
Webster 最常用的词汇列表上可能并没有术语“Heisenbug”。但不幸的是,作为软件工程师,我们对这个可恶的家伙是再熟悉不过的了。量子物理学里有个海森堡不确定性原理(Heisenberg Uncertainty Principle),认为观测者观测粒子的行为会影响观测结果,术语“Heisenbug”是海森堡不确定性原理的双关语,指生产环境下不经意出现、费尽九牛二虎之力却无法重现的计算机 Bug。所以要同时重现基本情形和 Bug 本身几乎是不可能的。
但要是照着下面的方法去做,保证会出现 Heisenbug:
- 编写并发程序,但一定要忽略并发概念,比如发布、逸出、Java 内存模型和字节码重排序。
- 全面测试程序。(不要担心,所有的测试都会通过!)
- 把程序发布到生产环境。
- 等待生产环境瘫痪,并检查你的收件箱。你马上就会发现有大量尖酸刻薄的电子邮件在痛批你和你满是 Bug 的应用。
在想方设法规避这些 Heisenbug 之前,思考一个更根本的问题可能会更合适:既然并发编程如此困难,为什么还要这么做呢?事实上,进行并发编程的原因有很多:
并行计算——随着处理器和内核的增加,多线程允许程序进行并行计算,以确保某个内核不会负担过重、而其他内核却空闲着。即使在一台单核机器上,计算不多的应用也可能会有较多的 I/O 操作,或是要等待其他的一些子系统,从而出现空闲的处理器周期。并发能让程序利用这些空闲的周期来优化性能。
公平——如果访问一个子系统的客户端有两个甚至更多个,一个客户端必须等前面的客户端完成才能执行是很不可取的。并发可以让程序给每个客户端请求分配一个线程,从而缩短收到响应的延迟。
方便——编写一系列独立运行的小任务,往往比创建、协调一个大型程序去处理所有的任务要容易。
但这些原因并不能改变并发编程很难这一事实。如果程序员没有彻底考虑清楚应用里的并发编程,就会制造出严重的 Heisenbug。在这篇文章里,我们将介绍用 Java 语言架构或开发并发应用时需要记住的十个建议。
建议 1—自我学习
我建议精读由 Brian Goetz 编著的《Java 并发编程实践》一书。这部自 2006 年以来就畅销的经典著作从最基本的内容开始讲解 Java 并发。我第一次读这本书的时候有醍醐灌顶的感觉,并意识到了过去几年犯的所有错误,后来发现我会不厌其烦地提起这本书。要想彻底深入了解 Java 并发的方方面面,可以考虑参加并发专家培训,这门课程以《Java 并发编程实践》为基础,由Java 专家Heinz Kabutz 博士创建,并得到了Brian Goetz 的认可。
建议2—利用现有的专业资源
使用Java 5 引入的java.util.concurrent 包。如果你没怎么用过这个包里的各个组件,建议你从SourceForge 上下载能执行的Java Concurrent Animated 应用(运行java -jar 命令),这个应用包含一系列动画(事实上是由你定制的),演示了concurrent 包里的每个组件。下载的应用有个交互式的目录,你在架构自己的并发解决方案时可以参考。
Java 在 1995 年底问世时,成为最早将多线程作为核心语言特性的编程语言之一。并发非常难,我们当时发现一些很优秀的程序员都写不好并发程序。不久之后,来自奥斯威戈州立大学的并发大师 Doug Lea 教授出版了他的巨著《Java 并发编程》。这本书的第二版引入了并发设计模式的章节,java.util.concurrent 包后来就是以这些内容为基础的。我们以前可能会把并发代码混在类里面,Doug Lea 让我们把并发代码提取成能由并发专家检验质量的单独组件,这能让我们专注于程序逻辑,而不会过度受困于变化莫测的并发。等我们熟悉这个包、并在程序中使用的时候,引入并发错误的风险就能大大降低了。
建议 3—注意陷阱
并发并不是个高级的语言特性,所以不要觉得你的程序不会有线程安全方面的问题。所有的 Java 程序都是多线程的:JVM 会创建垃圾回收器、终结处理器(Finalizer)、关闭钩子等线程,除此以外,其他框架也会引入它们自己的线程。比如 Swing 和 Abstract Window Toolkit(AWT)会引入事件派发线程(Event Dispatch Thread)。远程方法调用(RMI)的 Java 应用编程接口,还有 Struts、Sparing MVC 等所谓的模型 - 视图 - 控制器(MVC)Web 框架都会为每个调用分配一个线程,而且都有明显的不足之处。所有这些线程都能调用你代码里的编程钩子,这可能会修改你应用的状态。如果允许多个线程在读或写操作中访问程序的状态变量,却没有正确的同步机制,那你的程序就是不正确的。要意识到这一点,并在并发编码时积极应对。
