数;在用户自主选择实例类型和硬件规格的同时,仍能享受到 Amazon Lambda 带来的便利。

这是一项足以改变 Serverless 定义的更新。亚马逊云科技实际上为大型企业开辟了一条从 Amazon EC2 平滑进入 Amazon Lambda 的迁移路径,让那些原本因性能、成本或硬件需求而必须留在 Amazon EC2 上的稳态工作负载,也能无缝衔接 Amazon Lambda。
FaaS 与容器服务的界线也因此进一步模糊。无服务器不再是一个要么接受,要么放弃的选择,而是一系列可按需调节的服务。
亚马逊云科技的第二场自我革命,则来自底层硬件。
在本届 re:Invent 大会上,亚马逊云科技发布了迄今为止性能最强、集成度最高的 CPU Amazon Graviton5。

Amazon Graviton5 最显著的变化,是从 Amazon Graviton4 的双芯片设计,回归到单封装架构。这一调整带来了根本性的提升:192 个核心共享统一的内存访问路径,消除了跨芯片通信带来的结构性延迟。相比之下, Amazon Graviton4 的两颗芯片之间虽然 Coherent Link 链接,但跨芯片访问仍会引入协议开销与排队等待,某些场景下延迟甚至可能增加两倍。
在单封装的基础上, Amazon Graviton5 实现了规模与效率的飞跃:在单个封装内集成 192 个核心,并将 L3 缓存容量提升至前代的 5 倍以上。实际测试中,基于 Amazon Graviton5 的新一代 M9g 实例,性能比基于 Amazon Graviton4 的 M8g 实例提升约 25%。凭借这一表现, Amazon Graviton5 已具备与 AMD 的 192 核、Intel 的 144 核服务器芯片直接竞争的规模与实力。
展示性能参数之外,苹果又一次站上了 re:Invent 的主舞台。
去年,苹果 AI 与机器学习高级总监 Benoit Dupin 曾透露,与传统的 x86 实例相比,使用亚马逊云科技的 Amazon Graviton 和 Amazon Inferentia 芯片后,处理机器学习工作负载的效率提升超过 40%。
苹果云系统和平台部门副总裁 Payam Mirrashidi 这次则披露了更多合作内容:运行在 Amazon Graviton 上的 Swift 应用,每天处理着数十亿次请求;苹果已将多项核心服务用 Swift 重写并迁移至 Amazon Graviton 平台,最终获得了 40% 的性能提升与 30%的成本降低。
与苹果的合作释放出重要信号: Amazon Graviton 的价值已超越单纯算力或性价比,x86 向 ARM 的迁移不再只是早期尝试者的冒险,而是成熟企业可以大规模推进的选择。
