
编者按:本文是松子(李博源)的大数据平台发展史系列文章的第二篇(共四篇),本系列以独特的视角,比较了非互联网和互联网两个时代以及传统与非传统两个行业。是对数据平台发展的一个回忆,对非互联网、互联网,从数据平台的用户角度、数据架构演进、模型等进行了阐述。
前言,本篇幅将进入大家熟知的互联网时代,数据平台发展史仅是自己经历过由传统数据平台到互联网数据平台发展一些简单回忆,在这一篇章中将引用部分互联网数据平台架构,在这里仅作案例。
我相信很多从传统行业转到互联网时是各种不适应,适应短则几个月,长则一年以上。进入到互联网有种感觉,它是一个擅长制造流行新概念的行业,“数据平台“,”数据产品“也不幸免。数据平台这词 Data PlatForm 也无从考究是从什么时间点被提出的,仅知道自己刚进互联网时”数据平台“ 这个词狭义代指数据仓库了。
08 年左右的 Data Platform 还泛指数据仓库,那时互联网企业的数据仓库刚兴起没几年,在建设思路上还是以传统数据平台的第二、三代架构为参照物实施建设的。自己猜测那时很多互联网企业也是使用 Oracle、IBM、EMC 的软硬件区做的各类系统的实施,自然数据平台建设者都是来给电信、移动、制造业等各大数据仓库实施的甲方、乙方各类牛人。
行业的差异性导致业务不同,影响到数据平台源(数据源)的差异性、随着信息化共享与服务的这个“神奇”互联网行业快速发展,互联网业务逐渐的重视数据,所以互联网的从业者在看数据、使用数据的方式每一年也不同、大数据的各种技术也在快速更新中,各方面因素导致了互联网数据平台的建设、服务用户特点、数据模型与非互联网数据平台有较为显著差异。
