
本文将介绍优化训练神经网络模型的一些常用方法,并给出使用 TensorFlow 实现深度学习的最佳实践样例代码。为了更好的介绍优化神经网络训练过程,我们将首先介绍优化神经网络的算法——梯度下降算法。然后在后面的部分中,我们将围绕该算法中的一些元素来优化模型训练过程。
梯度下降算法
梯度下降算法主要用于优化单个参数的取值,而反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。反向传播算法是训练神经网络的核心算法,它可以根据定义好的损失函数优化神经网络中参数的取值,从而使神经网络模型在训练数据集上的损失函数达到一个较小值。神经网络模型中参数的优化过程直接决定了模型的质量,是使用神经网络时非常重要的一步。
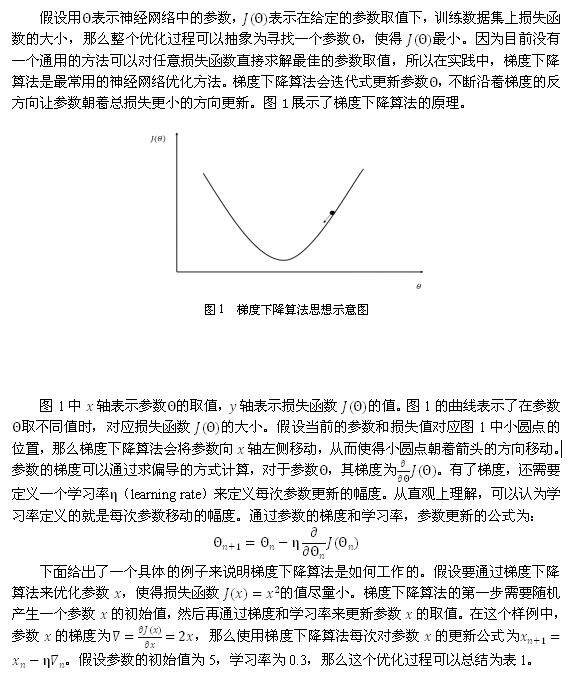
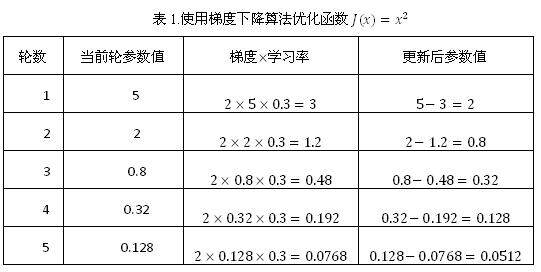
从表 1 中可以看出,经过 5 次迭代之后,参数 x 的值变成了 0.0512,这个和参数最优值 0 已经比较接近了。虽然这里给出的是一个非常简单的样例,但是神经网络的优化过程也是可以类推的。神经网络的优化过程可以分为两个阶段,第一个阶段先通过前向传播算法计算得到预测值,并将预测值和真实值做对比得出两者之间的差距。然后在第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。本书将略去反向传播算法具体的实现方法和数学证明,有兴趣的读者可以参考论文 _Learning representations by back-propagating errors_。

为了综合梯度下降算法和随机梯度下降算法的优缺点,在实际应用中一般采用这两个算法的折中——每次计算一小部分训练数据的损失函数。这一小部分数据被称之为一个 batch。通过矩阵运算,每次在一个 batch 上优化神经网络的参数并不会比单个数据慢太多。另一方面,每次使用一个 batch 可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
学习率的设置
上面提到在优化神经网络时,需要设置学习率(learning rate)控制参数更新的速度。学习率决定了参数每次更新的幅度。如果幅度过大,那么可能导致参数在极优值的两侧来回移动。还是以优化 J(x)=x2 函数为样例。如果在优化中使用的学习率为 1,那么整个优化过程将会如表 2 所示。
表 2. 当学习率过大时,梯度下降算法的运行过程
轮数
当前轮参数值
梯度学习率
更新后参数值
1
5
2*5*1=10
5-10=-5
2
-5
2*(-5)*1=-10
-5-(-10)=5
3
5
2*5*1=10
5-10=-5
从上面的样例可以看出,无论进行多少轮迭代,参数将在 5 和 -5 之间摇摆,而不会收敛到一个极小值从上面的样例可以看出,无论进行多少轮迭代,参数将在 5 和 -5 之间摇摆,而不会收敛到一个极小值。相反,当学习率过小时,虽然能保证收敛性,但是这会大大降低优化速度。我们会需要更多轮的迭代才能达到一个比较理想的优化效果。比如当学习率为 0.001 时,迭代 5 次之后,x 的值将为 4.95。要将 x 训练到 0.05 需要大约 2300 轮;而当学习率为 0.3 时,只需要 5 轮就可以达到。综上所述,学习率既不能过大,也不能过小。为了解决设定学习率的问题,TensorFlow 提供了一种更加灵活的学习率设置方法——指数衰减法。tf.train.exponential_decay 函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。exponential_decay 函数会指数级地减小学习率,它实现了以下代码的功能:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_ steps)
其中 decayed_learning_rate 为每一轮优化时使用的学习率,learning_rate 为事先设定的初始学习率,decay_rate 为衰减系数,decay_steps 为衰减速度。下面给出了一段代码来示范如何在 TensorFlow 中使用 tf.train.exponential_decay 函数。
