
近日,总部位于美国旧金山的人工智能研究机构 Essential AI 正式发布并开源其首个大语言模型 Rnj-1(读作“range-1”,致敬数学家拉马努金),包含基础版(Base)与指令微调版(Instruct)两个版本。该模型基于 Gemma 3 架构打造,将上下文窗口扩展至 32k,在代码生成、智能体工具调用、数学科学推理等核心任务中表现优异。
Essential AI 由 Ashish Vaswani 与 Niki Parmar 共同创立,两人此前在 Google Brain 任职,参与提出了 “Transformer” 架构,该架构被视为现代大规模语言模型(如 GPT‑4、Gemini 系列模型)和自然语言处理技术的基石。
公司成立于隐秘模式(stealth mode)阶段,并于 2023 年 12 月正式公开,从包括 Nvidia、AMD、Google LLC 等多家科技巨头及风险资本处获得超过 5600 万美元的 A 轮融资。公司定位为构建“开放平台”,致力于推动前沿 AI 技术的开放研究与工程化应用。
首款模型表现如何
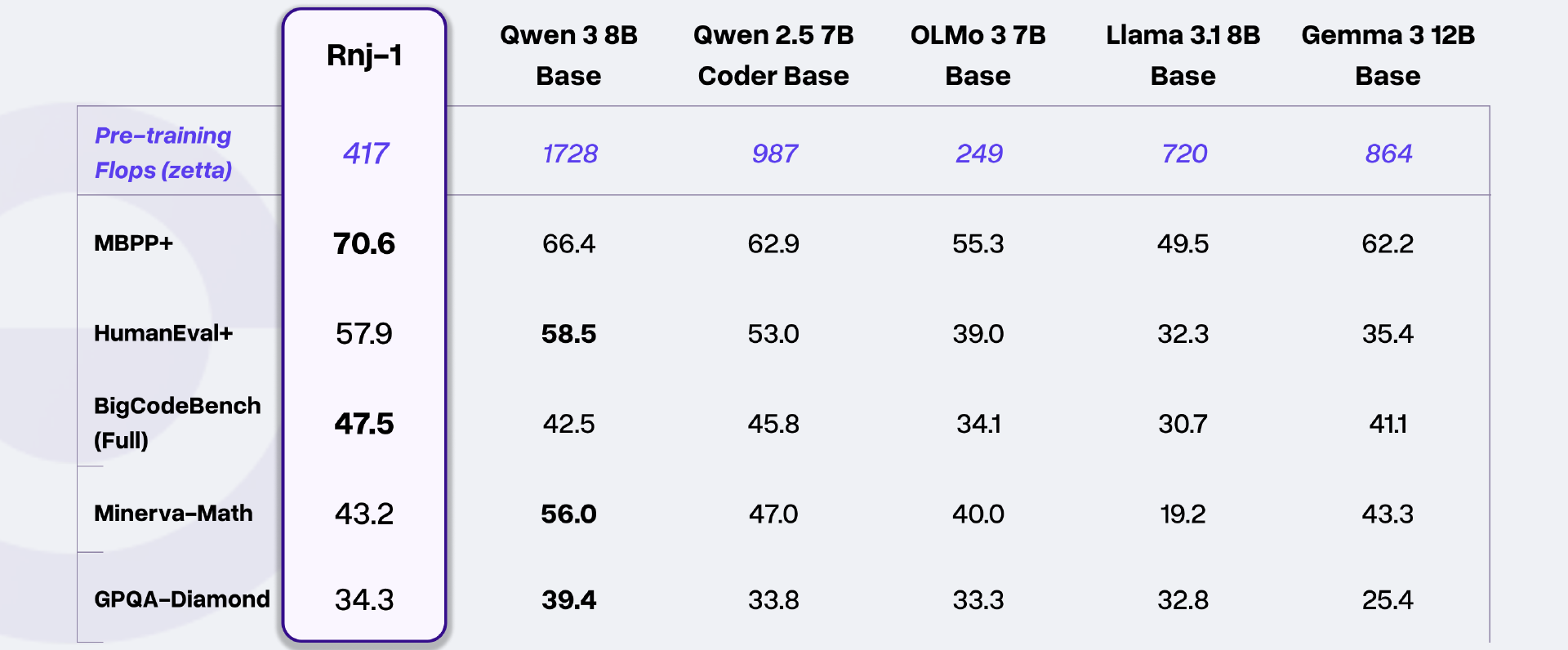
据介绍,Rnj-1 是一款 8B 参数规模的大语言模型,采用全局自注意力机制与 YaRN 技术实现 32k 长上下文支持,其预训练算力消耗为 417 zettaFLOPs,在多项权威评测中展现出超越同量级模型的综合能力,部分指标甚至比肩更大参数规模的开源模型。
多任务性能领跑同量级模型
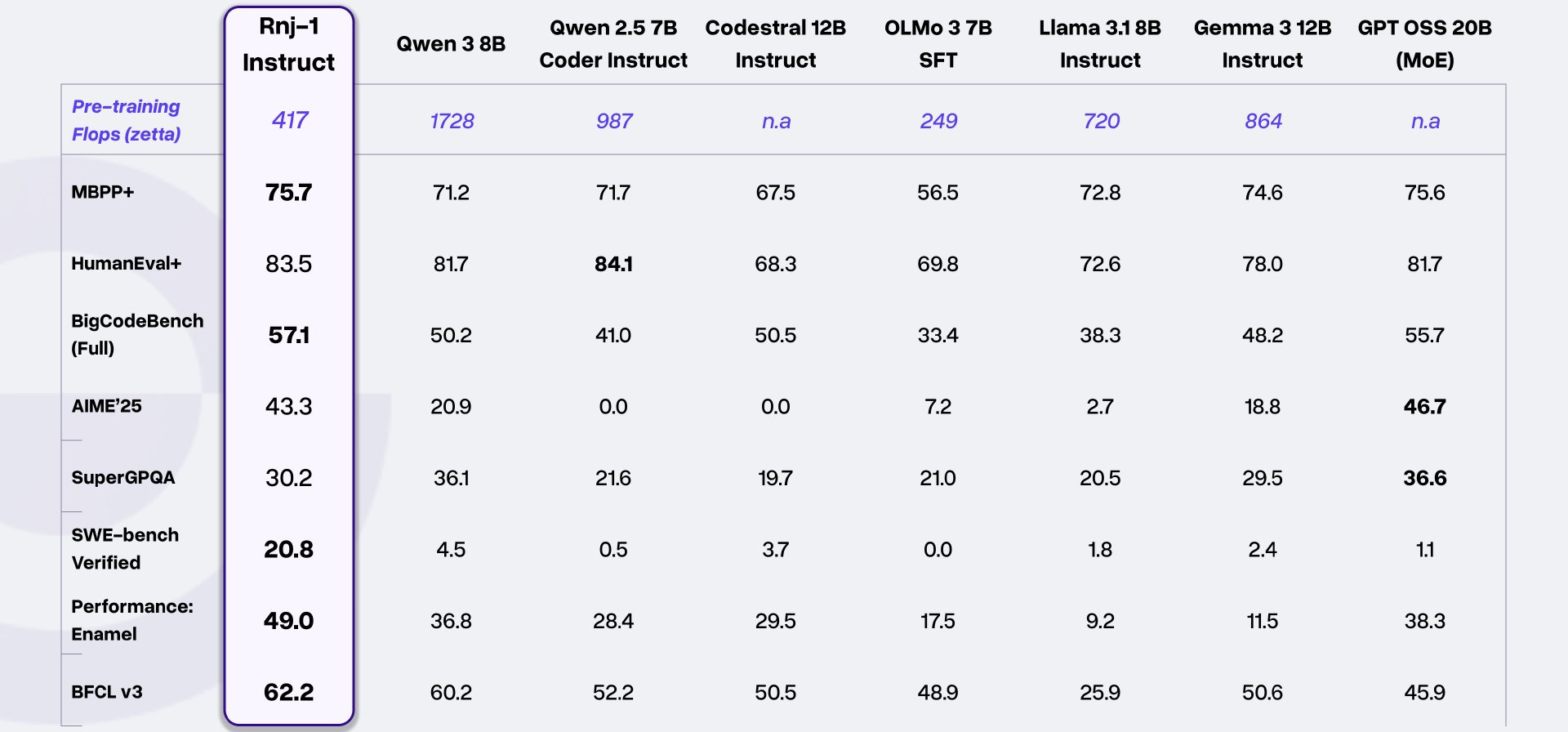
在代码生成类任务中,Rnj-1 Instruct 表现尤为突出:在 HumanEval+评测中得分 83.5,MBPP+评测得分 75.7,BigCodeBench(Full)评测得分 57.1,不仅领先 Qwen 3 8B、Llama 3.1 8B Instruct 等同量级模型,在 BigCodeBench 任务中还超越了 GPT OSS 20B(MoE)。