
深层神经网络(简称 DNN)是一类高度通用且日益普及的机器学习模型 ; 与传统方法相比,深层神经网络往往需要更多时间与更为强大的计算资源作为支撑。通过在微软 HDInsight 集群之上部署此类模型,数据科学家与工程师们能够轻松扩展可用计算资源,以便继续使用原本熟知的脚本语言与深度学习框架实现其运行所需的吞吐能力。作为我们 Azure 平台深度学习应用系列文章的第五篇,本文将展示如何在微软 Cognitive Toolkit(简称 CNTK)与谷歌 TensorFlow 两大常见深度学习框架当中构建 DNN,并利用其配合 PySpark 在 Azure Data Lake Store 之上对大规模图像集合进行评分。我们将这种方法应用于常规 DNN 用例——即航拍图像分类,并展示此种方法如何识别城市发展当中的各类最新模式。
本篇文章亦是对我们工作内容的摘要与总结。如果您需要获取示例数据 / 代码 / 模型以及分步指南,请点击此处查看完整版教程。
在本系列的前四篇文章中,我们分别探讨了如何利用其它深度学习框架、脚本语言、用例以及 / 或者 Azure 服务对 DNN 进行训练与操作。这四篇文章皆采用 MXNet,即一套作为 CNTK 与 TensorFlow 替代性方案的深度学习框架选项。而本文的示例将主要采用 Python/PySpark,这一点与采用微软 R Server/SparkR 的第一到第三篇文章有所不同。而第四篇文章则讨论如何训练一套文本分类模型,并在 Azure Web Apps(而非 HDInsight Spark)之上对其进行操作。
- 《利用 Azure GPU 虚拟机、MXNet 与微软 R Server 在云端构建深层神经网络》
- 《利用微软 R Server 与 Azure Data Lake 实现云规模深度学习》
- 《利用微软 R Server 与 Azure GPU 虚拟机在 ImageNet 上训练深层神经网络》
- 《在微软 Azure 上利用卷积神经网络实现云规模文本分类》
航拍图像分类用例说明
航拍图像分类属于一种常见任务,且在多种行业当中拥有重大原经济与政治意义。精细农业领域经常通过分析航拍影像以监测作物生长情况,同时确定需要进行纠正及治疗的地块。在营销与财务方面,图像分类器则可识别属性特征,有助于对物业价值进行估算。政府机构则可利用航拍影像分类以执行各项政策规定:举例来说,希腊最近就通过识别航拍影像中包含家庭游泳池的不动产发现数以万计逃税者。图像分类器亦适用于地缘政治监测,发现新的远程定居点,同时评估人口密度或在不存在直接数据的情况下推断特定区域内的经济活力。此外,政府及学术界的研究人员也可以利用这些航拍数据以追踪城市扩张、森林砍伐以及气候变化等因素带来的影响。
本文与相关教程则着眼于其中一项具体用命:利用航拍图像预测某一区域内的土地利用方式(包括开发、种植与森林等)。这类应用中需要的大量训练与验证数据集能够通过美国航拍图像与地面实际土地利用标签轻松构建完成。而利用此类数据训练而成的图像分类器将能够量化土地使用趋势,甚至在个人财产层面确定新的土地开发活动,具体如下图所示。
通过迁移学习训练航拍图像分类器
从零开始构建 DNN 可能需要长达数周的 GPU 计算周期以及极为庞大的训练数据集。作为替代选项,常见的办法是重新调整已经完成了相关任务训练的现有 DNN:这一过程被称为迁移学习或者重新训练。为了说明迁移学习的实现方法,这里我们将阐述 AlexNet(本用例中将要使用的一种原型图像分类 DNN)及其各层的实际作用。
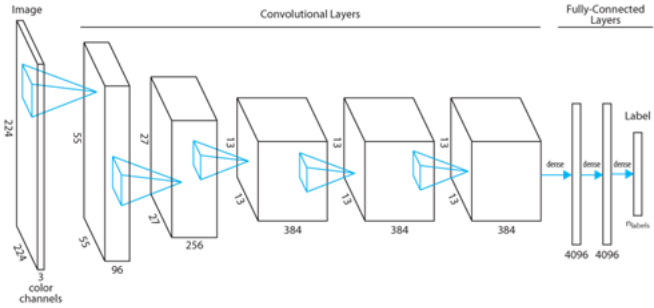
AlexNet 中的第一层(同时也是大多数其它图像分类 DNN 中的首层)为卷积层。此层中的每个神经元从输入图像中的一条 11 像素 x11 像素 x3 色彩通道(即 RGB)内获取输入数据。该神经元的学习权重被统称为卷积滤波器,负责确定神经元针对输入内容给出的单值输出结果。通过以四像素步幅沿图像的 x 与 y 维度进行输入区域滑动,该神经元的滤波器与完整的 224 x 224 x3 输入图像之间将生成尺寸为 55 x 55 x 1 维度的卷积。实际上,此类卷积通常通过将 55 x 55 个神经元的相同副本接入不同输入区域来实现。96 个此类神经元组共同构成 AlexNet 的第一层,即允许其学习 96 种不同的卷积滤波器。
在训练过程中,第一层中的多数神经元负责学习对应于边缘检测器的卷积滤波器,其中各边缘检测器可能各自拥有不同的方向与 / 或色彩灵敏度。此项功能可通过检查卷积滤波器本身或者识别对神经元存在强激活效应的图像进行可视化,这项技术由 Zeiler 与 Fegus 于 2013 年率先提出。以下图像(已经得到 Matt Zeiler 的转载许可)显示出 AlexNet 第一层中四个示例神经元的卷积滤波器(首行)与强激活图像(末行)样本:

典型的图像分类 DNN 当中还包含其它卷积层,这些卷积层与首层神经元输出相结合以识别更为复杂的形状。下图(已经得到 Matt Zeiler 的转载许可)显示了强激活训练 DNN 的第二层至第五层当中的示例神经元样本图像。较低层中的神经元由在多标签图像中的简单形状与色彩组合进行强激活,具体包括圆形物体或者腿部等。在较高层中,神经元则通常更具类特定性:其可能被从多个视角的相同对象或者具有相同标签的不同对象所激活。

由后续卷积层识别出的复杂形状属于图像分类当中的优秀预测因子,但其以组合方式使用效果更佳。举例来说,“轮胎”形状可能存在于汽车与摩托车图像当中,但是同时包含“轮胎”与“头盔”形状的图像则可能表达了摩托车内容。一般来讲,图像分类 DNN 当中的充分连接后续卷积层一般会将此类逻辑编码在训练模型当中。该模型的最终充分连接层包含在数量上等同于类的大量神经元(初始 AlexNet 中数量为 1000); 该模型的预测输出标签则由此层中的最大激活神经元指数给出。
在迁移学习当中,预训练模型的最后一层(有时可能包括更多完全连接层)会被移除,并替代以一个或者多个利用新的分类任务进行训练的新层。在最简单的迁移学习形式当中,经过训练的模型的保留层将被“冻结”:即在重新训练期间不改变其权重。这种作法通过限制模型当中自由参数的数量以降低过度拟合的可能性,但亦有可能带来也许不适合新的图像分类任务的图像特征。我们也可以通过另一种被称为微调的方法对旧有层的权重进行更新,这能够更好地适应新任务的特征,但通常需要规模较大的训练集以避免过度拟合。
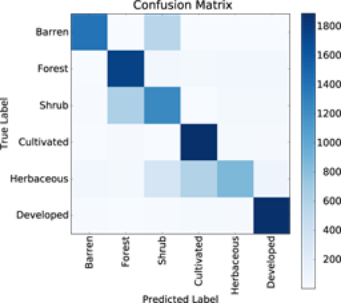
为了对我们的航拍图像分类器进行训练,这里我们替换 ImageNet 训练完毕的图像分类 DNN 中(面向 CNTK 的 AlexNet,TensorFLow 下则为一套 50 层 ResNet)的最终层,同时冻结其它剩余层。我们高兴地发现,原本用于在 ImageNet 数据集中进行分类的特征也同样适用于明显与之无关的新航拍图像。(两套模型在处理六种土地利用类别图像时的总体准确度约为 80%,而在未开发土地分类情况下的准确度进一步上升至约 92%; CNTK 模型的混淆矩阵如下所示。)不过也有部分其他用户报告称,现有模型无法通过迁移学习适应新的任务要求:一定比例的成功机率,再加上相对较低的资源需求以及对小型训练集的适应能力,解释了为何工业应用当中更倾向于选择迁移学习而非重新进行模型训练。
Spark 操作方法