数据源
做数据的人,从非互联网进入到互联网最显著的特点是面对的数据源类型忽然多了起来,在传统企业数据人员面对的是结构化存储数据,基本来自 excel、表格、DB 系统等,在数据的处理技术上与架构上是非常容易总结的,但是在互联网因为业务独特性导致了所接触到的数据源特性多样化,网站点击日志、视频、音频、图片数据等很多非结构化快速产生与保存,在这样的数据源的多样化与容量下采用传统数据平台技术来处理当然是有些力不从心了(备注:IBM 的科学家分析员道格. 莱尼的一份数据增长报告基础上提出了大数据的 4V 特性 大数据 4v 特性网上概念很多大家可以问度娘)。
目前最火热的移动互联网, 大家都在通过自己的手机、平板去访问网站、购物等所以每个人都是数据的生产者,移动用户在使用习惯上呈现移动化、碎片化,以至于业务特性、商业模式比传统互联网又有显著差别, 用户在不同位置需求是不同的、使用 APP 也是不同的、手机终端类型也是多样化。这些差异性比较导致移动互联网的数据与传统的互联网时代又产生显著差异性。
例如买家通过 Pc 购物从浏览物品到支付可能在很短时间内完成,但是通过手购物碎片化就显得多一些,可能在某个空余时间浏览物品,保存或放入购物车,等有时间在去做支付。大约在 2009 年到 2012 年之间做用户行为分析感觉很多原有网页端拍下物品去支付,逐渐转为 PC 端下单通过移动端支付。
我在这里整理一个表格不同时代数据源的差异性(备注可能整理的有点不全):
行业域
非互联网
互联网
移动互联网
数据来源 (相对于数据平台来讲)