此外,其在 SWE-bench Verified(软件工程师实际任务评测)中得分 20.8,远超同量级模型的平均水平(多数不足 5 分),具备解决真实软件工程问题的能力。
生成示例:
https://vimeo.com/1143853378/8df3376a1a?fl=pl&fe=sh
在数学与科学推理领域,Rnj-1 Instruct 在 AIME'25(高阶中学数学任务)中斩获 43.3 分,大幅领先 Qwen 3 8B(20.9 分)、Gemma 3 12B Instruct(18.8 分);基础版模型在 Minerva-Math 数学评测中得分 43.2,与 Gemma 3 12B Base 持平,展现出扎实的基础数理能力。在工具调用评测 BFCL v3 中,Rnj-1 Instruct 得分 62.2,同样位居同量级模型前列。
高效的量化与推理性能
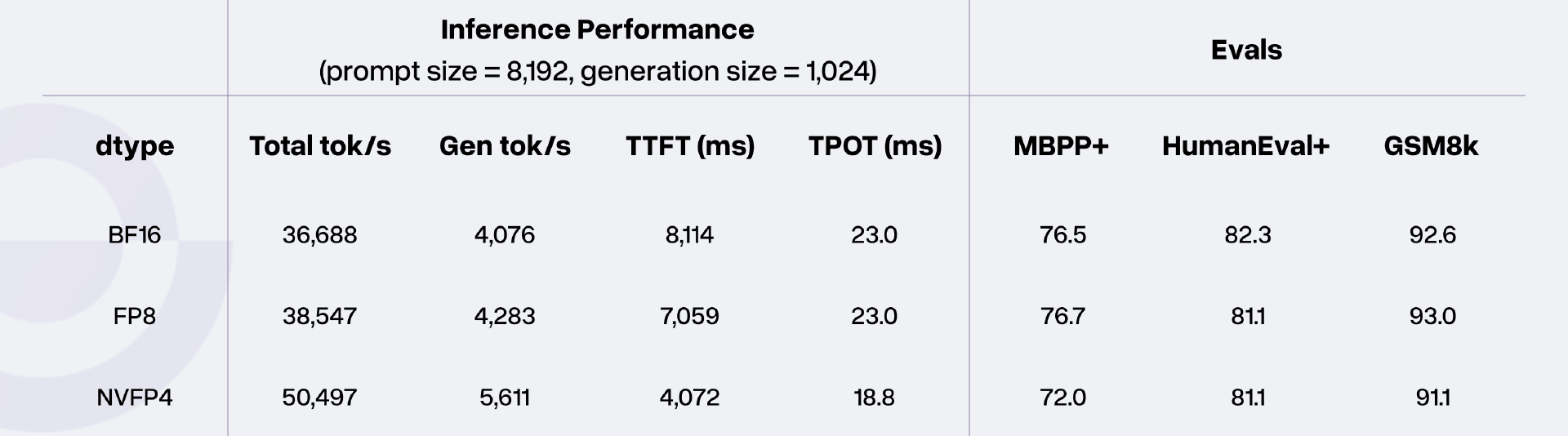
Rnj-1 具备不错的量化鲁棒性,在 NVIDIA B200 GPU、批次大小 128、KV 缓存为 FP8 的测试环境下,不同精度的推理表现如下:
BF16 精度下,总 token 吞吐量达 36,688 tok/s,生成 token 速度为 4,076 tok/s,同时保持 MBPP+ 76.5、HumanEval+ 82.3 的高任务得分;
切换至 NVFP4 低精度后,总 token 吞吐量提升至 50,497 tok/s,生成速度达 5,611 tok/s,且核心任务得分无显著下降,兼顾了推理效率与能力保留。
独特的智能体与工具使用能力
“Rnj-1 Instruct 在 Agentic 编码方面遥遥领先,这是我们的目标能力之一。”团队表示。