极致的性能压榨和工程优化
亚马逊云科技实用计算高级副总裁 Peter DeSantis,和亚马逊云科技计算与机器学习服务副总裁 Dave Brown 的主题演讲,历来是观察云基础设施演进的标尺。2025 年,当 AI 成为一切工作负载的核心,亚马逊云科技在基础设施上的创新,都指向一个明确靶心——为 AI 重塑成本和效率。
从硅基芯片、软件栈再到核心服务,亚马逊云科技正以前所未有的深度,对 AI 的算力、推理与数据基础设施进行“性能压榨”。
性能优化的起点,是对算力单元的重构。Amazon Trainium3 芯片及以其为核心的 Amazon EC2 Trn3 UltraServers,共同构成了为超大规模 AI 训练而生的系统级答案。

Amazon EC2 Trn3 UltraServers 是由 144 颗 Amazon Trainium3 芯片构成的单一 AI 超级计算机,提供 360 petaflops 的 FP8 计算能力与 20 TB 高带宽内存,计算与内存带宽相比前代分别提升 4.4 倍与 3.9 倍。实际效能更为关键:运行 GPT-OSS-120B 模型时,每兆瓦功耗输出的 Token 数量是 Amazon Trainium2 的 5 倍以上。
在发布 Amazon Trainium3 同时,Peter DeSantis 披露 Amazon Trainium4 正在开发中,承诺提供比 Amazon Trainium3 高 6 倍的 FP4 计算性能、4 倍内存带宽和 2 倍高带宽内存容量。这将确保亚马逊云科技在 AI 芯片领域的长期领先地位。
比一系列令人眼花缭乱的性能数字更有“杀伤力”的指标是,投资 Amazon Trainium3 是个省钱的“生意”,Peter DeSantis 在演讲中表示,Amazon Trainium3 可以将训练成本降低 40%。
如果一款芯片可以同时实现性能升级、成本降低、效率提升,那对于 AI Infra 构建者而言无异于“梦中情人”。顶尖 AI 公司因此齐聚 Amazon Trainium 生态下,验证了这条路径的价值: Anthropic 在 Amazon Trainium 上训练和运行 Claude 最新一代模型。Decart AI 则借助 Amazon Trainium3 与 NKI 优化实时视频生成模型,实现了 4 倍帧率性能提升和 80% 的张量核心利用率,远超传统 GPU 系统。

谈及对 AI 落地工程的优化,向量能力是另一个不可或缺的维度。