结构化各类数据库 (DB 系统)、结构化文本、Excel 表格等,少量 word
Web、自定义、系统的日志,各类结构化 DB 数据、长文本、视频 主要是来自网页
除了互联网那些外还含有大量定位数据、自动化传感器、嵌入式设备、自动化设备等
数据包含信息
CRM 客户信息、事务性 ERP/MRPII 数据、资金账务数据 等。
除了传统企业数据信息外,还含有用户各类点击日志、社交数据、多媒体、搜索、电邮数据等等
除了传统互联网的数据外,还含有 Gps、穿戴设备、传感器各类采集数据、自动化传感器采集数据等等
数据结构特性
几乎都是结构化数据
非结构化数据居多
非结构化数据居多
数据存储 / 数据量
主要以 DB 结构化存储为主,从几百兆到 百 G 级别
文件形式、DB 形式,流方式、 从 TB 到 PB
文件形式、流方式、DB 范式,非结构化 从 TB 到 PB
产生周期
慢,几天甚至周为单位
秒或更小为单位
秒或更小为单位
对消费者行为采集与还原
粒度粗
粒度较细
粒度非常细
数据价值
长期有效
随着时间衰减
随着时间快速衰减
单位时间内数据聚合度
高度聚合
聚合度低
聚合度很低

该图引用 2013 年“中国数据库大会大数据的实践与应用”
数据平台的用户
总结下来互联网的数据平台“服务”方式迭代演进大约可以分为三个阶段。
阶段一 :
约在 2008 年 -2011 年初的互联网数据平台,那时建设与使用上与非互联网数据平台有这蛮大的相似性,主要相似点在数据平台的建设角色、与使用到的技术上。
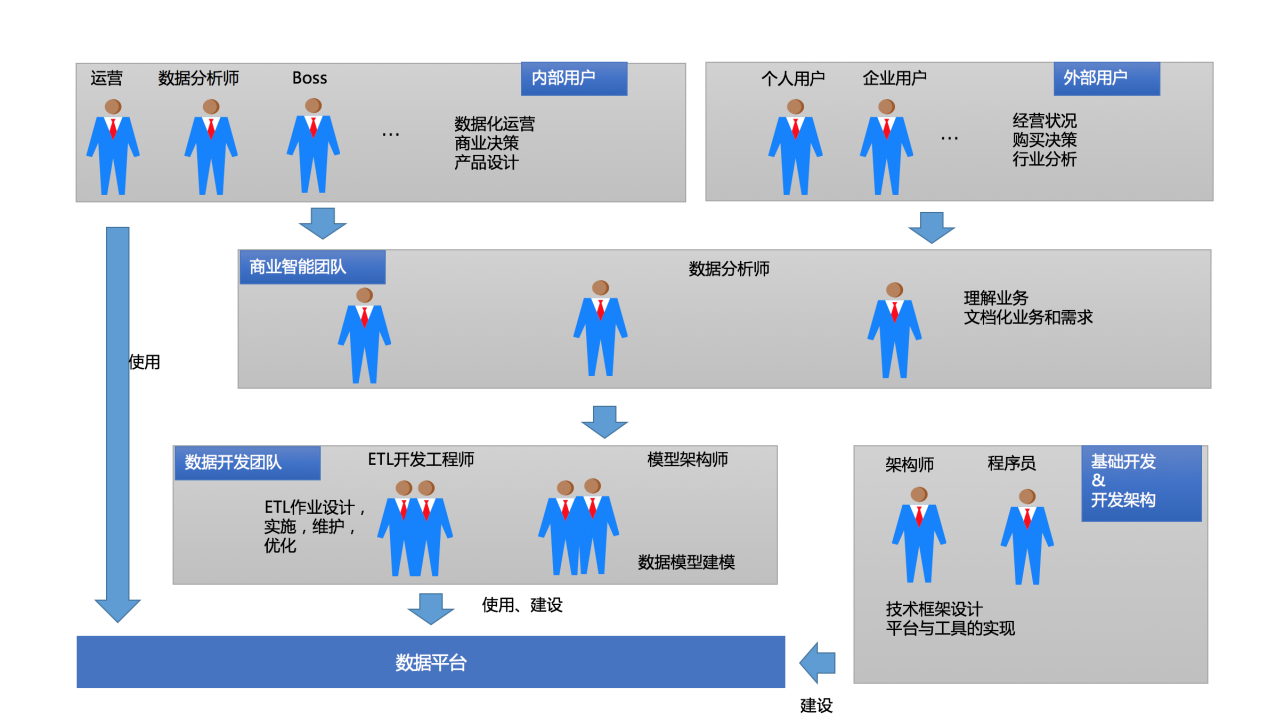