据介绍,Rnj-1 Instruct 支持多轮对话下的端到端应用生成,可通过学习使用性能分析工具迭代优化代码效率,在 Enamel(高效算法代码生成任务)中得分 49.0,远超 Llama 3.1 8B Instruct(9.2 分)、Gemma 3 12B Instruct(11.5 分)等同量级模型,展现出“代码生成-优化-验证”的全流程能力。
示例演示:
https://vimeo.com/1143841317/44adfbd044?fl=pl&fe=cm
战略转向:从“研产兼顾”到“深耕基础模型”
Rnj-1 的诞生源于 Essential 在 2025 年的战略调整,其核心研发由 Ashish Vaswani 牵头,团队聚焦模型底层能力构建,以“打造智能工具”为目标,完成了从战略转型到技术落地的完整闭环。
在发布模型的同时,Essential 坦诚,2025 年 2 月,公司面临研发与产品业务资源争夺的困境,最终决定将核心精力转向基础模型研发。团队坚信“掌握 AI 能力的底层技术是打造持久价值 AI 公司的关键”,且开源 AI 将成为行业未来,因此确立了“为开源生态做实质性贡献”的核心目标,并制定了 2025 年底的四大任务:验证核心研究方向的可行性、建立严谨的实验与工程标准、打造自用高效智能工具、向开源生态输出优质模型。
压缩是模拟智能的必要步骤
随即,Essential 立刻遇到了一个迄今为止最根本、最带有“灵魂拷问”意味的选择:到底要押注预训练(pre-training),还是后训练(post-training)。
“在 DeepSeek R1 发布后,整个行业都沉浸在‘RL(强化学习)无所不能’的叙事里,但我们认为:压缩是模拟智能的必要步骤,而语言模型的预测式预训练任务才是更合理的出发点。我们在预训练早期就观察到模型出现了‘反思能力’和‘探索式推理’的迹象,这进一步印证了我们的判断:强预训练是下游能力的决定性基础。”Essential 表示。
Essential 认为,他们处理“预训练 vs 后训练”这一问题的方式,也象征着其整体的决策哲学:
团队会根据其在长期路线图中的重要性,下注关键的研究与工程方向;
并将每个押注拆解成多个可执行的里程碑,再依据手头资源优先排序。
“在一个充满噪音、每天都有‘新范式’冒出来的行业里,坚持少数高信念方向虽然痛苦,但却是成功的必要条件。”Essential 表示,“我们也清楚,并非所有研究方向都会成功,但专注基础原理、坚持长期主义,会赋予我们在失败后迅速修正方向和继续前进的能力。”
四个高层次目标
Essential 为 2025 年底设定了四个更高层次的目标:
验证团队押注的研究到底是“有生命力”还是“走不通”。
建立无可挑剔的实验严谨性与工程标准。
构建一个对自身研发真正有用的模型。
为开源 AI 生态做出实质性贡献。
其中,目标 1 和 2 的达成,将为目标 3 和 4 创造最佳条件。
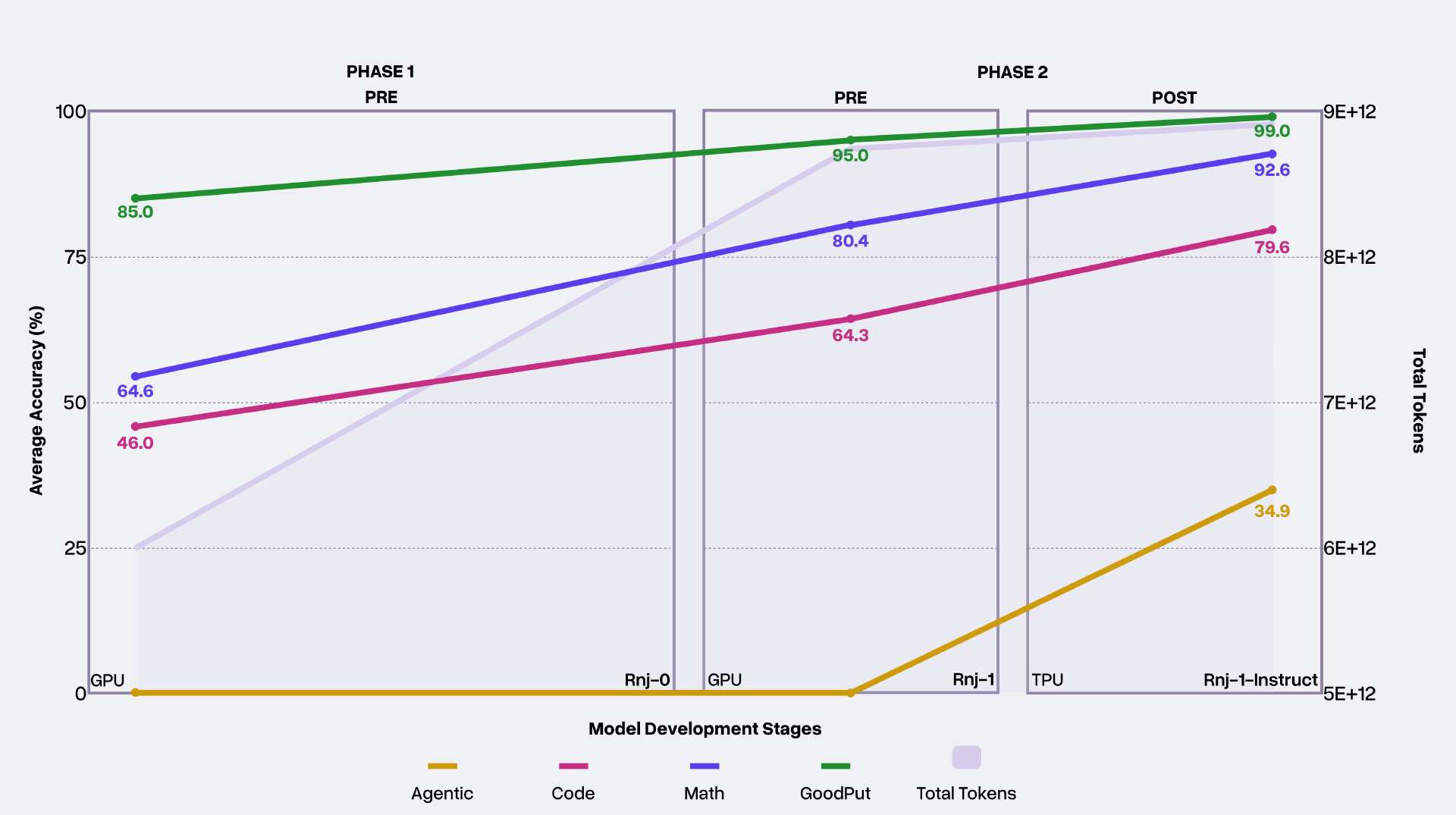
为了实现这些目标,Essential 将全年划分为两个阶段,每个阶段都以一次更大规模的旗舰模型训练作为收官。这些大模型训练用于在更大规模下验证其最有希望的研究成果。
在早期探索中,Essential 使用 2 亿到 20 亿参数的模型快速遍历实验空间;最终选择 80 亿参数的稠密 Transformer 作为旗舰规模,在迭代速度与方法评估深度之间取得最佳平衡。
越来越多证据显示,“能力涌现”的某些迹象在小模型上就会出现,Essential 团队相信小规模模型中还存在某些“稳定信号”,只是目前尚未完全掌握。然而,并非所有小模型信号都可靠,因此必须依赖更大规模、更昂贵的训练来获得更高信噪比的结果。Essential 认为这将是未来一个重要的研究方向。
研究成果
长期来看,Essential 希望模型能够自动对数据进行表示、转换与融合,在预训练过程中不断优化可量化的能力表现。在研究层面,团队取得多项关键成果。