此次发布会中,亚马逊云科技给足了诚意,宣布向量搜索在全平台落地,客户无需学习全新的技术栈,也无需管理复杂流水线,亚马逊云科技将向量能力集成到各类服务中,例如 Amazon OpenSearch。
向量搜索能力的全平台落地,在效率和成本上都带来的优势——客户无需重新学习全新的向量数据库,也无需为新的服务付费。
向量服务的底座支撑,是此次全新发布的 Amazon Nova 多模态嵌入模型。它实现了向量跨模型搜索的功能,支持文本、文档、图像、视频和音频,将所有这些概念转换为共享向量空间,创建对数据的统一理解。
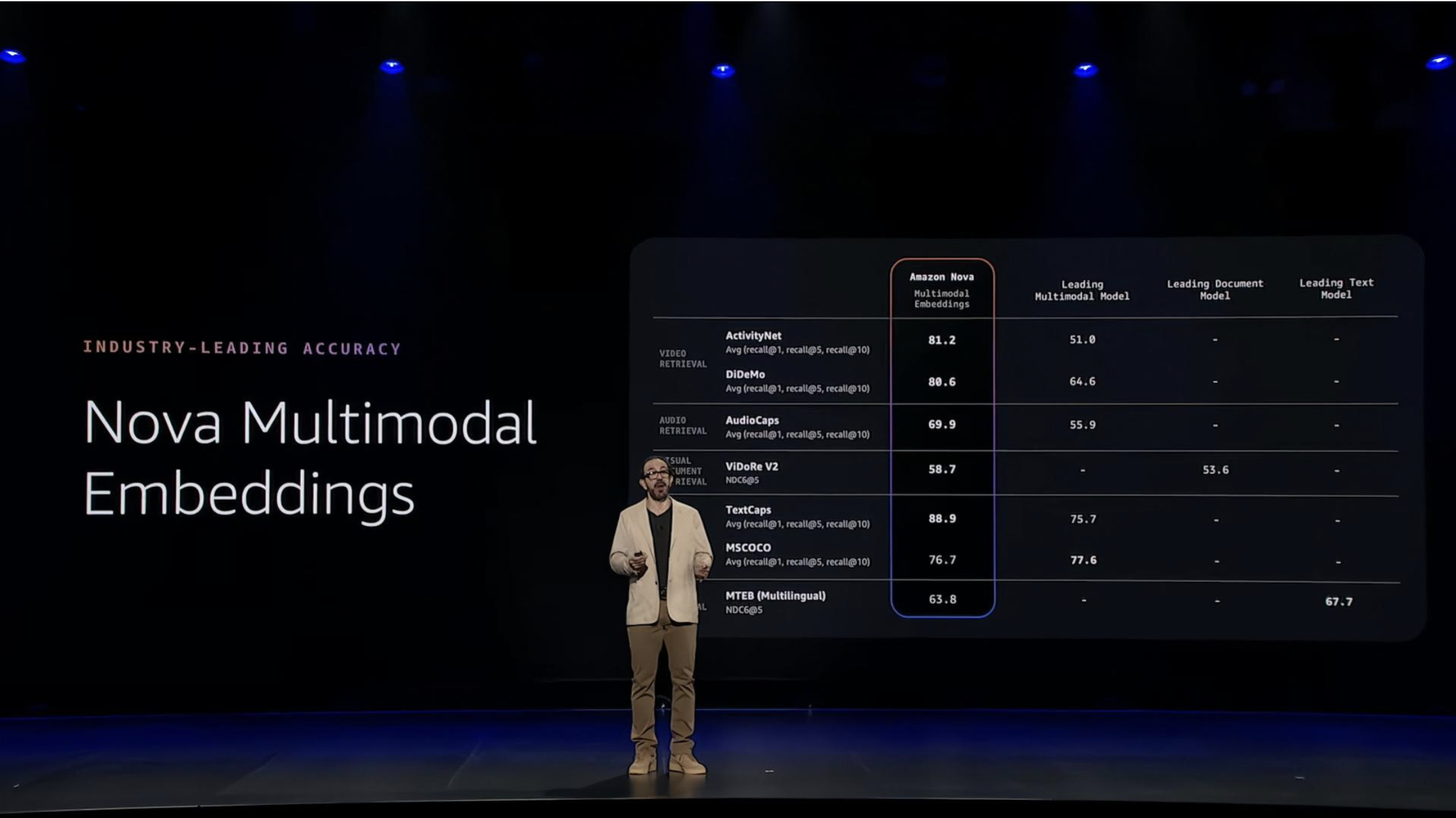
最令人感到振奋的应用,莫过于 Amazon S3 Vectors。它将向量存储能力整合至亚马逊云科技最大的数据服务 Amazon S3 中,Amazon S3 的原生成本结构与海量规模为向量数据库提供了强力支撑,可实现数十亿级向量的亚 100 毫秒级查询响应。
Amazon S3 Vectors 的核心功能,已经滋养出了前文提到的 TwelveLabs 这般的顶尖视频模型公司。
TwelveLabs 将其核心数据平台构建于 Amazon S3 之上。借助 Amazon S3 Vectors,该公司得以直接在存储原始视频的 S3 存储桶中,处理并存储数十亿个向量嵌入。这消除了数据迁移与架构重构的复杂性,使其能够高效处理数百万小时的视频数据。

此外,在 2024 年作为“传闻”见诸媒体的“地幔计划 Project Mantle”,在 2025 年被正式发布,成为了现实。
从芯片到实例,再到 Amazon Neuron SDK ,完成高效 AI 推理的组件已经齐全,但管理方法和平台尚有不足,面对即将到来的海量并发推理任务,亚马逊云科技显然不准备把管理的复杂性完全留给客户。
此次发布的 Amazon Project Mantle 推理引擎,则通过构建能实时自适应的架构,应对推理请求的各阶段流程需求不同、高并发状态下客户需求多样的挑战。
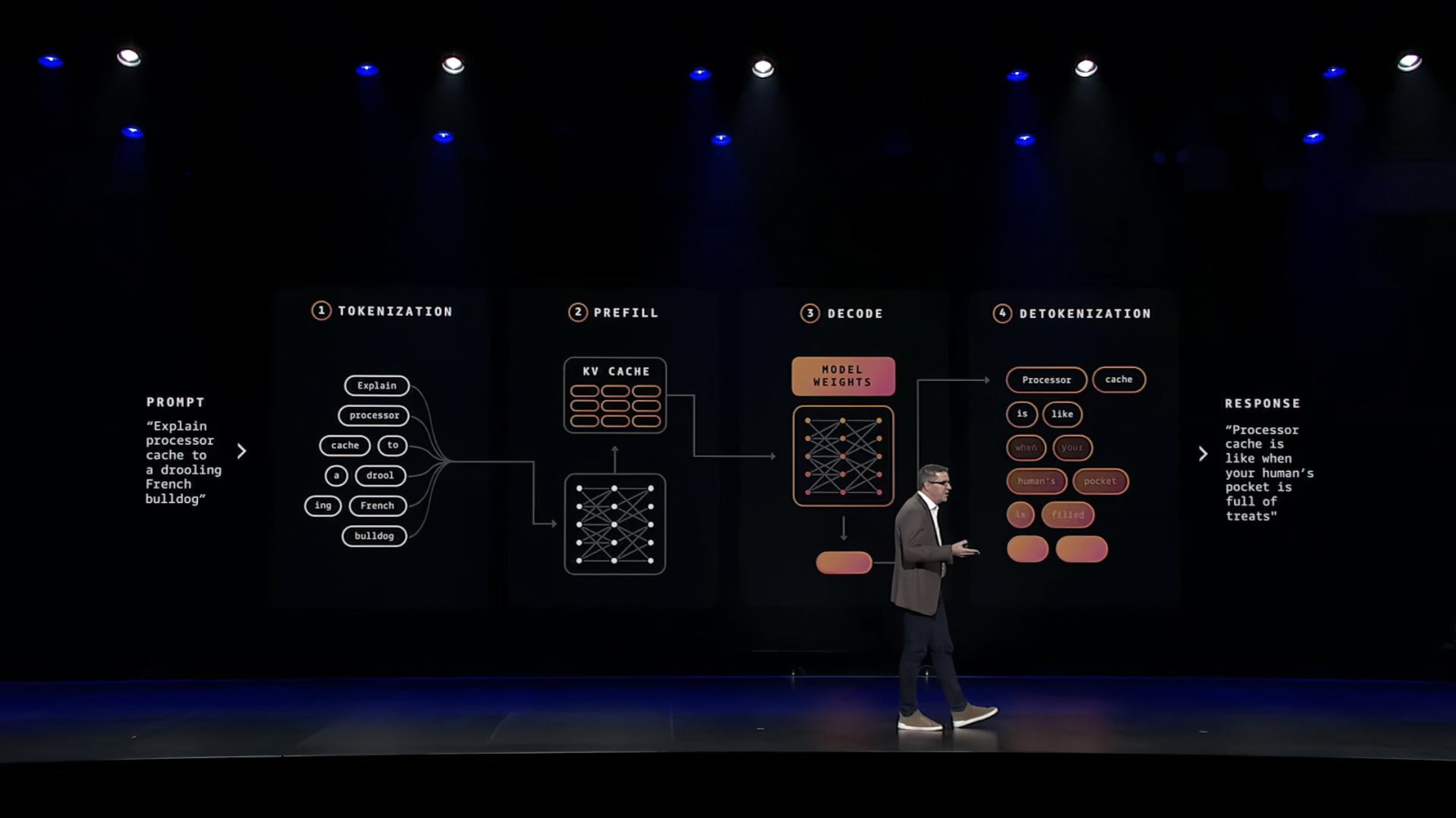
Amazon Project Mantle 通过三通道的优先级管理、独立客户队列、基于日志的持久化状态恢复等机制,将充满不确定性的推理过程转变得可预测。
在服务层级上,系统让客户自主定义推理需求层级,并将请求分配到不同优先级的通道:Priority 通道面向实时、延迟敏感的交互场景,Standard 通道适用于稳定可预测的工作负载,Flex 通道适合后台任务、更注重成本效率。
公平性问题上,Amazon Project Mantle 为每位客户分配独立队列,确保一个客户的突发情况不会影响其他客户性能。