- 老板们、运营的需求主要是依赖于报表、分析报告、临时需求、商业智能团队的数据分析师去各种分析、临时需求、挖掘,这些角色是数据平台的适用方。
- ETL 开发工程师、数据模型建模、数据架构师、报表设计人员 ,同时这些角色又是数据平台数据建设与使用方。
- 数据平台的技术框架与工具实现主要有技术架构师、JAVA 开发等。
- 用户面对是结构化的生产数据、PC 端非结构化 log 等 数据。
- ELT 的数据处理方式(备注在数据处理的方式上,由传统企业的 ETL 基本进化为 ELT)。
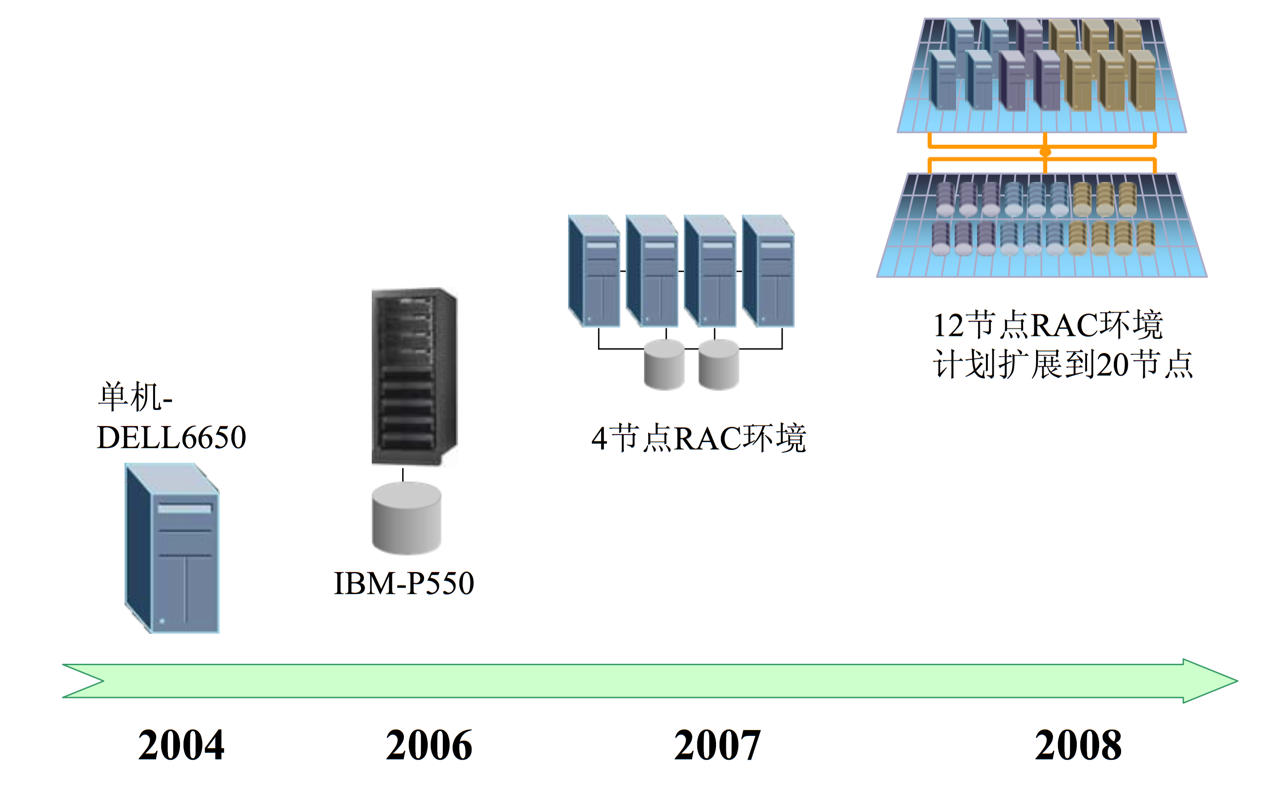
现在的淘宝是从 2004 年开始构建自己的数据仓库,2004 年是采用 DELL 的 6650 单节点、到 2005 年更换为 IBM 的 P550 再到 2008 年的 12 节点 Rac 环境。在这段时间的在 IBM、EMC、Oracle 身上的投入巨大 (备注:对这段历史有兴趣可以去度娘:“【深度】解密阿里巴巴的技术发展路径“),同时淘宝的数据集群也变为国内最大的数据仓库集群。
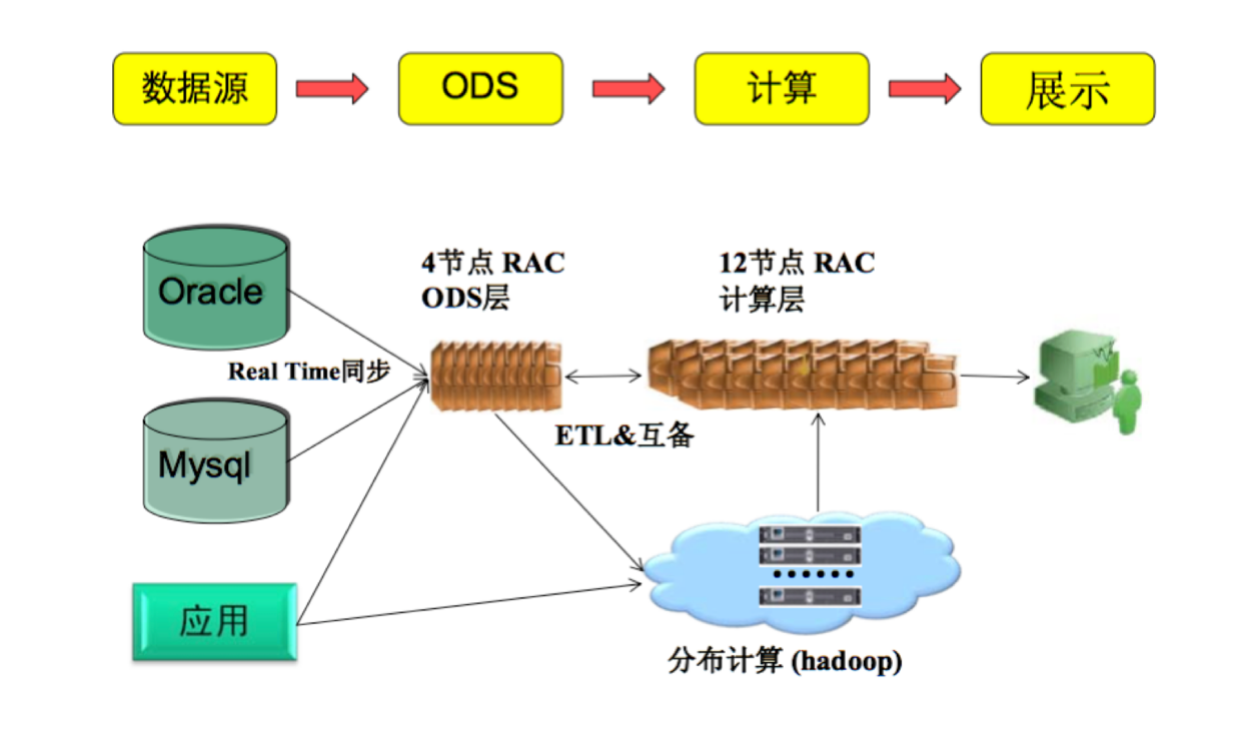
我当时用 Oracle 搭建的数据仓库做临时需求时,一个经过反复优化的 SQL 语句在晚上 9 点放入能够 Running 凌晨 4 点多而被电话中狂吼的 DBA 给 kill 掉,痛不欲生。
因为快速膨胀的数据量,在 2010 年开始考虑引进 Greenplum 最为主平台提供强大的计算能力,但没想到快速爆炸的数据量让我们在 POC 测试阶段就把 Greenplum 的适合业务场景定位清楚了。