数据科学家在 DNN 训练期间通常会采用一种名为“小批量(minibatching)”的方法。具体来讲,其在每个训练轮次当中对训练图像中的一个子集进行评分(通常立足 GPU 的多个核心进行并行处理),并将结果加以组合以更好地推断参数并更新梯度。包括 CNTK 以及 TensorFLow 在内的各类深度学习框架都提供便捷的方式以实现小批量方法,从而描述训练文件的具体加载与预处理方式。多数用户在训练过程当中可能并没有意识到这些高效功能的存在,而在将训练完毕的模型应用于新数据时则是不可利用这些功能。举例来说,我们的用例需要利用 PySpark 将经过训练的 DNN 应用于 Azure Data Lake Store 上的大型图像集:在这种情况下,由于文件并未存储在本地,因此无法使用 CNTK 以及 TensorFlow 中的内置图像加载 / 预处理机制(同样的问题也经常出现在各类 Web 服务以及机器人应用当中)。在这类情况下,我们必须忠实地复制模型训练期间所执行的加载与预处理步骤。大家可以参阅我们的 Git 库以了解此流程当中示例 Python 脚本的细节信息。
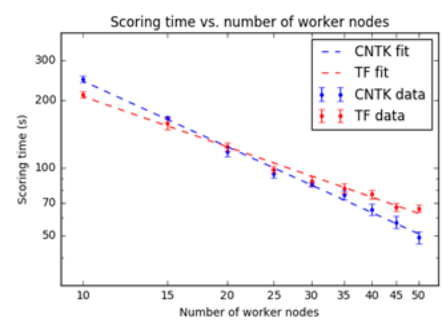
深度学习框架安装与为了评估并行化脚本进行的调整对于在 Spark 集群之上操作 DNN 同样非常重要。我们提供一套示例脚本以演示如何协调 CNTK、TensorFlow 以及全部依赖项的安装操作。Spark 集群通过将一部分工作负载分配给各个“工作节点”以快速执行可分配任务:大家可以在部署过程中指定工作节点的数量,并随后根据需求变化对其进行动态伸缩。如下图所示,执行图像处理任务所需要的总体时间与可用于处理的节点数量成反比。托管在同一 Azure Data Lake Store 上的同地协作 Spark 集群作为输入数据与合适的跨工作节点图像分区选项,这将减少图像与模型的加载延迟。教程当中的示例 Jupyter notebook 说明了使用 PySpark 进行图像处理协调的具体细节。
航拍图像分类器的实际应用
为了演示这套经过训练的分类器的潜在用途,我们利用这套 CNTK 模型处理英国米德尔塞克斯郡(微软新英格兰研发中心所在地)的航拍图像。利用该模型对 2016 年收集的图像预测结论同上一次经过证实的标签(2011 年分析结果)进行比较,我们得以识别出该郡内新近发展的区域,甚至包括部分独立物业设施(见下图中央的 224 米 x 224 米区块)。

我们这套模型的准确度足以归纳出全郡发展的主要趋势。在下图当中,各个像素代表着一个 224 米 x 224 米单一区域的分类结果,其中绿色像素代表未经开发的土地、红色像素代表已经开发的土地,而白色像素则代表耕地。(左图为国土资源数据库提供的已证实标签,中图与右图则分别代表根据此前与新近航拍图像得出的预测结论。)

如果您希望进一步了解我们的工作内容,包括相关示例数据 / 代码与实践,请点击此处查阅相关教程。
Mary、T.J.、Miruna 与 Sudarshan。
感谢 Mario Bourgin、Yan Zhang 以及 Rahee Ghosh 对本文的校对以及文中所提及教程的测试。

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论