
要点
- 学习如何在异构的运行环境里使用 Pipeline61 管理数据管道
- Pipeline61 的三个主要组件:执行引擎、数据服务,以及依赖和版本管理器
- 自动化版本控制和依赖管理为我们提供了历史可追踪性和可再现性
- 比较几个数据管道框架,如 Crunch、Pig、Cascading、Flume 和 Tez
- 案例学习:使用 Pipeline61 处理三种不同格式的数据(CSV、文本和 JSON)
这篇文章先是出现在 IEEE Software 杂志上,IEEE Software 是一本提供严谨科技资讯的杂志。企业总是在可靠性和灵活性方面面临挑战,IT 经理和技术领导者依赖 IT 专家们来提供高超的解决方案。
Pipeline61 框架可以用于为异构的运行环境构建数据管道。它可以重用已经部署在各个环境里的作业代码,并提供了版本控制和依赖管理来解决典型的软件工程问题。
研究人员开发了大数据处理框架,如 MapReduce 和 Spark,用于处理分布在大规模集群里的大数据集。这些框架着实降低了开发大数据应用程序的复杂度。在实际当中,有很多的真实场景要求将多个数据处理和数据分析作业进行管道化和集成。例如,图像分析应用要求一些预处理步骤,如图像解析和特征抽取,而机器学习算法是整个分析流里唯一的核心组件。不过,要对已经开发好的作业进行管道化和集成,以便支持更为复杂的数据分析场景,并不是一件容易的事。为了将运行在异构运行环境里的数据作业集成起来,开发人员必须写很多胶水代码,让数据在这些作业间流入流出。Google 的一项研究表明,一个成熟的系统可能只包含了 5% 的机器学习代码,而剩下的 95% 都是胶水代码。
为了支持对大数据作业进行管道化和集成,研究人员推荐使用高级的管道框架,如 Crunch、Pig 和 Cascading 等。这些框架大都是基于单一的数据处理运行环境而构建的,并要求使用特定的接口和编程范式来构建管道。况且,管道应用需要不断演化,满足新的变更和需求。这些应用还有可能包含各种遗留的组件,它们需要不同的运行环境。因此,维护和管理这些管道变得非常复杂和耗时。
Pipeline61 框架旨在为在异构的运行环境里维护和管理数据管道减少精力的投入,而不需要重写原有的作业。它可以将运行在各种环境里的数据处理组件集成起来,包括 MapReduce、Spark 和脚本。它尽可能重用现有的数据处理组件,开发人员就没有必要重新学习新的编程范式。除此之外,它为每个管道的数据和组件提供了自动化的版本控制和依赖管理。
现有的管道框架
大多数用于构建管道化大数据作业的框架都是基于单一的处理引擎而构建的(比如 Hadoop),并使用了外部的持久化服务(比如 Hadoop 分布式文件系统)来交换数据。表 A 比较了几种最为重要的管道框架。
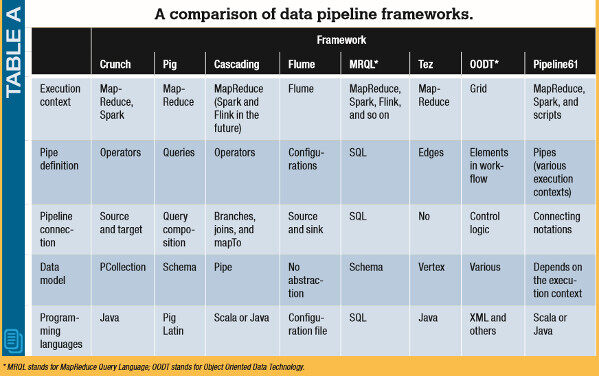
Crunch 定义了自己的数据模型和编程范式,用于支持管道的写入,并在 MapReduce 和 Spark 上运行管道作业。Pig 使用了一种基于数据流的编程范式来编写 ETL(抽取、转换、加载)脚本,并在执行期被转换成 MapReduce 作业。Cascading 为管道提供了基于操作符的编程接口,并支持在 MapReduce 上运行 Cascading 应用。 Flume 最初是为基于日志的管道而设计的,用户通过配置文件和参数来创建管道。 MRQL (MapReduce 查询语言)是一种通用的系统,用于在各种运行环境上进行查询和优化,如 Hadoop、Spark 和 Flink 。Tez 是一个基于有向无环图的优化框架,它可以用于优化使用 Pig 和 Hive 编写的 MapReduce 管道。
Pipeline61 与这些框架的不同点在于:
- 支持对异构的数据处理作业(MapReduce、Spark 和脚本)进行管道化和集成。
- 重用现有的编程范式,而不是要求开发人员学习新的编程范式。
- 提供自动化的版本控制和依赖管理,具备历史可追踪性和可重现性,这些对于管道的持续开发来说是非常重要的。
与 Pipeline61 类似,Apache Object Oriented Data Technology( OODT )数据栅格框架支持让用户从异构环境中捕捉、定位和访问数据。与 Pipeline61 相比,OODT 提供了更具通用性的任务驱动工作流执行过程,开发人员必须编写程序来调用不同的任务。相反,Pipeline61 专注于与当前的大数据处理框架进行深度集成,包括 Spark、MapReduce 和 IPython。OODT 使用了基于 XML 的管道配置,而 Pipeline61 为各种编程语言提供了编程接口。最后,OODT 需要维护数据集的一般性信息和元数据。Pipeline61 为管道里的 IO 数据和转换任务提供了显式的来源信息。因此,Pipeline61 原生地支持历史数据管道或部分数据管道的重新生成和重新执行。
一个有趣的例子
我们的例子是一个嫌疑检测系统,图 1 展示了该系统的数据处理管道。系统收集来自各个部门和组织的数据,比如来自政府道路服务部门的机动车注册记录、来自政府税务部门的个人收入报告,或来自航空公司的航程记录。来自不同数据源的记录可能具有不同的格式,如 CSV、文本、JSON,它们的结构是不一样的。
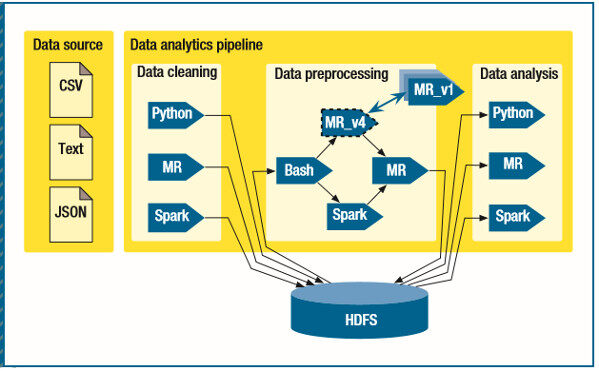
图 1. 嫌疑检测系统的数据处理管道。来自不同部门和组织的数据可能具有不同的格式和结构。CSV 表示以逗号分隔的数据值,JSON 表示 JavaScript Object Notation,MR 表示 MapReduce,HDFS 是 Hadoop 分布式文件系统。
在数据管道的各个阶段,不同的数据科学家或工程师们可能使用不同的技术和框架来开发数据处理组件,比如 IPython、MapReduce、R 和 Spark。一些遗留的组件也可以通过 Bash 脚本或第三方软件进行集成。所以,管理和维护异构环境里持续变化的数据管道是一个复杂而沉闷的任务。使用新框架替代旧框架的代价是很高的,或许更加难以承受。在最坏的情况下,开发人员可能需要重新实现所有的数据处理组件。
另外,正如我们之前提过的那样,为了满足新的系统变更需求,管道应用程序需要保持演化和更新。例如,可能会有新的数据源加入进来,或者现有的数据源的格式和结构会发生变更,或者升级分析组件来提升性能和准确性。这些都会导致管道组件的持续变化和更新。在管道演化过程中提供可追踪性和可再现性会成为一个挑战。管道开发人员可能想检查管道的历史,用于比较更新前后有什么不同。另外,如果有必要,每个数据处理组件应该能够回滚到上一个版本。
Pipeline61
为了解决这些挑战性问题,Pipeline61 使用了三个主要的组件:执行引擎触发器、监控器,以及管道管理器。数据服务提供了统一的数据 IO 层,用于完成枯燥的数据交换以及各种不同数据源之间的转换工作。依赖和版本管理器为管道里的数据和组件提供了自动化的版本控制和依赖管理。Pipeline61 为开发人员提供了一套管理 API,他们可以通过发送和接收消息进行管道的测试、部署和监控。
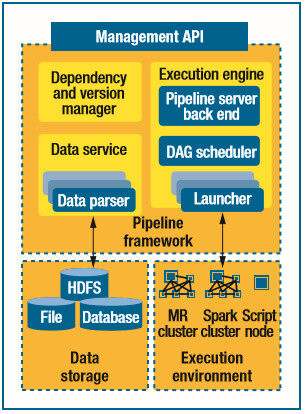
图 2. Pipeline61 架构。Pipeline61 框架旨在为在异构的运行环境里维护和管理数据管道减少精力的投入,而不需要重写原有的作业。DAG 表示有向无环图。
Pipe 模型
Pipeline61 将管道组件表示为 pipe,每个 pipe 有一些相关联的实体:
- pipe 的名字必须是唯一的,而且要与 pipe 的管理信息具有相关性。名字里可以包含命名空间信息。