随着 2010 年引入了 hadoop&hive 平台进行新一代的数据平台的构建,此时的 Greenplum 因为优秀的 IO 吞吐量以及有限的任务并发安排到了网站日志的处理以及给分析师提供的数据分析服务。
该阶段的数据模型是根据业务的特性采用退化、扁平化的模型设计方式去构建的(备注:将会在模型篇章详细讲解)。
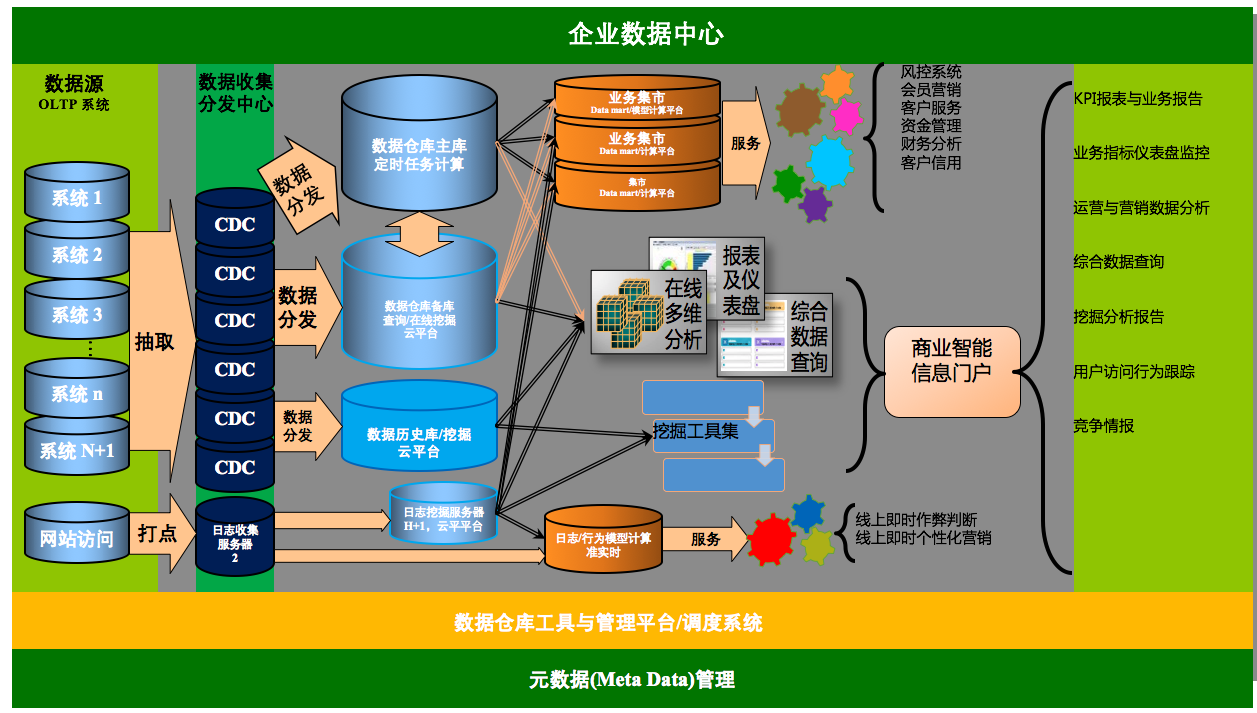
阶段二:
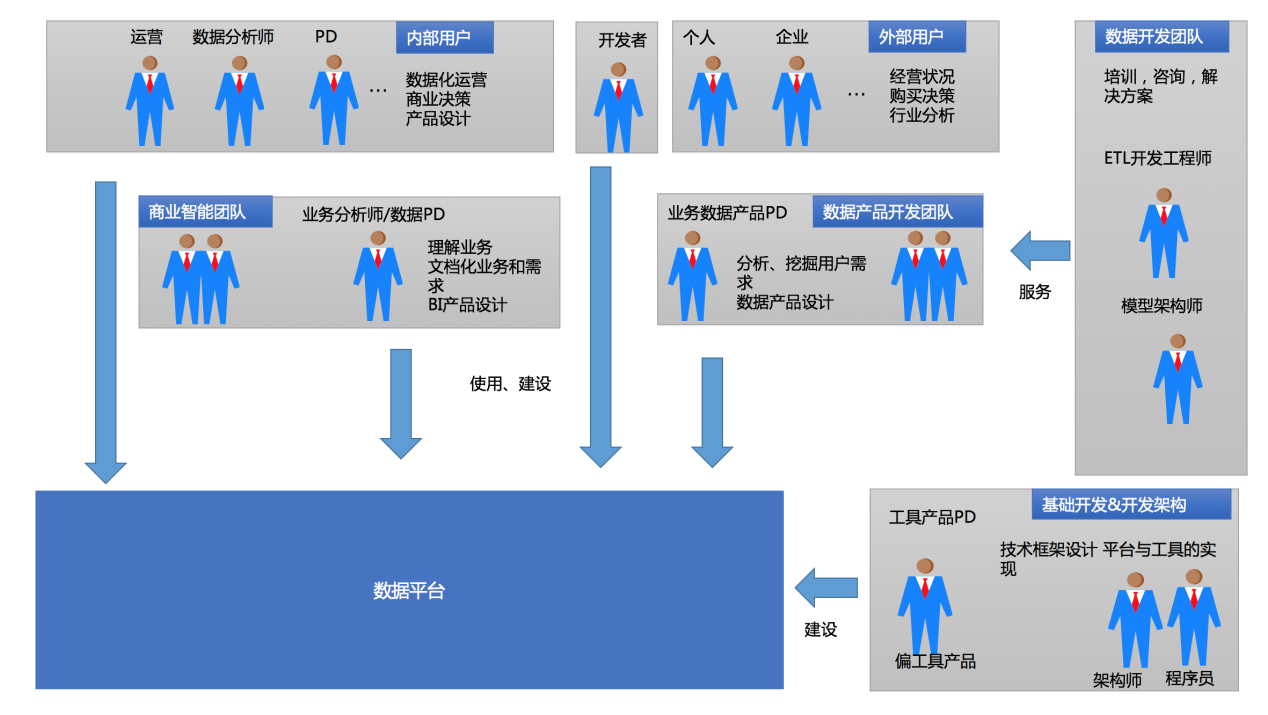
互联网的数据平台除了受到技术、数据量的驱动外,同时还来自数据产品经理梳理用户的需求按照产品的思维去构建并部署在了数据的平台上。互联网是一个擅长制造流程新概念的行业。约在 2011 年到 2014 年左右,随着数据平台的建设逐渐的进入快速迭代期,数据产品、数据产品经理这两个词逐渐的升温以及被广泛得到认可(备注:数据产品相关内容个人会在数据产品系列中做深入分享),同时数据产品也随着需求、平台特性分为面向用户级数据产品、面向平台工具型产品两个维度分别去建设数据平台。
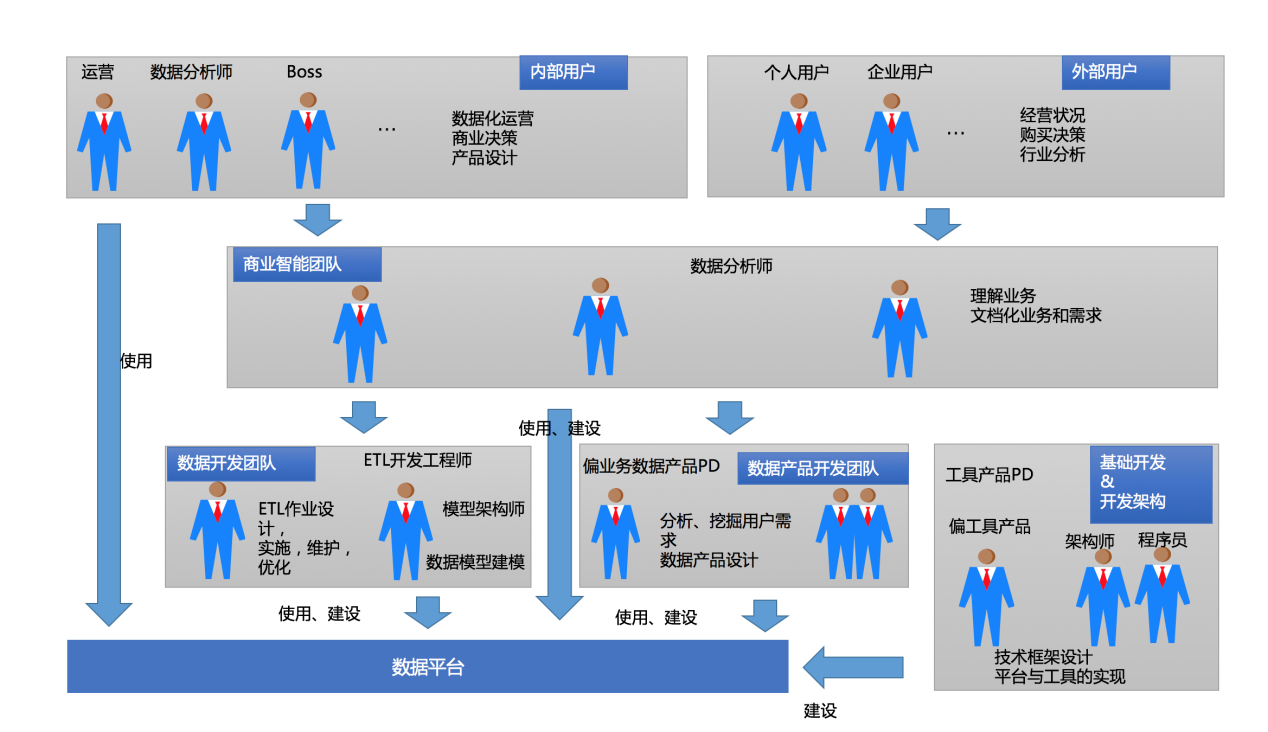
- 企业各个主要角色都是数据平台用户。
- 各类数据产品经理(偏业务数据产品、偏工具平台数据产品)推进数据平台的建设。
- 分析师参与数据平台直接建设比重增加。
- 数据开发、数据模型角色都是数据平台的建设者与使用者(备注:相对与传统数据平台的数据开发来说,逐渐忽略了数据质量的关注度,数据模型设计角色逐渐被弱化)。