# 通过 exponential_decay 函数生成学习率。 learning_rate = tf.train.exponential_decay( learning_rate_base, global_step, decay_step, decay_rate) # 使用指数衰减的学习率。在 minimize 函数中传入 global_step 将自动更新 # global_step 参数,从而使得学习率也得到相应更新。 learning_step = tf.train.GradientDescentOptimizer(learning_rate)\ .minimize(...my loss..., global_step=global_step)
过拟合问题
在使用梯度下降优化神经网络时,被优化的函数就是神经网络的损失函数。这个损失函数刻画了在训练数据集上预测结果和真实结果之间的差距。然而在真实的应用中,我们想要的并不是让模型尽量模拟训练数据的行为,而是希望通过训练出来的模型对未知的数据给出判断。模型在训练数据上的表现并不一定代表了它在未知数据上的表现。过拟合问题就是可以导致这个差距的一个很重要因素。所谓过拟合,指的是当一个模型过为复杂之后,它可以很好地“记忆”每一个训练数据中随机噪音的部分而忘记了要去“学习”训练数据中通用的趋势。举一个极端的例子,如果一个模型中的参数比训练数据的总数还多,那么只要训练数据不冲突,这个模型完全可以记住所有训练数据的结果从而使得损失函数为 0。可以直观地想象一个包含 _n_ 个变量和 _n_ 个等式的方程组,当方程不冲突时,这个方程组是可以通过数学的方法来求解的。然而,过度拟合训练数据中的随机噪音虽然可以得到非常小的损失函数,但是对于未知数据可能无法做出可靠的判断。
图 2 显示了模型训练的三种不同情况。在第一种情况下,由于模型过于简单,无法刻画问题的趋势。第二个模型是比较合理的,它既不会过于关注训练数据中的噪音,又能够比较好地刻画问题的整体趋势。第三个模型就是过拟合了,虽然第三个模型完美地划分了灰色和黑色的点,但是这样的划分并不能很好地对未知数据做出判断,因为它过度拟合了训练数据中的噪音而忽视了问题的整体规律。比如图中浅色方框更有可能和“X”属于同一类,而不是根据图上的划分和“O”属于同一类。
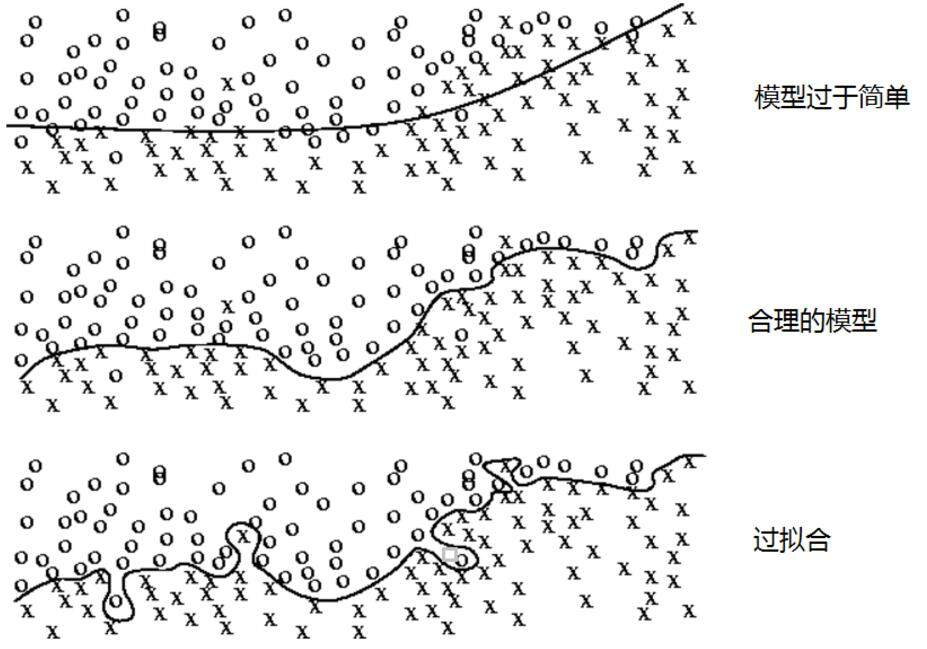
图 2 神经网络模型训练的三种情况

无论是哪一种正则化方式,基本的思想都是希望通过限制权重的大小,使得模型不能任意拟合训练数据中的随机噪音。但这两种正则化的方法也有很大的区别。首先,_L_1 正则化会让参数变得更稀疏,而 _L_2 正则化不会。所谓参数变得更稀疏是指会有更多的参数变为 0,这样可以达到类似特征选取的功能。之所以 _L_2 正则化不会让参数变得稀疏的原因是当参数很小时,比如 0.001,这个参数的平方基本上就可以忽略了,于是模型不会进一步将这个参数调整为 0。其次,_L_1 正则化的计算公式不可导,而 _L_2 正则化公式可导。因为在优化时需要计算损失函数的偏导数,所以对含有 _L_2 正则化损失函数的优化要更加简洁。优化带 _L_1 正则化的损失函数要更加复杂,而且优化方法也有很多种。以下代码给出了一个简单的带 _L_2 正则化的损失函数定义:
w= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1)) y = tf.matmul(x, w) loss = tf.reduce_mean(tf.square(y_ - y)) + tf.contrib.layers.l2_regularizer(lambda)(w)

滑动平均模型
在采用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中都可以在一定程度提高最终模型在测试数据上的表现。滑动平均模型可以有效的减小训练数据中的噪音对模型带来的影响。在 TensorFlow 中提供了 tf.train.ExponentialMovingAverage 来实现滑动平均模型。在初始化 ExponentialMovingAverage 时,需要提供一个衰减率(decay)。这个衰减率将用于控制模型更新的速度。ExponentialMovingAverage 对每一个变量会维护一个影子变量(shadow variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为:

下面通过一段代码来解释 ExponentialMovingAverage 是如何被使用的。