首先,在“数据分类体系(data taxonomies)”上的研究,使其得以提出一种新的方法:在加入“数据重复惩罚”的前提下,同时实现对数据分布的聚类与混合。 STEM(科学、技术、工程、数学)方向能力的大幅提升,很大程度上源于这项工作。
其次,Essential 证明了 Muon 优化器在实际使用中优于 AdamW,并开发了针对大模型规模的分片(sharding)策略。两次旗舰模型训练都受益于 Muon 更高的 token 使用效率。更全面地理解优化器行为与神经网络训练动态,是 Essential 重视的长期研究方向。
然后,在 Rnj-1 上,Essential 做出了一项重要押注:在前所未有的规模上建模程序执行过程。团队认为,大模型不应只停留在理解代码层面,而必须真正模拟程序在不同环境中的关键行为。”为了让基座模型学会迭代优化代码,Essential 还投入研究“代码演化(code evolution)”的基础模式。两项押注均在小模型上经过了充分验证,Essential 认为它们显著提升了 Rnj-1 的软件工程能力。
由于算力限制,Essential 尚未能在大模型上完全隔离、拆解各项研究带来的具体能力增益,但这是其接下来会重点推进的方向。
当 Rnj-1 进入预训练的最后阶段时,团队已经能够确认:它具备了相当有价值的数学能力、编程能力以及科学知识沉淀。接下来必须回答的问题是:需要多少监督微调,才能激发它的指令遵循能力、通用推理能力,以及处理长交互与真实世界复杂任务的能力?——这些任务通常只有更大规模的模型才能胜任。
Essential 的后训练(post-training)方法受到现有研究的启发,包括:
通过 YaRN 的长上下文中期训练
Nemotron 的方法
简单 Agent 环境
Essential 设定了三项核心任务:
探索不同定向数据分布如何影响模型的推理与 Agent 能力
通过与模型实时交互来观察质的能力提升
收集下游反馈,为下一轮预训练押注提供依据
