
技术运营团队的由来
在运维更名为技术运营的两年内,我们对这个团队的工作目标产生了新的理解,工作内容也逐渐从传统的维护往 DevOps 方向转化。技术运营,简单地讲就是利用技术手段,降低资源消耗,提高基础资源的运行效率,提高整个软件生命周期运行的效率。这意味着对团队内的每个工程师都提出了更高的要求:一方面我们要支持目前的系统运行;同时也要针对目前的业务流程去开发自己的工具,让整个基础资源和能力工具化,把经验和自己对流程的理解变成Web化的工具,提供给程序员使用 ****。
为什么必须自主研发监控系统
目前在 TalkingData 的 Developer 除了负责代码的编写,还要负责生产系统自己程序的性能指标提供监控接口,以及生产环境程序 bug 的处理。Developer 能够一定程度的获取生产权限,方便常规的维护和简单故障的处理。这样一来,技术运营的挑战就来了:权限的管理、性能指标的监控、日志的管理以及资源的隔离,都需要有成熟的工具去支撑。目前市面上有很多开源的软件可以实现这样的功能,但是在不同程度上存在各种各样的问题。以监控为例,开源的监控很多,Zabbix、Nagios、Cacti,都是不错的监控软件,但是首先它们并不能满足大数据场景下的数据存储;其次,如果监控项和主机数量过多,数据查询时会出现速度慢等一系列问题。所以技术运营首先选择在监控上做了全新的设计和开发,新监控命名为 OWL(猫头鹰),意思就是在技术人员睡觉的时候提供值班服务。
自研监控系统的三大技术要点
传统的监控很多还是在停留在设备、网络、系统相关的监控上,重视数据的采集,但是在数据算法和 Role 上比较传统。对监控系统简化抽象下,传统监控可以大致分为三个过程:数据采集、数据存储、响应处理。OWL监控在传统监控基础上,增加了Algorithm模块,支持复杂的算法规则报警,如下图所示:
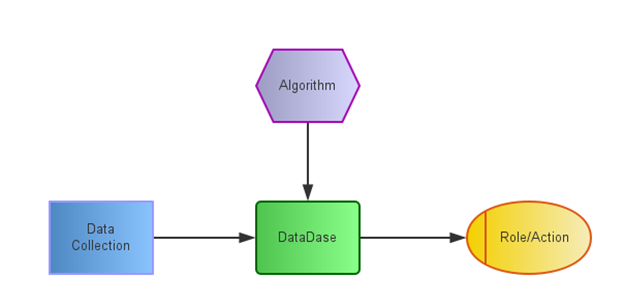
1. 监控数据采集
Data Collection 就是数据采集,这里指的数据不光是基础硬件的指标,也可以是业务指标。下面介绍两个实例。
第一个例子是主机硬盘状态的采集:
下面的数据采集中第一列是硬盘设备标号,第二列是硬盘的状态,在监控的这个层面,一切都是 metric,不同的层级可以抽象到不同的 metric,结合 metric + timestamp + tagk1 + tagv1… + tagkN + tagvN,这样针对相同的 metric 去加 tag,用来标示数据,方便后期的查询。
{ "0_1_12": 0, "0_1_13": 0, "0_1_10": 0, "0_1_11": 0, "0_1_4": 0, "0_1_5": 0, "0_1_6": 0, "0_1_7": 0, "0_1_0": 0, "0_1_1": 0, "0_1_2": 0, "0_1_3": 0, "0_1_8": 0, "0_1_9": 0 }
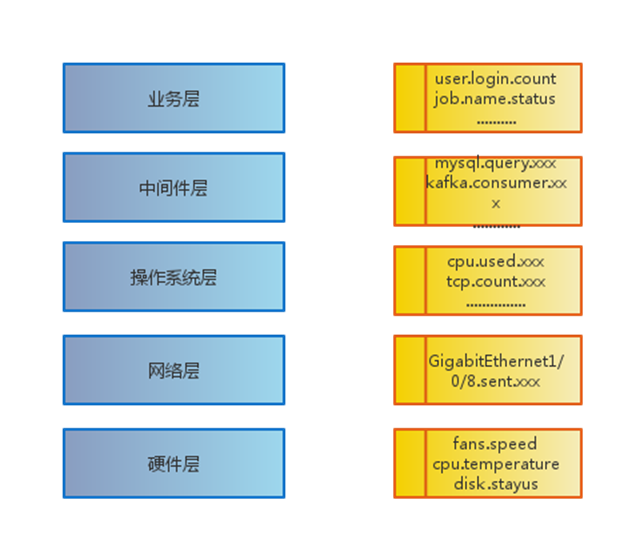
第二个例子是Nginx 的访问状态的数据采集:
第一列是 http 请求的状态,第二列是计数器
{ "200": 29312, "404": 0, "499": 60, "412": 0, "400": 114, "502": 0, "408": 179 }