import tensorflow as tf v1 = tf.Variable(0.0, dtype=tf.float32) step = tf.Variable(0, trainable=False) # 定义一个滑动平均的类(class)。初始化时给定了衰减率(0.99)和控制衰减率的变量 step。 ema = tf.train.ExponentialMovingAverage(0.99, step) # 定义一个更新变量滑动平均的操作。这里需要给定一个列表,每次执行这个操作时 # 这个列表中的变量都会被更新。 maintain_averages_op = ema.apply([v1]) with tf.Session() as sess: init_op = tf.initialize_all_variables() sess.run(init_op) # 更新变量 v1 的值到 5。 sess.run(tf.assign(v1, 5)) # 更新 v1 的滑动平均值。衰减率为 min{0.99,(1+step)/(10+step)= 0.1}=0.1, # 所以 v1 的滑动平均会被更新为 0.10+0.95=4.5。 sess.run(maintain_averages_op) print sess.run([v1, ema.average(v1)]) # 输出 [5.0, 4.5] # 更新 step 的值为 10000。 sess.run(tf.assign(step, 10000)) # 更新 v1 的值为 10。 sess.run(tf.assign(v1, 10)) # 更新 v1 的滑动平均值。衰减率为 min{0.99,(1+step)/(10+step) 0.999}=0.99, # 所以 v1 的滑动平均会被更新为 0.994.5+0.0110=4.555。 sess.run(maintain_averages_op) print sess.run([v1, ema.average(v1)]) # 输出 [10.0, 4.5549998]
ensorFlow 最佳实践样例程序
将训练和测试分成两个独立的程序,这可以使得每一个组件更加灵活。比如训练神经网络的程序可以持续输出训练好的模型,而测试程序可以每隔一段时间检验最新模型的正确率,如果模型效果更好,则将这个模型提供给产品使用。除了可以将不同功能模块分开,本节还将前向传播的过程抽象成一个单独的库函数。因为神经网络的前向传播过程在训练和测试的过程中都会用到,所以通过库函数的方式使用起来既可以更加方便,又可以保证训练和测试过程中使用的前向传播方法一定是一致的。下面我们将给出 TensorFlow 模型训练的一个最佳实践,它使用了上文中提到的所有优化方法来解决 MNIST 问题。在这儿最佳实践中总共有三个程序,第一个是 mnist_inference.py,它定义了前向传播的过程以及神经网络中的参数。第二个是 mnist_train.py,它定义了神经网络的训练过程。第三个是 mnist_eval.py,它定义了测试过程。以下代码给出了 mnist_inference.py 中的内容。
# -*- coding: utf-8 -*- import tensorflow as tf # 定义神经网络结构相关的参数。 INPUT_NODE = 784 OUTPUT_NODE = 10 LAYER1_NODE = 500 # 通过 tf.get_variable 函数来获取变量。在训练神经网络时会创建这些变量;在测试时会通 # 过保存的模型加载这些变量的取值。而且更加方便的是,因为可以在变量加载时将滑动平均变量 # 重命名,所以可以直接通过同样的名字在训练时使用变量自身,而在测试时使用变量的滑动平 # 均值。在这个函数中,将变量的正则化损失加入损失集合。 def get_weight_variable(shape, regularizer): weights = tf.get_variable( "weights", shape, initializer=tf.truncated_normal_initializer(stddev=0.1)) # 当给出了正则化生成函数时,将当前变量的正则化损失加入名字为 losses 的集合。在这里 # 使用了 add_to_collection 函数将一个张量加入一个集合,而这个集合的名称为 losses。 # 这是自定义的集合,不在 TensorFlow 自动管理的集合列表中。 if regularizer != None: tf.add_to_collection('losses', regularizer(weights)) return weights # 定义神经网络的前向传播过程。 