同时,为了在长时间运行请求下保证架构的可靠性,Amazon Project Mantle 引入了日志系统,使 Amazon Bedrock 可以持续捕获每个请求的状态,一旦出现问题,就能从断点处精确恢复。日志系统也使得更精细的微调策略得以实现:在 Amazon Bedrock 中,微调被视为一项长时间运行的任务,实时流量激增时暂停,流量回落微调会从断点处继续执行。
在重新设置推理引擎时,亚马逊云科技还重点考虑了有严格隐私与合规要求的企业。Amazon Bedrock 集成了机密计算(Confidential Computing)技术,使运维人员无法访问运行环境,确保请求在经过客户认证的环境中执行。
考虑到与苹果、OpenAI 以及一种硅谷独角兽广泛的、深度的合作,在所有参与构建未来 AI 的公司面前,亚马逊云科技实质上正成为最值得依赖、也最具前瞻性的云计算伙伴。
首先,亚马逊云科技拥有“自我重构”的决心。 从打破无服务器边界、推出 Amazon Lambda 托管实例,到改变 Amazon Graviton5 芯片架构,亚马逊云科技不惜解构自己确立的产品形态与规则。这清晰传递出一个信号:在 AI 重塑一切的未来,任何固有的架构、概念与教条,都必须为更高的效率、更强的性能和更切实的客户价值让路。放下包袱,方能定义未来。
其次,在过去几天的发布中,亚马逊云科技的高管们多次提到,公司在很多模块都拥有全栈自主生产、调优的工程能力,考虑到大部分云计算企业仍然执拗于“堆卡”“GPU 优先分配权”,这为亚马逊云科技带来了难得的“工程纵深”。 亚马逊云科技拒绝捷径,从芯片、服务器到服务层,建立起极致的性能与效率优势。它同时投入专用 AI 算力与通用 CPU 算力,表明其理解 AI 革命的基石依然是坚实、可靠且高效的基础设施。
第三层,则是不断扩大的生态壁垒。从芯片到模型,从数据到开发工具,亚马逊云科技提供的是一套可托付、可扩展、持续进化的“全栈能力地图”——它不仅提供算力,更提供确定性。
最终,这一切技术创新与战略选择,都指向亚马逊云科技一直坚持的一点:AI 的形态在变,应用的写法在变,但云计算最基本的价值——安全、可用、弹性、成本与敏捷性——从未过时,反而愈发成为决定性竞争力。亚马逊云科技在这一点上重新把行业的注意力拉回了基础:AI 的未来,必须建立在一个稳固的地基之上。

2025 亚马逊云科技 re:Invent 中国行即将启幕!12 月 18 日开始,北京、上海、深圳、成都四城线下巡演及线上专场将同步开启,无论你是云计算新手还是技术老兵,都将从高阶演讲、实战内容、技术分享和专家互动中受益。点击链接,立即注册,抢占席位,把握 Agentic AI 时代的新机遇!