- pipe 的版本信息会自动增长。用户可以执行指定版本的 pipe。
- 管道服务器负责管理和维护 pipe。pipe 需要知道管道服务器的地址信息,在运行期间,它可以向管道服务器发送通知消息。
- 输入和输出 URL 里包含了 pipe 的 IO 数据所使用的协议和地址。协议表示持久化系统的类型,如 HDFS(Hadoop 分布式文件系统)、JDBC(Java Database Connectivity)、S3(Amazon Simple Storage Service)、文件存储和其他类型的数据存储系统。
- IO 数据的输入格式和输出格式指明了数据的读取格式和写入格式。
- 运行上下文指明了运行环境和运行框架所需要的其他信息。
运行上下文与数据处理框架紧密相关。Pipeline61 目前有三种主要的运行上下文:
- Spark 运行上下文包含了一个 SparkProc 属性,该属性为 SparkSQL 提供了一个转换函数,用于将输入 RDD(弹性分布式数据集)转化成输出 RDD,或者将输入 DataFrame 转换成输出 DataFrame。
- MapReduce 运行上下文包含了一些结构化的参数,指明了 MapReduce 作业的 Mapper、Reducer、Combiner 和 Partitioner。可以使用 key-value 的形式添加其他参数。
- shell 运行上下文包含了一个脚本文件或者内联的命令。Python 和 R 脚本是 shell pipe 组件的子类型,它们可以使用更多由数据服务控制的输入和输出。shell pipe 的不足之处在于,开发人员必须手动地处理输入和输出的数据转换。
图 3 展示了如何写一个简单的 SparkPipe。基本上,开发人员只要使用 SparkProc 接口来包装 Spark RDD 函数,然后使用 SparkProc 初始化一个 SparkPipe 对象。

图 3. 如何写一个简单的 SparkPipe。开发人员使用 SparkProc 接口包装 Spark RDD 函数,然后使用 SparkProc 初始化一个 SparkPipe 对象。
Pipeline61 让开发人员可以在逻辑层面将不同类型的 pipe 无缝地集成到一起。它提供了方法,用于将 pipe 连接起来形成管道。在将 pipe 连接起来之后,前一个 pipe 的输出就变成了下一个 pipe 的输入。在后面的案例学习部分,我们会展示一个更具体的例子。
执行引擎
执行引擎包含了三个组件。
管道服务器包含了消息处理器,用于接收和处理来自用户和任务的消息。用户可以通过发送消息来提交、部署和管理他们的管道作业和依赖。运行中的任务可以通过发送消息来报告它们的运行状态。运行时消息也可以触发一些事件,这些事件可以在运行期间调度和恢复进程。
有向无环图调度器遍历管道的任务图,并将任务提交到相应的运行环境。一个任务会在它的所有父任务都被成功执行之后进入自己的执行调度期。
任务启动器为 pipe 启动执行进程。目前,Pipeline61 使用了三种类型的任务启动器:
- Spark 启动器会初始化一个子进程,作为执行 Spark 作业的驱动进程。它会捕捉运行时状态的通知消息,并将通知发送给管道服务器,用于监控和调试。
- MapReduce 启动器会初始化一个子进程,用于提交由 pipe 指定的 MapReduce 作业。在将执行状态发送给管道服务器之前,子进程会等待作业执行完毕,不管是成功还是失败。
- shell 启动器会创建一系列进程通道,用于处理 shell 脚本或者由 shell pipe 所指定的命令。在这些进程结束或者任何一个进程失败之后,相关的状态消息将被发送给管道服务器。
开发人员可以实现新的任务启动器,用于支持新的运行上下文:
- 可以使用由执行框架(比如 Hadoop 和 Spark)提供的 API
- 在已经启动的进程里初始化子进程,并执行程序逻辑。
理论上,任何可以通过 shell 脚本启动的任务都可以使用进程启动器来执行。
数据服务
每个 pipe 在运行期间都是独立执行的。pipe 根据输入路径和格式来读取和处理输入数据,并将输出结果写入指定的存储系统。管理各种 IO 数据的协议和格式是件枯燥的事情,而且容易出错。所以,数据服务为开发人员代劳了这些工作。
数据服务提供了一组数据解析器,它们根据给定的格式和协议在特定运行环境里读取和写入数据。例如,对于一个 Spark pipe 来说,数据服务使用原生的 Spark API 来加载文件本文到 RDD 对象,或者使用 SparkSQL API 从 JDBC 或 JSON 文件加载数据到 Spark DataFrame。对于 Python pipe 来说,数据服务使用 Python Hadoop API 加载 CSV 文件的数据到 HDFS,并转换成 Python DataFrame。基本上,数据服务是将数据协议和格式映射到特定运行环境的数据解析器。
我们可以扩展数据服务,实现并注册新的数据解析器。一些数据解析工具,如 Apache Tika ,可以作为数据服务的补充实现。
依赖和版本管理器
对于管道管理员来说,管理和维护管道生命周期是一件很重要的事情,同时也很复杂。 为了解决管道管理方面存在的痛点,依赖和版本管理器可以帮助用户来维护、跟踪和分析管道数据和组件的历史信息。
依赖和版本管理器为每个管道维护了三种类型的信息。管道执行跟踪过程为管道应用程序的每一个运行实例维护了一个数据流图。每个图的节点都包含了实例组件的元数据,比如启动时间、结束时间和运行状态。
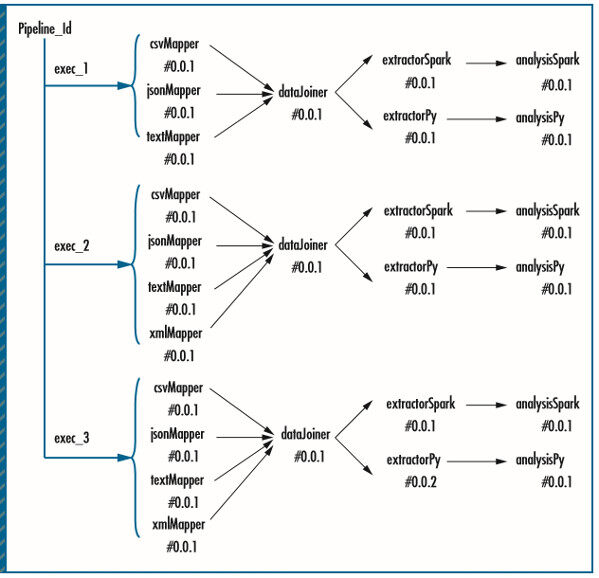
图 4. 在 Pipeline61 中维护的历史和依赖信息,第一部分。管道执行跟踪过程为管道应用程序的每一个运行实例维护了一个数据流图。
管道依赖跟踪过程 (图 5a) 为每个管道组件的不同版本维护着历史元数据。它将每个组件的依赖信息保存成树状结构。保存在树中的元数据包含了最近更新的名字、版本、作者、时间戳,以及运行依赖包。
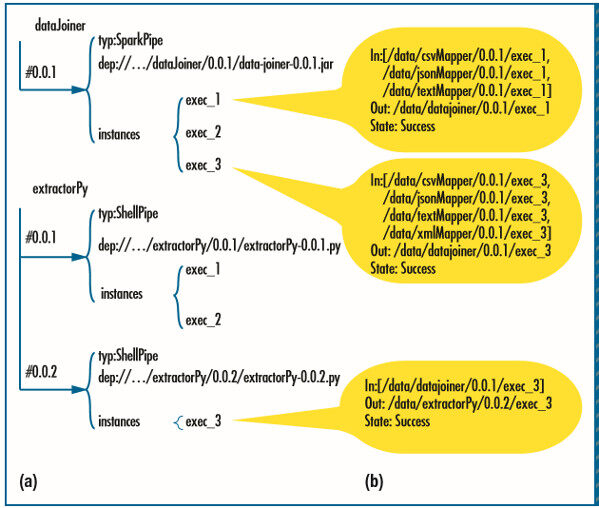
图 5. 在 Pipeline61 中维护的历史和依赖信息,第二部分。(a) 管道依赖跟踪过程为每个管道组件的不同版本维护着历史元数据。(b) 数据快照包含了管道应用程序每一个运行实例的输入输出位置和样本数据。
数据快照(图 5b)包含了管道应用程序每一个运行实例的输入输出位置和样本数据。
Pipeline61 用户可以通过这些历史信息来分析管道历史,并通过重新运行旧版本的管道来重新生成历史结果。
案例学习
以下的案例学习展示了 Pipeline61 的效率和优势。示例使用了来自不同组织的三种格式的数据源,包括 CSV、文本和 JSON。两组数据科学家使用少量手写的 MapReduce 和 Python 程序来对整体数据集进行分析。我们引入了我们的管道框架,用于自动执行管道任务和管道管理。图 6 展示了我们是如何在 Pipeline61 里指定管道的。

图 6. 在 Pipeline61 里指定管道。在相关的案例学习里,两组数据科学家使用少量手写的 MapReduce 和 Python 程序来对整体数据集进行分析。
首先,我们指定了三种数据映射器——csvMapper、jsonMapper 和 textMapper——用于处理不同格式的输入数据。我们指定了三个 MapReduce pipe,并将三种 mapper 分别作为数据解析器传递进去。
接下来,我们使用 RDD 函数 DataJoinerProc 指定了一个叫作 dataJoiner 的 Spark pipe,用于组合三种 mapper 的输出结果。