2. 监控数据存储
监控数据的存储也是一个很有意思的话题,监控数据在数据结构上是很有特色的。仔细观察发现监控数据基本上都是和时间维度相关的,以 metric +timestamp的组合形式的数据占了所有监控数据量的大部分,相比而言,多维度的监控数据比较少;如果出现了多维度的监控数据,也可以通过其他的方式绕开处理。RDBMS 由于要考虑数据的关联,所以它在整体数据存储设计上充分考虑了数据的完整性和关系型,同时在 schema 设计上还要遵守数据库的几大范式。传统的监控大多数还是使用了 RDBMS,但是这造成了性能上和扩展性上的局限性。针对监控数据这样简单的数据结构,却采用了一套复杂的存储格式。随着近些年各种各样的垂直的
技术领域对数据的存储不同要求的演变,如 Graph database,Time Series Databases 等数据库得到了不断发展;监控数据在存储上有了更多的选择,InfluxDB,OpenTSDB,KairosDB 都是不错的选择,最后我们选择了 OpenTSDB,这主要是因为 TalkingData 的大数据基因,Hadoop 和 HBase 在我们的业务系统中大规模使用。从现有的数据体量上,OpenTSDB 能够满足现在的业务要求。简单的总结了一下 OpenTSDB 的优点:
- 使用 HBase 存储,不存在单点故障。
- 使用 HBase 存储,存储空间几乎无限。支持永久存储,可以做容量规划。
- 易于定制图形
- 能扩展采集数据点到 100 亿级。
- 能扩展 metrics 数量到 K 级别(比如 CPU 的使用情况,可以算作一个 metric,即 metric 就是 1 个监控项)
- 支持秒级别的数据。
此外,OpenTSDB支持API**** 查询,可以轻松地和其他系统进行数据对接,也方便其他系统抽取监控相关的数据。 并且,查询方式灵活:查询数据可以使用 query 接口,它既可以使用 get 的 query string 方式,也可以使用 post 方式以 JSON 格式指定查询条件。
3. 监控的报警算法
Algorithm 这块是传统监控系统所欠缺的,基本上都是单个指标的大于,小于这样的算法,但是 ** 遇到集群或者复杂的指标,就需要自己去增加一些算法,比如多个指标的加和,平均值,top10,历史相似度等。** 这些算法的引入,可以增加报警的准确度,有效的减少报警数量,让报警变得人性化。 关于报警的算法会在本系列的后续文章进行详细介绍。
自研监控系统一览
简单的介绍一下 OWL 的整体架构,下面目前的架构是第四个大版本。在研发的过程中,我们也尝试了很多的开源技术,如 RRDtools、Graphlite,也踩了很多的技术坑,最后我们整体选择了 OpenTSDB,在这个技术栈下面演进了两个版本:
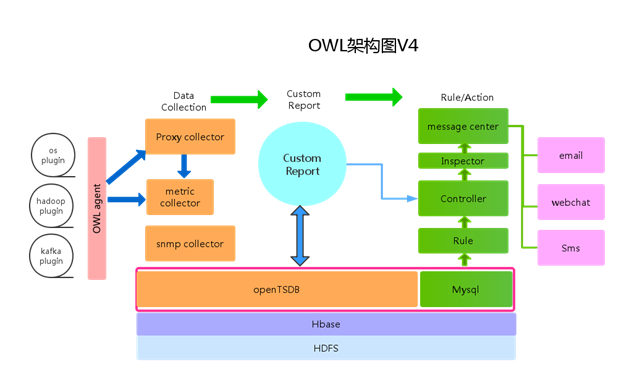
方案特点一:语言栈统一为 Go
2015 年的版本,由于技术人员的稀缺,我们采用了一部分 Python 一部分 Golang 的系统,在开源推广中带来了很多问题,主要是部署难度增加。2016 年即将发布的版本中,metric collection 模块、Controller 模块、Inspector 模块全部采用 Golang 开发,简单摘录一下 Golang 的优点:
- 部署简单。Go 编译生成的是一个静态可执行文件,除了 glibc 外没有其他外部依赖。这让部署变得异常方便:目标机器上只需要一个基础系统和必要的管理、监控工具,完全不需要操心应用所需的各种包、库的依赖关系,大大减轻了维护的负担。这是与 Python 的巨大区别。
- 并发性好。goroutine 和 channel 使得编写高并发的服务端软件变得相当容易,很多情况下完全不需要考虑锁机制以及由此带来的各种问题。单个 Go 应用也能有效的利用多个 CPU 核,并行执行的性能好。
- 良好的语言设计。
- 执行性能好。虽然不如 C 和 Java,但通常比原生 Python 应用还是高一个数量级的,适合编写一些瓶颈业务。内存占用也非常节省。
我们也同样意识到这样的问题,所以在 OWL V4.0 的版本中,全部统一了语言栈,降低了大家的使用难度,和后期技术栈的维护难度。
方案特点二:定制化自己的图表
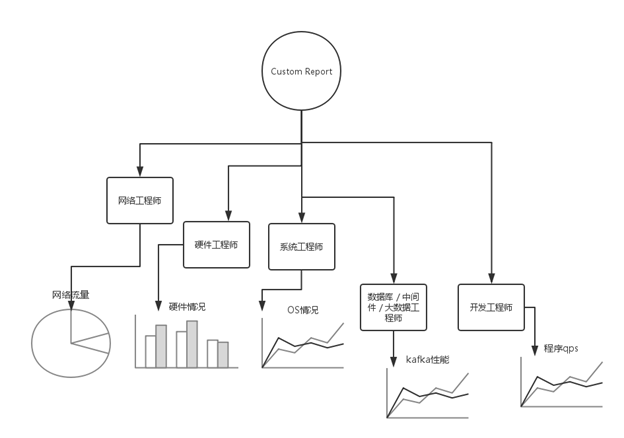
上面的架构图中,大家不难发现,整个 OWL 的设计核心是 Custom Report。将整个系统从以工具为核心,转向以数据和用户为核心,OWL 的好处是首先使用者会自己定义感兴趣的数据指标;其次在指标上添加 rule,用户可以更专注数据;随后可以做一些简单的数据处理,一些数据加和等这样的简单运算;并且定制不同样式的图表,饼图、柱状图、线图。
在整个监控上形成一个立体的结构,不同层面的工程师可以在同一个层面上工作。
有了好的工具支持,才能让工程师DevOps起来。OWL 新版本中也将会支持 Docker 的支持,这块目前采用的主要是 google 开源的 cAdvisor 作为数据采集的,通过二次开发将 cAdvisor 变成 plugin 集成进入 OWL。
方案特点三:报警模块的划分
关于报警方式,目前没有放置在 OWL 中。在 TalkingData,所有的报警采用 Message center 的方式,Message center 有独立的 Web,支持基础的信息查询,信息的发送对外采用 restful API 暴露给其他的系统,信息的传送方式上,按照消息的优先级程度,采用不同的下行方式,高=短信+企业微信+email;中=企业微信+email;低=email,目前正在考虑加入商业化的呼转服务。 具体详情参见本系列的后续文章:《报警系统的设计与实现》。
总结
OWL 只是 TalkingData 在 DevOps 尝试的其中一个平台。如果从长期的角度去考虑,企业构建自己的运维平台,应该按照云平台的思路去建设,将工程师定义为整个平台的使用者,要简化工程师在基础资源上消耗的时间,降低资源使用的时间成本,这样才会在DevOps的路上越走越好。
作者简介
潘松柏,TalkingData 高级运维总监,曾就职于中国移动 12580、中国惠普等企业。2011 年作为初始团队成员加入 TalkingData 任高级运维总监,负责公司 SaaS 产品线和行业客户私有云服务项目的基础系统实施和建设。15 年年底,TalkingData 技术运营开源了企业级监控 OWL 系统,解决了大数据下不同组件的监控问题,将监控统一到分布式平台来实现。
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论