建议 4—采用简单直接的方法
首先保证代码正确,然后再去追求性能。封装等技术能确保你的程序是线程安全的,但也会减慢运行速度。不过 HotSpot 做了很好的优化工作,所以比较好的做法是先保证程序运行正确,然后再考虑性能调整。我们发现,比较聪明的优化方式往往会令代码比较费解、不易维护,一般也不会节省时间。要避免这样的优化,无论它们看上去多么优雅或聪明。一般来说,最好先写不经优化的代码,然后用剖析工具找出问题点和瓶颈,再尝试着去纠正这些内容。先解决最大的瓶颈,然后再次剖析;你会发现改正一个问题点后,接下来最严重的一些问题也会自动修复。一开始就正确地编写程序,要比后面再针对安全性改造代码容易一个数量级,所以要让程序保持简单、正确,并从一开始就认真记录所有为并发采取的措施。在代码使用 @ThreadSafe、@NotThreadSafe、@Immutable、@GuardedBy 等并发注释是一种很好的记录方式。
建议 5—保持原子性
在并发编程里,如果一个操作或一组操作在其调用和返回响应之间,对系统的其他部分来说就像在一瞬间发生的,那这个操作或这组操作就是原子的。原子性是并发处理互相隔离的保证。Java 能确保 32 位的操作是原子的,所以给 integer 和 float 类型的变量赋值始终都是完全安全的。当多个线程同时去设置一个值的时候,只要能保证一次只有一个线程修改了值,而不是好几个线程都修改了这个值,那就自然而然地做到了安全性。但涉及 long 和 double 变量的 64 位操作就没有这样的保证了;Java 语言规范允许把一个 64 位的值当成两个 32 位的值,用非原子的方式去赋值。结果在使用 long 和 double 类型的变量时,多个线程要是试图同时去修改这个变量,就可能产生意想不到和不可预知的结果,变量最终的值可能既不是第一个线程修改的结果,也不是第二个线程修改的结果,而是两个线程设置的字节的组合。举例来说,如果线程 A 将值设置成十六进制的 1111AAAA,与此同时,线程 B 将值设置为 2222BBBB,最后的结果很可能是 1111BBBB,两个线程可都没这么设置。把这样的变量声明成 volatile 类型可以很容易地修复这个问题,volatile 关键字会告诉运行时把 setter 方法作为原子操作执行。但 volatile 也不是万能的;虽然这能保证 setter 方法是原子的,但要想保证变量的其他操作也是原子的,还需要进一步的同步处理。举例来说,如果“count”是个 long 类型的变量,调用递加功能 count++ 完全有可能出错。这是因为 ++ 看起来是个单一操作,但事实上是“查询”、“增加”、“设置”三个操作的集合。如果并发线程不稳定地交叉执行 ++ 操作,两个线程就可能同时执行查询操作,获得相同的值,然后算出相同的结果,导致设置操作互相冲突、生成同样的值。如果“count”是个计数器,那某次计数就会丢失。当多个线程同时执行检查、更新和设置操作时,要确保在一个同步块里执行它们,或者是使用 java.util.concurrent.locks.Lock 的实现,比如 ReentrantLock。
很多程序员都认为只有写值需要同步、读取值则不用同步。这是一种错误的认知。举例来说,如果同步了写值操作,而读取值没进行同步,读线程极有可能看不到写线程写入的值。这看起来似乎是个 Bug,但它实际上是 Java 的一个重要特性。线程往往在不同的 CPU 或内核中执行,而在处理器的设计里,数据从一个内核移到另一个内核是比较慢的。Java 意识到了这一点,因而允许每个线程在启动时对状态进行拷贝;随后,如果状态在其他线程里的变化不合法,那仍然可以访问原始状态。虽然把变量声明成 volatile 能保证变量的可见性,但仍然不能保证原子性。你可以在必要的地方对代码进行正确地同步,你也有义务这么做。
建议 6—限制线程
要防止多个线程互相竞争去访问共享数据,一种方式就是不要共享!如果特定的数据点只由单个线程去访问,那就没有必要考虑额外的同步问题。这种技术称为“线程限制(Thread Confinement)”。
限制线程的一种方式是让对象不可变。尽管不可变的对象会生成大量的对象实例,但从维护的角度来说,不可变对象确实是专家要求的。
建议 7—注意 Java 内存模型
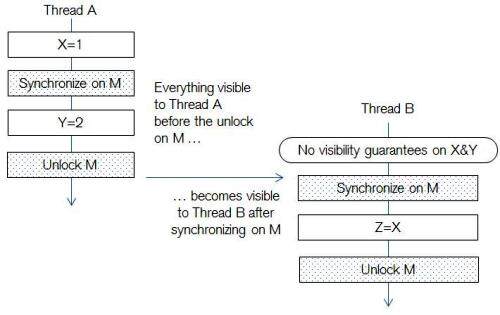