最后,我们指定了两组分析 pipe 组件,从 dataJoiner 那里消费输出结果。因为每个分析分支关注不同的输入特征,我们为每个分析组件添加了一个特征抽取器。然后我们将这两个分析组件实现为 Python pipe 和 Spark pipe。最后,我们使用连接操作将这些 pipe 连接在一起,组成了整体的数据流。
在这个场景里,如果使用现有的管道框架,比如 Crunch 和 Cascading,那么开发人员需要重新实现所有的东西。这样做存在风险,也非常耗时。它不仅对重用已有的 MapReduce、Python 或 shell 脚本程序造成限制,而且也对数据分析框架(如 IPython 和 R)的使用造成约束。
相反,Pipeline61 专注于管理和管道化异构的管道组件,所以它可以显著地减少集成新旧数据处理组件所需要的投入。
管道后续的开发和更新也会从 Pipeline61 的版本和依赖管理中获得好处。例如,如果开发人员想要更新一个组件,他们可以从数据快照历史中获得组件最新的输入和输出样本。然后,他们基于样本数据实现和测试新的程序,确保新版本组件不会对管道造成破坏。
在将更新过的组件提交到生产环境之前,开发人员可以为新组件指定一个新的管道实例,并将它的输出结果与生产环境的版本进行比较,对正确性进行双重检查。除此之外,如果新组件在部署之后出现错误,管道管理器可以很容易地回滚到前一个版本。管道服务器自动维护着每个组件的历史数据和依赖,所以可以实现回滚。
这种 DevOps 风格的支持对于维护和管理管道应用程序来说是很有意义的,而现有的管道框架很少会提供这些支持。
不过 Pipeline61 也存在不足。它不检查各个数据处理框架数据结构的兼容性。到目前为止,开发人员在进行管道开发时,必须手动对每个 pipe 的输入和输出进行手动测试,确保一个 pipe 的输出可以作为下一个 pipe 的输入。为了解决这个问题,我们打算使用现有的结构匹配(schema-matching)技术。
当然,在管道运行期间,大部分中间结果需要被写到底层的物理数据存储(如 HDFS)里,用于连接不同运行上下文的 pipe,同时保证管道组件的可靠性。因此,Pipeline61 的管道运行比其他框架要慢,因为其他框架独立运行在一个单独的环境中,不需要与外部系统集成。我们可以通过只保存重要的数据来解决这个问题。不过,这需要在可靠性和历史管理完整性之间做出权衡。
致谢
感谢澳大利亚政府交通部门和澳大利亚研究委员会的 ICT 中心(澳大利亚国家 ICT)。
参考资料
- D. Sculley et al., “ Machine Learning: The High-Interest Credit Card of Technical Debt ”, Proc. NIPS 2014 Workshop Software Eng. for Machine Learning (SE4ML), 2014.
- A. Gates, Programming Pig: Dataflow Scripting with Hadoop, O’Reilly, 2011.
- P. Nathan, Enterprise Data Workflows with Cascading, O’Reilly, 2013.
- B. Saha et al., “Apache Tez: A Unifying Framework for Modeling and Building Data Processing Applications”, Proc. 2015 ACM SIGMOD Int’l Conf. Management of Data (SIGMOD 15), 2015, pp. 1357–1369.