“总体而言,我们已经非常接近年初设定的目标:从零开始构建一个对我们自身真正有用的智能工具。”Essential 表示,“再经过几个季度,我们预计模型便能满足我们内部工程与科研需求。”
Essential 强调,“在所有工作中,我们始终遵守一个铁律:必须深入训练数据本身,必须亲自检查我们所评估的任务。”
基础设施建设
对于基础设施建设,团队的工作围绕一个核心目标:消除一切会阻碍实验迭代速度的瓶颈,无论是哪类 workload。
Essential 的加速器基础设施分布在两个云上,横跨两种截然不同的平台:Google TPU v5p(ASIC) 和 AMD MI300X GPU 。
今年初,JAX 对 AMD 芯片的支持非常有限,Essential 1.2 Exaflop 的算力像两座互不连通的孤岛。而如今,团队成员已经可以在统一的 JAX 训练框架 中无缝开发模型,同时支持 TPU/GPU,并能将任务调度到任意平台运行。
Essential 构建了节点自动恢复系统,使 badput(因节点故障导致的无效算力)减少了 三分之二。旗舰训练在 MI300X 上达到了约 50% 的理论峰值 FLOPs,未来目标至少提升到 65%。
在数据基础设施方面,Essential 从 GCP 托管服务迁移至 GKE 上的 Kubernetes + Spark 集群,并使用 spot 实例大幅降低成本。同时,团队构建了一套经过严格测试的通用数据作业,并放入共享工具包,使其能在不同项目间高效复用、减少学习成本。
“有无数令人难以抗拒的想法争夺我们的注意力。”Essential 团队表示,比如其正热衷于条件计算(conditional computation)、扩展并强化模型处理更长上下文的能力,以及低精度训练。在中期,团队将继续推进关于“压缩”的核心论点,扩展其希望模拟的程序行为的类型与范围,以及代码演化。诸如强化学习等用于培养复杂推理能力的扩展性方法,将很快出现在路线图上。