了解 Java 内存模型对变量可见性的约束。所谓的“程序次序法则”是指,在一个线程里设置的变量不需要任何同步,对这个线程之后的所有内容来说都是可见的。如果线程 A 调用 synchronized(M) 的时候获得了锁 M,锁 M 随后会被线程 A 释放、被线程 B 获取,那线程 A 释放锁之前的所有动作(包括获取锁之前设置的变量,也许是意料之外的),在线程 B 获得锁 M 之后,也对线程 B 可见。对线程可见的所有值来说,锁的释放就意味着内存提交。(见下图)。请注意,java.util.concurrent 里新的加锁组件 Semaphore 和 ReentrantLock 也表示相同的意思。volatile 类型的变量也有类似的含义:线程 A 给 volatile 变量 X 设置值,这类似于退出同步块;线程 B 读取 volatile 变量 X 的值,就类似于进入同一变量的同步块,这意味着在线程 A 给 X 赋值的时候,对线程 A 可见的那些内容在线程 B 读取 X 的值之后,也会对线程 B 可见。
建议 8—线程数
根据应用情况确定合适的线程数。我们使用下面的变量来推导计算公式:
假设 T 是我们要推导出的理想线程数;
C 是 CPU 个数;
X 是每个进程的利用率(%);
U 是目标利用率(%)。
如果我们只有一个被百分之百利用的 CPU,那我们只需要一个线程。当利用率是 100% 时,线程数应该等于 CPU 的个数,可以用公式表示为 T=C。但如果每个 CPU 只被利用了 x(%),那我们就可以用 CPU 的个数除以 x 来增加线程数,结果就是 T=C/x。例如,如果 x 是 0.5,那线程数就可以是 CPU 个数的两倍,所有的线程将带来 100% 的利用率。如果我们的目标利用率只有 U(%),那我们必须乘以 U,所以公式就变为 T=UC/x。最后,如果一个线程的 p% 是受处理器限制的(也就是在计算),n% 是不受处理器限制的(也就是在等待),那很显然,利用率 x=p/(n+p)。注意 n%+p%=100%。把这些变量代入上面的公式,可以得出如下结果:
T=CU(n+p)/n 或
T=CU(1+p/n)。
要确定 p 和 n,你可以让线程在每次 CPU 调用和非 CPU 调用(比如 I/O 调用和 JDBC 调用)的前后输出时间日志,然后分析每次调用的相对时间。当然,并不是所有的线程都会显示出相同的指标,所以你必须平均一下;对调整配置来说,求平均值应该是个不错的经验。得到大致正确的结果是很重要的,因为引入过多的线程事实上反而会降低性能。还有一点也不容小觑,就是让线程数保持可配置,这样在你调整硬件配置的时候,可以很容易地调整线程数。只要你计算出线程数,就可以把值传给 ThreadPoolExecutor。由于进程间的上下文切换是由操作系统负责的,所以把 U 设置得低一点,以便给其他进程留些资源。不过公式里的其他计算就不用考虑其他进程了,你只考虑自己的进程就可以了。
好消息是会有一些偏差,如果你的线程数有 20% 左右的误差,那可能不会有较大的性能影响。
建议 9—在 server 模式下开发
在 server 模式下进行开发,即便你开发的只是个客户端应用。server 模式意味着运行时环境会进行一些字节码的重排序,以实现性能优化。相对 client 模式来说,server 模式会更频繁地进行编译器优化,不过在 client 模式下也会发现这些优化点。在测试过程中使用 server 模式能尽早进行优化处理,就不用等到发布到生产环境里再进行优化了。
但要分别使用 -server、-client 和 -Xcomp 参数进行测试(提前进行最大优化,以避免运行时分析)。
要设置 server 模式,在调用 java 命令时使用 -server 选项。在 Java Specialists 享誉盛名的 Heinz Kabutz 博士指出,一些 64 位模式的 JVM(比如 Apple OSX 最近才推出的 JVM)会忽略 -server 选项,所以你可能还要使用 -showversion 选项,-showversion 选项会在程序日志的一开始显示版本,并指明是 client 模式还是 server 模式。如果你正在用 Apple OSX,你可以用 -d32 选项切换到 32 位模式。简言之,使用 -showversion -d32 -server 进行测试,并检查日志,以确保使用的 Java 版本正是你期望的那个。Heinz 博士还建议,用 -Xcomp 和 -Xmixed 选项各进行一次独立的测试(-Xcomp 不会进行 JIT 运行时优化;-Xmixed 是缺省值,会对 hot spots 进行优化)。