- 用户面对是数据源多样化,比如日志、生产数据库的数据、视频、音频等非结构化数据。
- 原有 ETL 中部分数据转换功能逐渐前置化,放到业务系统端进行(备注:部分原有在 ETL 阶段需要数据标准化一些过程前置在业务系统数据产生阶段进行,比如 Log 日志。 移动互联网的日志标准化。
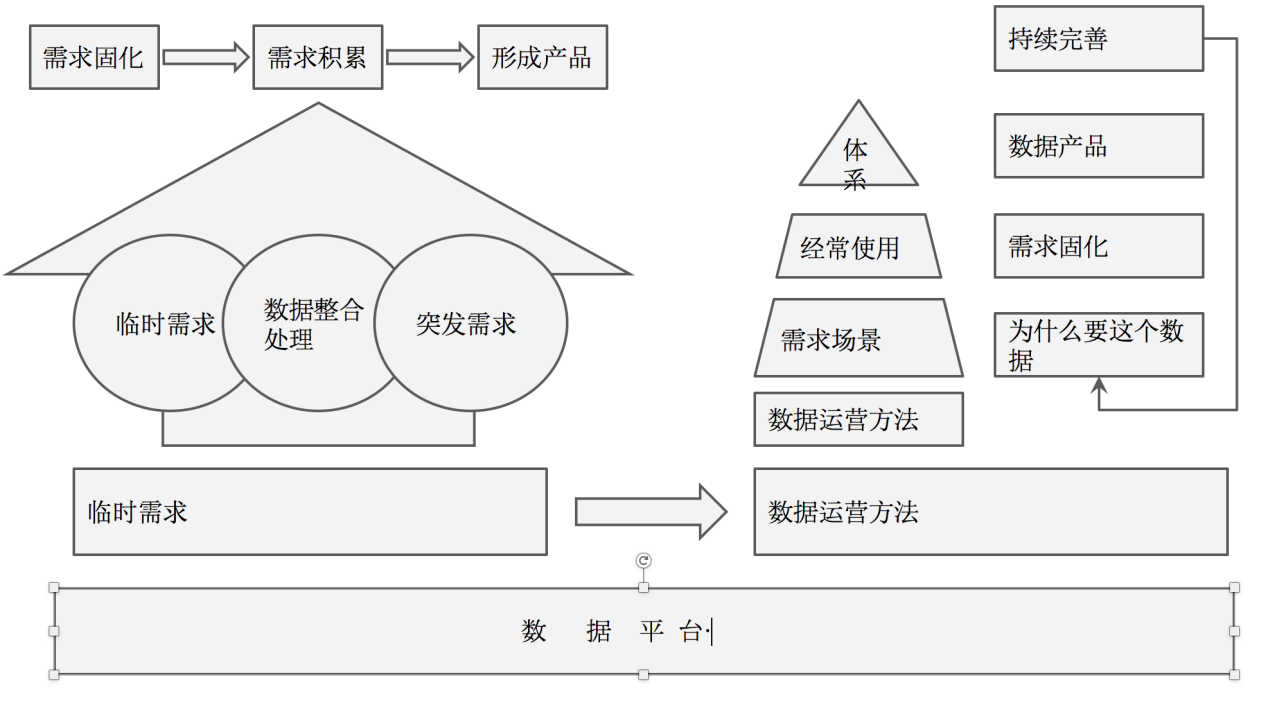
互联网企业随着数据更加逐渐被重视,分析师、数据开发在面对大量的数据需求、海量的临时需求疲惫不堪,变成了资源的瓶颈,在当时的状态传统的各类的 Report、Olap 工具都无法满足互联网行业个性化的数据需求。开始考虑把需求固定化变为一个面向最终用户自助式、半自助的产品来满足快速获取数据 & 分析的结果,当总结出的指标、分析方法(模型)、使用流程与工具有机的结合在一起时数据产品就诞生了(备注:当时为了设计一个数据产品曾经阅读了某个部门的 2000 多个临时需求与相关 SQL)。
数据产品按照面向的功能与业务可以划分为面向平台级别的工具型产品、面向用户端的业务级数据产品。按照用户分类可以分为面向内部用户数据产品,面向外部用户个人数据产品、商户(企业)数据产品。
面向平台级别有数据质量、元数据、调度、资管配置、数据同步分发等等。(备注:关于数据产品的发展与数据产品体系更多内容,请关注个人写作“数据产品系列”)。
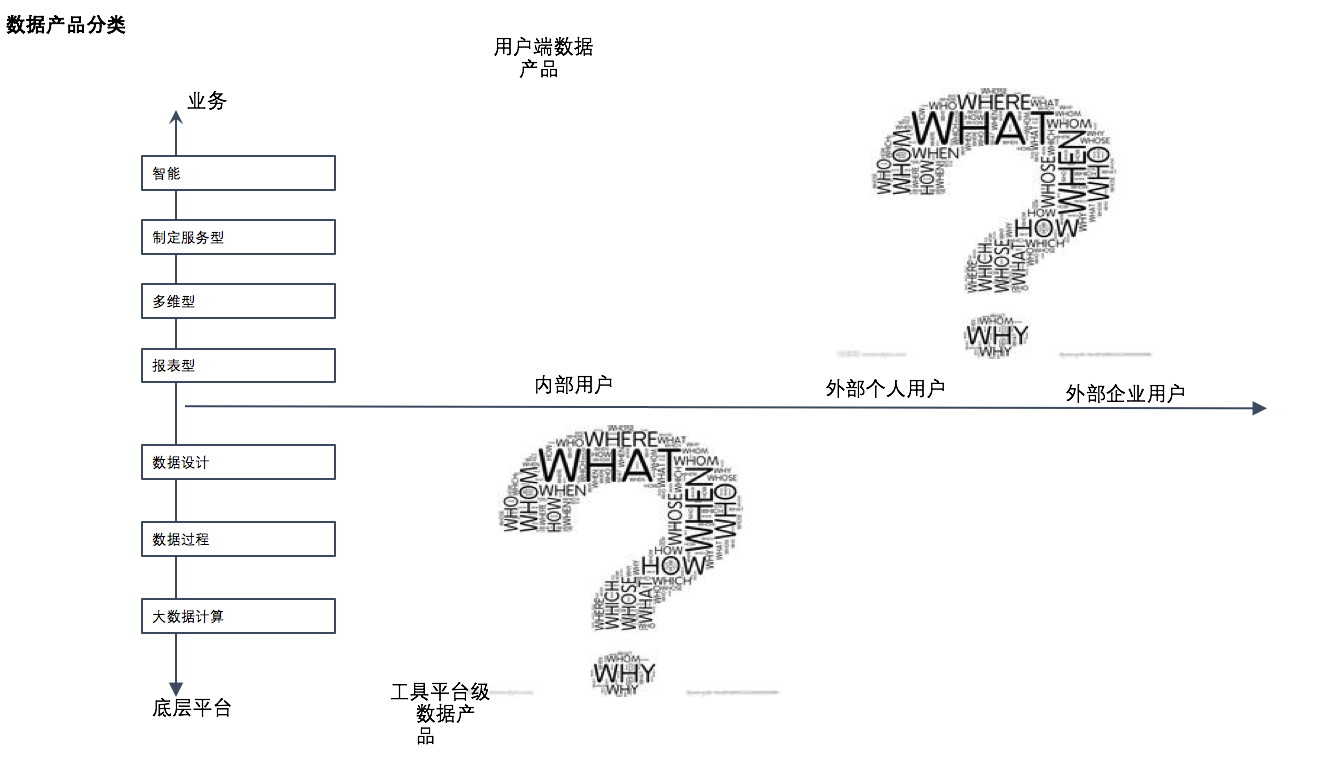
约 2010-2012 年的平台结构