def inference(input_tensor, regularizer): # 声明第一层神经网络的变量并完成前向传播过程。 with tf.variable_scope('layer1'): # 这里通过 tf.get_variable 或 tf.Variable 没有本质区别,因为在训练或是测试中 # 没有在同一个程序中多次调用这个函数。如果在同一个程序中多次调用,在第一次调用 # 之后需要将 reuse 参数设置为 True。 weights = get_weight_variable( [INPUT_NODE, LAYER1_NODE], regularizer) biases = tf.get_variable( "biases", [LAYER1_NODE], initializer=tf. constant_initializer(0.0)) layer1 = tf.nn.relu(tf.matmul(input_tensor, weights) + biases) # 类似的声明第二层神经网络的变量并完成前向传播过程。 with tf.variable_scope('layer2'): weights = get_weight_variable( [LAYER1_NODE, OUTPUT_NODE], regularizer) biases = tf.get_variable( "biases", [OUTPUT_NODE], initializer=tf. constant_initializer(0.0)) layer2 = tf.matmul(layer1, weights) + biases # 返回最后前向传播的结果。 return layer2
在这段代码中定义了神经网络的前向传播算法。无论是训练时还是测试时,都可以直接调用 inference 这个函数,而不用关心具体的神经网络结构。使用定义好的前向传播过程,以下代码给出了神经网络的训练程序 mnist_train.py。
# -*- coding: utf-8 -*- import os import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 加载 mnist_inference.py 中定义的常量和前向传播的函数。 import mnist_inference # 配置神经网络的参数。 BATCH_SIZE = 100 LEARNING_RATE_BASE = 0.8 LEARNING_RATE_DECAY = 0.99 REGULARAZTION_RATE = 0.0001 TRAINING_STEPS = 30000 MOVING_AVERAGE_DECAY = 0.99 # 模型保存的路径和文件名。 MODEL_SAVE_PATH = "/path/to/model/" MODEL_NAME = "model.ckpt" def train(mnist): # 定义输入输出 placeholder。 x = tf.placeholder( tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input') y_ = tf.placeholder( tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input') regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE) # 直接使用 mnist_inference.py 中定义的前向传播过程。 y = mnist_inference.inference(x, regularizer) global_step = tf.Variable(0, trainable=False) # 定义损失函数、学习率、滑动平均操作以及训练过程。 