建议 10—测试并发代码
我们都知道怎么创建单元测试程序,对代码里方法调用的后置条件进行测试。在过去这些年里,我们费了很大的劲儿才习惯执行单元测试,因为我们完成开发、开始维护的时候,才明白单元测试节省的时间所带来的价值。不过测试程序时,最重要的方面还是并发。因为并发是最脆弱的代码,也是我们能找到大部分 Bug 的地方。但具有讽刺意味的是,我们往往是在并发方面最疏忽大意,主要是因为并发测试程序很难编写。这要归因于线程交叉执行的不确定性——哪些线程会按什么样的顺序执行,通常是预测不出来的,因为在不同的机器上、甚至在同一机器的不同进程里,线程的交叉执行都会有所不同。
有一种测试并发的方法是用并发组件本身去进行测试。比如说,为了模拟任意的线程时间安排,要考虑线程次序的各种可能性,还要用定时执行器确切地按照这些可能性给线程排序。测试并发的时候,线程抛出异常并不会导致 JUnit 失败;JUnit 只在主线程遇到异常时才会失败,而其他线程遇到异常的时候则不会。解决这个问题的方法之一是把并发任务指定为 FutureTask,而不是去实现 Runnable 接口。因为 FutureTask 实现了 Runnable 接口,可以把它提交给定时执行的 Executor。FutureTask 有两个构造函数,其中一个接受 Callable 类型的参数,一个接受 Runnable 类型的参数。Callable 和 Runnable 类似,不过还是有两个显著的不同之处:Callable 的 call 方法有返回值,而 Runnable 的 run 方法返回 void;Callable 的 call 方法会抛出可检查型异常 ExecutionException,Runnable 的 run 方法只会抛出不可检查型异常。ExecutionException 有个 getCause 方法,这个方法会返回触发它的实际异常。(请注意,如果你传入的参数是 Runnable 类型,你还必须传入一个返回对象。FutureTask 内部会将 Runnable 和返回对象包装成 Callable 类型的对象,所以你仍然可以利用 Callable 的优势。)你可以用 FutureTask 安排并发代码,让 JUnit 的主线程调用 FutureTask 的 get 方法获取结果。Callable 或 Runnable 对象异步抛出的所有异常,get 方法都会重新抛出来。
但也有一些挑战。假设你期望一个方法是阻塞的,你想测试它是不是真的和预期一样。那你怎么测试阻塞呢?你要等多久才能确定这个方法确实阻塞了呢?FindBugs 会定位出来一些并发问题,你也可以考虑使用并发测试框架。Bill Pugh 是 FindBugs 的作者之一,他参与创建的 MultithreadedTC 提供了一套 API,可以指定、测试所有的交叉执行情况,以及其他并发功能。
在测试的时候要牢记一点——Heisenbug 并不会在每次运行时都出现,所以结果并不是简单的“通过”或“不通过”。多次循环(数千遍)执行并发测试程序,根据平均值和标准差得出统计指标,再去衡量是否成功了。
总结
Brian Goetz 告诫过大家,可见性错误会随着时间的推移越来越普遍,因为芯片设计者设计的内存模型在一致性方面越来越弱,不断增多的内核数量也会导致越来越多的交叉存取。
所以千万不要想当然地处理并发。要了解 Java 内存模型的内部工作机制,并尽量使用 java.util.concurrent 包,以便消灭并发程序里的 Heisenbug,然后就等着表达满意和好评的电子邮件纷至沓来吧。
链接:
作者简介

Victor Grazi今年五月成为一名 Oracle Java Champion,他从 2005 年起就职于瑞士瑞信银行的投资银行架构部,处理平台架构的相关事宜,他还是一名技术咨询师和 Java 技术布道者。此外,他经常在技术会议上演讲,给大家讲解 Java 并发和其他 Java 相关的主题。Victor 是“并发专家课程”的贡献者和教练,他还在 SourceForge 上提供了开源项目“Java Concurrent Animated”。他和他的家人住在纽约布鲁克林区。
查看英文原文: Exterminating Heisenbugs
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论