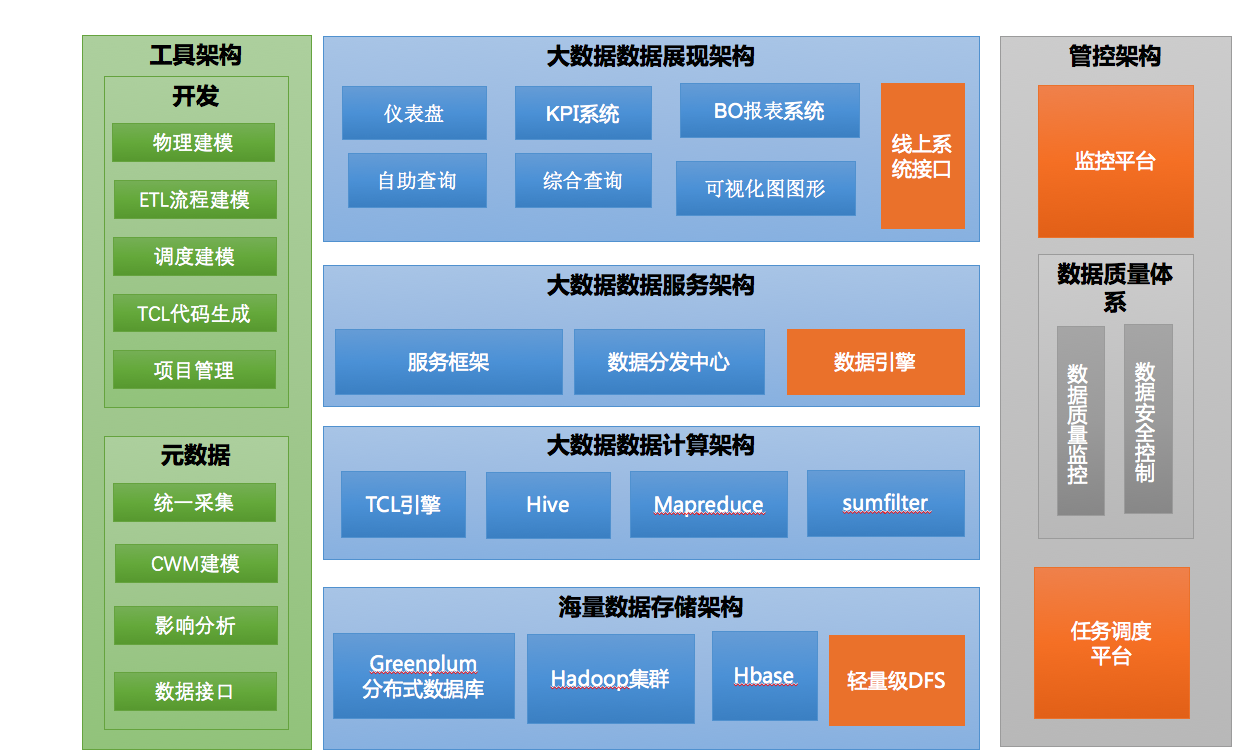
约 2012-2013 年的平台结构
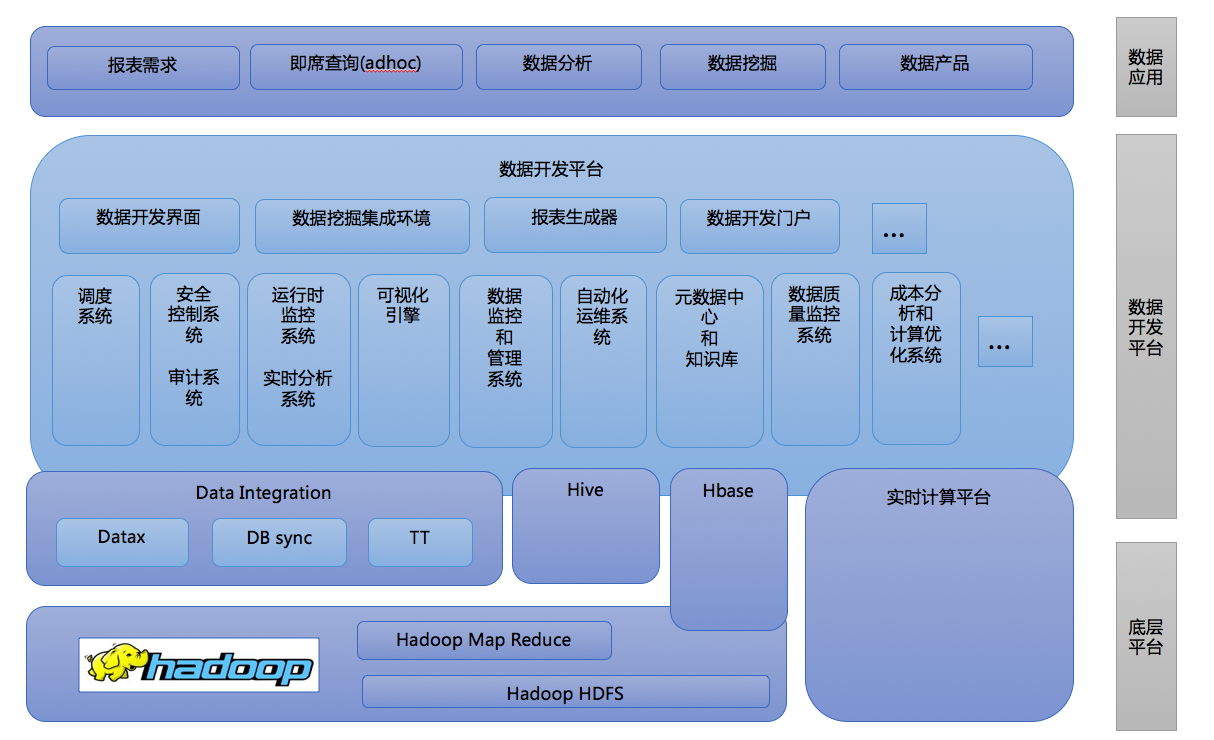
阶段三:
互联网业务的快速发展、大家已经从经营、分析的诉求重点转为数据化的精细运营上,随之而来的面临创新压力、如何做好精细化运营,数据平台的用户其聚焦在无法快速的响应日常需求其表现为做数据的已经无法满足当前业务日益增长的数据需求、运营上精细化已经对数据的粒度要求由高汇总逐渐转为过程化细粒度明细数据。
随着数据应用的深入,用数据往往不知道数据的口径与来源,加工数据的不知道业务含义,不同部门口径又是不一样,有的从交易来、有的从账务来。这里数据使用与数据加工上就出现了”断层”。有时在层级与功能部门前边也可能存在一个断层,对数据价值的内在衡量是不一样的,角色不一样,对于数据价值的的看法也就不同。
由于以上的种种问题,用数据的一些角色(分析师、运营或产品)会自己参与到从数据整理、加工、分析阶段。当数据平台变为自由全开放,使用数据的人也参与到数据的体系建设时,基本会因为不专业型,导致数据质量问题、重复对分数据浪费存储与资源、口径多样化等等原因。此时原有建设数据平台的多个角色可能转为对其它非专业做数据人员的培训、咨询与落地写更加适合当前企业数据应用的一些方案等。例如原有的数据产品会加入更多的在原有的数据建设中才有的一些流程让用户来遵守(统一的数据搜集、数据标准化的前置)。举例 Log 埋点产品化、自动 Report 的过程规范化(举例说明:原有一些运营自己建立的一些报表可能 sql 有问题就直接放入报表生成器中了。更改流程第一步现在 MQ 中验证完毕口径后,通过元数据解析进入到报表生成器中)、基于元数据驱动的 ETL 流程化等等,因为偏自助式、服务化的一些数据产品建立也将会导致数据平台迭代的演进。