variable_averages = tf.train.ExponentialMovingAverage( MOVING_AVERAGE_DECAY, global_step) variables_averages_op = variable_averages.apply( tf.trainable_variables()) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( logits=y, labels=tf.argmax(y_, 1)) cross_entropy_mean = tf.reduce_mean(cross_entropy) loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses')) learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY) train_step = tf.train.GradientDescentOptimizer(learning_rate)\ .minimize(loss, global_step=global_step) with tf.control_dependencies([train_step, variables_averages_op]): train_op = tf.no_op(name='train') # 初始化 TensorFlow 持久化类。 saver = tf.train.Saver() with tf.Session() as sess: tf.global_variables_initializer().run() # 在训练过程中不再测试模型在验证数据上的表现,验证和测试的过程将会有一个独 # 立的程序来完成。 for i in range(TRAINING_STEPS): xs, ys = mnist.train.next_batch(BATCH_SIZE) _, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys}) # 每 1000 轮保存一次模型。 if i % 1000 == 0: # 输出当前的训练情况。这里只输出了模型在当前训练 batch 上的损失函 # 数大小。通过损失函数的大小可以大概了解训练的情况。在验证数据集上的 # 正确率信息会有一个单独的程序来生成。 print("After %d training step(s), loss on training " "batch is %g." % (step, loss_value)) # 保存当前的模型。注意这里给出了 global_step 参数,这样可以让每个被 # 保存模型的文件名末尾加上训练的轮数,比如“model.ckpt-1000”表示 # 训练 1000 轮之后得到的模型。 saver.save( sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) def main(argv=None): mnist = input_data.read_data_sets("/tmp/data", one_hot=True) train(mnist) if __name__ == '__main__': tf.app.run()
运行上面的程序,可以得到类似下面的结果。
~/mnist$ python mnist_train.py Extracting /tmp/data/train-images-idx3-ubyte.gz Extracting /tmp/data/train-labels-idx1-ubyte.gz Extracting /tmp/data/t10k-images-idx3-ubyte.gz Extracting /tmp/data/t10k-labels-idx1-ubyte.gz After 1 training step(s), loss on training batch is 3.46893. After 1001 training step(s), loss on training batch is 0.172291. After 2001 training step(s), loss on training batch is 0.197483. After 3001 training step(s), loss on training batch is 0.153582. After 4001 training step(s), loss on training batch is 0.117219. After 5001 training step(s), loss on training batch is 0.121872. After 6001 training step(s), loss on training batch is 0.0976607.