 Wu Dongyao是 NICTA 和新南威尔士大学的计算机科学与工程博士生。他的研究包括大数据基础架构、云计算、分布式系统和并行计算。他之前获得中国科学院软件学院的计算机科学与技术硕士学位。可以通过 dongyao.wu@nicta.com.au 联系到他。
Wu Dongyao是 NICTA 和新南威尔士大学的计算机科学与工程博士生。他的研究包括大数据基础架构、云计算、分布式系统和并行计算。他之前获得中国科学院软件学院的计算机科学与技术硕士学位。可以通过 dongyao.wu@nicta.com.au 联系到他。
 Zhu Liming是 Data61 的软件与计算系统研究项目的研究主任,Data61 将 NICTA 和 CSIRO(Commonwealth Scientifi c and Industrial Research Organisation)的研究人员集聚在一起。他同时是新南威尔士大学和悉尼大学的联合教授。他的研究涉及软件架构、可靠性系统和数据分析基础架构。他曾获得新南威尔士大学的软件工程博士学位。他还是澳大利亚标准 IT-015(系统和软件工程)和 IT-038(云计算)组委会的成员,并对 ISO/SC7/WG42 与架构相关的标准有所贡献。可以通过 liming.zhu@nicta.com.au 联系到他。
Zhu Liming是 Data61 的软件与计算系统研究项目的研究主任,Data61 将 NICTA 和 CSIRO(Commonwealth Scientifi c and Industrial Research Organisation)的研究人员集聚在一起。他同时是新南威尔士大学和悉尼大学的联合教授。他的研究涉及软件架构、可靠性系统和数据分析基础架构。他曾获得新南威尔士大学的软件工程博士学位。他还是澳大利亚标准 IT-015(系统和软件工程)和 IT-038(云计算)组委会的成员,并对 ISO/SC7/WG42 与架构相关的标准有所贡献。可以通过 liming.zhu@nicta.com.au 联系到他。
 Xu Xiwei是 Data61 分析和架构组的研究员,也是新南威尔士大学的客座讲师。她主要从事可靠性、云计算、DevOps 和大数据工作。她曾获得新南威尔士大学的软件工程博士学位。可以通过 xiwei.xu@nicta.com.au 联系到她。
Xu Xiwei是 Data61 分析和架构组的研究员,也是新南威尔士大学的客座讲师。她主要从事可靠性、云计算、DevOps 和大数据工作。她曾获得新南威尔士大学的软件工程博士学位。可以通过 xiwei.xu@nicta.com.au 联系到她。
 Sherif Sakr是 Abdulaziz 大学健康信息部门的联合教授。他同时附属于新南威尔士大学和 NICTA。他曾获得 Konstanz 大学计算机与信息科学的博士学位。他还是 IEEE 的高级成员。可以通过 sherif.sakr@nicta.com.au 联系到他。
Sherif Sakr是 Abdulaziz 大学健康信息部门的联合教授。他同时附属于新南威尔士大学和 NICTA。他曾获得 Konstanz 大学计算机与信息科学的博士学位。他还是 IEEE 的高级成员。可以通过 sherif.sakr@nicta.com.au 联系到他。
 Daniel Sun是 NICTA 的研究员,也是新南威尔士大学计算机科学与工程学院的客座讲师。他的研究包括系统建模和评估、算法和分析、可靠性、能源以及并行分布式系统中的网络。他曾获得日本科学与技术学院的信息科学博士学位。可以通过 daniel.sun@nicta.com.au 联系到他。
Daniel Sun是 NICTA 的研究员,也是新南威尔士大学计算机科学与工程学院的客座讲师。他的研究包括系统建模和评估、算法和分析、可靠性、能源以及并行分布式系统中的网络。他曾获得日本科学与技术学院的信息科学博士学位。可以通过 daniel.sun@nicta.com.au 联系到他。
 Lu Qinghua是中国石油大学软件学院的讲师。她的研究领域包括软件架构、云计算可靠性、大数据架构和服务计算。她曾获得新南威尔士计算机科学与工程的博士学位。可以通过 qinghua.lu@nicta.com.au 联系到她。
Lu Qinghua是中国石油大学软件学院的讲师。她的研究领域包括软件架构、云计算可靠性、大数据架构和服务计算。她曾获得新南威尔士计算机科学与工程的博士学位。可以通过 qinghua.lu@nicta.com.au 联系到她。
查看英文原文: Building Pipelines for Heterogeneous Execution Environments for Big Data Processing
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论