- 给用户提供的各类丰富的分析、取数的产品,简单上手的可以使用。
- 原有 ETL、数据模型角色转为给用户提供平台、产品、数据培训与使用咨询。
- 数据分析师直接参与到数据平台过程、数据产品的建设中去。
- 用户面对是数据源多样化,比如日志、生产数据库的数据、视频、音频等非结构化数据。
在互联网这个大数据浪潮下,2016 年以后数据平台是如何去建设?如何服务业务?
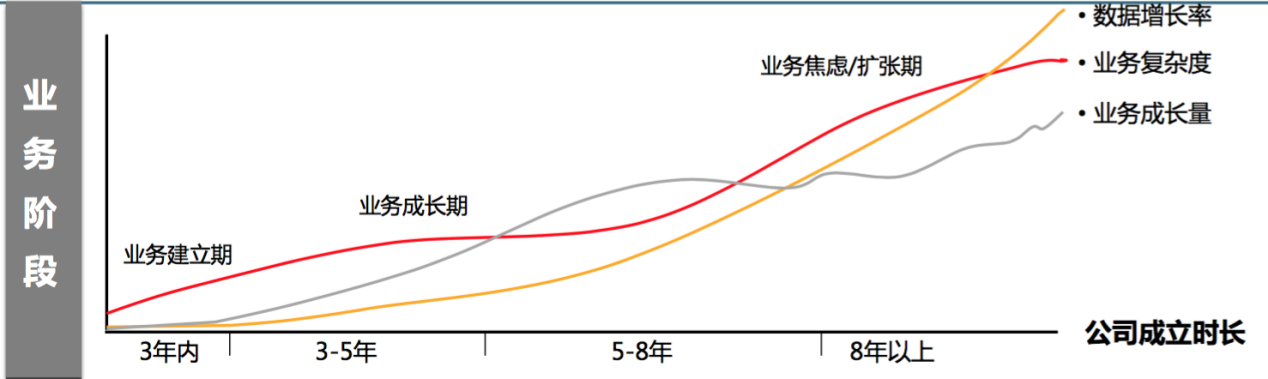
企业的不同发展阶段数据平台该如何去建设的?这个大家是可以思考的。但是我相信互联网企业是非常务实的,基本不会采用传统企业的自上而下的建设方式,互联网企业的业务快速变与迭代要求快速分析到数据,必须新业务数据迭代,老业务数据快速去杂。敏捷数据平台或许是种不错的选择方法之一吧!
下一篇将是本系列的最后一篇,互联网数据平台下的数据建模(备注:是数据仓库模型)。
关于作者
松子(李博源) ,自由撰稿人,数据产品 & 数据分析总监。2000 年开始数据领域,从业传统制造业、银行、保险、第三方支付 & 互联网金融、在线旅行、移动互联网行业 ; 个人沉淀在大数据产品、大数据分析、数据模型领域;欢迎关注个人微信订阅号:songzi2016。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论