在新的训练代码中,不再将训练和测试跑在一起。训练过程中,每 1000 轮输出一次在当前训练 batch 上损失函数的大小来大致估计训练的效果。在上面的程序中,每 1000 轮保存一次训练好的模型,这样可以通过一个单独的测试程序,更加方便地在滑动平均模型上做测试。以下代码给出了测试程序 mnist_eval.py。
# -*- coding: utf-8 -*- import time import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 加载 mnist_inference.py 和 mnist_train.py 中定义的常量和函数。 import mnist_inference import mnist_train # 每 10 秒加载一次最新的模型,并在测试数据上测试最新模型的正确率。 EVAL_INTERVAL_SECS = 10 def evaluate(mnist): with tf.Graph().as_default() as g: # 定义输入输出的格式。 x = tf.placeholder( tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input') y_ = tf.placeholder( tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input') validate_feed = {x: mnist.validation.images, y_:mnist.validation. labels} # 直接通过调用封装好的函数来计算前向传播的结果。因为测试时不关注正则化损失的值, # 所以这里用于计算正则化损失的函数被设置为 None。 y = mnist_inference.inference(x, None) # 使用前向传播的结果计算正确率。如果需要对未知的样例进行分类,那么使用 # tf.argmax(y, 1) 就可以得到输入样例的预测类别了。 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 通过变量重命名的方式来加载模型,这样在前向传播的过程中就不需要调用求滑动平均 # 的函数来获取平均值了。这使得我们可以完全共用 mnist_inference.py 中定义的 # 前向传播过程。 variable_averages = tf.train.ExponentialMovingAverage( mnist_train.MOVING_AVERAGE_DECAY) variables_to_restore = variable_averages.variables_to_restore() saver = tf.train.Saver(variables_to_restore) # 每隔 EVAL_INTERVAL_SECS 秒调用一次计算正确率的过程以检测训练过程中正确率的# 变化。 while True: with tf.Session() as sess: # tf.train.get_checkpoint_state 函数会通过 checkpoint 文件自动 # 找到目录中最新模型的文件名。 ckpt = tf.train.get_checkpoint_state( mnist_train.MODEL_SAVE_PATH) if ckpt and ckpt.model_checkpoint_path: # 加载模型。 saver.restore(sess, ckpt.model_checkpoint_path) # 通过文件名得到模型保存时迭代的轮数。 global_step = ckpt.model_checkpoint_path .split('/')[-1].split('-')[-1] accuracy_score = sess.run(accuracy, feed_dict=validate_feed) print("After %s training step(s), validation " "accuracy = %g" % (global_step, accuracy_score)) else: print('No checkpoint file found') return time.sleep(EVAL_INTERVAL_SECS) def main(argv=None): mnist = input_data.read_data_sets("/tmp/data", one_hot=True) evaluate(mnist) if __name__ == '__main__': tf.app.run()
上面给出的 mnist_eval.py 程序会每隔 10 秒运行一次,每次运行都是读取最新保存的模型, 并在 MNIST 验证数据集上计算模型的正确率。如果需要离线预测未知数据的类别(比如这个样例程序可以判断手写体数字图片中所包含的数字),只需要将计算正确率的部分改为答案输出即可。运行 mnist_eval.py 程序可以得到类似下面的结果。注意因为这个程序每 10 秒自动运行一次,而训练程序不一定每 10 秒输出一个新模型,所以在下面的结果中会发现有些模型被测试了多次。一般在解决真实问题时,不会这么频繁地运行评测程序。
~/mnist$ python mnist_eval.py Extracting /tmp/data/train-images-idx3-ubyte.gz Extracting /tmp/data/train-labels-idx1-ubyte.gz Extracting /tmp/data/t10k-images-idx3-ubyte.gz Extracting /tmp/data/t10k-labels-idx1-ubyte.gz After 1 training step(s), validation accuracy = 0.0616 After 1001 training step(s), validation accuracy = 0.9764 After 2001 training step(s), validation accuracy = 0.9834 After 2001 training step(s), validation accuracy = 0.9834 After 3001 training step(s), validation accuracy = 0.9852 After 4001 training step(s), validation accuracy = 0.9854 After 5001 training step(s), validation accuracy = 0.986 After 6001 training step(s), validation accuracy = 0.9854
上面的程序可以将 MNIST 正确率达到~98.4%。
本文内容来自作者图书作品《TensorFlow: 实战 Google 深度学习框架》,点击购买。
作者介 **** 绍
郑泽宇,才云首席大数据科学家,前谷歌高级工程师。从 2013 年加入谷歌至今,郑泽宇作为主要技术人员参与并领导了多个大数据项目,拥有丰富机器学习、数据挖掘工业界及科研项目经验。2014 年,他提出产品聚类项目用于衔接谷歌购物和谷歌知识图谱(Knowledge Graph)数据,使得知识卡片形式的广告逐步取代传统的产品列表广告,开启了谷歌购物广告在搜索页面投递的新纪元。他于 2013 年 5 月获得美国 Carnegie Mellon University(CMU)大学计算机硕士学位, 期间在顶级国际学术会议上发表数篇学术论文,并获得西贝尔奖学金。
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 3 条评论